超详细整理!Pandas实用手册(PART I)
这一系列一共三部分,里面的一些技巧可能暂时用不上,但是相信总有一天你会接触到,建议收藏 每一小节对应代码大家可以在我共享的colab上把玩,
每一小节对应代码大家可以在我共享的colab上把玩,
???? https://colab.research.google.com/drive/1WhKCNkx6VnX1TS8uarTICIK2ViPzNDjw
订阅号后台回复 "pd" 获取 
写在前面
pandas是Python的一个数据分析库,提供如DataFrame等十分容易操作的数据结构,是近年做数据分析时不可或缺的工具之一。
虽然已经有满坑满谷的教学文章、视频或是线上课程,正是因为pandas学习资源之多,导致初学者常常不知如何踏出第一步。在这篇文章里头,我们将接近40个实用的pandas技巧由浅入深地分成6大类别:
建立DataFrame
定制化DataFrame 显示设定
数据清理& 整理
取得想要关注的数据
基本数据处理与转换
简单汇总& 分析数据
通过有系统地呈现这些pandas技巧,我们希望能让更多想要利用Python做数据分析或是想成为data scientist的你,能用最有效率的方式掌握核心pandas能力;同时也希望你能将自己认为实用但本文没有提到的技巧与我们分享。
废话不多说啦,让我们开始这趟pandas旅程吧!当然,首先你得import pandas:
建立DataFrame
pandas里有非常多种可以初始化一个DataFrame的技巧,以下列出一些我觉得实用的初始化方式。
用Python dict建立DataFrame
使用Python的dict来初始化DataFrame十分只管,基本上dict里头的每一个键(key)都对应到一个列名称,而其值(value)则是一个iterable,代表该列里头所有的数值。 在需要管理多个DataFrames时你会需要用更有意义的名字来代表它们,但在数据科学领域里只要看到df,每个人都会预期它是一个Data Frame,不论是Python或是R语言的使用者。
在需要管理多个DataFrames时你会需要用更有意义的名字来代表它们,但在数据科学领域里只要看到df,每个人都会预期它是一个Data Frame,不论是Python或是R语言的使用者。
很多时候你也会需要改变DataFrame 里的列名称: 这里也很直观,就是给一个将旧列名对应到新列名的Python dict。值得注意的是参数
这里也很直观,就是给一个将旧列名对应到新列名的Python dict。值得注意的是参数axis=1:在pandas里大部分函数预设处理的轴为行(row),以axis=0表示;而将axis设置为1则代表你想以列(column)为单位套用该函数。
你也可以用df.columns的方式改变列名称:
使用pd.util.testing随机建立DataFrame
当你想要随意初始化一个DataFrame并测试pandas功能时,pd.util.testing就显得十分好用:
head函数预设用来显示DataFrame中前5项数据,要显示最后数据则可以使用tail函数。
你也可以用makeMixedDataFrame建立一个有各种数据类型的DataFrame方便测试: 其他函数如
其他函数如makeMissingDataframe及makeTimeDataFrame我们在后面的章节介绍使用。
将剪贴簿内容转换成DataFrame
你可以从Excel、Google Sheet 或是网页上复制表格并将其转成DataFrame。
只需简单2个步骤:
复制其他来源的表格;
执行 pd.read_clipboard;
 这个技巧在你想要快速将一些数据转成DataFrame 时非常方便。
这个技巧在你想要快速将一些数据转成DataFrame 时非常方便。
读取线上CSV文档
不限于本地档案,只要有正确的URL 以及网络连接就可以将网络上的任意CSV 档案转成DataFrame。比方说你可以将Kaggle著名的Titanic竞赛的CSV档案从网络上下载下来并转成DataFrame: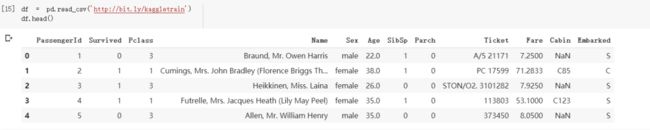 过来人经验,虽然像这样利用pandas 直接从网络上下载并分析数据很方便,但是有时host 数据的网页与机构(尤其是政府机关)会无预期地修改他们网站,导致数据集的URL 失效。为了最大化重现性,我还是会建议将数据载到本地备份之后,再做分析比较实在。
