25张图解Redis连环面试!击溃面试官!
很多人问我,面试到底考察什么?面试官究竟想听到怎样的回答?针对这类疑惑,我觉得最好的解答,无疑是带着大家,以面试官视角,去进行面试,知己知彼,百战不殆,这就是我写这个系列的初衷。
话不多说,接下来就来看看我们面试官系列的第一弹吧!
这次我们的面试主题是Redis,我一般要考察的知识点都在下图,根据候选人的情况,会选择不同的知识点进行提问。
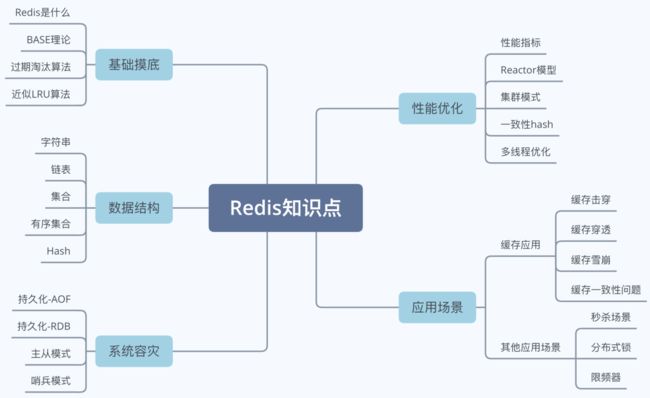
通过上图,大家对Redis面试问题也心里有数了吧?
现在,就让我们来体验一场沉浸式面试,牛牛担任恶魔面试官,友情请来阿柴担任面试者。
本文分为六个部分进行:

准备好了么?Let's go!

PART1 基础摸底
一般情况下,面试官不会上来就问难度颇高的问题,都是随着知识点循序渐进,校招更是遵从这样的引导思路。所以,考察面试者都是从基础知识入手,Redis当然也不例外。
![]()
你知道Redis是什么吗?


Redis是一个数据库,不过与传统RDBM不同,Redis属于NoSQL,也就是非关系型数据库,它的存储结构是Key-Value。Redis的数据直接存在内存中,读写速度非常快,因此 Redis被广泛应用于缓存方向。
![]()
![]()
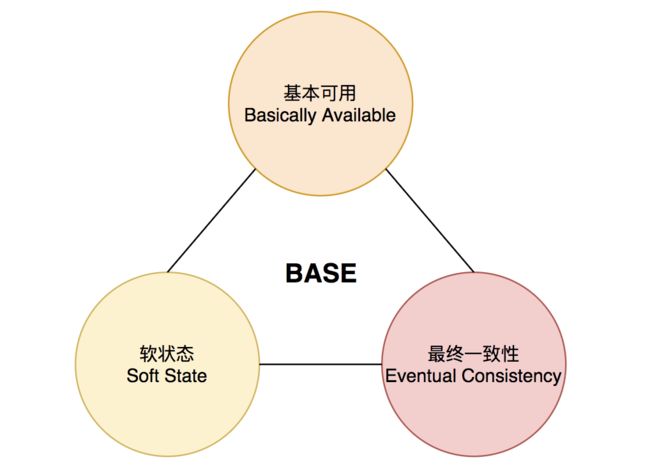
那NoSQL的BASE理论是什么?


可以说BASE理论是CAP中一致性的妥协。和传统事务的ACID截然不同,BASE不追求强一致性,而是允许数据在一段时间内是不一致的,但最终达到一致状态,从而获得更高的可用性和性能。
![]()
![]()
先说说你最常用的Redis命令吧?


我最常用的读操作是get a,表示获取a对应的数据;最常用的写操作是setex a t b,表示将a的数据设置为b,并且在t秒后过期。
![]()
![]()
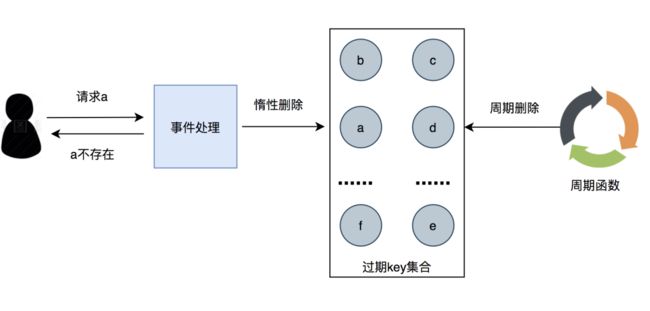
你提到了过期时间,那你知道Redis的过期键清除策略吗?


