【源自paddlex】基于PaddleX的钢板表面缺陷检测
小白第一次尝试投稿,持续了5天对本项目成功运行,过的非常的恍惚,实在是太痛苦!故在此将整个过程记录于此,说明:
1.在源代码的基础上进行了修改(但修改量不大)
2.但是源代码是可以运行出来的
原文地址:
但是建议从此项目中进入:
(理由下文会说)
为之前逃避学习编程留下悔恨的泪水,在此和各位朋友们记录一下前期掉的坑:
本菜主妄想在本地运行这个,那不就意味着都部署环境?!
1.部署tensorflow框架(失败)
2.pycharm+anaconda(数据集分析正确,训练出错)
3.ai studio自带notebook(成功)
创建项目时选择note版本:
1.ai studio经典款
2.BML Codelab(新款)
这个项目的原作者notebook是经典款,而paddlex现在将其更新为BML Codelab,现在社区里多数的项目都是基于此,操作界面类似jupyter notebook,简洁易上手,but!这不是最重要的,最重要的是!!!
这个项目里上传了数据集,直接解压就好了,就不需要大家再从ai studio上下载到本地,再从本地上传至项目里了,毕竟等1.5G上传完...
(+表情包)
这里,我直接放上我的代码和运行截图:
#解压原始数据集severstal-steel-de
!unzip -oq data/data12731/severstal-steel-de -d data/data12731/paddlex是基于Linux内核,所以文件名比较奇怪
-d [路径]:将该压缩文件解压至此[路径]下
运行完成后与该数据集同级目录下将会生成4个文件:
- train_images:该文件夹中存储训练图像
- test_images:该文件夹中存储测试图像
- train.csv:该文件中存储训练图像的缺陷标注,有4类缺陷,ClassId = [1, 2, 3, 4]
- sample_submission.csv:该文件是一个上传文件的样例,每个ImageID要有4行,每一行对应一类缺陷
# 修改两个压缩文件的权限
!chmod 755 data/data12731/train_images.zip
!chmod 755 data/data12731/test_images.zip把光标放在这两个压缩文件上,会发现,运行完前后的变化:
可读:False → 可读:True
#解压压缩文件夹到制定的两个文件夹下(不需要手动创建这两个文件夹)
!unzip -oq data/data12731/train_images.zip -d data/data12731/train_images
!unzip -oq data/data12731/test_images.zip -d data/data12731/test_images解压后会生成这两个新文件夹
(+截图)
# 修改导入权限
!chmod -R 777 /home/aistudio/data/data12731/train.csv
!chmod -R 777 /home/aistudio/data/data12731/sample_submission.csv这个原理和上一条一致
数据可视化
# 导库
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
from pathlib import Path
from collections import defaultdict
import cv2 # 读取csv格式(括号里是csv文件的路径)
train_df = pd.read_csv("data/data12731/train.csv")
sample_df = pd.read_csv("data/data12731/sample_submission.csv")如果我们目前正在运行的这个ipynb文件和这两个csv文件在同一目录下,括号里只需要写这个文件名即可,反之为文件路径。
# 初步查看下里面的数据
print(train_df.head())
print('\r\n')
print(sample_df.head())运行结果如下:

注意数据的标注形式,一共2列:第1列:ImageId_ClassId(图片编号+类编号);第2例EncodedPixels(图像标签)。注意这个图像标签和我们平常遇到的不一样,平常的是一个mask灰度图像,里面有许多数字填充,背景为0,但是这里,为了缩小数据,它使用的是像素“列位置-长度”格式。举个例子:
我们把一个图像(h,w)flatten(注意不是按行而是按列),29102 12 29346 24 29602 24表示从29102像素位置开始的12长度均为非背景,后面以此类推。这就相当于在每个图像上画一条竖线。
# 统计有无缺陷及每类缺陷的图像数量
class_dict = defaultdict(int)
kind_class_dict = defaultdict(int)
no_defects_num = 0
defects_num = 0
for col in range(0, len(train_df), 4):
img_names = [str(i).split("_")[0] for i in train_df.iloc[col:col+4, 0].values]
if not (img_names[0] == img_names[1] == img_names[2] == img_names[3]):
raise ValueError
labels = train_df.iloc[col:col+4, 1]
if labels.isna().all():
no_defects_num += 1
else:
defects_num += 1
kind_class_dict[sum(labels.isna().values == False)] += 1
for idx, label in enumerate(labels.isna().values.tolist()):
if label == False:
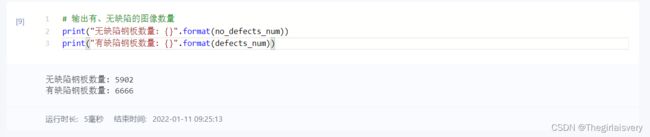
class_dict[idx+1] += 1# 输出有、无缺陷的图像数量
print("无缺陷钢板数量: {}".format(no_defects_num))
print("有缺陷钢板数量: {}".format(defects_num))运行结果如下:
# 接下来对有缺陷的图像进行分类统计:
plt.figure(figsize=(8, 6))
fig, ax = plt.subplots()
