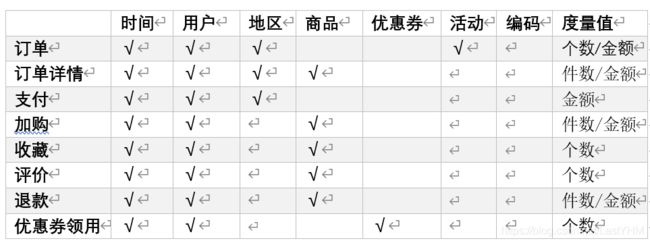
hive在数仓ODS层到DWD层建模方法
数仓建模的原因
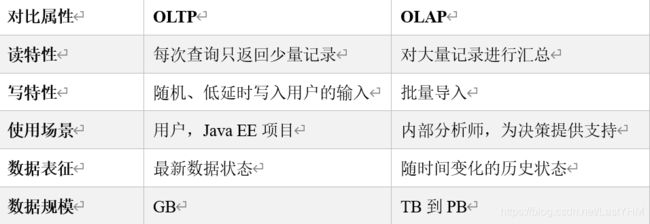
当今的数据处理大致可以分成两大类:联机事务处理OLTP(on-line transaction processing)、联机分析处理OLAP(On-Line Analytical Processing)。OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。二者的主要区别对比如下表所示。
创建数仓主要完成OLAP的业务需求,将原始数据导入到ODS层之后,就需要将原始数据的关系建模转变为维度建模
数仓建模的好处
数仓建模的好处从关系模型和维度模型的对比中可以看出
关系建模
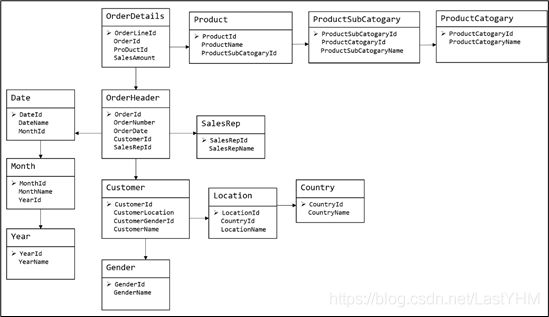
关系模型如图所示,严格遵循第三范式(3NF),从图中可以看出,较为松散、零碎,物理表数量多,而数据冗余程度低。由于数据分布于众多的表中,这些数据可以更为灵活地被应用,功能性较强。关系模型主要应用与OLTP系统中,为了保证数据的一致性以及避免冗余,所以大部分业务系统的表都是遵循第三范式的。
OLTP系统中,数据多保存在关系型数据库(Mysql)中,一方面数据的冗余会造成数据库难以保存,另一方面表格太大不利于Mysql的快速响应,拆分为多个零碎小表的格式更利于查询使用
维度建模

维度模型如图所示,主要应用于OLAP系统中,通常以某一个事实表为中心进行表的组织,主要面向业务,特征是可能存在数据的冗余,但是能方便的得到数据。
关系模型虽然冗余少,但是在大规模数据,跨表分析统计查询过程中,会造成多表关联,这会大大降低执行效率。在使用hive进行数仓项目的数据管理时,由于地层使用FDFS分布式存储,磁盘空间充足,冗余的数据不会造成困扰,另一方面,hive查询引擎的原因,过多表格直接的join会引发spark产生过多的shuffle流程(如果使用MR会产品过多的mapreduce),造成性能的下降
数仓建模中模型的分类和选择
在维度建模的基础上又分为三种模型:星型模型、雪花模型、星座模型
星型模型
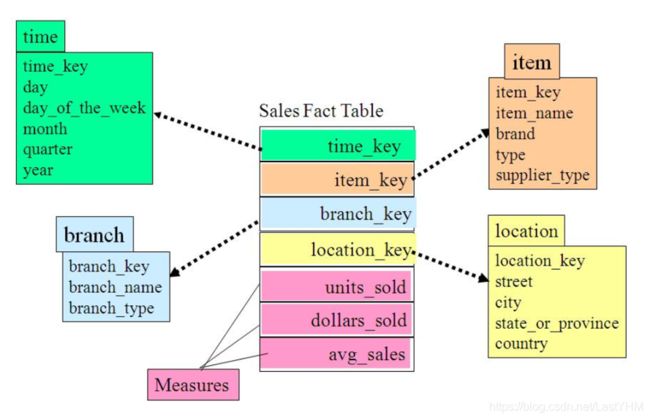
标准的星型模型维度只有一层,中间为事实表,外围是维度表,尽量把维度表缩减为一层的做法,在查询的性能上会有较大的提升,同时会造成更多的数据冗余。