过期键清除策略有三种,分别是定时删除、定期删除和惰性删除。
![]()

定时删除,是在设置键的过期时间的同时,创建一个定时器,让定时器在键的过期时间来临时,立即执行对键的删除操作;
![]()

定期删除,每隔一段时间,程序就对数据库进行一次检查,删除里面的过期键;
![]()

惰性删除,是指使用的时候,发现Key过期了,此时再进行删除。
![]()

Redis过期键采用的是定期删除+惰性删除二者结合的方式进行删除的。
![]()
![]()
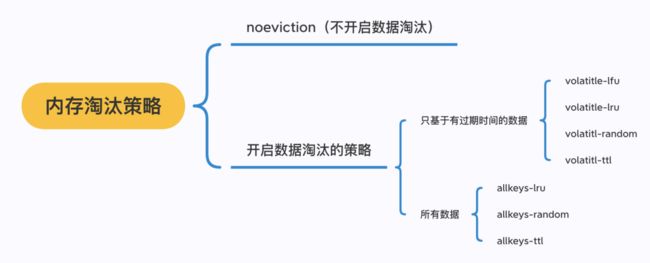
如果过期键没有被访问,而周期性删除又跟不上新键产生的速度,内存不就慢慢耗尽了吗?


Redis支持内存淘汰,配置参数maxmemory_policy决定了内存淘汰策略的策略。这个参数一共有8个枚举值。
![]()
![]()
内存淘汰用到的是LRU算法吗?


嗯...Redis用的是近似LRU算法,LRU算法需要一个双向链表来记录数据的最近被访问顺序,但是出于节省内存的考虑,Redis的LRU算法并非完整的实现。
![]()

Redis通过对少量键进行取样,然后和目前维持的淘汰池综合比较,回收其中的最久未被访问的键。通过调整每次回收时的采样数量maxmemory-samples,可以实现调整算法的精度。
![]()
显然,面试官开门见山,摸了下阿柴的基础,并进行了一定程度的发散。看得出来,阿柴基础扎实,有备而来,是时候探探他的真本事了。
PART2 数据结构
![]()
你知道Redis有多少数据结构吗 ?


对外暴露5种Redis对象,分别是String、List、Hash、Set、Zset。底层实现依托于sds、ziplist、skiplist、dict等更基础数据结构。
![]()

不错,知道得很清楚,能区分对外结构和底层实现。那么下面就针对几个结构,来重点追问下。
![]()
那Redis字符串有什么特点?


Redis的字符串如果保存的对象是整数类型,那么就用int存储。如果不能用整数表示,就用SDS来表示,SDS通过记录长度,和预分配空间,可以高效计算长度,进行append操作。

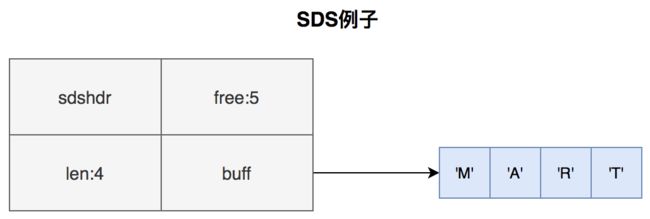
嗯,能说清楚SDS就达到了面试官的预期,如果能根据不同数据类型讲清楚,加分!
![]()
Hash扩容过程是怎样的?


两张Hash表,平常起作用的都是0号表,当装载因子超过阈值时就会进行Rehash,将0号每上每一个bucket慢慢移动到1号表,所以叫渐进式Rehash,这种方式可以减少迁移系统的影响。
![]()
![]()
慢慢移动?能详细说下Rehash过程吗?


