电商数据仓库系统
电商数据仓库系统
- 数据仓库概述
- 数据仓库建模概述
-
- 数据仓库建模的意义
- 数据仓库建模方法论
-
- ER模型
- 维度模型
- 维度建模理论之事实表
-
- 事实表概述
- 事务型事实表
-
- 设计流程
- 不足
- 周期型快照事实表
- 累积型快照事实表
- 维度建模理论之维度表
- 维度建模理论之维度表
- 数据仓库设计
- 数据仓库环境准备
-
- 数据仓库运行环境
-
- Hive环境搭建
- Yarn环境配置
- 数据仓库开发环境
- 模拟数据准备
数据仓库概述
数据仓库是一个为数据分析而设计的企业级数据管理系统。数据仓库可集中、整合多个信息源的大量数据,借助数据仓库的分析能力,企业可从数据中获得宝贵的信息进而改进决策
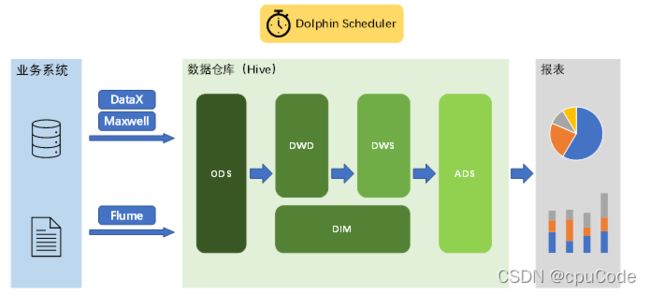
数据仓库核心架构 :
数据仓库建模概述
数据仓库建模的意义
数据模型 : 数据组织和存储方法,它强调从业务、数据存取和使用角度合理存储数据。只有将数据有序的组织和存储起来之后,数据才能得到高性能、低成本、高效率、高质量的使用
- 高性能:快速查询所需要的数据
- 低成本:减少重复计算,实现计算结果的复用,降低计算成本
- 高效率:良改善用户使用数据的体验,提高使用数据的效率
- 高质量:改善数据统计口径的混乱,减少计算错误的可能性
数据仓库建模方法论
ER模型
建模方法 : 从全企业的高度,用实体关系(Entity Relationship,ER)模型来描述企业业务,并用规范化的方式表示出来,在范式理论上符合 3NF
实体关系模型
数据库规范化
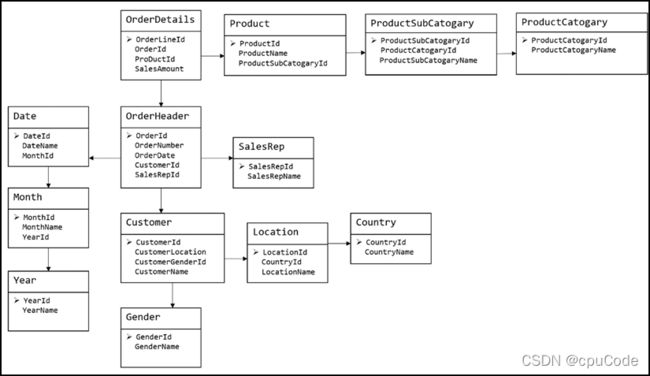
建模方法的出发点是整合数据,其目的是将整个企业的数据进行组合和合并,并进行规范处理,减少数据冗余性,保证数据的一致性。这种模型并不适合直接用于分析统计
维度模型
维度模型 : 将复杂的业务通过事实和维度两个概念进行呈现。事实通常对应业务过程,而维度通常对应业务过程发生时所处的环境
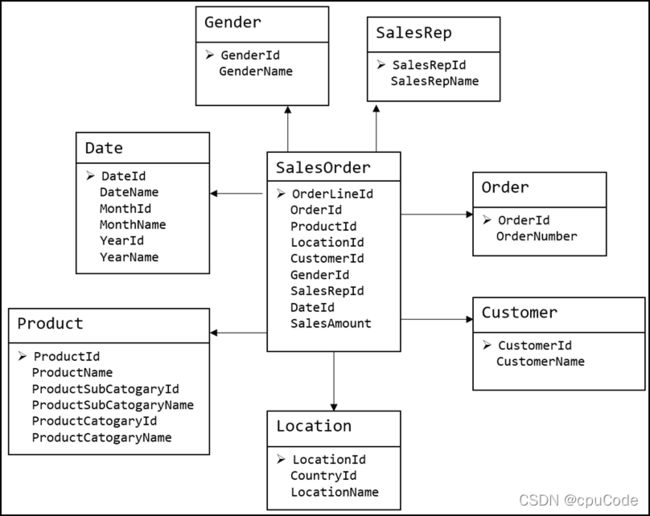
维度建模以数据分析作为出发点,为数据分析服务,因此它关注的重点的用户如何更快的完成需求分析以及如何实现较好的大规模复杂查询的响应性能
维度建模理论之事实表
事实表概述
事实表 : 数据仓库维度建模的核心,紧紧围绕着业务过程来设计。其包含与该业务过程有关的维度引用(维度表外键)以及该业务过程的度量(可累加的数字类型字段)
事实表 : 比较 “细长”,即列较少,但行较多,且行的增速快
事实表的类型:
- 事务事实表
- 周期快照事实表
- 累积快照事实表
事务型事实表
事务事实表 : 记录各业务过程,它保存的是各业务过程的原子操作事件 ( 最细粒度的操作事件 )
粒度 : 事实表中一行数据所表达的业务细节程度
事务型事实表 : 分析与各业务过程相关的各项统计指标,由于保存最细粒度的记录,可以提供最大限度的灵活性,可以统计各种细节层次的需求
设计流程
设计事务事实表步骤:
- 选择业务过程
- 声明粒度
- 确认维度
- 确认事实
选择业务过程
声明粒度
确定维度
确定事实
不足
事务型事实表 : 保存所有业务过程的最细粒度的操作事件,故理论上其可以支撑与各业务过程相关的各种统计粒度的需求
周期型快照事实表
累积型快照事实表
维度建模理论之维度表
维度建模理论之维度表
数据仓库设计

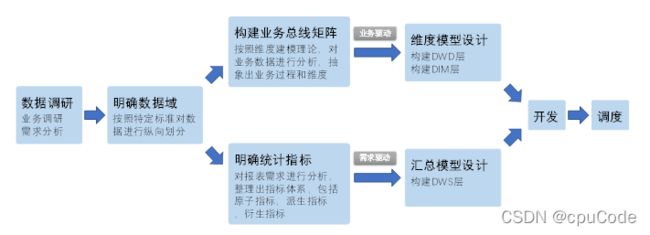
