LeetBook哈希表专题题解(详解/一题多解)
哈希表
文章目录
- 哈希表
-
- 设计哈希表
-
- 设计哈希集合(set)
-
- (超大数组法)
- (拉链法1(list实现))
- (拉链法2(模拟实现单链表+虚拟头节点))
- (拉链法3(模拟单链表不叫虚拟头节点))
- 设计哈希映射
-
- (超大数组法)
- (拉链法1 vector+list+pair)
- (拉链法2 vector+ListNode*)
- (拉链法3 vector + ListNode*)
- (面试写拉链法)
- (带有虚拟头结点的拉链法)
- (开放寻址法)
- 实际应用-哈希集合
-
- 存在重复元素
-
- (multiset)
- (set1)
- (set2)
- (sort)
- 只出现一次的数字
-
- (异或)
- (multiset)
- (set)
- 两个数组中的交集(广义set)
-
- (哈希表unordered_set)
- (排序+二分)
- (排序+双指针)
- 快乐数
-
- (哈希unordered_set)
- (快慢指针)
- 哈希映射-提供更多信息
-
- 两数之和
-
- (暴力法)
- (哈希表1)
- (哈希表2)
- 同构字符串
-
- (双哈希+双射)
- (双哈希+索引)
- (用find()找索引)
- 两个列表的最小索引总和
-
- (哈希表+unordered_map排序)
- (哈希表+min_sum标记)
- 哈希映射-按键聚合
-
- 字符串中第一个唯一字符
-
- (哈希表)
- (find()函数找索引值)
- 两个数组的交集Ⅱ(狭义)
-
- (哈希表1Array)
- (哈希表2unordered_map)
- (查找)
- (排序+双指针)
- 存在重复元素Ⅱ
-
- (哈希表unordered_map)
- (哈希表ordered_set)
- 设计键值(key)
-
- 字母异位词分组
- (哈希表unordered_map1)
- (哈希表unordered_map2)
- 有效数独
-
- (哈希表判重)
- (用数组记录判重)
- 寻找重复子树
-
- (哈希表unordered_map记录路径)
- 如何设计键-总结
- 小结哈希表
-
- 宝石与石头
-
- (哈希表unordered_set)
- 无重复字符的最长子串
-
- (双指针+哈希表+滑动窗口1)
- (哈希表+局部双指针+滑动窗口2)
- (数组模拟哈希表)
- 四数相加Ⅱ
-
- (哈希表)
- 前K个高频元素(TopK问题)
-
- (大根堆堆+哈希表)O(N + KlogN)
-
- (堆(优先队列)的使用方法):
- (小根堆 + 哈希表)O(Nlogk)(k为堆的大小)
- (sort排序+哈希表)O(NlogN)
- (桶排序+哈希表)
- (*快排 + 哈希表)
设计哈希表
设计哈希集合(set)
(超大数组法)
class MyHashSet {
private:
vector<bool> table;
public:
/** Initialize your data structure here. */
MyHashSet(): table(1e6 + 1, false) {}
void add(int key) {
table[key] = true;
}
void remove(int key) {
table[key] = false;
}
/** Returns true if this set contains the specified element */
bool contains(int key) {
return table[key];
}
};
空间复杂度:O(N)
时间复杂度:O(1)
(拉链法1(list实现))
class MyHashSet {
private:
int prime;
vector<list<int>> table;
// 找到数字在哈希表中映射的下标(哈希桶)
int hash(int key){
return key % prime;
}
// 返回key值在哈希桶中的位置
list<int>::iterator search(int key) {
int loc = hash(key);
return find(table[loc].begin(), table[loc].end(), key);
}
public:
/** Initialize your data structure here. */
MyHashSet():prime(10007), table(prime) {}
void add(int key) {
// 找到key对应的哈希桶
// 如果哈希桶中没有key值就将key插入
int loc = hash(key);
if (!contains(key))
table[loc].push_back(key);
}
void remove(int key) {
// 找到key值对应的哈希桶
// 在找到哈希桶中key的位置
int loc = hash(key);
auto it = search(key);
if (it != table[loc].end())
table[loc].erase(it);
}
/** Returns true if this set contains the specified element */
bool contains(int key) {
// 找到key对应的哈希桶
// 如果key值对应的位置再哈希桶中可以找到就返回true
int loc = hash(key);
return search(key) != table[loc].end();
}
};
如果所有的数字都映射到同一个哈希桶中的时候,这时候时间复杂度就是O(N)的,但是如果哈希桶的数量足够大,因而每一个哈希桶上的链表的个数不是很多的时候,平均的时间复杂度为O(1).
时间复杂度:O(N),平均时间复杂度:O(1)
空间复杂度:O(prime)
(拉链法2(模拟实现单链表+虚拟头节点))
class MyHashSet {
private:
// 单链表的结点
struct ListNode{
int key;
ListNode* next;
ListNode(int key):key(key), next(nullptr) {}
ListNode():key(-1), next(nullptr) {}
};
int prime;
vector<ListNode*> table;
// 返回key值对应的哈希桶
int hash(int key) {
return key % prime;
}
public:
// 将table的哈希桶中初始化只有一个val=-1的结点的链表
MyHashSet():prime(1007), table(prime, new ListNode) {}
void add(int key) {
// 找到key对应的哈希桶
int loc = hash(key);
// 如果没有key值才将key插入到哈希桶中
if (!contains(key)) {
ListNode* cur = table[loc];
// 找到哈希桶中的单链表的尾巴
while (cur->next != nullptr) {
cur = cur->next;
}
ListNode* newNode = new ListNode(key);
cur->next = newNode;
}
}
void remove(int key) {
int loc = hash(key);
ListNode* cur = table[loc];
// 如果哈希桶中有key值才能将key值删除
if (contains(key)) {
// 找到val值等于key的结点然后删除
while (cur->next->key != key) {
cur = cur->next;
}
ListNode* delNode = cur->next;
cur->next = cur->next->next;
delete delNode;
}
}
/** Returns true if this set contains the specified element */
bool contains(int key) {
int loc = hash(key);
ListNode* cur = table[loc];
// 遍历哈希桶中的单链表查看是否有val==key的结点
while (cur != nullptr) {
if (cur->key == key) return true;
cur = cur->next;
}
return false;
}
};
因为有虚拟头结点,所以在add()和remove()函数就不会改变链表的头结点了(被虚拟头结点占用了),所以对待所有的结点都可以想普通结点一样处理就可以了,但是这种方法对空间有消耗。
(拉链法3(模拟单链表不叫虚拟头节点))
class MyHashSet {
private:
// 单链表的结点
struct ListNode{
int key;
ListNode* next;
ListNode(int key):key(key), next(nullptr) {}
};
int prime;
vector<ListNode*> table;
// 返回key值对应的哈希桶
int hash(int key) {
return key % prime;
}
public:
MyHashSet():prime(1007), table(prime) {}
void add(int key) {
// 找到key对应的哈希桶
int loc = hash(key);
// 如果没有key值才将key插入到哈希桶中
if (!contains(key)) {
ListNode* cur = table[loc],*prev = nullptr;
// 特判一下头节点是否为空
if (cur == nullptr) {
table[loc] = new ListNode(key);
return;
}
// 找到哈希桶中的单链表的尾巴
while (cur->next != nullptr) {
cur = cur->next;
}
cur->next = new ListNode(key);
}
}
void remove(int key) {
int loc = hash(key);
ListNode* cur = table[loc];
// 如果哈希桶中有key值才能将key值删除
if (contains(key)) {
// 如果结点的第一个结点就是有key值的节点
if (cur->key == key) {
table[loc] = cur->next;
delete cur;
} else {// 找到key值等于key的结点然后删除
while (cur->next->key != key) {
cur = cur->next;
}
ListNode* delNode = cur->next;
cur->next = cur->next->next;
delete delNode;
}
}
}
/** Returns true if this set contains the specified element */
bool contains(int key) {
int loc = hash(key);
ListNode* cur = table[loc];
// 遍历哈希桶中的单链表查看是否有val==key的结点
while (cur != nullptr) {
if (cur->key == key) return true;
cur = cur->next;
}
return false;
}
};
如果不加虚拟头节点的话需要在add()函数和remove()函数加上一个对头节点的增上的特判。
在add()函数中需要判断2中情况 1.链表为空节点 (添加是需要改变链表头)。2链表有结点.