当周期函数发现为装载因子超过阈值时就会进行Rehash。Rehash的流程大概分成三步。
![]()

首先,生成新Hash表ht[1],为 ht[1] 分配空间。此时字典同时持有ht[0]和ht[1]两个哈希表。字典的偏移索引从静默状态-1,设置为0,表示Rehash 工作正式开始。
![]()

然后,迁移ht[0]数据到ht[1]。在 Rehash进行期间,每次对字典执行增删查改操作,程序会顺带迁移一个ht[0]上的数据,并更新偏移索引。与此同时,周期函数也会定时迁移一批。
![]()

最后,ht[1]和ht[0]指针对象交换。随着字典操作的不断执行, 最终在某个时间点上,ht[0]的所有键值对都会被Rehash至 ht[1],此时再将ht[1]和ht[0]指针对象互换,同时把偏移索引的值设为-1,表示Rehash操作已完成。
![]()
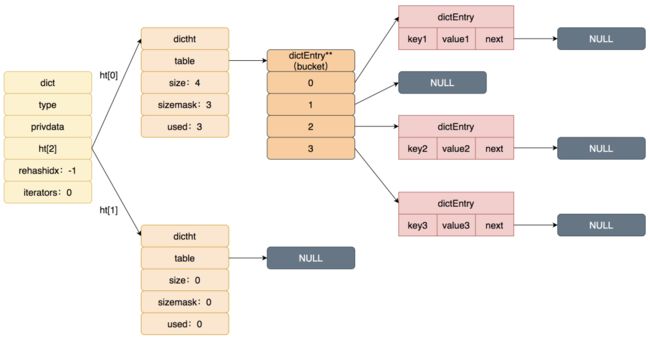
![]()
如果字典正在Rehash,此时有请求过来,Redis会怎么处理?


针对新增Key,是往ht[1]里面插入。针对读请求,先从ht[0]读,没找到再去ht[1]找。至于删除和更新,其实本质是先找到位置,再进行操作,所以和读请求一样,先找ht[0],再找ht[1],找到之后再进行操作。
![]()
![]()
接下来讲讲跳表的实现吧。


跳表本质上是对链表的一种优化,通过逐层跳步采样的方式构建索引,以加快查找速度。如果只用普通链表,只能一个一个往后找。跳表就不一样了,可以高层索引,一次跳跃多个节点,如果找过头了,就用更下层的索引。
![]()
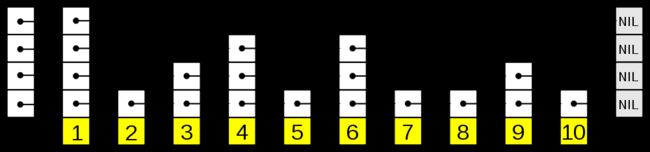
图片来自维基百科
![]()
那每个节点有多少层呢?


使用概率均衡的思路,确定新插入节点的层数。Redis使用随机函数决定层数。直观上来说,默认1层,和丢硬币一样,如果是正面就继续往上,这样持续迭代,最大层数32层。
![]()

可以看到,50%的概率被分配到第一层,25%的概率被分配到第二层,12.5%的概率被分配到第三层。这种方式保证了越上层数量越少,自然跨越起来越方便。
![]()

跳表原理说清楚就达标,说出层次算法加分。
![]()
Redis的Zset为什么同时需要字典和跳表来实现?


Zset是一个有序列表,字典和跳表分别对应两种查询场景,字典用来支持按成员查询数据,跳表则用以实现高效的范围查询,这样两个场景,性能都做到了极致。
![]()
Redis的数据结构包含了很多干货,在细节处见功夫,阿柴对答如流。面试官不由地更加期待他接下来的表现了。
PART3 系统容灾
![]()
Redis是基于内存的存储,如果服务重启,数据不就丢失了吗?


可以通过持久化机制,备份数据。有两种方式,一种是开启RDB,RDB是Redis的二进制快照文件,优点是文件紧凑,占用空间小,恢复速度比较快。同时,由于是子进程Fork的模式,对Redis本身读写性能的影响很小。

