Hive 3.1.2 数仓基本概念 大致分层
数据仓库的基本概念
数据库和数据仓库的区别:
数据库 On-Line Transaction Processing(OLTP):存储数据的仓库 一般用于事务操作,主要是用于捕获数据 要求延迟性较低
数据仓库 On-Line Analytical Processing(OLAP):存储数据的仓库 ,面向于主题(分析)的,一般是保存过去的历史数据,主要是对这些数据进行统计分析,对未来提供决策支持,一般对延迟没有特备要求
- 何为数据分析呢?
指的从数据容器中,根据需求要求获取相关的数据的过程(数据查询操作)
一般使用什么工具进行数据分析呢? SQL
会SQL的人一般比会任何其他语言的人多
- 什么是数据仓库?
数据仓库就是面向于分析 主要是用于保存过去的历史数据对这些数据进行统计分析处理 从而对未来提供决策支持
可以把数据仓库比作粮仓
思考1: 粮仓自己是否会生产粮食
不会的, 粮食一般来源于全国各地
思考2: 粮仓是否会消耗粮食
粮仓自己并不会消耗粮食
-
数仓的最大特点
-
数仓本身不生产数据 也不消耗数据 数据来源于各个数据源
-
-
数据仓库的四大特征
- 面向于主题(分析)的:主题指的分析的目标
- 继承性:数据都是来源于各个数据源的,将各个数据源的数据集中防止在一起
- 非易失性(稳定性):由于存储的是过去既定发生的数据,这些数据一般不允许出现变更
- 时变性:随着时间的推移,原有的分析方案可能无法满足未来的需求,此时需要变更,同时数据也会出现新增操作
数据库和数据仓库区别
数据库(OLTP 联机事务处理): 面向于业务 用于捕获数据 延迟性比较低 数据构建尽量避免冗余发生
数据仓库(OLAP 联机分析处理 ): 面向于主题(分析), 存储过去既定发生的历史数据 对延迟性没有要求 允许出现冗余
首先要明白,数据仓库的出现 并不是为了取代数据库
- 数据库是面向于事务的设计,数据仓库是面向于主题设计的。
- 数据库一般存储业务数据,数据仓库存储的一般是历史数据。
- 数据库设计是尽量避免冗余,一般针对某一业务应用进行设计,比如一张简单的user表,记录用户名、密码等简单数据即可,符合业务应用,但是不符合分析。数据仓库在设计是有意引入冗余,依照分析需求、分析维度、分析指标进行设计
- 数据库是为捕获数据而设计,数据仓库是为分析数据而设计。
- 数据仓库 是在数据库已经大量存在的情况下 为了进一步挖掘数据资源 为了决策需要而产生的 它绝不是所谓的“大型数据库”。
数据仓库的分层设计和ETL介绍
为什么要进行数仓分层呢?
- 利于维护管理
- 提供开发效率
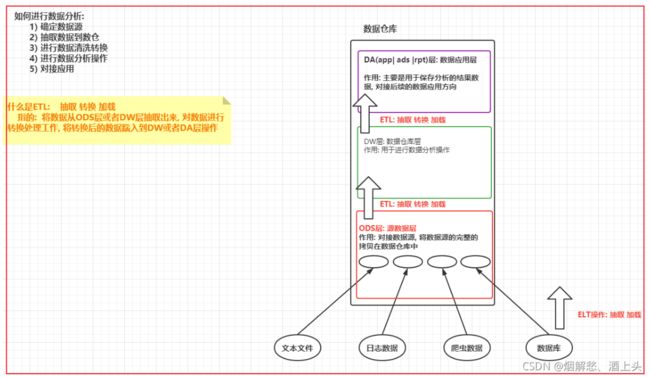
根据上图总结
数据仓库的分层:
ODS层:源数据层
作用: 对接数据源,一般会和数据源保持相同的粒度,完整的数据源的数据拷贝到ODS层中
DW层:数据仓库层
作用:进行数据分析处理工作
DA层:数据应用层
作用:存储DW层分析的结果数据,用于对接后续应用方向
ETL(抽取Extract,转换Transform,加载Load)操作:不管是在DW层 还是DA层都是存在的
基本流程:
1、数据从ODS层抽取出来,对ODS层数据进行清洗转换处理工作,将清洗转换处理后的数据加载到DW层操作
2、数据从DW层抽取出来,对DW层数据进行统计分析处理工作,将处理后的是数据加载到DA层操作
ELT操作:ETL包含ELT
基本流程:
数据从各个数据源中被抽取出来,直接灌入到DW层的过程
ETL工程师:主要从事将数据源的数据灌入到ODS以及再次灌入到DW层操作,甚至包括灌入到DA层
数仓分析工程师:进行DW分析处理工作
Apache Hive 基本介绍
hive是隶属于Apache软件基金会的一员, 是apache的顶级项目(http://hive.apache.org), hive是基于hadoop, 意味着如果要使用hive, 必须要先安装并启动好hadoop集群
hive是一个数据仓库的工具, 可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
本质是将SQL转换为MapReduce程序, 意味着分析的时效性较差
应用场景: 进行离线数据分析
hive其实就是一个翻译软件, 将SQL翻译成MR操作, 而对于使用者, 无需关系底层翻译过程, 只需要会写SQL即可
hive的架构
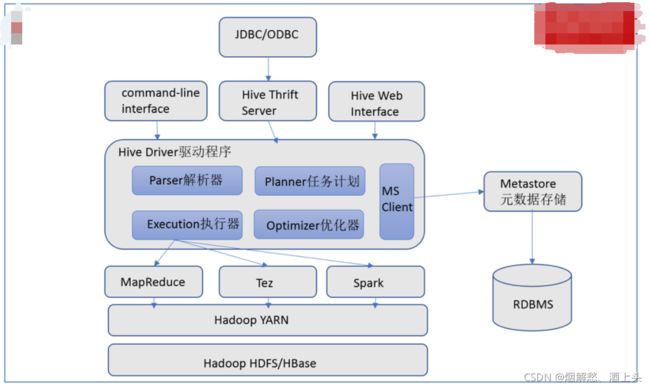
