Hadoop分布式集群安装
伪分布集群见:
https://blog.csdn.net/weixin_40612128/article/details/119008295?spm=1001.2014.3001.5501
伪分布集群搞定了以后我们来看一下真正的分布式集群是什么样的。
看一下这张图,图里面表示是三个节点,左边这一个是主节点,右边的两个是从节点,hadoop集群是支持主从架构的。
不同节点上面启动的进程默认是不一样的。
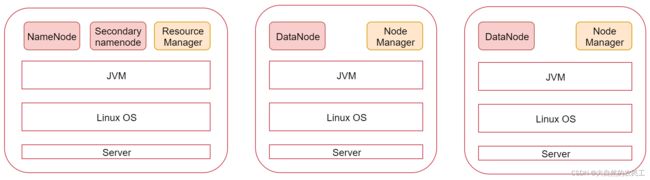
下面我们就根据图中的规划实现一个一主两从的hadoop集群
环境准备:三个节点
bigdata01 192.168.182.100
bigdata02 192.168.182.101
bigdata03 192.168.182.102
注意:每个节点的基础环境都要先配置好,先把ip、hostname、firewalld、ssh免密码登录、JDK这些基础环境配置好
目前的节点数量是不够的,按照第一周学习的内容,通过克隆的方式创建多个节点,具体克隆的步骤在这就不再赘述了。
先把bigdata01中之前安装的hadoop删掉,删除解压的目录,修改环境变量即可。
注意:我们需要把bigdata01节点中/data目录下的hadoop_repo目录和/data/soft下的hadoop-3.2.0目录删掉,恢复此节点的环境,这里面记录的有之前伪分布集群的一些信息。
[root@bigdata01 ~]# rm -rf /data/soft/hadoop-3.2.0
[root@bigdata01 ~]# rm -rf /data/hadoop_repo
假设我们现在已经具备三台linux机器了,里面都是全新的环境。
下面开始操作。
注意:针对这三台机器的ip、hostname、firewalld、JDK这些基础环境的配置步骤在这里就不再记录了,具体步骤参考2.1中的步骤。
bigdata01
bigdata02
bigdata03
这三台机器的ip、hostname、firewalld、ssh免密码登录、JDK这些基础环境已经配置ok。
这些基础环境配置好以后还没完,还有一些配置需要完善。
配置/etc/hosts
因为需要在主节点远程连接两个从节点,所以需要让主节点能够识别从节点的主机名,使用主机名远程访问,默认情况下只能使用ip远程访问,想要使用主机名远程访问的话需要在节点的/etc/hosts文件中配置对应机器的ip和主机名信息。
所以在这里我们就需要在bigdata01的/etc/hosts文件中配置下面信息,最好把当前节点信息也配置到里面,这样这个文件中的内容就通用了,可以直接拷贝到另外两个从节点
[root@bigdata01 ~]# vi /etc/hosts
192.168.182.100 bigdata01
192.168.182.101 bigdata02
192.168.182.102 bigdata03
修改bigdata02的/etc/hosts文件
[root@bigdata02 ~]# vi /etc/hosts
192.168.182.100 bigdata01
192.168.182.101 bigdata02
192.168.182.102 bigdata03
修改bigdata03的/etc/hosts文件
[root@bigdata03 ~]# vi /etc/hosts
192.168.182.100 bigdata01
192.168.182.101 bigdata02
192.168.182.102 bigdata03
集群节点之间时间同步
集群只要涉及到多个节点的就需要对这些节点做时间同步,如果节点之间时间不同步相差太多,会应该集群的稳定性,甚至导致集群出问题。
首先在bigdata01节点上操作
使用ntpdate -u ntp.sjtu.edu.cn实现时间同步,但是执行的时候提示找不到ntpdata命令
[root@bigdata01 ~]# ntpdate -u ntp.sjtu.edu.cn
-bash: ntpdate: command not found
默认是没有ntpdate命令的,需要使用yum在线安装,执行命令 yum install -y ntpdate
[root@bigdata01 ~]# yum install -y ntpdate
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
* base: mirrors.cn99.com
* extras: mirrors.cn99.com
* updates: mirrors.cn99.com
base | 3.6 kB 00:00
extras | 2.9 kB 00:00
updates | 2.9 kB 00:00
Resolving Dependencies
--> Running transaction check
---> Package ntpdate.x86_64 0:4.2.6p5-29.el7.centos will be installed
--> Finished Dependency Resolution