sns.barplot(x=list(class_dict.keys()), y=list(class_dict.values()), ax=ax)
ax.set_title("the number of images for each class")
ax.set_xlabel("class")
plt.show()
print(class_dict)# 统计一张图像中可能包含的缺陷种类数
plt.figure(figsize=(8, 6))
fig, ax = plt.subplots()
sns.barplot(x=list(kind_class_dict.keys()), y=list(kind_class_dict.values()), ax=ax)
ax.set_title("Number of classes included in each image");
ax.set_xlabel("number of classes in the image")
plt.show()
print(kind_class_dict) 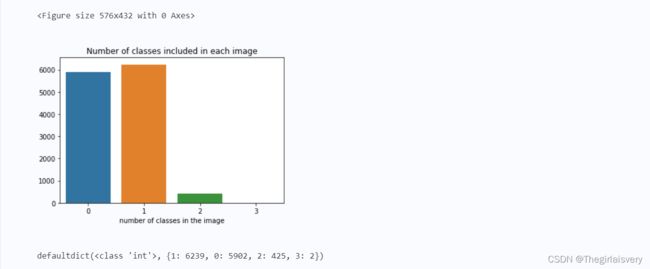
# 读取训练集图像数据
from collections import defaultdict
from pathlib import Path
from PIL import Image
train_size_dict = defaultdict(int)
train_path = Path("data/data12731/train_images")
for img_name in train_path.iterdir():
img = Image.open(img_name)
train_size_dict[img.size] += 1
# 检查下训练集中图像的尺寸和数目
print(train_size_dict)
# 接下来读取测试集图像数据
test_size_dict = defaultdict(int)
test_path = Path("data/data12731/test_images")
for img_name in test_path.iterdir():
img = Image.open(img_name)
test_size_dict[img.size] += 1
print(test_size_dict)
# 可视化数据集:先读取csv文本数据
train_df = pd.read_csv("data/data12731/train.csv") # 下面为了方便可视化,我们为不同的缺陷类别设置颜色显示:
palet = [(249, 192, 12), (0, 185, 241), (114, 0, 218), (249,50,12)]
plt.figure(figsize=(8, 6))
fig, ax = plt.subplots(1, 4, figsize=(15, 5))
for i in range(4):
ax[i].axis('off')
ax[i].imshow(np.ones((50, 50, 3), dtype=np.uint8) * palet[i])
ax[i].set_title("class color: {}".format(i+1))
fig.suptitle("each class colors")
plt.show()
# 接下来将不同的缺陷标识归类:
idx_no_defect = []
idx_class_1 = []
idx_class_2 = []
idx_class_3 = []
idx_class_4 = []
idx_class_multi = []
idx_class_triple = []
for col in range(0, len(train_df), 4):
img_names = [str(i).split("_")[0] for i in train_df.iloc[col:col+4, 0].values]
if not (img_names[0] == img_names[1] == img_names[2] == img_names[3]):
raise ValueError
labels = train_df.iloc[col:col+4, 1]
if labels.isna().all():
idx_no_defect.append(col)
elif (labels.isna() == [False, True, True, True]).all():
idx_class_1.append(col)
elif (labels.isna() == [True, False, True, True]).all():
idx_class_2.append(col)
elif (labels.isna() == [True, True, False, True]).all():
idx_class_3.append(col)
elif (labels.isna() == [True, True, True, False]).all():
idx_class_4.append(col)
elif labels.isna().sum() == 1:
idx_class_triple.append(col)
else:
idx_class_multi.append(col)
train_path = Path("train_data/data12731/test_imagesimages")# 接下来创建可视化标注函数:
def name_and_mask(start_idx):
col = start_idx
img_names = [str(i).split("_")[0] for i in train_df.iloc[col:col+4, 0].values]
if not (img_names[0] == img_names[1] == img_names[2] == img_names[3]):
raise ValueError
labels = train_df.iloc[col:col+4, 1]
mask = np.zeros((256, 1600, 4), dtype=np.uint8)
for idx, label in enumerate(labels.values):
if label is not np.nan:
mask_label = np.zeros(1600*256, dtype=np.uint8)
label = label.split(" ")
positions = map(int, label[0::2])
length = map(int, label[1::2])
