轻量化网络—ShuffleNet V1 V2理解
轻量化网络—ShuffleNetV2理解
ShuffleNetV2原始论文:https://openaccess.thecvf.com/content_ECCV_2018/html/Ningning_Light-weight_CNN_Architecture_ECCV_2018_paper.html
ShuffleNetV1原始论文:
https://openaccess.thecvf.com/content_cvpr_2018/html/Zhang_ShuffleNet_An_Extremely_CVPR_2018_paper.html
旷视官方开源ShuffleNet代码:https://github.com/megvii-model/ShuffleNet-Series
社区代码复现:https://github.com/xiaohu2015/DeepLearning_tutorials/blob/master/CNNs/ShuffleNet.py
社区代码复现:https://github.com/miaow1988/ShuffleNet_V2_pytorch_caffe
一、轻量化网络分类
- 压缩已经训练好的模型:知识蒸馏 权值量化 剪枝 注意力迁移
- 直接训练轻量化网络:squeezeNet mobileNet Mnasnet Xception EfficientNet
- 加速卷积运算:im2col+GEMM Wingrad 低秩分解
- 硬件部署:TensorRT Jetson Tensorflow openvino FPGA集成电路
ShuffleNet属于直接训练的轻量化网络,通俗来说,就是生下来就是一个轻量化网络,无需再压缩。
轻量化网络可以说是在“带着镣铐跳舞”,所谓的“镣铐”,是指有许多的参数指标限定:
- 计算量 参数量 内存访问量(MAC) 耗时 碳排放
- CUDA加速 对抗学习 Transformer Attention Nas
二、ShuffleNet V1理解
2.1、分组1*1卷积 Group Convolution
每个卷积核不再处理所有的输入通道,而是只处理一部分的输入通道。从下图中可以看出,采用 Group Convolution将参数量降为原来的1/3,计算量也大大降低。

2.2、通道重排 Channel Shuffle
通道重排操作实现跨通道的信息交流。如下图,红绿蓝三个channel等分成3个部分,再进行重新组合成三个新的channel,实现信息交互。

通道重排步骤
- reshape成g行n列的矩阵
- Transpose转置
- flatten

2.3、网络模型
(a )以depthwise convolution为骨干网络模型。
(b )以pointwise group和channel shuffle为骨干网络模型。
(c )下采样模型,采用concat连接方法。

2.4、核心代码复现
class ShuffleV1Block(nn.Module):
def __init__(self, inp, oup, *, group, first_group, mid_channels, ksize, stride):
super(ShuffleV1Block, self).__init__()
self.stride = stride
assert stride in [1, 2]
self.mid_channels = mid_channels
self.ksize = ksize
pad = ksize // 2
self.pad = pad
self.inp = inp
self.group = group
if stride == 2:
outputs = oup - inp
else:
outputs = oup
branch_main_1 = [
# pw
nn.Conv2d(inp, mid_channels, 1, 1, 0, groups=1 if first_group else group, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
# dw
nn.Conv2d(mid_channels, mid_channels, ksize, stride, pad, groups=mid_channels, bias=False),
nn.BatchNorm2d(mid_channels),
]
branch_main_2 = [
# pw-linear
nn.Conv2d(mid_channels, outputs, 1, 1, 0, groups=group, bias=False),
nn.BatchNorm2d(outputs),
]
self.branch_main_1 = nn.Sequential(*branch_main_1)
self.branch_main_2 = nn.Sequential(*branch_main_2)
if stride == 2:
self.branch_proj = nn.AvgPool2d(kernel_size=3, stride=2, padding=1)
def forward(self, old_x):
x = old_x
x_proj = old_x
x = self.branch_main_1(x)
if self.group > 1:
x = self.channel_shuffle(x)
x = self.branch_main_2(x)
if self.stride == 1:
return F.relu(x + x_proj)
elif self.stride == 2:
return torch.cat((self.branch_proj(x_proj), F.relu(x)), 1)
def channel_shuffle(self, x):
batchsize, num_channels, height, width = x.data.size()
assert num_channels % self.group == 0
group_channels = num_channels // self.group
x = x.reshape(batchsize, group_channels, self.group, height, width)
x = x.permute(0, 2, 1, 3, 4)
x = x.reshape(batchsize, num_channels, height, width)
return x
三、ShuffleNet V2理解
3.1、四条轻量化网络设计原则
在ShuffleNet V2论文中,作者通过测试,总结出四条轻量化网络的设计原则,下图为将MobileNet和ShuffleNet分别部署在CPU和ARM上得到的测试结果:
- FLOPS仅反映卷积层,是衡量一个网络的间接指标,而非直接指标。
- 不同硬件上的测试结果不同。
- 数据读写MAC占用影响大。
- Element-wise逐元素(add逐元素相加操作,Relu激活函数…)操作带来的开销不可忽略。

3.2、四点准则/改进(核心)
3.2.1、输入输出通道相同时,MAC最小
对于轻量级CNN网络,常采用深度可分割卷积(depthwise separable convolutions),其中点卷积( pointwise convolution)即1x1卷积复杂度最大。
这里假定输入和输出特征的通道数分别为 c1 和 c2 ,特征图的空间大小为 hw,那么1x1卷积的FLOPs为 B=c1c2hw 。对应的MAC为hw(c1+c2)+c1c2 (这里假定内存足够)。

