NLP面试题Transformer复杂结构模型和简单结构模型的优缺点是什么?
自Attention机制提出后,加入attention的Seq2seq模型在各个任务上都有了提升,所以现在的seq2seq模型指的都是结合RNN和attention的模型。之后google又提出了解决Seq2Seq问题的Transformer模型,用全attention的结构代替了lstm,在翻译任务上取得了更好的成绩。本文主要介绍《Attention is all you need》这篇文章,自己在最初阅读的时候还是有些不懂,希望可以在自己的解读下让大家更快地理解这个模型^ ^
Attention原理还不熟悉的可以看:
- 【NLP】Attention原理详解
- Tensorflow版BERT中文模型踩坑总结
1. 模型结构
模型结构如下图:

和大多数seq2seq模型一样,transformer的结构也是由encoder和decoder组成。
1.1 Encoder
Encoder由N=6个相同的layer组成,layer指的就是上图左侧的单元,最左边有个“Nx”,这里是x6个。每个Layer由两个sub-layer组成,分别是multi-head self-attention mechanism和fully connected feed-forward network。其中每个sub-layer都加了residual connection和normalisation,因此可以将sub-layer的输出表示为: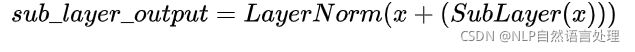
接下来按顺序解释一下这两个sub-layer:
- Multi-head self-attention
熟悉attention原理的童鞋都知道,attention可由以下形式表示:![]()
multi-head attention则是通过h个不同的线性变换对Q,K,V进行投影,最后将不同的attention结果拼接起来:
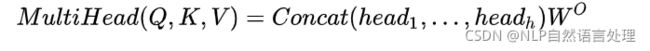
![]()
self-attention则是取Q,K,V相同。
另外,文章中attention的计算采用了scaled dot-product,即: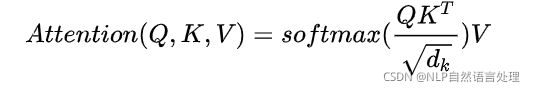
作者同样提到了另一种复杂度相似但计算方法additive attention,在 ![]() 很小的时候和dot-product结果相似,大的时候,如果不进行缩放则表现更好,但dot-product的计算速度更快,进行缩放后可减少影响(由于softmax使梯度过小,具体可见论文中的引用)。
很小的时候和dot-product结果相似,大的时候,如果不进行缩放则表现更好,但dot-product的计算速度更快,进行缩放后可减少影响(由于softmax使梯度过小,具体可见论文中的引用)。
- Position-wise feed-forward networks
这层主要是提供非线性变换。Attention输出的维度是[bsz*seq_len, num_heads*head_size],第二个sub-layer是个全连接层,之所以是position-wise是因为过线性层时每个位置i的变换参数是一样的。
1.2 Decoder
Decoder和Encoder的结构差不多,但是多了一个attention的sub-layer,这里先明确一下decoder的输入输出和解码过程:
- 输出:对应i位置的输出词的概率分布
- 输入:encoder的输出 & 对应i-1位置decoder的输出。所以中间的attention不是self-attention,它的K,V来自encoder,Q来自上一位置decoder的输出
- 解码:这里要注意一下,训练和预测是不一样的。在训练时,解码是一次全部decode出来,用上一步的ground truth来预测(mask矩阵也会改动,让解码时看不到未来的token);而预测时,因为没有ground truth了,需要一个个预测。
文末附上我总结的BERT面试点&相关模型汇总,还有NLP组队学习群的加群方式~明确了解码过程之后最上面的图就很好懂了,这里主要的不同就是新加的另外要说一下新加的attention多加了一个mask,因为训练时的output都是ground truth,这样可以确保预测第i个位置时不会接触到未来的信息。
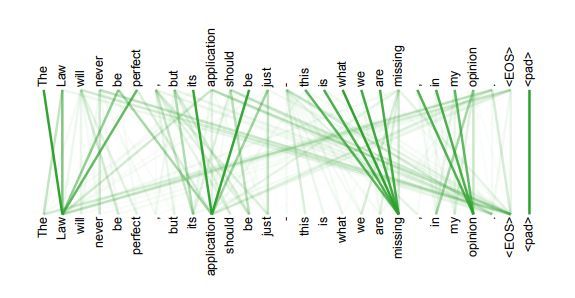
加了mask的attention原理如图(另附multi-head attention):