for pos, le in zip(positions, length):
mask_label[pos-1:pos+le-1] = 1
mask[:, :, idx] = mask_label.reshape(256, 1600, order='F') #按列取值reshape
return img_names[0], mask
def show_mask_image(col):
name, mask = name_and_mask(col)
img = cv2.imread(str('data/data12731/train_images' + '/' + name))
fig, ax = plt.subplots(figsize=(15, 15))
for ch in range(4):
contours, _ = cv2.findContours(mask[:, :, ch], cv2.RETR_LIST, cv2.CHAIN_APPROX_NONE)
for i in range(0, len(contours)):
cv2.polylines(img, contours[i], True, palet[ch], 2)
ax.set_title(name)
ax.imshow(img)
plt.show()# 接下来先展示5张无缺陷图像:
for idx in idx_no_defect[:5]:
show_mask_image(idx)

# 仅含第1类缺陷的图像展示:
for idx in idx_class_1[:5]:
show_mask_image(idx)
# 仅含第2类缺陷的图像展示:
for idx in idx_class_2[:5]:
show_mask_image(idx)
# 仅含第3类缺陷的图像展示:
for idx in idx_class_3[:5]:
show_mask_image(idx)
# 仅含第4类缺陷的图像展示:
for idx in idx_class_4[:5]:
show_mask_image(idx) 
# 最后再看下同时具有3种缺陷的图片:
for idx in idx_class_triple:
show_mask_image(idx)
import os
import numpy as np
import pandas as pd
import shutil
import cv2
def name_and_mask(start_idx):
'''
获取文件名和mask
'''
col = start_idx
img_names = [
str(i).split("_")[0] for i in train_df.iloc[col:col + 4, 0].values
]
if not (img_names[0] == img_names[1] == img_names[2] == img_names[3]):
raise ValueError
labels = train_df.iloc[col:col + 4, 1]
mask = np.zeros((256, 1600), dtype=np.uint8)
mask_label = np.zeros(1600 * 256, dtype=np.uint8)
for idx, label in enumerate(labels.values):
if label is not np.nan:
label = label.split(" ")
positions = map(int, label[0::2])
length = map(int, label[1::2])
for pos, le in zip(positions, length):
mask_label[pos - 1:pos + le - 1] = idx + 1
mask[:, :] = mask_label.reshape(256, 1600, order='F') #按列取值reshape
return img_names[0], mask
if __name__ == '__main__':
# 创建数据集目录结构
target_root = "steel"
if os.path.exists(target_root):
shutil.rmtree(target_root)
os.makedirs(target_root)
target_ann = os.path.join(target_root, "Annotations")
if os.path.exists(target_ann):
shutil.rmtree(target_ann)
os.makedirs(target_ann)
target_image = os.path.join(target_root, "JPEGImages")
if os.path.exists(target_image):
shutil.rmtree(target_image)
os.makedirs(target_image)
# 原始数据集图像目录
train_path = "data/data12731/train_images"
# 读取csv文本数据
train_df = pd.read_csv("data/data12731/train.csv")
# 逐个图像生成mask
index = 1
for col in range(0, len(train_df), 4):
img_names = [
str(i).split("_")[0] for i in train_df.iloc[col:col + 4, 0].values
]
if not (img_names[0] == img_names[1] == img_names[2] == img_names[3]):
raise ValueError
name, mask = name_and_mask(col)
# 拷贝img(jpg格式)
src_path = os.path.join(train_path, name)
dst_path = os.path.join(target_image, name)
shutil.copyfile(src_path, dst_path)
# 写入标注文件(png格式)
dst_path = os.path.join(target_ann, name.split('.')[0] + '.png')
cv2.imwrite(dst_path, mask)
print('完成第 ' + str(index) + '张图片')
index += 1
print('全部完成')运行结果如下:

...