根据均值不等式,可得:
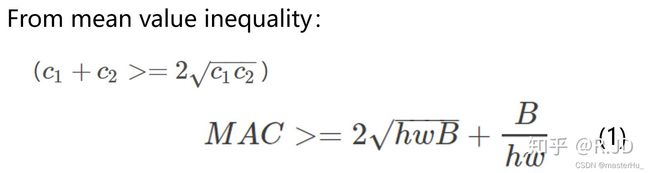
3.2.2、分组数过大的分组会增加MAC
变量g为不同的分组数,GPU的FLOPS相同,分组数越多,推理越慢,MAC越大,特别对于GPU。

3.2.3、碎片化操作对并行加速不友好
series为串行操作,parallel为并行操作。在AlexNet、MobileNet、Xception中运用了并行操作。
碎片化操作越多,推理越慢,特别对于GPU并行设备、小型网络。

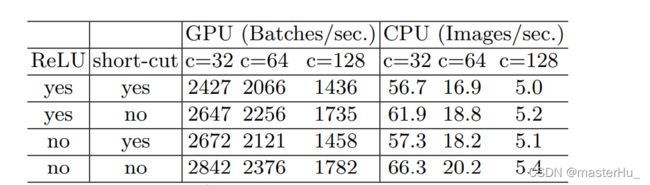
3.2.4、逐元素操作带来的内存耗时不可忽略
逐元素操作包括:add逐元素相加,Relu激活函数等操作。
下表为10个ResNet中的bottlenet模块堆叠,可看出Relu和Short-cut带来的内存消耗和耗时不可忽略。
3.3、改进后的网络模型
(a)ShuffleNet V1基本模型
(b)ShuffleNet V1下采样模型
©ShuffleNet V2 基本模型
(d)ShuffleNet V2下采样模型

改进的点
- 不分组
- 采用channle split
- 取消channel shuffle
- concat连接
3.4、核心代码复现
import torch
import torch.nn as nn
class ShuffleV2Block(nn.Module):
def __init__(self, inp, oup, mid_channels, *, ksize, stride):
super(ShuffleV2Block, self).__init__()
self.stride = stride
assert stride in [1, 2]
self.mid_channels = mid_channels
self.ksize = ksize
pad = ksize // 2
self.pad = pad
self.inp = inp
outputs = oup - inp
branch_main = [
# pw
nn.Conv2d(inp, mid_channels, 1, 1, 0, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
# dw
nn.Conv2d(mid_channels, mid_channels, ksize, stride, pad, groups=mid_channels, bias=False),
nn.BatchNorm2d(mid_channels),
# pw-linear
nn.Conv2d(mid_channels, outputs, 1, 1, 0, bias=False),
nn.BatchNorm2d(outputs),
nn.ReLU(inplace=True),
]
self.branch_main = nn.Sequential(*branch_main)
if stride == 2:
branch_proj = [
# dw
nn.Conv2d(inp, inp, ksize, stride, pad, groups=inp, bias=False),
nn.BatchNorm2d(inp),
# pw-linear
nn.Conv2d(inp, inp, 1, 1, 0, bias=False),
nn.BatchNorm2d(inp),
nn.ReLU(inplace=True),
]
self.branch_proj = nn.Sequential(*branch_proj)
else:
self.branch_proj = None
def forward(self, old_x):
if self.stride==1:
x_proj, x = self.channel_shuffle(old_x)
return torch.cat((x_proj, self.branch_main(x)), 1)
elif self.stride==2:
x_proj = old_x
x = old_x
return torch.cat((self.branch_proj(x_proj), self.branch_main(x)), 1)
def channel_shuffle(self, x):
batchsize, num_channels, height, width = x.data.size()
assert (num_channels % 4 == 0)
x = x.reshape(batchsize * num_channels // 2, 2, height * width)
x = x.permute(1, 0, 2)
x = x.reshape(2, -1, num_channels // 2, height, width)
return x[0], x[1]
四、总结
ShuffleNet算是轻量化网络中性能较高的。在原始论文中讲到ShuffleNet作为目标检测的主干网络也是很不错的,原始论文还做了不少实验,并进行了讨论。ShuffleNet V2在ARM平台上是最快的,在GPU和CPU平台逊色一些。个人认为要深入了解,建议去精度原始论文。
一些参考的资料:
轻量级神经网络“巡礼”(一)——
https://zhuanlan.zhihu.com/p/67009992
机器之心博客:
https://www.jiqizhixin.com/articles/2018-07-29-3
知乎:如何看待 Face++ 旷视科技出品的轻量高效网络 ShuffleNet ?
https://www.zhihu.com/question/62243686
如何评价shufflenet V2?
https://www.zhihu.com/question/287433673/answer/455350957
马宁宁采访:对话ShuffleNet v2一作马宁宁: 疫情居家科研,也能成果斐然
https://zhuanlan.zhihu.com/p/375719361
知乎-科普帖:深度学习中GPU和显存分析:
https://zhuanlan.zhihu.com/p/31558973