过来人经验,虽然像这样利用pandas 直接从网络上下载并分析数据很方便,但是有时host 数据的网页与机构(尤其是政府机关)会无预期地修改他们网站,导致数据集的URL 失效。为了最大化重现性,我还是会建议将数据载到本地备份之后,再做分析比较实在。
优化内存使用量
你可以透过df.info查看DataFrame当前的内存用量: 从最后一列可以看出Titanic这个小DataFrame只占了322 KB。这边使用的df不占什么内存,但如果你想读入的DataFrame很大,可以只读入特定的栏位并将已知的分类型(categorical)栏位转成category型态以节省内存(在分类数目较数据量小时有效):
从最后一列可以看出Titanic这个小DataFrame只占了322 KB。这边使用的df不占什么内存,但如果你想读入的DataFrame很大,可以只读入特定的栏位并将已知的分类型(categorical)栏位转成category型态以节省内存(在分类数目较数据量小时有效):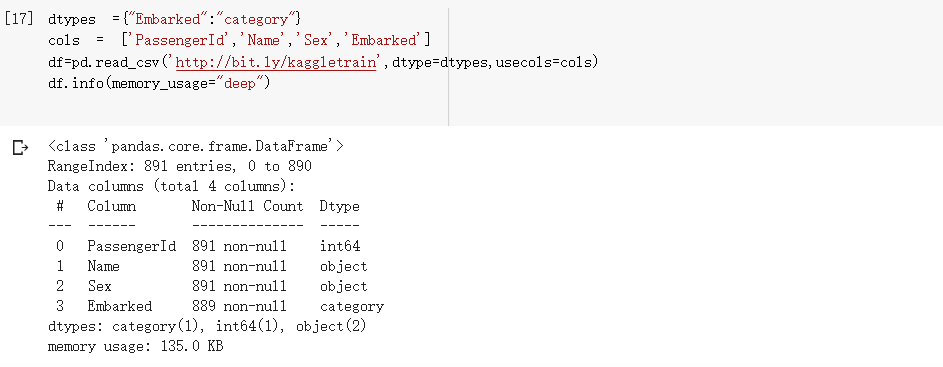 通过减少读入的栏位数并将object转换成category栏位,读入的df只剩135KB,只需刚刚的40%内存用量。
通过减少读入的栏位数并将object转换成category栏位,读入的df只剩135KB,只需刚刚的40%内存用量。
另外如果你想在有限的内存处理巨大CSV文档,也可以透通过chunksize参数来限制一次读入的行数(rows):
读入并合并多个CSV档案成单一DataFrame
很多时候因为企业内部ETL或是数据处理的方式(比方说利用Airflow处理批次数据),相同类型的数据可能会被分成多个不同的CSV档案储存。
假设在本地端dataset资料夹内有2个CSV档案,分别储存Titanic号上不同乘客的数据: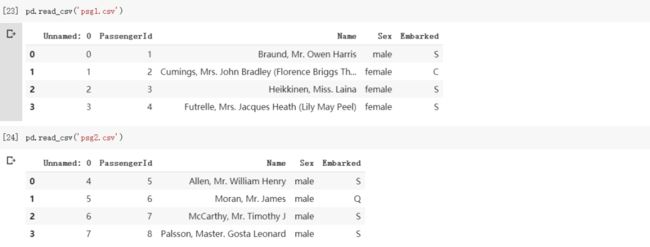 注意上面2个DataFrames的内容虽然分别代表不同乘客,其格式却是一模一样。这种时候你可以使用
注意上面2个DataFrames的内容虽然分别代表不同乘客,其格式却是一模一样。这种时候你可以使用pd.concat将分散在不同CSV的乘客数据合并成单一DataFrame,方便之后处理: 你还可以使用
你还可以使用reset_index函数来重置串接后的DataFrame索引。
前面说过很多pandas函数预设的axis参数为0,代表着以行(row)为单位做特定的操作,在pd.concat的例子中则是将2个同样格式的DataFrames依照axis=0串接起来。有时候同一笔数据的不同特征值(features)会被存在不同文档里,这时候我们就需要选定axis=1。
定制化DataFrame显示设定
虽然pandas 会尽可能地将一个DataFrame 完整且漂亮地呈现出来,有时候你还是会想要改变预设的显示方式。这节列出一些常见的使用情境。
完整显示所有列
有时候一个DataFrame 里头的栏位太多, pandas 会自动省略某些中间栏位以保持页面整洁: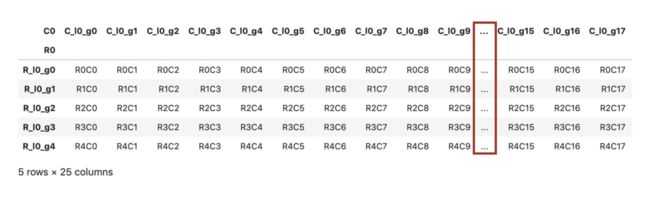 但如果你无论如何都想要显示所有栏位以方便一次查看,可以透过
但如果你无论如何都想要显示所有栏位以方便一次查看,可以透过pd.set_option函数来改变display.max_columns设定:
pd.set_option("display.max_columns", None)
df
另外你也可以使用T来转置(transpose)当前DataFrame,垂直显示所有栏位:
df.T.head (15)
此外,你可以在pandas官方文件里查看其他常用的显示设定[1]。
减少显示的栏位长度