雪花模型
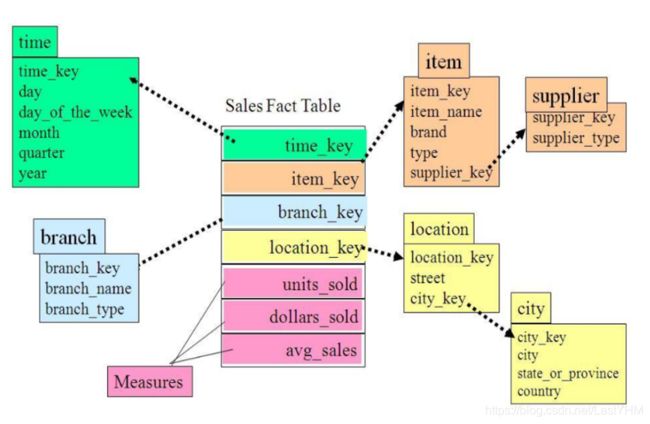
在中心一张事实表的外围,有多于1层的维度表,即为雪花模型在性能上会弱于星型模型,但是相对应的会降低一部分数据冗余
星座模型
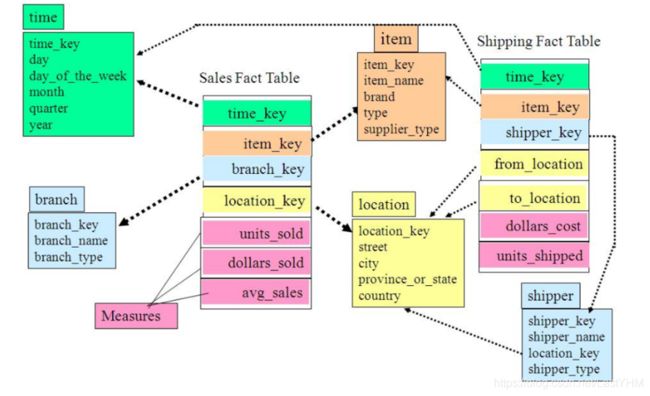
星座模型与上述两种模型不属于同一纬度,星座模型表示的是多个事实表的纬度模型。
星座模型是多数数仓的常态,它主要反映了数仓模型中有多张事实表,同时它们共享一些维度表
模型的选择
在进行星型模型和雪花模型的选择中,主要取决于性能优先还是灵活更优先。多数数仓中不会绝对选择一种,根据情况灵活组合,甚至并存。总体来看,更倾向于维度更少的星型模型。
在hive中,由于减少join能够大幅度减少shuffle,性能差距很大,所以推荐使用星型模型。
数仓建模中的表格类型介绍
在ODS层中的表格,保留有Mysql中导入的原始字段和数据,属于关系模型,不存在维度模型中的表格类型。
而在DWD层中,创建维度模型,需要有两种表格类型组成:维度表和事实表
维度表
维度表:一般是对事实的描述信息。每一张维表对应现实世界中的一个对象或者概念。 例如:用户、商品、日期、地区等。
维度表的特征:(相对于事实表而言)
维表的范围很宽(具有多个属性、列比较多)
跟事实表相比,行数相对较小:通常< 10万条
内容相对固定:编码表
事实表
事实表中的每行数据代表一个业务事件(下单、支付、退款、评价等)。“事实”这个术语表示的是业务事件的度量值(可统计次数、个数、金额等)。
每一个事实表的行包括:具有可加性的数值型的度量值、与维度表相连接的外键、通常具有两个和两个以上的外键、外键之间表示维表之间多对多的关系。
事实表的特征:(相对于维度表)
数据量非常的大(行数)
内容相对的窄:列数较少(主要是外键id和度量值)
经常发生变化,每天会新增加很多。
1)事务型事实表
以每个事务或事件为单位,例如一个销售订单记录,一笔支付记录等,作为事实表里的一行数据。一旦事务被提交,事实表数据被插入,数据就不再进行更改,其更新方式为每日增量更新。
2)周期型快照事实表
周期型快照事实表中不会保留所有数据,只保留固定时间间隔的数据,例如每天或者每月的销售额,或每月的账户余额等。
例如购物车,有加减商品,随时都有可能变化,但是我们更关心每天结束时这里面有多少商品,方便我们后期统计分析。因此周期型快照事实表的更新方式为每日全量更新,即每日对数据做一个快照。