在remove()函数中需要判断3中情况1.链表没有结点 2.链表中只有一个结点 (删除是需要改变链表头)3.有一个及以上的结点
设计哈希映射
(超大数组法)
class MyHashMap {
private:
int N = 1e6 + 1;
int* table = new int[N];
public:
/** Initialize your data structure here. */
MyHashMap() {
fill(table, table + N, -1);
}
/** value will always be non-negative. */
void put(int key, int value) {
table[key] = value;
}
/** Returns the value to which the specified key is mapped, or -1 if this map contains no mapping for the key */
int get(int key) {
return table[key];
}
/** Removes the mapping of the specified value key if this map contains a mapping for the key */
void remove(int key) {
table[key] = -1;
}
};
/**
* Your MyHashMap object will be instantiated and called as such:
* MyHashMap* obj = new MyHashMap();
* obj->put(key,value);
* int param_2 = obj->get(key);
* obj->remove(key);
*/
(拉链法1 vector+list+pair)
class MyHashMap {
private:
int prime;
vector<list<pair<int, int>>> table;
int hash(int key) {
return key % prime;
}
list<pair<int, int>>::iterator search(int key) {
int loc = hash(key);
auto it = find_if(table[loc].begin(), table[loc].end(), [key](pair<int, int> x) {
return x.first == key;
});
return it;
}
public:
/** Initialize your data structure here. */
MyHashMap() :prime(1007), table(prime) {}
/** value will always be non-negative. */
void put(int key, int value) {
int loc = hash(key);
auto it = search(key);
if (it != table[loc].end()) {
it->second = value;
}
else {
table[loc].push_back({ key, value });
}
}
/** Returns the value to which the specified key is mapped, or -1 if this map contains no mapping for the key */
int get(int key) {
int loc = hash(key);
auto it = search(key);
if (it != table[loc].end()) {
return it->second;
}
else {
return -1;
}
}
/** Removes the mapping of the specified value key if this map contains a mapping for the key */
void remove(int key) {
int loc = hash(key);
auto it = search(key);
if (it != table[loc].end()) {
table[loc].erase(it);
}
}
};
这题需要用到lambda表达式,就是在哈希桶中的链表寻找{key, value}的时候需要用到,因为map是二元组,所以list中的结点也是pair二元组来实现的。
那么问题来了,虽然pair之间可以比较大小,但是在put函数中需要找到key值相同的pair,如果找到就将value值修改掉,如果没找到就就添加一个pair,但是在使用find函数的时候只能用key值去比较,不能用key和pair去比较。
这时候就需要用到find_if函数,就是将限定好的满足要求的对象找到,这就可以自己定义了。可以用bool函数写一个比较函数,但是又有一个问题就是key值是函数中的参数不是list中的元素pair的参数,在写比较函数的时候怎么知道要和函数外的参数key值去比较呢?所以这是就只能用lambda表达式,[临时参数](参数列表) {函数体}可以在[]中写好临时变量key然后在参数列表中写出容器中的元素类型声明,最后函数体中将每一个函数参数(pair中的元素)和key比较,就可以了
(拉链法2 vector+ListNode*)
这种方法将方法讲的比较详细
class MyHashMap {
private:
struct ListNode {
int key, val;
ListNode* next;
ListNode():key(-1), val(-1), next(nullptr) {}
ListNode(int key, int val):key(key),val(val),next(nullptr) {}
};
int prime;
vector<ListNode*> table;
int hash(int key) {
return key % prime;
}
public:
/** Initialize your data structure here. */
MyHashMap():prime(10007), table(prime) {}
/** value will always be non-negative. */
void put(int key, int value) {
int loc = hash(key);
ListNode* cur = table[loc];
// 如果哈希桶中的链表有结点的话,去修改对应key值结点的value
if (cur != nullptr) {
ListNode* prev = nullptr;// 设置一个结点的前结点
while (cur != nullptr) {
if (cur->key == key) {
cur->val = value;
return ;
}
prev = cur;
cur = cur->next;
}
cur = prev;
}
ListNode* newNode = new ListNode(key, value);
// 尾插法
// // 如果哈希桶中的链表有结点,就让结点接在链表最后
// if (cur != nullptr) {
// cur->next = newNode;
// } else {// 链表中没有结点,就将哈希桶第一个结点设置为newNode
// table[loc] = newNode;
// }
// 头插法
newNode->next = table[loc];
table[loc] = newNode;
}
/** Returns the value to which the specified key is mapped, or -1 if this map contains no mapping for the key */
int get(int key) {
int loc = hash(key);
ListNode* cur = table[loc];
if (cur != nullptr) {
while (cur != nullptr) {
if (cur->key == key) {
return cur->val;
}
cur = cur->next;
}
}
return -1;
}
/** Removes the mapping of the specified value key if this map contains a mapping for the key */
void remove(int key) {
int loc = hash(key);
ListNode* cur = table[loc];
if (cur != nullptr) {
ListNode* prev = nullptr;
while (cur != nullptr) {
if (cur->key == key) {
ListNode* delNode = cur;
if (prev == nullptr) {// 链表的头结点值就是key值,哈希桶的头就要改变
table[loc] = cur->next;
} else {// 链表中不止一个结点
prev->next = cur->next;
}
delete delNode;
return ;
}
prev = cur;
cur = cur->next;
}
}
}
};
(拉链法3 vector + ListNode*)
这种方式比较暴力
class MyHashMap {
private:
struct ListNode {
int key, val;
ListNode* next;
ListNode(int k, int v) :key(k), val(v), next(nullptr) {}
};
int prime = 10007;
ListNode* table[10007] = { nullptr };
int hash(int key) {
return key % prime;
}
public:
/** Initialize your data structure here. */
MyHashMap() {
}
/** value will always be non-negative. */
void put(int key, int value) {
remove(key);
int loc = hash(key);
ListNode* newNode = new ListNode(key, value);
newNode->next = table[loc];
table[loc] = newNode;
}
/** Returns the value to which the specified key is mapped, or -1 if this map contains no mapping for the key */
int get(int key) {