对架构的解释
客户端: 命令行客户端, thrift Server, web
后期主要采用命令行客户端 和 thrift Server
hive服务:
解释器: 客户端传递过来SQL后, 首先通过解释器对SQL的语法已经数据进行校验处理
解析器: 将SQL进行编译处理, 生产执行计划(先执行什么, 然后执行什么, 怎能处理, 数据在哪里, 量有多少)
优化器: 对解析器生成的执行计划进行优化处理
执行器: 将执行计划默认翻译为MapReduce, 将MR提交给YARN集群,后续执行器监控状态 获取结果
元数据服务: 在hive中, 创建库, 创建表, 表有那些字段, 字段类型, 数据从哪里读... 这些都是元数据
hive仅仅是一款工具, 并不负责任何数据的存储, 元数据存储需要依赖于数据库来存储, 默认的数据库是derby,
生产中一般会选择外部数据库比如MySQL
hive专门提供了一个用于和元数据打交道的服务: metastore服务
整个hive: 数据读取一般都是来源于HDFS, 数据计算一般是有MR计算, 交由给yarn提供资源
可以说, hive和hadoop是一个强依赖的关系
hive:主要是进行离线化 批量化数据处理操作
hive的安装操作
hive的部署三种模式:
- 内嵌模式
指的: 将metastore服务和hive服务内嵌在一起, 无需单独启动metastore服务项,随着客户端的启动而启动,同时在内嵌模式下, 采用元数据库为derby数据库
好处: 安装简单, 解压即可用
弊端: 在不同路径下启动hive, 都会单独形成一个derby数据库, 导致元数据无法共享, 会出现脑裂问题
说明: 此种模式在实际生产中, 基本不会见到
- 本地模式
指的: 将metastore服务和hive的服务内嵌在一起, 无需单独启动metastore服务项,随着客户端的启动而启动,但是可以自由选择元数据库, 一般会选择第三方mysql数据库作为元数据存储
好处: 部署相对简单, 而且避免脑裂问题
弊端: 每一次启动hive, 都会同时启动一个metastore的服务项, 导致数据库连接增多, 占用资源, 对mysql影响不好
说明: 此种模式一般在测试环境中使用
- 远程模式
指的: 将metastore服务和hive服务都独立出来, 形成两个单独独立的服务项,
分别为 metastore 和 hiveserver2服务, 这两个服务是可以单独部署启动 长期挂载在后台,
后续客户端就可以通过hive服务进行连接操作, 而且客户端可以在任意的节点上,
以及后续一些其他的软件需要依赖于hive, 主要依赖的也是metastore服务项
好处: 支持远程连接, 只需要启动一次即可 , 方便和其他软件进行集成
弊端: 安装较为繁琐一些
说明: 此种模式是后续以及生产环境中主要采用模式
安装操作
- 第一步:修改hadoop的 core-site.xml中 ,添加一下内容:
#修改hadoop 配置文件 etc/hadoop/core-site.xml,加入如下配置项
<property>
<name>hadoop.proxyuser.root.hostsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.root.groupsname>
<value>*value>
property>
注意: 如果发现没有配置, 请将其添加到core-site.xml中, 添加后, 记得发给其他节点
- 第二步: 上传hive的安装包到node1的节点, 并解压
cd /export/software/
rz 上传即可
说明: 如果提示 -bash: rz: 未找到命令 请执行以下命令安装即可:
yum -y install lrzsz
执行解压:
tar -zxf apache-hive-3.1.2-bin.tar.gz -C /export/server/
cd /export/server
mv apache-hive-3.1.2-bin/ hive-3.1.2

- 第三步: 修改 hive的环境配置文件: hive-env.sh
cd /export/server/hive-3.1.2/conf
cp hive-env.sh.template hive-env.sh
vim hive-env.sh
输入 i
修改一下内容:
# 配置hadoop的家目录
HADOOP_HOME=/export/server/hadoop-3.3.0/
# 配置hive的配置文件的路径
export HIVE_CONF_DIR=/export/server/hive-3.1.2/conf/
# 配置hive的lib目录
export HIVE_AUX_JARS_PATH=/export/server/hive-3.1.2/lib/
配置后保存退出即可:
esc
:wq
- 第四步: 添加一个hive的核心配置文件: hive-site.xml
cd /export/server/hive-3.1.2/conf
vim hive-site.xml
输入i
添加以下内容:
<configuration>
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://node2:3306/hive3?createDatabaseIfNotExist=true&useSSL=falsevalue>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.jdbc.Drivervalue>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>hadoopvalue>
property>
<property>
<name>hive.server2.thrift.bind.hostname>
<value>node2value>
property>
<property>
<name>hive.metastore.urisname>
<value>thrift://node2:9083value>
property>
<property>
<name>hive.metastore.event.db.notification.api.authname>
<value>falsevalue>
property>
configuration>
添加后, 保存退出即可:
esc
:wq
- 第五步: 上传mysql的驱动包到hive的lib目录下
cd /export/server/hive-3.1.2/lib
rz 上传即可
上传后, 校验是否已经上传到lib目录下

- 第六步: 解决Hive与Hadoop之间guava版本差异
cd /export/server/hive-3.1.2/
rm -rf lib/guava-19.0.jar
cp /export/server/hadoop-3.3.0/share/hadoop/common/lib/guava-27.0-jre.jar ./lib/
如果此步没有执行, 可能会报出如下错误:
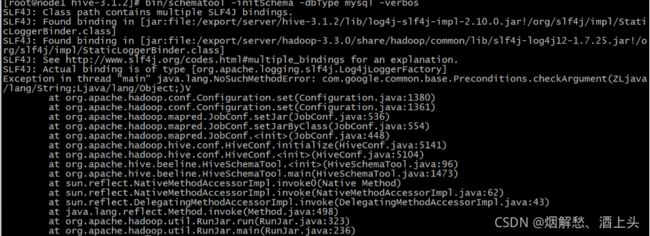
- 第七步: 初始化元数据
cd /export/server/hive-3.1.2/
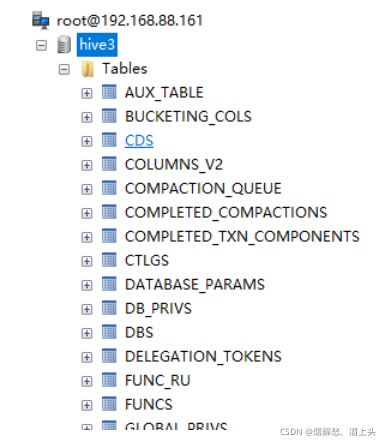
bin/schematool -initSchema -dbType mysql -verbos
执行完成后, 可以看到在mysql的hive3的数据库中, 会产生74张元数据表
可能出现的错误:
root @ node1 (passwd no) 类似于这样的一个错误
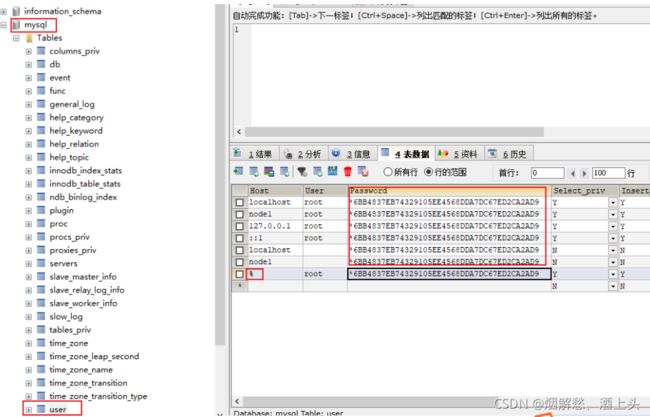
出现的原因: 由于mysql的密码不对导致的
在mysql的 mysql数据库中有一个user表, 打开user表后, 找到password, 将 Host为%的password的免密内容拷贝到其他行中, 保证大家都一样即可
拷贝后, 如下图, 然后就可以在Linux中重启mysql
重启命令:
service mysqld restart
或者
service mysql restart
或者
systemctl restart mysqld.service
或者
systemctl restart mysql.service
- 第八步: 创建HDFS的hive相关的目录
hadoop fs -mkdir /tmp
hadoop fs -mkdir -p /user/hive/warehouse
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse
如何启动
- 第一步 先启动hadoop集群
启动命令:
