pix2pix Image-to-Image Translation with Conditional Adversarial Networks笔记及代码实现
1.Introduction
GANs在最近两年得到了广泛的应用,本文研究的技术很多人就已经提到过,尽管如此,之前的论文都是关注特定的应用,而cGANs作为图像转换的问题的通用方法的有效性仍然是不清楚的,我们的主要贡献 在于阐释了cGANs在很多问题上都能产生合理的结果,第二个贡献在于提出来一个简单有效的框架,并分析了几种结构的选择结果
2.Related work
2.1图像建模的结构化损失
Image-to-image 的问题通常被表述为逐像素的分类或者回归问题。这些表述将输出空间看作是非结构化的,即:每个输出的像素都被看作是条件独立于其他所有的像素。cGANs相反,学习结构化的损失(Structured losses),结构化的会对 输出节点的构造进行处罚。大多数文章都考虑这种loss,如条件随机场,SSIM指标,特征匹配,非参数化loss,卷积伪先验,基于匹配协方差统计的损失。cGANs不同于学到的loss,理论上,其实惩罚介于输出和目标之间的任何可能的不同结构。
2.2 条件GAN
前人早就将条件GAN用在如离散标签,文本,和图像等等。图像条件的模型是从一个标准map进行图像预测,未来帧预测,产品照片生成,从稀疏标注中进行图片生成(文献[46]中式用一个自动回归方法来解决这个问题)。其他虽然也有将GAN用在image-to-image上,但是只用无约束GAN,并依赖其他项(如L2回归)来强制输出是约束于输入的。这些文献在如图像修复,未来状态预测,基于用户操作的图像编辑,风格转换和超分辨率。每个方法都只适用具体领域。本文方法希望做到普适,同时这就需要比那些方法相对简单。
不同于之前的几种生成器和判别器的结构选择,本文的生成器使用的是U-Net结构;判别器使用的是卷积“PatchGAN”分类器,其只惩罚在图像块尺度规模上的结构。一个类似的PatchGAN结构在文献中早就有所提及,其实为了抓取局部类型统计。本文展示该方法可以适用更广泛的问题,还分析了更改patch size带来的影响。
3.Method
GAN是生成模型,可以学习一个随机噪声z到输出图像y的映射:G:z→y。而条件GAN是基于观测的图片x和随机噪声z,学习映射到y:G:{x,z}→y。该训练过程如图2.
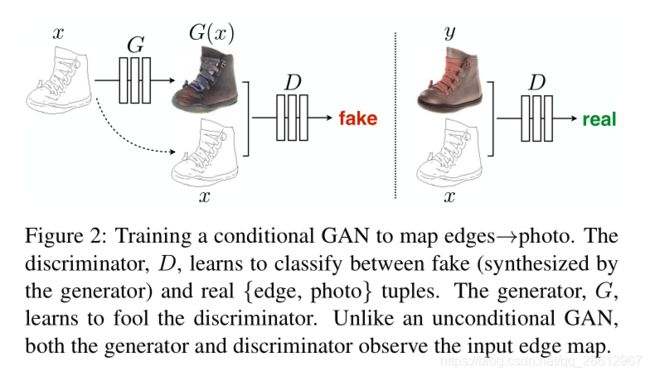
3.1objective
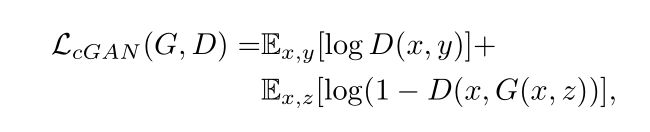
这里G试图最小化该目标函数,而D试图最大化该目标函数,既:![]()
之前的文献已经证实将GAN的目标函数与一些其他loss(如l2距离)混合起来是有好处的。判别器的工作依然没变,但是生成器不止需要欺骗判别器,还需要在受到L2约束下接近ground-truth。本文采用L1距离,因为L1能减少输出的图片模糊:
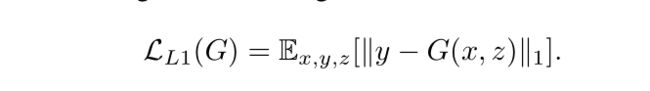
最终的损失函数为:
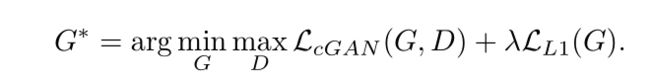
没有z的输入,GAN还是能学到从x到y的映射,但是会产生判别性的输出。因此会无法匹配除了delta函数的其他任何分布。之前的条件GAN意识到了这点,所以给生成器在x之外,提供高斯噪音z作为输入。在初始实验中,作者并未找到该策略的有效性,即让生成器简单忽略该噪音,这与Mathieu的论证吻合。在本文最终模型中,作者只在在训练和测试阶段的生成器的几层的dropout项中采用噪音。尽管存在dropout噪音,作者只在输出上观察到微小的随机性。设计的条件GAN可以提供高随机性输出,从而捕获它们建模的条件分布的完整熵,是当前工作还没解决的问题。
3.2 Network architectures
本文调整了[43]中的生成器和判别器结构,判别器和生成器同时使用convolution-BatchNorm-ReLU形式的模块。