int loc = hash(key);
ListNode* cur = table[loc];
while (cur != nullptr) {
if (cur->key == key) {
return cur->val;
}
cur = cur->next;
}
return -1;
}
/** Removes the mapping of the specified value key if this map contains a mapping for the key */
void remove(int key) {
int loc = hash(key);
ListNode* cur = table[loc];
if (cur == nullptr) return;
else if (cur->key == key) {
table[loc] = cur->next;
delete cur;
return;
} else {
while (cur->next != nullptr) {
if (cur->next->key == key) {
ListNode* delNode = cur->next;
cur->next = cur->next->next;
delete delNode;
return;
}
cur = cur->next;
}
}
}
};
(面试写拉链法)
class MyHashMap {
private:
struct ListNode {
int key, val;
ListNode* next;
ListNode():key(-1), val(-1), next(nullptr) {};
ListNode(int k, int v):key(k), val(v), next(nullptr) {}
};
int prime;
vector<ListNode*> table;
int hash(int key) {
return key % prime;
}
public:
/** Initialize your data structure here. */
MyHashMap():prime(1007), table(prime) {}
/** value will always be non-negative. */
void put(int key, int value) {
int loc = hash(key);
auto& head = table[loc];
// 如果链表中没有结点
if (head == nullptr) {
head = new ListNode(key, value);
return ;
}
// 如果链表中有结点尾插法
// 1.如果有key值结点就修改结点的val
// 2.如果没有key值结点就在链表最后添加一个结点
ListNode* cur = head, * prev = nullptr;
while (cur != nullptr) {
if (cur->key == key) {// 1
cur->val = value;
return ;
}
prev = cur;
cur = cur->next;
}
// 2
prev->next = new ListNode(key, value);
}
/** Returns the value to which the specified key is mapped, or -1 if this map contains no mapping for the key */
int get(int key) {
int loc = hash(key);
auto& head = table[loc];
// 遍历链表找key值为key的结点
ListNode* cur = head;
while(cur != nullptr) {
if (cur->key == key) {
return cur->val;
}
cur = cur->next;
}
return -1;
}
/** Removes the mapping of the specified value key if this map contains a mapping for the key */
void remove(int key) {
int loc = hash(key);
auto& head = table[loc];
// 如果没有结点直接返回void
if (head == nullptr)
return ;
// 如果有结点就找key值为key的结点
ListNode* cur = head, *prev = nullptr;
while (cur != nullptr) {
if (cur->key == key) {
// 如果链表的头结点就是key值结点,则头结点需要移动
if (prev == nullptr) {
ListNode* delNode = cur;
head = head->next;
delete delNode;
} else {// 如果中间结点是key值结点就直接跳过该节点
prev->next = cur->next;
delete cur;
}
return;
}
prev = cur;
cur = cur->next;
}
}
};
不加虚拟头结点需要在头结点的增删是做特判
在put()函数中需要判断2中情况 1.链表为空节点 (添加是需要改变链表头)。2链表有结点.(正常处理)
在remove()函数中需要判断3中情况1.链表没有结点 (直接返回void)2.链表中只有一个结点 (删除是需要改变链表头)3.有一个及以上的结点(正常处理)
(带有虚拟头结点的拉链法)
class MyHashMap {
struct ListNode {
int val, key;
ListNode* next;
ListNode():val(-1), key(-1), next(nullptr) {}
ListNode(int k, int v):val(v), key(k), next(nullptr) {}
};
int prime;
vector<ListNode*> table;
int hash(int key) {
return key % prime;
}
public:
/** Initialize your data structure here. */
MyHashMap():prime(1007), table(prime, new ListNode) {}
// 将哈希桶都设置成虚拟头结点
/** value will always be non-negative. */
void put(int key, int value) {
int loc = hash(key);
auto& head = table[loc];
ListNode* cur = head->next, *prev = head;
while (cur != nullptr) {
if (cur->key == key) {
cur->val = value;
return ;
}
prev = cur;
cur = cur->next;
}
prev->next = new ListNode(key, value);
}
/** Returns the value to which the specified key is mapped, or -1 if this map contains no mapping for the key */
int get(int key) {
int loc = hash(key);
auto& head = table[loc];
ListNode* cur = head->next;
while (cur != nullptr) {
if (cur->key == key) {
return cur->val;
}
cur = cur->next;
}
return -1;
}
/** Removes the mapping of the specified value key if this map contains a mapping for the key */
void remove(int key) {
int loc = hash(key);
auto& head = table[loc];
ListNode* cur = head->next, *prev = head;
while (cur != nullptr) {
if (cur->key == key) {
prev->next = cur->next;
delete cur;
return;
}
prev = cur;
cur = cur->next;
}
}
};
(开放寻址法)
class MyHashMap {
private:
const static int N = 20011;
vector<pair<int, int>> table;
public:
/** Initialize your data structure here. */
MyHashMap():table(N, {-1, -1}) {}
int find(int key) {
int k = key % N;
// 没有用过该节点并且没有绕一圈
while (table[k].first != -1 && table[k].first != key) {
k = (k + 1) % N;
}
return k;
}
/** value will always be non-negative. */
void put(int key, int value) {
int loc = find(key);
table[loc] = {key, value};
}
/** Returns the value to which the specified key is mapped, or -1 if this map contains no mapping for the key */
int get(int key) {
int loc = find(key);
if (table[loc].first == -1)
return -1;
return table[loc].second;
}
/** Removes the mapping of the specified value key if this map contains a mapping for the key */
void remove(int key) {
int loc = find(key);
if (table[loc].first != -1)
table[loc].first = -2;// -2是删除的结点,-1是没用过的结点
}
};
这种方法比较费空间,因为删除过后的结点为了和没有用过的结点冲突,所以就不用删除过后的结点了。因为如果删除过后的结点key值变成-1的话那么该节点的所有结点就是去了意义。
实际应用-哈希集合
存在重复元素
题目要求:在数组中是否有重复元素
(multiset)
class Solution {
public:
bool containsDuplicate(vector<int>& nums) {
// 将nums中的数字放到一个可以用重复元素的集合中
multiset<int> vis;
for (auto num : nums) {
vis.insert(num);
}
// 统计数字在集合中的个数
for (auto n : vis) {
if (vis.count(n) > 1)
return true;
}
return false;
}
};
(用multiset可以存放重复元素的特性,并用count()可以统计元素个数的特性)用multiset统计数组中数字个数
(set1)
class Solution {
public:
bool containsDuplicate(vector<int>& nums) {
// 将数组中的数字放到集合中
set<int> vis;
for (int num : nums) {
vis.insert(num);
}
// 比较集合中的元素个数和数组中的元素元素
return vis.size() != nums.size();
}
};
(利用set没有重复元素的特性)用set将重复的元素合并,然后比较集合和原数组中的元素个数
(set2)
class Solution {
public:
bool containsDuplicate(vector<int>& nums) {
set<int> vis;
for (int num : nums) {
// 判断当前的元素是否在集合中出现过
if (vis.count(num))
return true;
// 将数字放到集合中
vis.insert(num);
}
return false;
}
};
(用count()函数判断是否出现过当前的数字)判断集合中是否出现过当前数字,并将出现过得数字放到集合中去
(sort)
class Solution {
public:
bool containsDuplicate(vector<int>& nums) {
// 将数组排序,如果有重复数字就会相邻
sort(nums.begin(), nums.end());
for (int i = 0; i < nums.size() - 1; i ++) {
if (nums[i] == nums[i + 1])
return true;
}
return false;
}
};
只出现一次的数字
(异或)
class Solution {
public:
int singleNumber(vector<int>& nums) {
int ans = 0;
// 两个重复的元素异或之后就变成了0
for (int num : nums) {
ans ^= num;
}
return ans;
}
};
注意:a ^ a = 0,a ^ 0 = a
(multiset)
class Solution {
public:
int singleNumber(vector<int>& nums) {
multiset<int> vis;
for (int num : nums) {
vis.insert(num);
}
for (int v : vis) {
if (vis.count(v) == 1)
return v;
}
return 0;
}
};
用multiset统计数字的个数
(set)
class Solution {
public:
int singleNumber(vector<int>& nums) {
set<int> vis;
for (int num : nums) {
if (vis.count(num))
vis.erase(num);
else
vis.insert(num);
}
return *vis.begin();
}
};
(用set.count()函数统计数字的个数)如果出现过的数字就不再将重复数字添加到结合中去并且将集合中的该数字移除掉,到最后集合中只剩下一个没有重复过的元素
两个数组中的交集(广义set)
(哈希表unordered_set)
用unordered_set不用set的原因是因为:unordered_set的底层是哈希表查找元素的时间是O(1),但是set的底层是rbtree所以时间是O(Nlog2N)时间会慢一点。
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
// 将数组中的数放到集合中,便于用count()统计元素个数
unordered_set<int> vis;
for (int num : nums1) {
vis.insert(num);
}
// 检查nums2的元素是否在集合中出现过
// 如果出现过就将元素插入数组中
// 为了避免重复元素插入,在将元素放入数组中后将该元素从集合vis去除
vector<int> ans;
for (int num : nums2) {
if (vis.count(num)) {
ans.push_back(num);
vis.erase(num);
}
}
return ans;
}
};
为了保证元素的唯一性,遇到一个交集元素就在vis哈希表中删除一个元素。
(排序+二分)
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
// 将两个数组排序,一个数组是为了二分查找,一个数组是为了给数组去重
sort(nums1.begin(), nums1.end());
sort(nums2.begin(), nums2.end());
vector<int> ans;
for (int i = 0; i < nums2.size(); i++) {
int target = nums2[i];
// 对数组nums1二分,找num2中的元素
int l = 0, r = nums1.size() - 1;
while (l < r) {
int mid = l + r >> 1;
if (nums1[mid] >= target) r = mid;
else l = mid + 1;
}
// 如果可以找到就将放入答案中
if (nums1[l] == target)
ans.push_back(target);
}
// 最后给交集去重
ans.erase(unique(ans.begin(), ans.end()), ans.end());
return ans;
}
};
将两个集合中的所有相同的元素都放在一个vector中最后去重即可。
去重函数:
1.先将数组排序sort(v.begin(), v.end()),排序的原因是因为通过排序可以让重复的数字或者字母相邻,为去重函数unique()做准备。
2.用unique函数将重复数字移动到数组的后半部分,并返回第一个重复数字的迭代器auto it = unique(v.begin(), v.end())
3.用erase函数将后面的重复数字移除v.erase(it, v.end())
总结简洁写法为:
vector<int> v;
// 插入数据...
sort(v.begin(), v.end());
v.erase(unique(v.begin(), v.end()), v.end());
(排序+双指针)
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
sort(nums1.begin(), nums1.end());
sort(nums2.begin(), nums2.end());
vector<int> ans;
int idx1 = 0, idx2 = 0;
while (idx1 < nums1.size() && idx2 < nums2.size()) {
if (nums1[idx1] == nums2[idx2]) {// 保证数组元素的唯一性
if (ans.size() == 0 || ans.back() != nums1[idx1]){
ans.push_back(nums1[idx1]);
}
idx1 ++;
idx2 ++;
}// nums1[idx1]和nums2[idx2]哪个小就让idx往后走一个
else if (nums1[idx1] < nums2[idx2])
idx1 ++;
else
idx2 ++;
}
return ans;
}
};
因为排序过后数组有了单调性所以就可以用双指针了。在当nums1[idx1] == nums2[idx2]的时候,可以控制数组的元素不同来保证数组元素的唯一性。
快乐数
(哈希unordered_set)
class Solution {
public:
bool isHappy(int n) {
// 用vis记录n衍生出来的数
unordered_set<int> vis;
// 当n==1的时候就返回true
while (n != 1) {
int sum = 0;
while (n) {
int bit = n % 10;
sum += bit * bit;
n /= 10;
}
n = sum;
// 将平方和放入vis中
// 如果在vis中已经出现过该数字就说明已经死循环了
if (vis.count(sum))
return false;
vis.insert(sum);
}
return true;
}
};
(快慢指针)
class Solution {
public:
// 算出一个数各个位上的平方和
int getN(int n) {
int sum = 0;
while (n) {
int bit = n % 10;
sum += bit * bit;
n /= 10;
}
return sum;
}
bool isHappy(int n) {
int slow = n, fast = getN(n);
// slow每次算一次,fast每次算两次
// 因为计算是循环的所以一定会相遇
while (slow != 1 && slow != fast) {
slow = getN(slow);
fast = getN(getN(fast));
}
// 判断slow是否为1
return slow == 1;
}
};
哈希映射-提供更多信息
两数之和
(暴力法)
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
for (int i = 0; i < nums.size(); i ++) {
for (int j = i + 1; j < nums.size(); j ++) {
if (target == nums[i] + nums[j])// 如果两数之和等于target就返回
return {i, j};
}
}
return vector<int>();
}
};
(哈希表1)
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int, int> hash;
for (int i = 0; i < nums.size(); i ++) {
int t = target - nums[i];