这边你一样可以通过pd.set_option函数来限制Titanic数据集里头Name栏位的显示长度: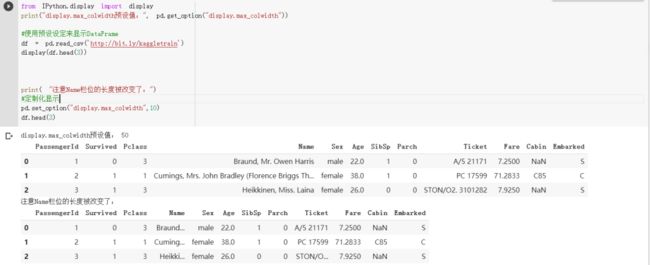
改变浮点数显示位数
除了栏位长度以外,你常常会想要改变浮点数(float)显示的小数点位数: 你会发现
你会发现Fare栏位现在只显示小数点后一位的数值了。另外注意刚刚设定的max_colwidth是会被套用到所有DataFrame的。因此这个DataFrame的Name栏位显示的宽度还跟上个DataFrame相同:都被缩减了。
想要将所有调整过的设定初始化,可以执行:
pd.reset_option("all")
其他常用的options 包含:
max_rows
max_columns
date_yearfirst
等等。执行pd.describe_option()可以显示所有可供使用的options,但如果你是在Jupyter notebook内使用pandas的话,我推荐直接在set_option函式的括号里输入Shift+ tab显示所有选项。
为特定DataFrame加点样式
pd.set_option函数在你想要把某些显示设定套用到所有 DataFrames时很好用,不过很多时候你会想要让不同DataFrame有不同的显示设定或样式(styling)。
比方说针对下面这个只有10笔数据的DataFrame,你想要跟上一节一样把Fare栏位弄成只有小数点后一位,但又不想影响到其他DataFrame或是其他栏位: 这时候你可以使用
这时候你可以使用pandas Styler底下的format函数来做到这件事情: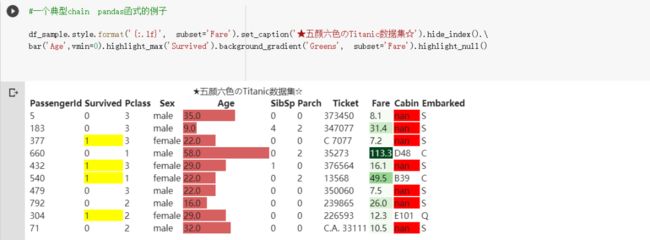 如果你从来没有用过df.style,这应该是你这辈子看过最缤纷的DataFrame。
如果你从来没有用过df.style,这应该是你这辈子看过最缤纷的DataFrame。
从上而下,上述代码对此DataFrame 做了以下styling:
将
Fare栏位的数值显示限制到小数后第一位添加一个标题辅助说明
隐藏索引(注意最左边!)
将
Age栏位依数值大小画条状图将
Survived最大的值highlight将
Fare栏位依数值画绿色的colormap将整个DataFrame 的空值显示为红色
pd.DataFrame.style会回传一个Styler,你已经看到除了format函数以外,还有很多其他函数可以让你为DataFrame添加样式。使用format函数的最大好处是你不需要用像是round等函数去修改实际数值,而只是改变呈现结果而已。
熟悉styling技巧能让你不需画图就能轻松与他人分享简单的分析结果,也能凸显你想让他们关注的事物。「小提醒」:为了让你能一次掌握常用函数,我把能加的样式都加了,实际上你应该思考什么视觉样式是必要的,而不是盲目地添加样式。
另外值得一提的是pandas 函数都会回传处理后的结果,而不是直接修改原始DataFrame。这让你可以轻松地把多个函式串(chain)成一个复杂的数据处理pipeline,但又不会影响到最原始的数据: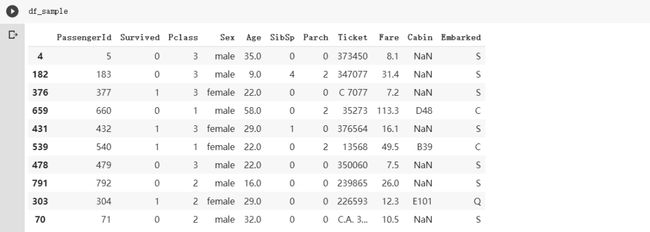 瞧!原来的DataFrame还是挺淳朴的,注意
瞧!原来的DataFrame还是挺淳朴的,注意Fare栏位里的小数点并没有因为刚刚的styling而变少,而这让你在呈现DataFrame时有最大的弹性。
本期pandas之旅到此结束,敬请期待下一期![]()
本文参考资料:[1]pandas官方文件里查看其他常用的显示设定: https://pandas.pydata.org/pandas-docs/stable/user_guide/options.html#frequently-used-options
- END -
转自:NewBeeNLP 公众号;
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
END
合作请加QQ:365242293
数据分析(ID : ecshujufenxi )互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。