Dependencies Resolved
===============================================================================
Package Arch Version Repository Size
===============================================================================
Installing:
ntpdate x86_64 4.2.6p5-29.el7.centos base 86 k
Transaction Summary
===============================================================================
Install 1 Package
Total download size: 86 k
Installed size: 121 k
Downloading packages:
ntpdate-4.2.6p5-29.el7.centos.x86_64.rpm | 86 kB 00:00
Running transaction check
Running transaction test
Transaction test succeeded
Running transaction
Installing : ntpdate-4.2.6p5-29.el7.centos.x86_64 1/1
Verifying : ntpdate-4.2.6p5-29.el7.centos.x86_64 1/1
Installed:
ntpdate.x86_64 0:4.2.6p5-29.el7.centos
Complete!
然后手动执行ntpdate -u ntp.sjtu.edu.cn 确认是否可以正常执行
[root@bigdata01 ~]# ntpdate -u ntp.sjtu.edu.cn
7 Apr 21:21:01 ntpdate[5447]: step time server 185.255.55.20 offset 6.252298 sec
建议把这个同步时间的操作添加到linux的crontab定时器中,每分钟执行一次
[root@bigdata01 ~]# vi /etc/crontab
* * * * * root /usr/sbin/ntpdate -u ntp.sjtu.edu.cn
然后在bigdata02和bigdata03节点上配置时间同步
在bigdata02节点上操作
[root@bigdata02 ~]# yum install -y ntpdate
[root@bigdata02 ~]# vi /etc/crontab
* * * * * root /usr/sbin/ntpdate -u ntp.sjtu.edu.cn
在bigdata03节点上操作
[root@bigdata03 ~]# yum install -y ntpdate
[root@bigdata03 ~]# vi /etc/crontab
* * * * * root /usr/sbin/ntpdate -u ntp.sjtu.edu.cn
SSH免密码登录完善
注意:针对免密码登录,目前只实现了自己免密码登录自己,最终需要实现主机点可以免密码登录到所有节点,所以还需要完善免密码登录操作。
首先在bigdata01机器上执行下面命令,将公钥信息拷贝到两个从节点
[root@bigdata01 ~]# scp ~/.ssh/authorized_keys bigdata02:~/
The authenticity of host 'bigdata02 (192.168.182.101)' can't be established.
ECDSA key fingerprint is SHA256:uUG2QrWRlzXcwfv6GUot9DVs9c+iFugZ7FhR89m2S00.
ECDSA key fingerprint is MD5:82:9d:01:51:06:a7:14:24:a9:16:3d:a1:5e:6d:0d:16.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'bigdata02,192.168.182.101' (ECDSA) to the list of known hosts.
root@bigdata02's password:
authorized_keys 100% 396 506.3KB/s 00:00
[root@bigdata01 ~]# scp ~/.ssh/authorized_keys bigdata03:~/
The authenticity of host 'bigdata03 (192.168.182.102)' can't be established.
ECDSA key fingerprint is SHA256:uUG2QrWRlzXcwfv6GUot9DVs9c+iFugZ7FhR89m2S00.