3.2.1Generator with skips
在输入和输出之间共享大量低级信息是一个很好的想法,并且希望直接在网络上传送该信息。例如,图像着色,输入和输出是共享突出边缘的位置的。
为了让生成器有一种规避bottleneck的方法,增加了skip的连接,形状如U-Net。特别的,在层i和层n−i之间增加skip 连接,这里n是层的总量。每个skip连接简单的将层i与层n−i之间所有的特征通道进行连接。
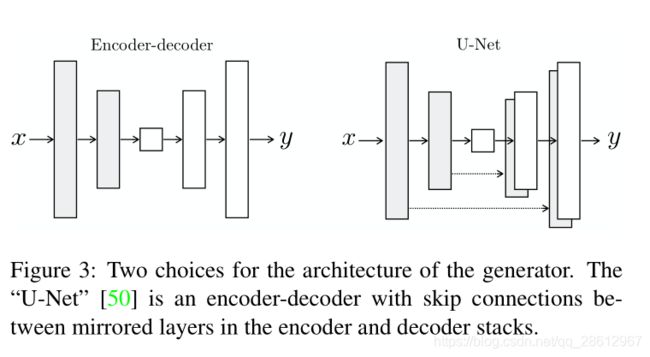
3.2.2 PatchGAN
众所周知L2 loss(看图4,L1也会模糊)会让图像生成问题中生成的图像变得模糊,虽然这些loss不能准确的抓取高频纹理,可是他们还是能够抓取低频轮廓的。对于这种情况,不需要一个全新的框架来强制低频的正确性,L1就够了。
那么受其启发,让GAN判别器只对高频结构进行建模,让L1项去对低频进行建模,如式子4。为了对高频进行建模,需要将注意力限制到局部图像块上。因此,本文设计出一个判别器结构,这里称其为PatchGAN,只惩罚图像块尺度上的结构。该判别器试图区分是否图像中每个N×N块是真的还是假的。将该判别器以卷积方式划过整个图像,平均所有的响应来提供判别器最终的输出。
在后面,证明了虽然N可以远小于图片的完整size,可是仍然可以生成高质量的结果。这是有利的,因为更小的PatchGAN有着更少的参数,运行更快,可以应用在任意大的图像。
这样鉴别器有效地将图像建模为马尔可夫随机场,其是假设像素之间的独立可分性性超过了块的直径。这种联系在文献[37]中有所探讨,同样对纹理模型和风格也有常见假设。PatchGAN因此可以理解成一种纹理/风格 loss形式。
3.3 Optimization and inference
为了优化该网络,遵循标准方法:交替的迭代,先在D上迭代一次,然后在G上迭代一次。如最初始GAN中所述,训练G时,不最小化log(1−D(x,G(x,z))),而是最大化logD(x,G(x,z))。另外,在优化D时,将目标除以2,这让D相对G而言减慢了速度。本文使用minibatch SGD和Adam解析器,学习率为0.0002,动量参数分别为β1=0.5,β2=0.999,
在推论阶段,运行生成器,其配置如训练过程一致。这不同于传统的,在测试时候也还是用dropout,并且基于测试batch使用BN,而不是用训练时候的batch。当batchsize设置为1时,BN被称为“实例标准化”,并且已被证明在图像生成任务中有效[53]。 在本实验中,根据实验使用1到10之间的batchsize。
4.实验
为了研究条件GAN的泛化性,作者在很多任务和数据集上进行了测试,包含图形任务,如相片生成;视觉任务,如语义分割:
- 语义 labels↔
- photo, 基于Cityscapes数据集[11];
- 建筑 labels↔
- photo,基于CMP Facades[44];
- Map↔
- aerial photo, 从谷歌地图爬取的数据;
- BW→
- color photos,基于[50]训练;
- Edges→
- photo, 训练数据来自[64,59];二值边缘使用HED边缘检测器[57]加上后处理完成的;
- Sketch$\rightarrow photo,测试edges
- \rightarrow $photo 人类绘制的模型来自[18];
- Day→
- night,基于[32];
- thermal→
- color photos,训练数据来自[26];
- photo withmissing pixels →
- inpainted photo,基于Paris streetview,来自[13].
每个数据集的详细训练过程在附录材料中。在所有情况中,输入和输出都是1-3通道的图片。结果在图
6.代码
这里有一些简单的实现,kears ,tensorflow
https://github.com/tjwei/GANotebooks