// 如果可以在哈希表中找到t的话,就返回t和当前数字的下标
if (hash.count(t)) return {hash[t], i};
hash[nums[i]] = i;
}
return {-1, -1};
}
};
上面这种写法可以避免数字重复的问题,因为是一遍存数据一遍判断,所以(count()函数)找到的数字一定都是已经遍历过的数,就算是数字相同的话,当前的数字的下标也不会和已经遍历过的数的下标相同,因为map会保存最开始的数的下标。
如果将所有的数字先全部放在ordered_map哈希表中,那么如果是重复key值就会只保存一个数字,这样就找不出不同数字的下标了。
(哈希表2)
利用unordered_map自带的find()函数可以找到key的迭代器。
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int, int> hash;
for (int i = 0; i < nums.size(); i ++ ) {
// find()返回的是key值的迭代器
auto it = hash.find(target - nums[i]);
if (it != hash.end()) {
return {it->second, i};
}
hash[nums[i]] = i;
}
return {-1, -1};
}
};
同构字符串
(双哈希+双射)
class Solution {
public:
bool isIsomorphic(string s, string t) {
unordered_map<char, char> hashMap1;
unordered_map<char, char> hashMap2;
for (int i = 0; i < s.size(); i ++) {
char x = s[i], y = t[i];
if ((hashMap1.count(x) && hashMap1[x] != y)
|| (hashMap2.count(y) && hashMap2[y] != x))
return false;
hashMap1[x] = y;
hashMap2[y] = x;
}
return true;
}
};
(双哈希+索引)
class Solution {
public:
bool isIsomorphic(string s, string t) {
int hash1[256] = {0}, hash2[256] = {0};
for (int i = 0; i < s.size(); i ++ ) {
int x = s[i], y = t[i];
// 如果哈希表中有x,两个哈希表中的字符位置不同的话
// 说明当前位置的字符出现的最后一个位置不同
if ((hash1[x] && hash1[x] != hash2[y])
|| (hash2[y] && hash2[y] != hash1[x]))
return false;
// 因为第一个字符的下标是0
// 所以i+1就可以避免第一个字符的误判
hash1[x] = i + 1;
hash2[y] = i + 1;
}
return true;
}
};
(用find()找索引)
class Solution {
public:
bool isIsomorphic(string s, string t) {
for (int i = 0; i < s.size(); i ++ ) {
if (s.find(s[i]) != t.find(t[i]))
return false;
}
return true;
}
};
用string.find()函数可以直接找到字符串中的字符的位置,就可以不用哈希表保存字符的索引了。其实用哈希表保存的字符的下标是在遍历过的字符串中字符的最后一个位置,所以用==string.rfind()也是可以的。==
两个列表的最小索引总和
题目要求:找出两个列表中重复元素的最小索引的和
(哈希表+unordered_map排序)
class Solution {
public:
vector<string> findRestaurant(vector<string>& list1, vector<string>& list2) {
unordered_map<string, int> hash;
for (int i = 0; i < list1.size(); i++) {
hash[list1[i]] = i;
}
unordered_map<string, int> sum;
for (int i = 0; i < list2.size(); i++) {
// 如果hash中有list2[i]的字符串,并且记录字符串的索引值之和
if (hash.count(list2[i])) {
sum.insert({ list2[i], hash[list2[i]] + i });
}
}
// 按照索引值的大小将哈希表unordered_map排序
vector<pair<string, int>> tmp(sum.begin(), sum.end());
sort(tmp.begin(), tmp.end(),
[](const pair<string, int> &x, const pair<string, int> &y)->int {
return x.second < y.second;
});
// 找出最小的几个字符串
vector<string> ans;
auto it = tmp.begin();
for (auto e : tmp) {
if (e.second == it->second) {
ans.push_back(e.first);
}
}
return ans;
}
};
思路:首先存储一个列表中的字符串及其索引,然后将列表2和列表1中的相同字符串,放到一个哈希表中按照索引值的大小排序。
问题:如何将unordered_map哈希表排序呢?(set和map底层都是红黑树所以会自动按照key排序,但是unordered_map和unordered_set底层是哈希表所以不会自动排序)
既然哈希表不会排序,就将哈希表放到一个vector中然后将vector排序。用lambda表达式也可以写一个比较函数
bool cmp(const pair<string, int>& x, const pair<string, int>& y)
{
return x.second < y.second;
}
(哈希表+min_sum标记)
class Solution {
public:
vector<string> findRestaurant(vector<string>& list1, vector<string>& list2) {
// 用哈希表将list1中的字符串及其下标记录下来
unordered_map<string, int> hash;
for (int i = 0; i < list1.size(); i ++) {
hash[list1[i]] = i;
}
vector<string> ans;
int min_sum = 0x7fffffff;// 最小的索引总和
for (int i = 0; i < list2.size(); i ++) {
if (hash.count(list2[i])) {// 如果list1和list2有相同的部分
int sum = hash[list2[i]] + i;// list1和list2相同字符串的索引的总和
if (sum < min_sum) {// 如果sum更小,就刷新ans中的字符串
ans.clear();
ans.push_back(list2[i]);
min_sum = sum;
} else if (sum == min_sum) {// 如果sum和最小索引和相等,就将多个字符串保存下来
ans.push_back(list2[i]);
}
}
}
return ans;
}
};
因为索引值的最小值可能会有多个,所以不能用min_sum只算出一个最小的索引值。所以每次将索引值相同的字符串都记录下来,如果遇到更小的索引总和,就将记录的字符串全部清空,继续记录当前和最小索引和相同的字符串。
哈希映射-按键聚合
字符串中第一个唯一字符
(哈希表)
用哈希表来统计字符出现的次数
class Solution {
public:
int firstUniqChar(string s) {
// 将字符串中的字符一社到哈希表中统计出现次数
int hash[26] = {0};
for (auto e : s) {
hash[e - 'a'] ++;
}
// 从前往后遍历找到字符串中只出现一次的字符
for (int i = 0; i < s.size(); i ++) {
if (hash[s[i] - 'a'] == 1) return i;
}
return -1;
}
};
也可以用unordered_map替代数组当哈希表,但是用数组作为哈希表也可以让时间和空间效率更高。
当unordered_map初始化元素的时候,如果value是基本数据类型,那么value就是基本类型的默认值,比如int就是0,char就是‘\0’。。。
(find()函数找索引值)
一个字符在字符串中的从前往后和从后往前的索引值是一样的话,说明该字符没有重复元素。
class Solution {
public:
int firstUniqChar(string s) {
for (int i = 0; i < s.size(); i ++) {
int start = s.find(s[i]);
int end = s.rfind(s[i]);
if (start == end)
return i;
}
return -1;
}
};
两个数组的交集Ⅱ(狭义)
注意区别:这题和两个数的交集Ⅰ的差别就在于这题交集的元素是狭义的交集,就是两个集合相同的部分。
题目要求:找出两个集合中重复的部分。
(哈希表1Array)
class Solution {
public:
vector<int> intersect(vector<int>& nums1, vector<int>& nums2) {
// 找那个集合的最大值更大
int max_num = 0;
for (int num : nums1) {
max_num = max(max_num, num);
}
for (int num : nums2) {
if (num > max_num) return intersect(nums2, nums1);
}
vector<int> vis(max_num + 1, 0);
for (int num : nums1) {
vis[num] ++;
}
vector<int> ans;
for (int num : nums2) {
if (vis[num] > 0)
{
ans.push_back(num);
vis[num] --;
}
}
return ans;
}
};