1.3 Positional Encoding
除了主要的Encoder和Decoder,还有数据预处理的部分。Transformer抛弃了RNN,而RNN最大的优点就是在时间序列上对数据的抽象,所以文章中作者提出两种Positional Encoding的方法,将encoding后的数据与embedding数据求和,加入了相对位置信息。
这里作者提到了两种方法:
- 用不同频率的sine和cosine函数直接计算
- 学习出一份positional embedding(参考文献)
经过实验发现两者的结果一样,所以最后选择了第一种方法,公式如下:
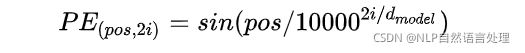

作者提到,方法1的好处有两点:
- 任意位置的
 都可以被 的线性函数表示,三角函数特性复习下:
都可以被 的线性函数表示,三角函数特性复习下:
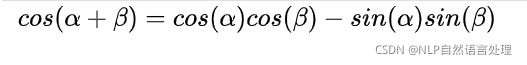
![]()
2. 如果是学习到的positional embedding,(个人认为,没看论文)会像词向量一样受限于词典大小。也就是只能学习到“位置2对应的向量是(1,1,1,2)”这样的表示。所以用三角公式明显不受序列长度的限制,也就是可以对 比所遇到序列的更长的序列 进行表示。
2. 优点
作者主要讲了以下三点:

- Total computational complexity per layer (每层计算复杂度)
2. Amount of computation that can be parallelized, as mesured by the minimum number of sequential operations required
作者用最小的序列化运算来测量可以被并行化的计算。也就是说对于某个序列![]() ,self-attention可以直接计算 的点乘结果,而rnn就必须按照顺序从 计算到
,self-attention可以直接计算 的点乘结果,而rnn就必须按照顺序从 计算到
3. Path length between long-range dependencies in the network
这里Path length指的是要计算一个序列长度为n的信息要经过的路径长度。cnn需要增加卷积层数来扩大视野,rnn需要从1到n逐个进行计算,而self-attention只需要一步矩阵计算就可以。所以也可以看出,self-attention可以比rnn更好地解决长时依赖问题。当然如果计算量太大,比如序列长度n>序列维度d这种情况,也可以用窗口限制self-attention的计算数量
4. 另外,从作者在附录中给出的栗子可以看出,self-attention模型更可解释,attention结果的分布表明了该模型学习到了一些语法和语义信息
3. 缺点
缺点在原文中没有提到,是后来在Universal Transformers中指出的,在这里加一下吧,主要是两点:
- 实践上:有些rnn轻易可以解决的问题transformer没做到,比如复制string,或者推理时碰到的sequence长度比训练时更长(因为碰到了没见过的position embedding)
- 理论上:transformers非computationally universal(图灵完备),(我认为)因为无法实现“while”循环
4. 总结
Transformer是第一个用纯attention搭建的模型,不仅计算速度更快,在翻译任务上获得了更好的结果,也为后续的BERT模型做了铺垫。
更多面试题可以关注星空智能对话机器人的Gavin的公开课