- 表面缺陷检测
# 安装PaddleX
!pip install paddlex
# 数据划分
!paddlex --split_dataset --format SEG --dataset_dir steel --val_value 0.1 --test_value 0.05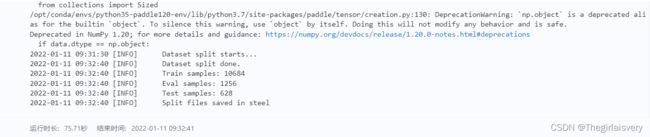
训练模型
!!!到这里请注意,以下将会放上两段代码!!!
第一段是原作者上传的代码,需要循环50次,总计14h左右,本菜主电脑配置比较垃圾,未能成功撑到那么久,但是运行是没问题的,请看截图。
第二段是修改后的代码,因为想快速导出数据,但由于源数据集太大,训练不够,也未能进行,但是运行是没问题的,请看截图。
源代码:
import paddlex as pdx
from paddlex import transforms as T
# 定义预处理变换
train_transforms = T.Compose([
T.Resize(
target_size=[128, 800], interp='LINEAR', keep_ratio=False),
T.RandomHorizontalFlip(),
T.Normalize(
mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
])
eval_transforms = T.Compose([
T.Resize(
target_size=[128, 800], interp='LINEAR', keep_ratio=False),
T.Normalize(
mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
])
# 定义数据集
train_dataset = pdx.datasets.SegDataset(
data_dir='steel',
file_list='steel/train_list.txt',
label_list='steel/labels.txt',
transforms=train_transforms,
num_workers='auto',
shuffle=True)
eval_dataset = pdx.datasets.SegDataset(
data_dir='steel',
file_list='steel/val_list.txt',
label_list='steel/labels.txt',
transforms=eval_transforms,
shuffle=False)
# 定义模型
num_classes = len(train_dataset.labels)
model = pdx.seg.HRNet(num_classes=num_classes, width=48)
# 训练
model.train(
num_epochs=100,
train_dataset=train_dataset,
train_batch_size=48, # 需根据实际显存大小调节
eval_dataset=eval_dataset,
learning_rate=0.04,
use_vdl=True,
save_interval_epochs=1,
save_dir='output/hrnet')
修改后代码:
import paddlex as pdx
from paddlex import transforms as T
# 定义预处理变换
train_transforms = T.Compose([
T.Resize(target_size=[128, 800], interp='LINEAR'),
T.RandomHorizontalFlip(0.5),
T.RandomVerticalFlip(0.5),
T.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
])
eval_transforms = T.Compose([
T.Resize(target_size=[128, 800], interp='LINEAR'),
T.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
])
# 定义数据集
train_dataset = pdx.datasets.SegDataset(
data_dir='steel',
file_list='steel/train_list.txt',
label_list='steel/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.SegDataset(
data_dir='steel',
file_list='steel/val_list.txt',
label_list='steel/labels.txt',
transforms=eval_transforms,
shuffle=False)
# 定义模型
model = pdx.seg.HRNet(
num_classes=len(train_dataset.labels),
use_mixed_loss=True)
# 训练
model.train(
train_dataset=train_dataset,
eval_dataset=eval_dataset,
num_epochs=10,
train_batch_size=16, # 需根据实际显存大小调节
learning_rate=0.025, # 学习率
use_vdl=True,
save_interval_epochs=2,
log_interval_steps=train_dataset.num_samples // 16 // 10,
save_dir='output/HRNet')
import matplotlib.pyplot as plt
%matplotlib inline
import cv2
import numpy as np
model = pdx.load_model('output/UNet/best_model')
result = model.predict('steel/JPEGImages/8f295e1a6.jpg')
pdx.seg.visualize('steel/JPEGImages/8f295e1a6.jpg', result, save_dir='predict/')
result = model.predict('steel/JPEGImages/7f506ca06.jpg')
pdx.seg.visualize('steel/JPEGImages/7f506ca06.jpg', result, save_dir='predict/')
image1 = cv2.imread('predict/visualize_8f295e1a6.jpg')
image2 = cv2.imread('predict/visualize_7f506ca06.jpg')
image1 = cv2.cvtColor(image1, cv2.COLOR_BGR2RGB)
image2 = cv2.cvtColor(image2, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(8, 4))
plt.subplot(211)
plt.imshow(image1)
plt.subplot(212)
plt.imshow(image2)
plt.show()