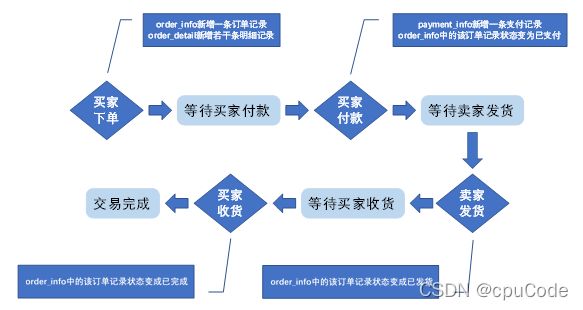
数据仓库环境准备
数据仓库运行环境
Hive环境搭建
Hive引擎:
- 默认MR
- Tez
- Spark
Hive on Spark:Hive 既作为存储元数据又负责 SQL 的解析优化,语法是 HQL 语法,执行引擎变成了 Spark ,Spark 负责采用 RDD 执行
Spark on Hive : Hive 只作为存储元数据,Spark 负责 SQL 解析优化,语法是 Spark SQL 语法,Spark 负责采用 RDD 执行
Hive on Spark 配置
官网下载的 Hive3.1.2 和 Spark3.0.0 默认是不兼容的
因为 Hive3.1.2 支持的Spark版本是 2.4.5,所以需要我们重新编译 Hive3.1.2 版本
编译步骤:
官网下载 Hive3.1.2 源码,修改 pom 文件中引用的 Spark 版本为 3.0.0 ,编译通过,直接打包获取 jar 包
在Hive所在节点部署Spark
上传并解压解压 spark-3.0.0-bin-hadoop3.2.tgz
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module/
mv /opt/module/spark-3.0.0-bin-hadoop3.2 /opt/module/spark
配置 SPARK_HOME 环境变量
sudo vim /etc/profile.d/my_env.sh
# SPARK_HOME
export SPARK_HOME=/opt/module/spark
export PATH=$PATH:$SPARK_HOME/bin
在 hive 中创建 spark 配置文件
vim spark-defaults.conf
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://cpucode101:8020/spark-history
spark.executor.memory 1g
spark.driver.memory 1g
在 HDFS 创建如下路径,用于存储历史日志
hadoop fs -mkdir /spark-history
向 HDFS 上传 Spark 纯净版 jar 包
修改 hive-site.xml 文件
vim hive-site.xml
<!--Spark依赖位置(注意:端口号8020必须和 namenode 的端口号一致)-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://cpucode101:8020/spark-jars/*</value>
</property>
<!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
Hive on Spark 测试
启动 hive 客户端
hive
Yarn环境配置
数据仓库开发环境
数仓开发工具 DataGrip。需要用到 JDBC 协议连接到 Hive,所以启动 HiveServer2
启动 HiveServer2
hiveserver2
配置DataGrip连接
配置连接属性
所有属性配置,和 Hive 的 beeline 客户端配置一致
修改连接,指明连接数据库
选择当前数据库为 gmall
模拟数据准备
企业在开始搭建数仓时,业务数据库存在历史数据,用户行为日志无历史数据
用户行为日志
业务数据
生成模拟数据