初始化一个vector用来统计数组中的数字出现的次数,所以就要求首先要找出两个集合中的最大值,然后将vector的初始化为max_num+10个0,然后统计nums1中数字出现的次数,最后再nums1中每找到一个交集元素就将nums1中的相应的交集元素-1,这样就可以找出所有的交集元素。
(哈希表2unordered_map)
用unordered_map记录数字出现过的次数。
unordered_map的初始化问题 : ==当unordered_map初始化元素的时候,如果value是基本数据类型,那么value就是基本类型的默认值,比如int就是0,char就是‘\0’。。。==当unordered_map在赋值的时候,如果key相同就不会将第二个key相同的pair插入
class Solution {
public:
vector<int> intersect(vector<int>& nums1, vector<int>& nums2) {
unordered_map<int, int> hash;
// 统计nums1中数字出现过的次数
for (int i = 0; i < nums1.size(); i ++) {
hash[nums1[i]] ++;
}
vector<int> ans;
for (int i = 0; i < nums2.size(); i ++) {
if (hash.count(nums2[i])) {// 如果nums2[i]出现过,就将该数字的出现次数-1
if (hash[nums2[i]] > 0)// 只有当出现次数>0的时候
ans.push_back(nums2[i]);
hash[nums2[i]] --;
}
}
return ans;
}
};
(查找)
class Solution {
public:
vector<int> intersect(vector<int>& nums1, vector<int>& nums2) {
vector<int> ans;
for (int i = 0; i < nums2.size(); i ++) {
// 在nums1中找nums2的数字,如果可以找到就是交集并将该数字删除
auto it = find(nums1.begin(), nums1.end(), nums2[i]);
if (it != nums1.end()) {
ans.push_back(*it);
nums1.erase(it);
}
}
return ans;
}
};
这里不适合用二分查找,因为找到的每一个数字都要放在数组中,而且要保证是集合的交集,所以每找到一个集合中的数组就要将该数字从集合中去除来保证交集元素的正确性。但是用二分的方式找到数字删除元素就要一个一个挪动,所以不如直接用find()函数直接找到交集元素的迭代器然后直接删除,虽然find()函数的效率不高,但是这样写方便一点。
(排序+双指针)
class Solution {
public:
vector<int> intersect(vector<int>& nums1, vector<int>& nums2) {
sort(nums1.begin(), nums1.end());
sort(nums2.begin(), nums2.end());
int idx1 = 0, idx2 = 0;
vector<int> ans;
while (idx1 < nums1.size() && idx2 < nums2.size()) {
int n1 = nums1[idx1], n2 = nums2[idx2];
if (n1 == n2) {
ans.push_back(n1);
idx1 ++;
idx2 ++;
} else if (n1 < n2){
idx1 ++;
} else {
idx2 ++;
}
}
return ans;
}
};
总结:使用排序+双指针的方法空间复杂度和时间复杂度综合起来是最高的。另外使用array哈希表或者是使用unordered_map哈希表都是一样的原理都是在统计出现过的元素的个数。但是因为array哈希表是连续的,所以中间可能会用很多的空间都被浪费了,这时使用散列表更会合适。
存在重复元素Ⅱ
(哈希表unordered_map)
class Solution {
public:
bool containsNearbyDuplicate(vector<int>& nums, int k) {
unordered_map<int, int> hash;
int min_num = 0x7fffffff;
for (int i = 0; i < nums.size(); i ++) {
if (hash.count(nums[i])) {// 如果哈希表中有重复的元素
int gap = i - hash[nums[i]];// 计算重复元素的下标差
if (gap < min_num) {// 取min(gap, min_num)
min_num = gap;
}
}
hash[nums[i]] = i;// 用哈希表记录数组中数的下标
}
return min_num <= k;
}
};
下面这种更好,就是遇到了一个重复元素下标差<=k就直接返回了
class Solution {
public:
bool containsNearbyDuplicate(vector<int>& nums, int k) {
unordered_map<int, int> hash;
for (int i = 0; i < nums.size(); i ++) {
// 当出现重复元素的时候并且下标差<=k就返回true
if (hash.count(nums[i]) && (i - hash[nums[i]]) <= k) {
return true;
}
hash[nums[i]] = i;// 用哈希表记录数组中数的下标
}
return false;
}
};
注意:在哈希表中找数值,有两种方法:
1)用count()函数可以快速的找到重复元素的个数
2)用find()(set map unordered_set unordered_map都有自己的find(const key_type& k))找到对应数值的迭代器,如果find() != ?.end()就说明容器中存在该数值。
ps:其他的容器也可以用InputIterator find (InputIterator first, InputIterator last, const T& val)来在容器中找到某个数值的迭代器。
(哈希表ordered_set)
用unordered_set维护一个大小为k的集合,当集合中在k距离内有重复的元素的时候,说明有重复的元素距离<=k。但是超出集合范围的元素应该删除。(注意:维护一个k大小的集合,但是k距离的元素不一定在集合内,比如说:k=3,集合:1,2,3,1虽然最后一个1在集合k=3的外面,但是距离其实k。所以在循环的时候,需要先判断当前的元素是否在聚合内,然后再将元素插入到集合中判断是否要使得集合的大小为k)。
class Solution {
public:
bool containsNearbyDuplicate(vector<int>& nums, int k) {
unordered_set<int> hash;
for (int i = 0; i < nums.size(); i ++) {
if (hash.count(nums[i]))
return true;
hash.insert(nums[i]);
if (hash.size() > k) // 如果集合的大小>k,就要删除k大小以外的数字
hash.erase(nums[i - k]);
}
return false;
}
};
设计键值(key)
字母异位词分组
题目要求:找出有相同字母组成但是不同排列方式的单词的分类。
(哈希表unordered_map1)
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
unordered_map<string, vector<string>> hash;
for (auto str : strs) {
string tmp = str;
sort(tmp.begin(), tmp.end());
hash[tmp].push_back(str);
}
vector<vector<string>> ans;
for (auto e : hash) {
ans.push_back(e.second);
}
return ans;
}
};
找出相同字母组成但是有不同的排列方式的单词。这些单词的共同点就是它们排序过后的单词是一样的。所以就可以将所有的这些单词映射到它们排序过后的单词身上,这样就可以将这些单词整合到一起了。
(哈希表unordered_map2)
方法1是将所有排列过的单词映射到它们排过序的单词上然后将整合过后的数组放入答案中。但是如果所有的单词还是映射到排过序的单词上,但是哈希表中对应的value是vector的索引这样就可以让映射到排过序的单词的所有单词直接插入到答案中了。
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
unordered_map<string, int> hash;
vector<vector<string>> ans;
int i = 0;
for (auto str : strs) {
string tmp = str;
sort(tmp.begin(), tmp.end());
if (hash.count(tmp)) {
ans[hash[tmp]].push_back(str);
} else {
hash[tmp] = i;
vector<string> tmp = {str};
ans.push_back(tmp);
i ++;
}
}
return ans;
}
};
有效数独
(哈希表判重)
class Solution {
public:
bool isValidSudoku(vector<vector<char>>& board) {
unordered_set<char> row, col, box;
for (int i = 0; i < 9; i ++) {
// 每判断过一行或者一列或者一个3x3的方格就重新刷新
row.clear();
col.clear();
box.clear();
for (int j = 0; j < 9; j ++) {
// 第一行的坐标
char ch1 = board[i][j];
if (row.count(ch1))
return false;
else if (ch1 != '.')
row.insert(ch1);
// 第一列的坐标
char ch2 = board[j][i];
if (col.count(ch2))
return false;
else if (ch2 != '.')
col.insert(ch2);
// 将第一行的坐标转化成第一个3x3的方格中的坐标
char ch3 = board[i/3*3 + j/3][i%3*3 + j%3];
if (box.count(ch3))
return false;
else if (ch3 != '.')