以往公开课选段视频如下:
NLP星空对话机器人Transformer课程片段2:数学内幕、注意力机制代码实现、及Transformer可视化。验证密码:456
GavinNLP星空对话机器人Transformer课程片段3:以对话机器人的流式架构为例阐述Transformer学习的第三境界
星空智能对话机器人的Gavin认为Transformer是拥抱数据不确定性的艺术。
Transformer的架构、训练及推理等都是在Bayesian神经网络不确定性数学思维下来完成的。Encoder-Decoder架构、Multi-head注意力机制、Dropout和残差网络等都是Bayesian神经网络的具体实现;基于Transformer各种模型变种及实践也都是基于Bayesian思想指导下来应对数据的不确定性;混合使用各种类型的Embeddings来提供更好Prior信息其实是应用Bayesian思想来集成处理信息表达的不确定性、各种现代NLP比赛中高分的作品也大多是通过集成RoBERTa、GPT、ELECTRA、XLNET等Transformer模型等来尽力从最大程度来对抗模型信息表示和推理的不确定性。
从数学原理的角度来说,传统Machine Learning及Deep learning算法训练的目标函数一般是基于Naive Bayes数学原理下的最大似然估计MLE和最大后验概率MAP来实现,其核心是寻找出最佳的模型参数;而Bayesian的核心是通过计算后验概率Posterior的predictive distribution,其通过提供模型的不确定来更好的表达信息及应对不确定性。对于Bayesian架构而言,多视角的先验概率Prior知识是基础,在只有小数据甚至没有数据的时候是主要依赖模型Prior概率分布(例如经典的高斯分布)来进行模型推理,随着数据的增加,多个模型会不断更新每个模型的参数来更加趋近真实数据的模型概率分布;与此同时,由于(理论上)集成所有的模型参数来进行Inference,所以Bayesian神经网络能够基于概率对结果的提供基于置信度Confidence的分布区间,从而在各种推理任务中更好的掌握数据的不确定性。
当然,由于Bayesian模型因为昂贵的CPU、Memory及Network的使用,在实际工程实践中计算Bayesian神经网络中所有概率模型分布P(B)是棘手的甚至是Intractable的几乎不能实现事情,所以在工程落地的时候会采用Sampling技术例如MCMC的Collapsed Gibbs Sampling、Metropolis Hastings、Rejection Sampling及Variational Inference的Mean Field及Stochastic等方法来降低训练和推理的成本。Transformer落地Bayesian思想的时候权衡多种因素而实现最大程度的近似估计Approximation,例如起使用了计算上相对CNN、RNN等具有更高CPU和内存使用性价比的Multi-head self-attention机制来完成更多视角信息集成的表达,在Decoder端训练时候一般也会使用多维度的Prior信息完成更快的训练速度及更高质量的模型训练,在正常的工程落地中Transformer一般也会集成不同来源的Embeddings,例如星空智能对话机器人的Transformer实现中就把One-hot encoding、Word2vec、fastText、GRU、BERT等encoding集成来更多层级和更多视角的表达信息。
拥抱数据不确定性的Transformer基于Bayesian下共轭先验分布conjugate prior distribution等特性形成了能够整合各种Prior知识及多元化进行信息表达、及廉价训练和推理的理想架构。理论上讲Transformer能够更好的处理一切以 “set of units” 存在的数据,而计算机视觉、语音、自然语言处理等属于这种类型的数据,所以理论上讲Transformer会在接下来数十年对这些领域形成主导性的统治力。
基于此,我们开发了全新一代围绕Transformer的自然语言处理课程:
NLP on Transformers 101
(基于Transformer的NLP智能对话机器人实战课程)
本课程以Transformer架构为基石、萃取NLP中最具有使用价值的内容、围绕手动实现工业级智能业务对话机器人所需要的全生命周期知识点展开,学习完成后不仅能够从算法、源码、实战等方面融汇贯通NLP领域NLU、NLI、NLG等所有核心环节,同时会具备独自开发业界领先智能业务对话机器人的知识体系、工具方法、及参考源码,成为具备NLP硬实力的业界Top 1%人才。
课程特色:
101章围绕Transformer而诞生的NLP实用课程
5137个围绕Transformers的NLP细分知识点
大小近1200个代码案例落地所有课程内容
10000+行纯手工实现工业级智能业务对话机器人
在具体架构场景和项目案例中习得AI相关数学知识
以贝叶斯深度学习下Attention机制为基石架构整个课程
五大NLP大赛全生命周期讲解并包含比赛的完整代码实现