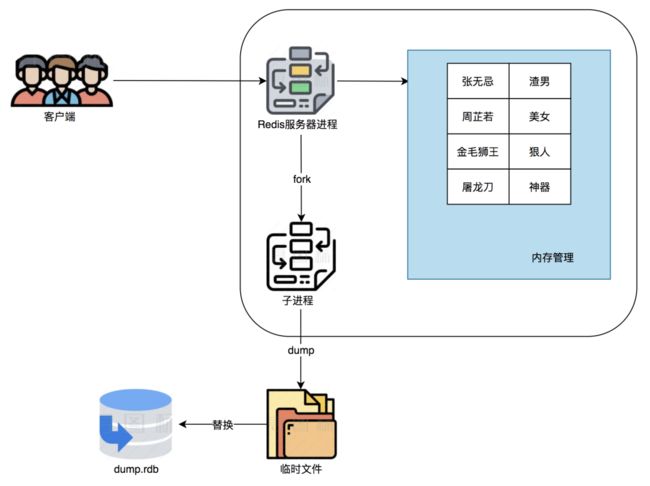

另一种方式是AOF,AOF中记录了Redis的操作命令,可以重放请求恢复现场,AOF的文件会比RDB大很多。
![]()

出于性能考虑,如果开启了AOF,会将命令先记录在AOF缓冲,之后再刷入磁盘。数据刷入磁盘的时机根据参数决定,有三种模式:1.关闭时刷入;2.每秒定期刷入;3.执行命令后立刻触发。
![]()

AOF的优点是故障情况下,丢失的数据会比RDB更少。如果是执行命令后立马刷入,AOF会拖累执行速度,所以一般都是配置为每秒定期刷入,这样对性能影响不会很大。
![]()

AOF运行原理-创建
![]()
这样看起来,AOF文件会越来越大,最后磁盘都装不下?


不会的,Redis可以在AOF文件体积变得过大时,自动地在后台Fork一个子进程,专门对AOF进行重写。说白了,就是针对相同Key的操作,进行合并,比如同一个Key的set操作,那就是后面覆盖前面。
![]()

在重写过程中,Redis不但将新的操作记录在原有的AOF缓冲区,而且还会记录在AOF重写缓冲区。一旦新AOF文件创建完毕,Redis 就会将重写缓冲区内容,追加到新的AOF文件,再用新AOF文件替换原来的AOF文件。
![]()

![]()
Redis机器挂掉怎么办?


可以用主从模式部署,即有一个或多个备用机器,备用机会作为Slave同步Master的数据,在Redis出现问题的时候,把Slave升级为Master。
![]()

![]()
主从可以自动切换吗?


本身是不能,但可以写脚本实现,只是需要考虑的问题比较多。Redis已经有了现成的解决方案:哨兵模式。哨兵来监测Redis服务是否正常,异常情况下,由哨兵代理切换。为避免哨兵成为单点,哨兵也需要多机部署。
![]()


如果Master挂掉,会选择哪个Slave呢?


当哨兵集群选举出哨兵Leader后,由哨兵Leader从Redis从节点中选择一个Redis节点作为主节点:
![]()

1.过滤故障的节点;
![]()

2.选择优先级slave-priority最大的从节点作为主节点,如不存在,则继续;
![]()

3.选择复制偏移量最大的从节点作为主节点,如果都一样,则继续。这里解释下,数据偏移量记录写了多少数据,主服务器会把偏移量同步给从服务器,当主从的偏移量一致,则数据是完全同步;
![]()

4.选择runid最小的从节点作为主节点。Redis每次启动的时候生成随机的runid作为Redis的标识。
![]()

![]()
前面你提到了哨兵Leader,那它是怎么来的呢?


每一个哨兵节点都可以成为Leader,当一个哨兵节点确认Redis集群的主节点主观下线后,会请求其他哨兵节点要求将自己选举为Leader。被请求的哨兵节点如果没有同意过其他哨兵节点的选举请求,则同意该请求,也就是选举票数+1,否则不同意。
![]()

如果一个哨兵节点获得的选举票数超过节点数的一半,且大于quorum配置的值,则该哨兵节点选举为Leader;否则重新进行选举。
![]()

PART4 性能优化
![]()
Redis性能怎么样?


只能说在十万级。使用之前,要跑BenchMark,实际情况下会受带宽、负载、单个数据大小、是否开启多线程等因素影响,脱开具体场景谈性能,就没有意义。
![]()

![]()
Redis性能这么高,那它是协程模型,还是多线程模型?


