PyTorch: hook机制
hook机制
- register_forward_hook
- register_full_backward_hook
- remove
- visual
在训练神经网络的时候我们有时需要输出网络中间层,一般来说我们有两种处理方法:一种是在model的forward中保存中间层的变量,然后再return的时候将其和结果一起返回;另一种是使用pytorch自带的register_forward_hook,即hook机制
register_forward_hook
register_forward_hook(hook)
- 返回module中的一个前向的hook,这个hook每次在执行forward的时候都会被调用
- hook:
hook(module, input, output)
可能不是很好理解,我们直接用一个例子来说明,如下所示,首先我们将hook包装在类SaveValues中,我们现在想要获取模型Net中的l1的输入和输出,因此将model.l1存入到类中:value = SaveValues(model.l1),在类中定义一个hook_fn_act函数,此函数的作用是随着我们的register_forward_hook函数获取Net的某一层的名字,输入以及输出,在这里对应的就是model.l1, 他的输入和输出,最终我们将他获取的网络层的名字、输入以及输出保存到类SaveValues中方便我们输出
注意:hook_fn_act函数必须有三个参数,分别对应module,input以及output
import torch
import torch.nn as nn
class SaveValues():
def __init__(self, layer):
self.model = None
self.input = None
self.output = None
self.grad_input = None
self.grad_output = None
self.forward_hook = layer.register_forward_hook(self.hook_fn_act)
self.backward_hook = layer.register_full_backward_hook(self.hook_fn_grad)
def hook_fn_act(self, module, input, output):
self.model = module
self.input = input[0]
self.output = output
def hook_fn_grad(self, module, grad_input, grad_output):
self.grad_input = grad_input[0]
self.grad_output = grad_output[0]
def remove(self):
self.forward_hook.remove()
self.backward_hook.remove()
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = nn.Linear(2, 5)
self.l2 = nn.Linear(5, 10)
def forward(self, x):
x = self.l1(x)
x = self.l2(x)
return x
l1loss = nn.L1Loss()
model = Net()
value = SaveValues(model.l2)
gt = torch.ones((10,), dtype=torch.float32, requires_grad=False)
x = torch.ones((2,), dtype=torch.float32, requires_grad=False)
y = model(x)
loss = l1loss(y, gt)
loss.backward()
x += 1.2
value.remove()
运行上述程序,当我们运行到y = model(x)这一行时,我们看一下value中的值(图左),当我们运行完y = model(x)时,我们看一下value中的值(图右),这是因为在执行net中的forward函数时,我们的hook机制会从中提取出网络的输入和输出,不执行forward就不会提取
注意:当我们不想在提取网络中间层时,我们调用value.remove()即可,即删除了网络中的hook。但是在训练网络时我们可能需要输出每个epoch的中间层信息,那么在for循环中就不需要删除hook啦
 |
 |
register_full_backward_hook
好像这个反向hook很少用到?
register_forward_hook(hook)
- 返回module中的一个反向的hook,这个hook每次在执行forward的时候都会被调用
- hook:
hook(module, grad_input, grad_output)
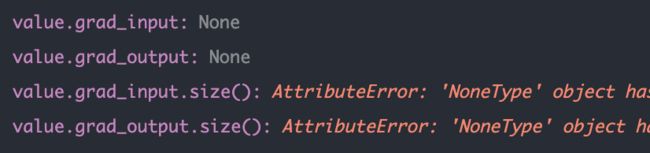
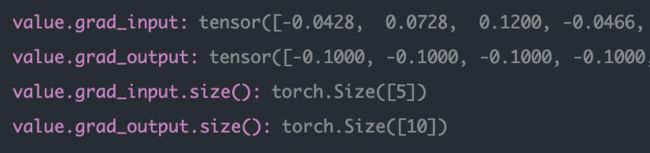
继续上述的代码,这次我们运行到loss.backward()之前与之后查看value中存储的grad的变化,如下所示,可以发现在没有反向传播之前grad为None,当我们执行反向传播之后grad就有值了
注意:这里将layer换成了l2,因为第一层l1经过backward之后依然是左图不变,可能是第一层没有梯度?
value = SaveValues(model.l2) # modify here: model.l1--->model.l2
 |
 |
remove
关于remove其实如果显存足够可以不用remove,虽然每个epoch的时候hook的值都会变化,但是只占用一个hook的内存,除非开销很大可以考虑remove
visual
当我们的SaveValues类提取出特征图之后,就可以对value.output进行可视化啦
当然如果有需要也可以用input、output或者grad进行相应的操作