ECDSA key fingerprint is MD5:82:9d:01:51:06:a7:14:24:a9:16:3d:a1:5e:6d:0d:16.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'bigdata03,192.168.182.102' (ECDSA) to the list of known hosts.
root@bigdata03's password:
authorized_keys 100% 396 606.1KB/s 00:00
然后在bigdata02和bigdata03上执行
bigdata02:
[root@bigdata02 ~]# cat ~/authorized_keys >> ~/.ssh/authorized_keys
bigdata03:
[root@bigdata03 ~]# cat ~/authorized_keys >> ~/.ssh/authorized_keys
验证一下效果,在bigdata01节点上使用ssh远程连接两个从节点,如果不需要输入密码就表示是成功的,此时主机点可以免密码登录到所有节点。
[root@bigdata01 ~]# ssh bigdata02
Last login: Tue Apr 7 21:33:58 2020 from bigdata01
[root@bigdata02 ~]# exit
logout
Connection to bigdata02 closed.
[root@bigdata01 ~]# ssh bigdata03
Last login: Tue Apr 7 21:17:30 2020 from 192.168.182.1
[root@bigdata03 ~]# exit
logout
Connection to bigdata03 closed.
[root@bigdata01 ~]#
有没有必要实现从节点之间互相免密码登录呢?
这个就没有必要了,因为在启动集群的时候只有主节点需要远程连接其它节点。
OK,那到这为止,集群中三个节点的基础环境就都配置完毕了,接下来就需要在这三个节点中安装Hadoop了。
首先在bigdata01节点上安装。
1:把hadoop-3.2.0.tar.gz安装包上传到linux机器的/data/soft目录下
[root@bigdata01 soft]# ll
total 527024
-rw-r--r--. 1 root root 345625475 Jul 19 2019 hadoop-3.2.0.tar.gz
drwxr-xr-x. 7 10 143 245 Dec 16 2018 jdk1.8
-rw-r--r--. 1 root root 194042837 Apr 6 23:14 jdk-8u202-linux-x64.tar.gz
2:解压hadoop安装包
[root@bigdata01 soft]# tar -zxvf hadoop-3.2.0.tar.gz
3:修改hadoop相关配置文件
进入配置文件所在目录
[root@bigdata01 soft]# cd hadoop-3.2.0/etc/hadoop/
[root@bigdata01 hadoop]#
首先修改hadoop-env.sh文件,在文件末尾增加环境变量信息
[root@bigdata01 hadoop]# vi hadoop-env.sh
export JAVA_HOME=/data/soft/jdk1.8
export HADOOP_LOG_DIR=/data/hadoop_repo/logs/hadoop
修改core-site.xml文件,注意fs.defaultFS属性中的主机名需要和主节点的主机名保持一致
[root@bigdata01 hadoop]# vi core-site.xml
fs.defaultFS
hdfs://bigdata01:9000
hadoop.tmp.dir
/data/hadoop_repo
修改hdfs-site.xml文件,把hdfs中文件副本的数量设置为2,最多为2,因为现在集群中有两个从节点,还有secondaryNamenode进程所在的节点信息
[root@bigdata01 hadoop]# vi hdfs-site.xml
dfs.replication
2
dfs.namenode.secondary.http-address
bigdata01:50090
修改mapred-site.xml,设置mapreduce使用的资源调度框架
[root@bigdata01 hadoop]# vi mapred-site.xml
mapreduce.framework.name
yarn
修改yarn-site.xml,设置yarn上支持运行的服务和环境变量白名单
注意,针对分布式集群在这个配置文件中还需要设置resourcemanager的hostname,否则nodemanager找不到resourcemanager节点。
[root@bigdata01 hadoop]# vi yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
yarn.resourcemanager.hostname
bigdata01
修改workers文件,增加所有从节点的主机名,一个一行
[root@bigdata01 hadoop]# vi workers
bigdata02
bigdata03
修改启动脚本
修改start-dfs.sh,stop-dfs.sh这两个脚本文件,在文件前面增加如下内容
[root@bigdata01 hadoop]# cd /data/soft/hadoop-3.2.0/sbin
[root@bigdata01 sbin]# vi start-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
[root@bigdata01 sbin]# vi stop-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
修改start-yarn.sh,stop-yarn.sh这两个脚本文件,在文件前面增加如下内容
[root@bigdata01 sbin]# vi start-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
[root@bigdata01 sbin]# vi stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
4:把bigdata01节点上将修改好配置的安装包拷贝到其他两个从节点
[root@bigdata01 sbin]# cd /data/soft/
[root@bigdata01 soft]# scp -rq hadoop-3.2.0 bigdata02:/data/soft/
[root@bigdata01 soft]# scp -rq hadoop-3.2.0 bigdata03:/data/soft/
5:在bigdata01节点上格式化HDFS
[root@bigdata01 soft]# cd /data/soft/hadoop-3.2.0
[root@bigdata01 hadoop-3.2.0]# bin/hdfs namenode -format
如果在后面的日志信息中能看到这一行,则说明namenode格式化成功。
common.Storage: Storage directory /data/hadoop_repo/dfs/name has been successfully formatted.