Redis是单线程Reactor模型,通过高效的IO复用以及内存处理实现高性能。如果是6.0之前我会毫不犹豫说是单线程,6.0之后,我还是会说单线程,但会补充一句,IO解包通过多线程进行了优化,而处理逻辑,还是单线程。
![]()

另外,如果考虑到RDB的Fork,一些定时任务的处理,那么Redis也可以说多进程,这没有问题。但是Redis对数据的处理,至始至终,都是单线程。


![]()
可以详细说下6.0版本发布的多线程功能吗?


多线程功能,主要用于提高解包的效率。和传统的Multi Reactor多线程模型不同,Redis的多线程只负责处理网络IO的解包和协议转换,一方面是因为Redis的单线程处理足够快,另一方面也是为了兼容性做考虑。
![]()

![]()
如果数据太大,Redis存不下了怎么办?


使用集群模式。也就是将数据分片,不同的Key根据Hash路由到不同的节点。集群索引是通过一致性Hash算法来完成,这种算法可以解决服务器数量发生改变时,所有的服务器缓存在同一时间失效的问题。
![]()

同时,基于Gossip协议,集群状态变化时,如新节点加入、节点宕机、Slave提升为新Master,这些变化都能传播到整个集群的所有节点并达成一致。
![]()
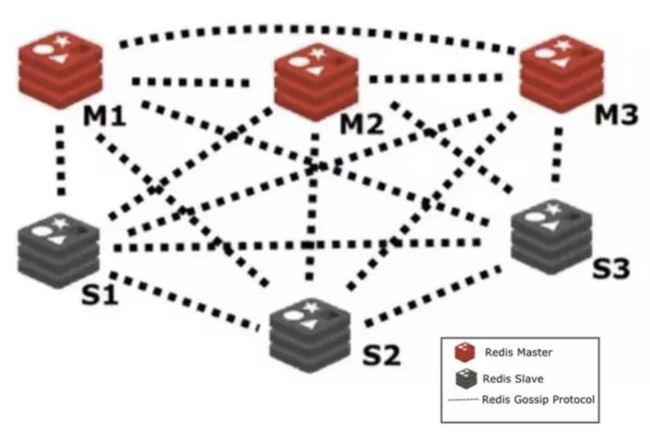
![]()
一致性Hash能详细讲一下吗?


好的,传统的Hash分片,可以将某个Key,落到某个节点。但有一个问题,当节点扩容或者缩容,路由会被完全打乱。如果是缓存场景,很容易造成缓存雪崩问题。
![]()
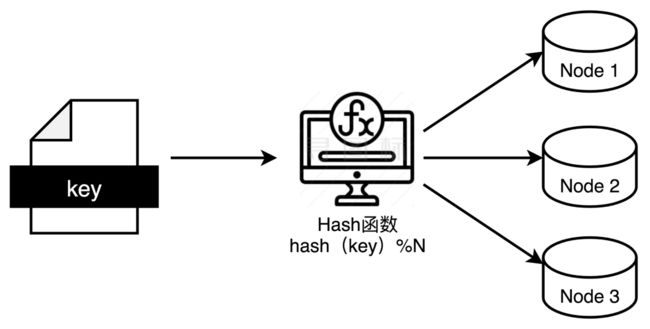

为了优化这种情况,一致性Hash就应运而生了。一致性Hash是说将数据和服务器,以相同的Hash函数,映射到同一个Hash环上,针对一个对象,在哈希环上顺时针查找距其最近的机器,这个机器就负责处理该对象的相关请求。
![]()

这种情况下,增加节点,只会分流后面一个节点的数据。减少节点,那么请求会由后一个节点继承。也就是说,节点变化操作,最多只会影响后面一个节点的数据。

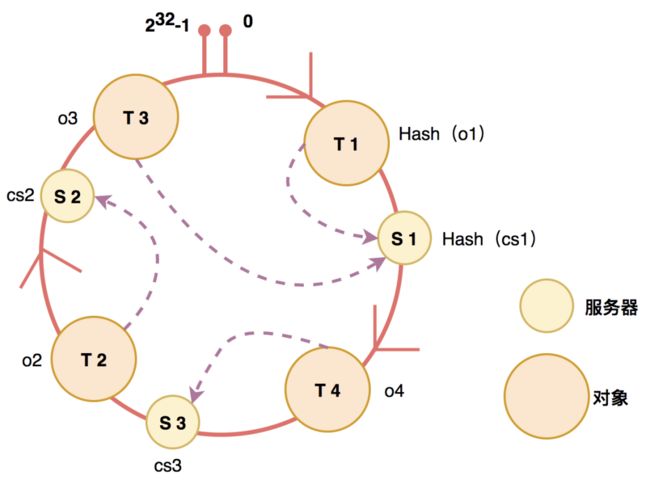
![]()
好了,看你对Redis掌握还不错,下面我们来聊聊场景相关的应用吧。

PART5 场景应用
![]()
Redis经常用作缓存,那数据一致性怎么保证?