box.insert(ch3);
}
}
return true;
}
};
用[i/3*3 + j/3][i%3*3 + j%3]可以将对应的行数转换成对应的子数独,也可以将对应的子数独转换成随影的函数。比如说:遍历第二行的时候实际上时遍历对应的子数独
(用数组记录判重)
class Solution {
public:
bool isValidSudoku(vector<vector<char>>& board) {
bool rows[9][9] = {false};
bool cols[9][9] = {false};
bool boxs[9][9] = {false};
for (int i = 0; i < 9; i ++) {
for (int j = 0; j < 9; j ++) {
if (board[i][j] == '.') continue;
int num = board[i][j] - '1';
int box_index = i/3*3 + j/3;// 子数独的多位坐标映射到对应的行数
if (rows[i][num] || cols[j][num] || boxs[box_index][num]) return false;
else {
rows[i][num] = true;
cols[j][num] = true;
boxs[box_index][num] = true;
}
}
}
return true;
}
};
用i/3%3 + j/3的方式将对应的子数独映射到对应的行数,例如说:遍历完第一个子数独(遍历完前三行)就会将所有在第一个子数独中的数字映射到第一行上。
寻找重复子树
(哈希表unordered_map记录路径)
class Solution {
public:
string dfs(TreeNode* root, vector<TreeNode*>& ans, unordered_map<string, int>& mp) {
if (root == nullptr) return "#";
// 将在树上遍历的路径记录下来
string str = to_string(root->val) + "," + findc(root->left, ans, mp) + "," + findc(root->right, ans, mp);
// 如果有相同的路径就说明有重复的子树
if (mp[str] == 1)
ans.push_back(root);
// 每次将对应结点的路径数量+1
mp[str] ++;
return str;
}
vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {
vector<TreeNode*> ans;
unordered_map<string, int> mp;// 用mp可以记录所有的走过的路径
dfs(root, ans, mp);
return ans;
}
};
思路:找到所有的重复子树,可以用哈希表来存储树的形状,而数的形状统一用序列化来表示。
如何设计键-总结
1.当字符串或者数组中每个元素的顺序不重要的时候,可以使用排过序的字符串或者数组作为键值。(字母异位词分组)
2.如果只关心每个值的偏移量,通常是第一个值的偏移量,则可以使用偏移量作为键。
3.在树中,有时希望用TreeNode作为键值,但是大多数情况下采用子树序列化更好(寻找重复子树)
4.在矩阵中,使用行索引或者列索引作为键值。(有效数独)
5.在数独中可以结合行索引和列索引i/3*3 + j/3的方式表示属于哪一个子数独。(有效数独)
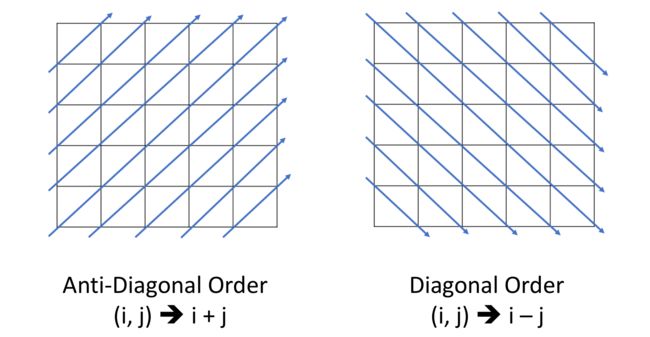
6.有时,在矩阵中,您可能希望将值聚合在同一对角线中。
小结哈希表
当遇到想要在某个数组中字符串中树上等等数据结构上搜索重复元素的时候哈希表是一个很好的工具,可以快速搜索重复元素及插入和删除元素。
常用unordered_map来统计数字出现过的次数,如果指向检查是否出现过重复数字可以用unordered_set来记录
宝石与石头
(哈希表unordered_set)
class Solution {
public:
int numJewelsInStones(string jewels, string stones) {
// 用哈希表记录每一个字符
unordered_set<char> hash;
for (auto ch : jewels) {
hash.insert(ch);
}
// 判断字符串中是否出现重复的字符
int ans = 0;
for (auto ch : stones) {
if (hash.count(ch))
ans ++;
}
return ans;
}
};
无重复字符的最长子串
(双指针+哈希表+滑动窗口1)
窗口的区间是[left, right]左闭右闭
class Solution {
public:
int lengthOfLongestSubstring(string s) {
if (s.empty()) return 0;
int left = 0, right = 0;
unordered_set<char> hash;
int max_size = 0;
while (right < s.size()) {
// 如果right指向的字符出现过,就让窗口紧缩
while (hash.count(s[right]) && left < right) {
hash.erase(s[left]);
left ++;
}
// 向窗口插入元素
hash.insert(s[right]);
// 更新窗口大小
if (right - left + 1 > max_size) max_size = right - left + 1;
// 扩展窗口
right ++;
}
return max_size;
}
};
因为是求出子串,所以可以想到用双指针和滑动窗口,这样就可以保证窗口内的字符是连续的。
(哈希表+局部双指针+滑动窗口2)
class Solution {
public:
int lengthOfLongestSubstring(string s) {
// 将每个字符映射到一个下标
unordered_map<char, int> hash;
int start = 0;// 窗口的开始位置
int max_size = 0;
for (int i = 0; i < s.size(); i ++) {
// 如果哈希表中出现过字符
// 就将窗口到该字符的下标中的字符全部删除
if (hash.count(s[i])) {
int j = start;
while (j <= hash[s[i]]) {
hash.erase(s[j]);
j ++;
}
start = j;
}
// 将字符映射一个下标
hash[s[i]] = i;
max_size = max(max_size, i - start + 1);
}
return max_size;
}
};
(数组模拟哈希表)
class Solution {
public:
int lengthOfLongestSubstring(string s) {
int hash[256] = {0};
int start = 0;
int max_size = 0;
for (int i = 0; i < s.size(); i ++) {
while(hash[s[i]] > 0) {
hash[s[start]] --;
start ++;
}
hash[s[i]] ++;
max_size = max(max_size, i - start + 1);
}
return max_size;
}
};
四数相加Ⅱ
(哈希表)
class Solution {
public:
int fourSumCount(vector<int>& nums1, vector<int>& nums2, vector<int>& nums3, vector<int>& nums4) {
unordered_map<int, int> hash;
// 用哈希表统计两数之和出现的次数
for (int n1 : nums1) {
for (int n2 : nums2) {
hash[n1 + n2] ++;
}
}
// 枚举另一组两数之和的相反数是否在哈希表中出现过
// 如果出现过ans就加上这两个数重复的次数(两数之和重复)
int ans = 0;
for (int n3 : nums3) {
for (int n4 : nums4) {
if (hash.count(-(n3 + n4)))
ans += hash[-(n3 + n4)];
}
}
return ans;
}
};
这题很多种思路:
1.暴力解,用四重for循环O(N4)
2.用哈希表存储一个数组中的值,然后三重for循环O(N) + O(N3)
3.用哈希表存储两数之和,然后两重for循环O(N2) + O(N2)
4.用哈希表存储三处之和,然后一重for循环O(N3) + O(N)
显然用哈希表存储两数之和是最优解
前K个高频元素(TopK问题)
(大根堆堆+哈希表)O(N + KlogN)
class Solution {
typedef pair<int, int> PII;
public:
struct cmpByValue{// 重写仿函数
bool operator() (PII a, PII b) {
return a.second < b.second;
}
};
vector<int> topKFrequent(vector<int>& nums, int k) {
// 用哈希表统计数字出现过的次数
unordered_map<int, int> hash;
for (auto n : nums) {
hash[n] ++;
}
// 将哈希表中的pair存储到堆中,并按出现过的次数排序
priority_queue<PII, vector<PII>, cmpByValue> q;
for (auto e : hash) {
q.push(e);
}
// 将对顶的前k个元素取出
vector<int> ans;
while (k --) {
ans.push_back(q.top().first);