node1执行 start-all.sh
启动后, 要确保hadoop是启动良好的
首先通过jps分别查看每一个节点:
在node1节点:
namenode
datanode
resourcemanager
nodemanager
在node2节点:
SecondaryNameNode
datanode
nodemanager
在node3节点:
datanode
nodemanager
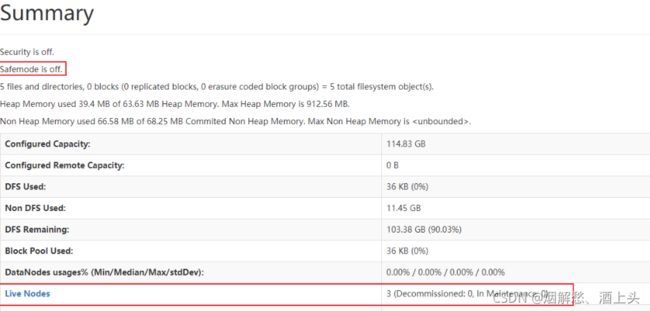
接着通过浏览器, 访问 node1:9870 查看 安全模式是否退出以及是否有3个datanode
最后,通过浏览器,访问 node1:8088 查看是否有三个激活节点

- 第二步: 启动 hive的服务: metastore
先启动metastore服务项:
前台启动:
cd /export/server/hive-3.1.2/bin
./hive --service metastore
注意: 前台启动后, 会一直占用前台界面, 无法进行操作
好处: 一般先通过前台启动, 观察metastore服务是否启动良好
前台退出: ctrl + c
后台启动:
当前台启动没有任何问题的时候, 可以将其退出, 然后通过后台启动, 挂载后台服务即可
cd /export/server/hive-3.1.2/bin
nohup ./hive --service metastore &
启动后, 通过 jps查看, 是否出现一个runjar 如果出现 说明没有问题(建议搁一分钟左右, 进行二次校验)
注意: 如果失败了, 通过前台启动, 观察启动日志, 看一下是什么问题, 尝试解决
后台如何退出:
通过 jps 查看进程id 然后采用 kill -9
- 第三步: 启动hive的服务: hiveserver2服务
接着启动hiveserver2服务项:
前台启动:
cd /export/server/hive-3.1.2/bin
./hive --service hiveserver2
注意: 前台启动后, 会一直占用前台界面, 无法进行操作
好处: 一般先通过前台启动, 观察hiveserver2服务是否启动良好
前台退出: ctrl + c
后台启动:
当前台启动没有任何问题的时候, 可以将其退出, 然后通过后台启动, 挂载后台服务即可
cd /export/server/hive-3.1.2/bin
nohup ./hive --service hiveserver2 &
启动后, 通过 jps查看, 是否出现一个runjar 如果出现 说明没有问题(建议搁一分钟左右, 进行二次校验)
注意: 如果失败了, 通过前台启动, 观察启动日志, 看一下是什么问题, 尝试解决
后台如何退出:
通过 jps 查看进程id 然后采用 kill -9
如何连接
- 第一种连接方式: 通过 hive原生客户端 (此种不需要掌握, 只是看看)
cd /export/server/hive-3.1.2/bin
./hive
- 第二种连接方式: 基于beeline的连接方式
cd /export/server/hive-3.1.2/bin
./beeline --进入beeline客户端
连接hive:
!connect jdbc:hive2://node1:10000
接着输入用户名: root
最后输入密码: 无所谓(一般写的都是虚拟机的登录密码)
- 演示远程连接操作
1) 将node1的hive的安装目录发送给需要远程连接的节点
cd /export/server/
scp -r hive-3.1.2/ node2:$PWD
scp -r hive-3.1.2/ node3:$PWD
2) 比如 使用 node2连接node1的hive服务
以下操作是在node2执行的:
cd /export/server/hive-3.1.2/bin
./beeline
连接hive:
!connect jdbc:hive2://node1:10000
接着输入用户名: root
最后输入密码: 无所谓(一般写的都是虚拟机的登录密码)
其他节点连接也是雷同的
请注意注意注意:
一定一定一定不要在node2和node3启动hive服务
hive的初体验
1. hive 映射
- hive可以将hdfs中结构化的文件数据在hive 中映射成为一个表,然后可以通过类SQL的方式进行查询处理
- 思考:什么是结构化数据呢?