从设计思路来说,有Cache Aside和Read/Write Through两种模式,前者是把缓存责任交给应用层,后者是将缓存的责任,放置到服务提供方。
![]()
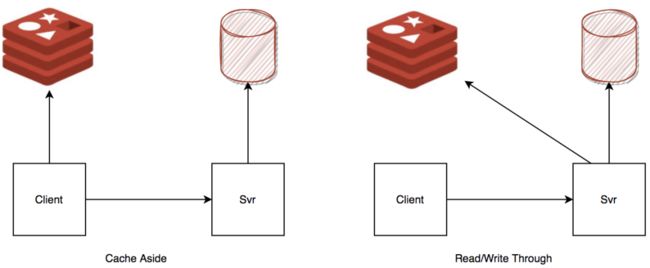
![]()
你说到两种模式,那么哪种模式更好呢?


两种模式各有优缺点,从透明性考虑,服务方比较合适;如果从性能极致来说,业务方会更有优势,毕竟可以减去服务RPC的损耗。
![]()
![]()
嗯,如果数据发生变化,你会怎样去更新缓存?


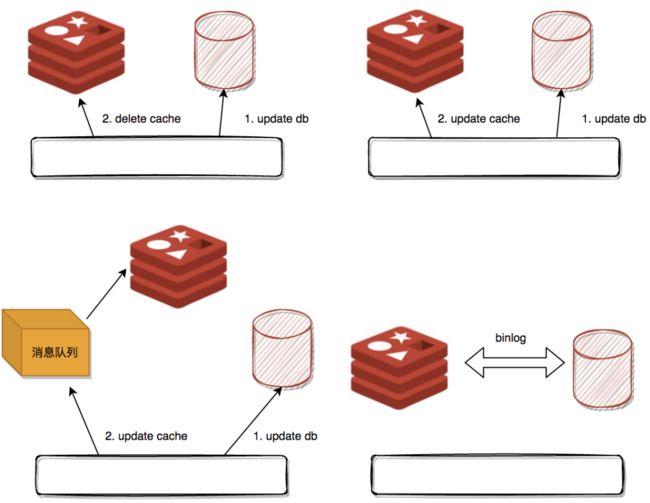
更新方式的话,大概有四种:
![]()

1.数据存到数据库中,成功后,再让缓存失效,等到读缓存不命中的时候,再加载进去;
![]()

2.通过消息队列更新缓存;
![]()

3.先更新缓存,再更新服务,这种情况相当于把Cache也做Buffer用;
![]()

4.起一个同步服务,作为MySQL一个从节点,通过解析binlog同步重要缓存。
![]()
![]()
那我们来谈谈Redis缓存雪崩。


缓存雪崩表示在某一时间段,缓存集中失效,导致请求全部走数据库,有可能搞垮数据库,使整个服务瘫痪。雪崩原因一般是由于缓存过期时间设置得相同造成的。
![]()


针对这种情况,可以借鉴ETCD中Raft选举的优化,让过期时间随机化,避免同一批请求,在同一时间过期。另一方面,还可以业务层面容灾,为热点数据使用双缓存。
![]()
![]()
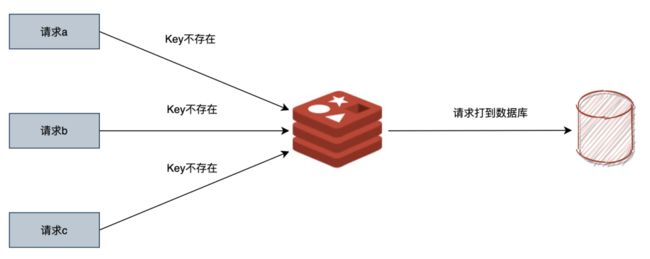
那Redis缓存穿透又是什么?