6:启动集群,在bigdata01节点上执行下面命令
[root@bigdata01 hadoop-3.2.0]# sbin/start-all.sh
Starting namenodes on [bigdata01]
Last login: Tue Apr 7 21:03:21 CST 2020 from 192.168.182.1 on pts/2
Starting datanodes
Last login: Tue Apr 7 22:15:51 CST 2020 on pts/1
bigdata02: WARNING: /data/hadoop_repo/logs/hadoop does not exist. Creating.
bigdata03: WARNING: /data/hadoop_repo/logs/hadoop does not exist. Creating.
Starting secondary namenodes [bigdata01]
Last login: Tue Apr 7 22:15:53 CST 2020 on pts/1
Starting resourcemanager
Last login: Tue Apr 7 22:15:58 CST 2020 on pts/1
Starting nodemanagers
Last login: Tue Apr 7 22:16:04 CST 2020 on pts/1
7:验证集群
分别在3台机器上执行jps命令,进程信息如下所示:
在bigdata01节点执行
[root@bigdata01 hadoop-3.2.0]# jps
6128 NameNode
6621 ResourceManager
6382 SecondaryNameNode
在bigdata02节点执行
[root@bigdata02 ~]# jps
2385 NodeManager
2276 DataNode
在bigdata03节点执行
[root@bigdata03 ~]# jps
2326 NodeManager
2217 DataNode
8:停止集群
在bigdata01节点上执行停止命令
[root@bigdata01 hadoop-3.2.0]# sbin/stop-all.sh
Stopping namenodes on [bigdata01]
Last login: Tue Apr 7 22:21:16 CST 2020 on pts/1
Stopping datanodes
Last login: Tue Apr 7 22:22:42 CST 2020 on pts/1
Stopping secondary namenodes [bigdata01]
Last login: Tue Apr 7 22:22:44 CST 2020 on pts/1
Stopping nodemanagers
Last login: Tue Apr 7 22:22:46 CST 2020 on pts/1
Stopping resourcemanager
Last login: Tue Apr 7 22:22:50 CST 2020 on pts/1
至此,hadoop分布式集群安装成功!
注意:前面这些操作步骤这么多,如果我是新手我怎么知道需要做这些操作呢?不用担心,官方给提供的有使用说明,也就是我们平时所说的官方文档,我们平时买各种各样的东西都是有说明书的,上面会告诉你该怎么使用,这个是最权威最准确的。
那我们来看一下Hadoop的官网文档:
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
Hadoop的客户端节点
在实际工作中不建议直接连接集群中的节点来操作集群,直接把集群中的节点暴露给普通开发人员是不安全的
建议在业务机器上安装Hadoop,只需要保证业务机器上的Hadoop的配置和集群中的配置保持一致即可,这样就可以在业务机器上操作Hadoop集群了,此机器就称为是Hadoop的客户端节点
Hadoop的客户端节点可能会有多个,理论上是我们想要在哪台机器上操作hadoop集群就可以把这台机器配置为hadoop集群的客户端节点。
