Spark的RDD依赖关系
Spark的RDD依赖关系
一、RDD的血缘关系
RDD 只支持粗粒度转换,即在大量记录上执行的单个操作。将创建 RDD 的一系列 Lineage(血统)记录下来,以便恢复丢失的分区。RDD 的 Lineage 会记录 RDD 的元数据信息和转换行为,当该 RDD 的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
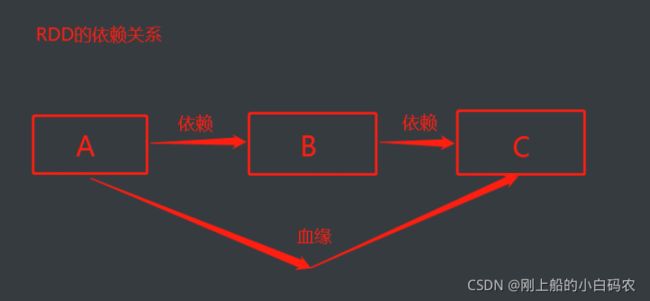
上图中A和B是依赖关系,B和C是依赖关系,那么A和B就是血缘关系,血缘关系可以看做是非直系亲属关系
类似于A和C的连续的RDD的依赖关系,称之为血缘关系,每个RDD会保存血缘关系
val fileRDD: RDD[String] = sc.textFile("input/1.txt")
println(fileRDD.toDebugString)
println("----------------------")
val wordRDD: RDD[String] = fileRDD.flatMap(_.split(" "))
println(wordRDD.toDebugString)
println("----------------------")
val mapRDD: RDD[(String, Int)] = wordRDD.map((_,1))
println(mapRDD.toDebugString)
println("----------------------")
val resultRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_+_)
println(resultRDD.toDebugString)
resultRDD.collect()
二、RDD的依赖关系
这里所谓的依赖关系,其实就是两个相邻 RDD 之间的关系
上图中的A和B是依赖关系,B和C是依赖关系,依赖关系可以看做是直系的亲属关系
RDD不会保存数据,RDD为了提供容错性,需要将RDD间的关系保存下来,一旦出现错误,可以根据血缘关系将数据源重新读取进行进算
根据依赖的RDD不同,RDD依赖关系会分成款依赖和窄依赖两种
val sc: SparkContext = new SparkContext(conf)
val fileRDD: RDD[String] = sc.textFile("input/1.txt")
println(fileRDD.dependencies)
println("----------------------")
val wordRDD: RDD[String] = fileRDD.flatMap(_.split(" "))
println(wordRDD.dependencies)
println("----------------------")
val mapRDD: RDD[(String, Int)] = wordRDD.map((_,1))
println(mapRDD.dependencies)
println("----------------------")
val resultRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_+_)
println(resultRDD.dependencies)
resultRDD.collect()
1:窄依赖
新的RDD的一个分区的数据依赖于旧的RDD一个分区的数据,这个依赖称之为OneToOne依赖,又称为窄依赖
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd)

2:宽依赖
新的RDD的一个分区的数据依赖于旧的RDD多个分区的数据,这个依赖称之为Shuffle依赖,又称为宽依赖
class ShuffleDependency[K: ClassTag, V: ClassTag, C: ClassTag](
@transient private val _rdd: RDD[_ <: Product2[K, V]],
val partitioner: Partitioner,
val serializer: Serializer = SparkEnv.get.serializer,
val keyOrdering: Option[Ordering[K]] = None,
val aggregator: Option[Aggregator[K, V, C]] = None,
val mapSideCombine: Boolean = false)
extends Dependency[Product2[K, V]]