缓存穿透指请求数据库里面根本没有的数据,高频请求不存在的Key,有可能是正常的业务逻辑,但更可能的,是黑客的攻击。
![]()

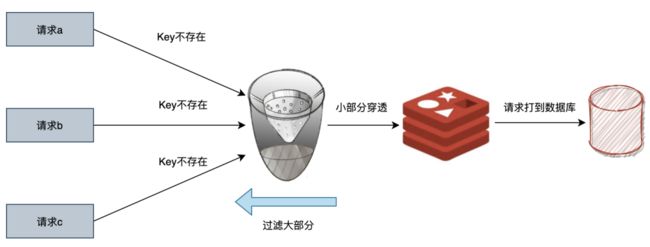
可以用布隆过滤器来应对,布隆过滤器是一种比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉我们 “某样东西一定不存在或者可能存在”。
![]()
![]()
那你说一下布隆过滤器的实现吧。


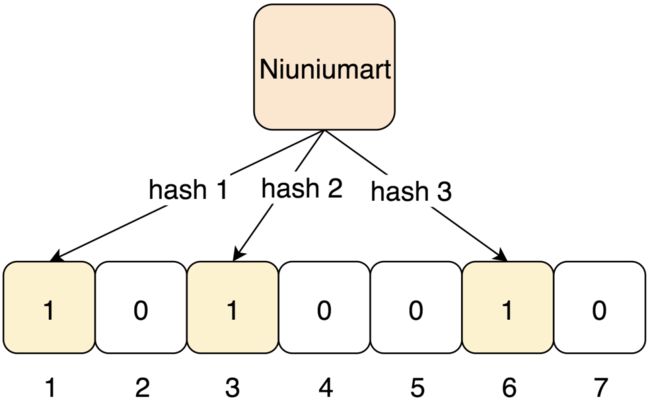
布隆过滤器底层是一个64位的整型,将字符串用多个Hash函数映射不同的二进制位置,将整型中对应位置设置为1。
![]()

在查询的时候,如果一个字符串所有Hash函数映射的值都存在,那么数据可能存在。为什么说可能呢,就是因为其他字符可能占据该值,提前点亮。
![]()

可以看到,布隆过滤器优缺点都很明显,优点是空间、时间消耗都很小,缺点是结果不是完全准确。

![]()
还有个概念叫缓存击穿,你能讲讲看吗?


嗯...缓存击穿,是指某一热键,被超高的并发访问,在失效的一瞬间,还没来得及重新产生,就有海量数据,直达数据库,可谓是兵临城下。
![]()

这种情况和缓存雪崩的不同之处,在于雪崩是大量缓存赶巧儿一起过期,击穿只是单个超热键失效。
![]()


这种超高频Key,我们要提高待遇,可以让它不过期,再单独实现数据同步逻辑,来维护数据的一致性。当然,无论如何,对后端肯定是需要限频的,不然如果Redis数据丢失,数据库还是会被打崩。限频方式可以是分布式锁或分布式令牌桶。
![]()
![]()
那Redis可以做消息队列吗?


嗯...可以是可以,但我觉得用它来做消息队列不合适。Redis本身没有支持AMQP规范,消息队列该有的能力缺胳膊少腿,消息可靠性不强。
![]()

因为总有人拿Redis做消息队列。Redis的作者都看不下去了,赶紧出了个Disque来专事专做,虽然没大红大紫,但至少明确告诉了我们,Redis,别拿来做消息队列!
![]()

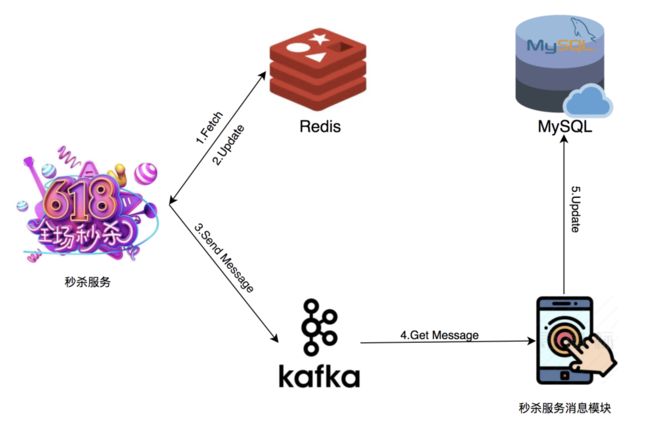
那你能谈谈Redis在秒杀场景的应用吗?