q.pop();
}
return ans;
}
};
(堆(优先队列)的使用方法):
模板申明带3个参数:priority_queue,其中Type 为数据类型,Container为保存数据的容器,Functional 为元素比较方式。
针对int类型
priority_queue<int> q;// 默认是大根堆,降序排列
priority_queue<int, vector<int>, greater<int>>; // 用仿函数变成小根堆,升序排列
针对pair类型
priority_queue<pair<int, int>> q;// 默认是大根堆,按first降序排列,如果fist相同则按second排列
priority_queue<pair<int, int>, vector<pair<int, int> >, greater<pair<int, int> > >;// 小根堆,按first升序排列,如果first相同则按second升序
自定义类型重载小于号:
struct Node {
int x, y;
Node(int x, int y):x(x), y(y) {}
bool operator< (const Node& a, const Node& b) const {
if (a.x != b.x) return a.x > b.x;
return a.y > b.y;
}
}
priority_queue<Node, vector<Node>, greater<Node>> q;
自定义仿函数
class cmp {// 自定义一个类并重载()
bool operator() (pair<int,int> a, pair<int,int> b) {
return a.second > b.second;
}
}
priority_queue<pair<int, int>, vector<pair<int, int> >, cmp >;
注意重载小于号:和之前的排序不同如果想要升序排列需要用a.first < b.first这样小的元素就在前面了,但是如果想要变成小根堆需要a.first > b.first才可以。
(小根堆 + 哈希表)O(Nlogk)(k为堆的大小)
class Solution {
typedef pair<int, int> PII;
struct cmpByValue {
bool operator() (PII a, PII b) {
return a.second > b.second;
}
};
public:
vector<int> topKFrequent(vector<int>& nums, int k) {
// 统计数字出现的次数
unordered_map<int, int> hash;
for (int num : nums) {
hash[num] ++;
}
// 维护一个大小为k的小根堆,如果元素个数>k,就将堆顶元素去掉
priority_queue<PII, vector<PII>, cmpByValue> q;
for (PII e : hash) {
q.push(e);
if (q.size() > k) {
q.pop();
}
}
vector<int> ans;
while (k --) {
ans.push_back(q.top().first);
q.pop();
}
return ans;
}
};
用小根堆比大根堆优化在于:大根堆在维护一个大小为N的堆,但是小根堆在维护一个大小为k的堆。小根堆在建堆的时候一直在调整,最后留下的k个元素就是最大的元素。而大根堆只是一直在不断的插入元素向下调整N个元素,前k个元素就是最大的元素。
// 17~23也可以这样写,上面的写法是在维护一个大小为k + 1的堆,这种写法是在维护一个大小为k的堆
priority_queue<PII, vector<PII>, cmp> q;
for (PII e : hash) {
if (q.size() == k) {
if (q.top().second < e.second) {
q.pop();
q.push(e);
}
} else {
q.push(e);
}
}
(sort排序+哈希表)O(NlogN)
class Solution {
public:
typedef pair<int, int> PII;
vector<int> topKFrequent(vector<int>& nums, int k) {
// 用哈希表统计数字出现的次数
unordered_map<int, int> hash;
for (auto num : nums) {
hash[num] ++;
}
// 用vector存储哈希表中的pair,方便后面的排序
vector<PII> num(hash.begin(), hash.end());
sort(num.begin(), num.end(), [](auto a, auto b) {
return a.second > b.second;
});
// 将前k个数字取出
vector<int> ans;
for (int i = 0; i < k; i ++) {
ans.push_back(num[i].first);
}
return ans;
}
};
利用哈希表可以记录数字及其出现的次数加上vector可以排序的两大特性,就可以统计出数字出现的次数并且派出高频的数字
(桶排序+哈希表)
class Solution {
public:
vector<int> topKFrequent(vector<int>& nums, int k) {
unordered_map<int, int> hash;
for (int num : nums) {
hash[num] ++;
}
// 将数字出现的次数作为第一维,因为可能有出现频率相同的数
vector<vector<int>> buckets(nums.size() + 1);
for (auto &[num, freq] : hash) {
buckets[freq].push_back(num);
}
// 从后往前遍历就是数字频率从高到低
vector<int> ans;
for (int i = buckets.size() - 1; i >= 0; i --) {
for (int j : buckets[i]) {
ans.push_back(j);
if (ans.size() == k) return ans;
}
}
return ans;
}
};
用哈希表统计数字出现的次数,将哈希表中数字出现的频率作为下标映射到数组中,这样使得数组从后往前遍历就是数字的频率从高到低(注意用vector来保存数,因为可能不同的数字出现的频率相同)。最后从后往前遍历如果有数字,就将数字放入ans中直到已经有k个。
(*快排 + 哈希表)
class Solution {
public:
int GetMid(vector<pair<int,int>>& buckets, int start, int end) {
int mid = (start + end) >> 1;
auto midVal = buckets[mid];
auto startVal = buckets[start];
auto endVal = buckets[end];
return startVal.second > endVal.second ?
(startVal.second > midVal.second ? start : mid) :
(endVal.second > midVal.second ? end : mid);
}
void Qsort(vector<pair<int,int>>& buckets, int start, int end, vector<int>& ans, int k) {
// 三数取中优化
int pick = GetMid(buckets, start, end);
swap(buckets[start], buckets[pick]);
// 快排:找出key所在的位置
int left = start, right = end;
int key = buckets[start].second;
while (left < right) {
while (left < right && buckets[right].second <= key) right --;
while (left < right && buckets[left].second >= key) left ++;
swap(buckets[left], buckets[right]);
}
int meeti = left;
swap(buckets[meeti], buckets[start]);
// 如果[start, meeti-1]中的数量>=k,说明在答案就在区间内
// 否则,答案在左边的数组中,加上右边数组中的k-(end-meeti+1)个元素
if (meeti - start >= k) {
Qsort(buckets, start, meeti - 1, ans, k);
} else {
for (int i = start; i <= meeti; i ++) {
ans.push_back(buckets[i].first);
}
if (k > meeti - start + 1) {
Qsort(buckets, meeti + 1, end, ans, k - (meeti - start + 1));
}
}
}
vector<int> topKFrequent(vector<int>& nums, int k) {
unordered_map<int, int> hash;
for (int num : nums) {
hash[num] ++;
}
vector<pair<int, int>> buckets;
for (auto e : hash) {
buckets.push_back(e);
}
vector<int> ans;
Qsort(buckets, 0, buckets.size() - 1, ans, k);
return ans;
}
};