结构化数据:
这个文件中数据具有相同列,每一列的数据类型都是固定的,类似于mysql的表
半结构的数据
文件中数据每一行都是有一定的格式,但是没一行的格式可能会不同,
将这种数据称为半结构的数据 类似于 XML文件 、HTML文件。
非结构化数据: 数据本身没有任何结构,比如文本数据 或者视频数据 图片。。。。。
2.需求: 请将以下数据在hive中映射称为一个表
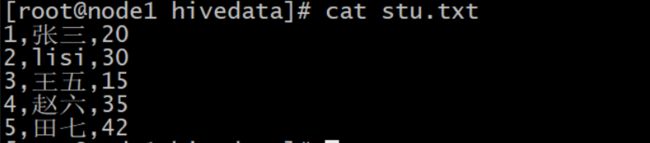
数据内容: stu.txt
1,张三,20
2,lisi,30
3,王五,15
4,赵六,35
5,田七,42
- 第一步:将这个文件上传到HDFS中
mkdir -p /root/hivedate
cd /root/hivadate
vim stu.txt
添加以下内容
1,张三,20
2,lisi,30
3,王五,15
4,赵六,35
5,田七,42
上传到hdfs的根目录下
hdfs dfs -put stu.txt /
- 第二步: 在hive中创建一个表
create table stu(
sid int,
sname string,
age int
);
当在hive中创建一张表 本质是在HDFS的 /user/hive/warehouse 目录下 创建一个同名目录
揣测应该将数据放置在stu对应的hdfs的目录下
- 查看数据
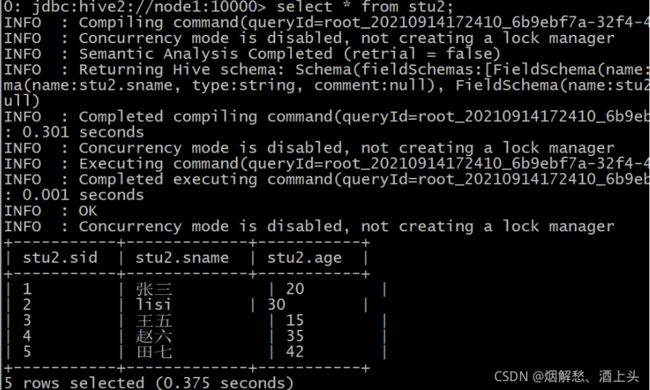
select * from stu;
- 第三步: 将stu.txt拷贝到HDFS的/user/hive/warehouse/stu目录下, 再次查看数据
拷贝操作
hdfs dfs -cp /stu.txt /user/hive/warehouse/stu
查看数据
select * from stu;
发现个问题,好像是映射成功了 但是数据无法显示。
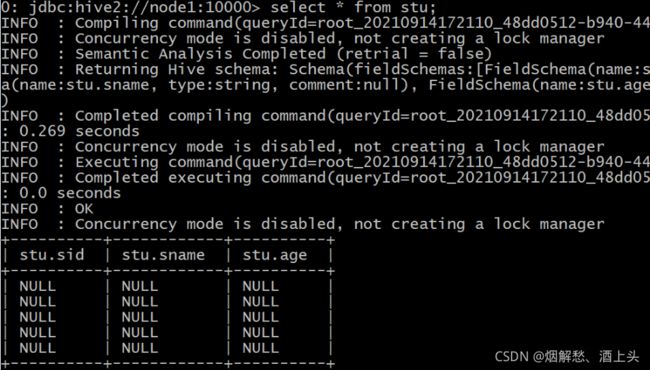
- 第四步: 再次创建一个表
create table stu2(
sid int,
sname string,
sage int
)row format delimited fields terminated by ',';
将stu.txt数据也拷贝到stu2对应hdfs的目录下:
hdfs dfs -cp /stu.txt /user/hive/warehouse/stu2
- 第五步: 查看stu2的数据
select * from stu2;