Redis主要是起到选拔流量的作用,记录商品总数,还有就是已下单数,等达到总数之后拦截所有请求。可以多放些请求进来,然后塞入消息队列。


蚂蚁金服的云Redis提到消息队列可以用Redis来实现,但我觉得更好的方式是用Kafka这种标准消息队列组件。
![]()
![]()
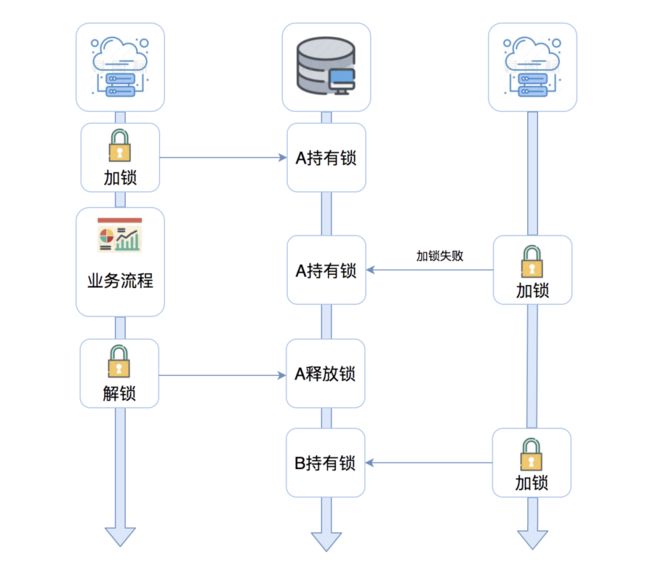
你能继续说说Redis在分布式锁中的应用吗?


锁是计算机领域一个非常常见的概念,分布式锁也依赖存储组件,针对请求量的不同,可以选择Etcd、MySQL、Redis等。前两者可靠性更强,Redis性能更高。
![]()
![]()
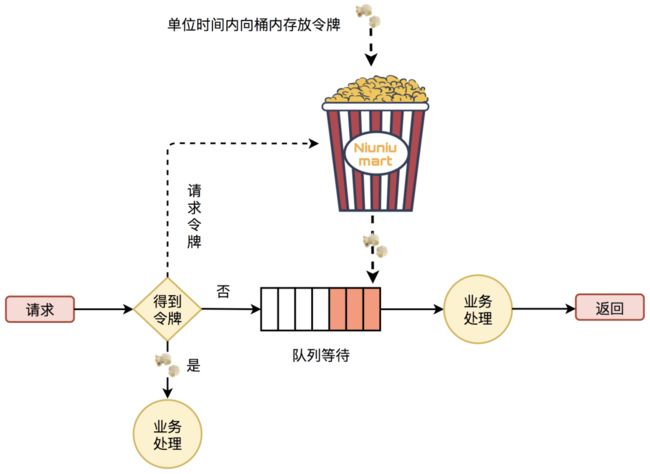
那我们再聊聊Redis在限流场景的应用吧。


在微服务架构下,限频器也需要分布式化。无论是哪种算法,都可以结合Redis来实现。这里我比较熟悉的是基于Redis的分布式令牌桶。
![]()

很显然,Redis负责管理令牌,微服务需要进行函数操作,就向Redis申请令牌,如果Redis当前还有令牌,就发放给它。拿到令牌,才能进行下一步操作。
![]()

另一方面,令牌不光要消耗,还需要补充,出于性能考虑,可以使用懒生成的方式:使用令牌时,顺便生成令牌。这样子还有个好处:令牌的获取,和令牌的生成,都可以在一个Lua脚本中,保证了原子性。
![]()
![]()
可以了,你就是我们想要的仔。

PART6 面试点评
Redis是后台开发中非常重要的领域,更是面试环节的高频考点,希望通过这种形式,让大家切身体会到面试的要点在哪里,并针对这些做专门的准备。
本次阿柴凭借着极高的修为,击退了恶魔面试官牛牛,但这不是结束,仅仅是个开端。