3)累积型快照事实表
累积快照事实表用于跟踪业务事实的变化。例如,数据仓库中可能需要累积或者存储订单从下订单开始,到订单商品被打包、运输、和签收的各个业务阶段的时间点数据来跟踪订单生命周期的进展情况。当这个业务过程进行时,事实表的记录也要不断更新。
数仓建模的步骤
维度建模一般按照以下四个步骤:
选择业务过程→声明粒度→确认维度→确认事实
(1)选择业务过程
在业务系统中,挑选我们感兴趣的业务线,比如下单业务,支付业务,退款业务,物流业务,一条业务线对应一张事实表。
如果是中小公司,尽量把所有业务过程都选择。
如果是大公司(1000多张表),选择和需求相关的业务线。
(2)声明粒度
数据粒度指数据仓库的数据中保存数据的细化程度或综合程度的级别。
声明粒度意味着精确定义事实表中的一行数据表示什么,应该尽可能选择最小粒度,以此来应各种各样的需求。
典型的粒度声明如下:
订单当中的每个商品项作为下单事实表中的一行,粒度为每次。
每周的订单次数作为一行,粒度为每周。
每月的订单次数作为一行,粒度为每月。
如果在DWD层粒度就是每周或者每月,那么后续就没有办法统计细粒度的指标了。所以建议采用最小粒度。
(3)确定维度
维度的主要作用是描述业务是事实,主要表示的是“谁,何处,何时”等信息。
确定维度的原则是:后续需求中是否要分析相关维度的指标。例如,需要统计,什么时间下的订单多,哪个地区下的订单多,哪个用户下的订单多。需要确定的维度就包括:时间维度、地区维度、用户维度。
维度表:需要根据维度建模中的星型模型原则进行维度退化。
(4)确定事实
此处的“事实”一词,指的是业务中的度量值(次数、个数、件数、金额,可以进行累加),例如订单金额、下单次数等。
在DWD层,以业务过程为建模驱动,基于每个具体业务过程的特点,构建最细粒度的明细层事实表。事实表可做适当的宽表化处理。
事实表和维度表的关联比较灵活,但是为了应对更复杂的业务需求,可以将能关联上的表尽量关联上。如何判断是否能够关联上呢?在业务表关系图中,只要两张表能通过中间表能够关联上,就说明能关联上。
(5)注意事项
一 、尽量选择更细的粒度
在保留数据时间的情况下,如果选择较粗的力度,后续再想进行查分,会非常麻烦。而选择较细的粒度,合并统计为较粗的粒度比较简单操作
二 、尽量保留更多的纬度表信息
如果后续新添加的需求所需要的字段没有在DWD层保留,在进行重新的建模添加会非常麻烦。
三、以需求为主导确定度量值
度量值是主要的统计信息,直接对应业务需求,所以要按照需求倒退事实表的度量值。