Python爬虫学习笔记_DAY_30_Python爬虫之scrapy框架管道的使用详细介绍【Python爬虫】
p.s.高产量博主,点个关注不迷路!
目录
I. 回顾scrapy框架结构
II. 定义items数据结构
III. 封装管道文件
IV. 设置settings配置文件
V. 调用管道执行下载
I. 回顾scrapy框架结构
首先,笔记承接上一篇,我们知道一个完整的scrapy框架项目文件有六个部分:
1️⃣ Spiders文件夹:这文件夹我们不陌生,因为每一次新建scrapy爬虫项目后,我们都需要终端进入Spiders文件夹,生产爬虫文件。在Spiders文件夹下,又有两个文件,一个是_init_.py文件,一个是tc.py。_init_.py文件是我们创建项目时默认生成的一个py文件,我们用不到这个py文件,因此我们可以忽略它,另一个tc.py文件是我们爬虫的核心文件,后续的大部分代码都会写入这个文件,因此它是至关重要的py文件。
2️⃣_init_.py文件:它和上面提到的Spiders文件夹下的_init_.py一样,都是不被使用的py文件,无需理会。
3️⃣ items.py文件:这文件定义了数据结构,这里的数据结构与算法中的数据结构不同,它指的是爬虫目标数据的数据组成结构,例如我们需要获取目标网页的图片和图片的名称,那么此时我们的数据组成结构就定义为 图片、图片名称。后续会专门安排对scrapy框架定义数据结构的学习。
4️⃣ middleware.py文件:这py文件包含了scrapy项目的一些中间构件,例如代理、请求方式、执行等等,它对于项目来说是重要的,但对于我们爬虫基础学习来说,可以暂时不考虑更改它的内容。
5️⃣ pipelines.py文件:这是我们之前在工作原理中提到的scrapy框架中的管道文件,管道的作用是执行一些文件的下载,例如图片等,后续会安排对scrapy框架管道的学习,那时会专门研究这个py文件。
6️⃣ settings.py文件:这文件是整个scrapy项目的配置文件,里面是很多参数的设置,我们会偶尔设计到修改该文件中的部分参数,例如下一部分提到的ROBOTS协议限制,就需要进入该文件解除该限制,否则将无法实现爬取。
其中,我们之前重点研究了spiders文件夹下的爬虫文件的书写,本次笔记的重点是对pipelines.py文件的操作,以实现管道下载,同时需要辅助items.py和settings.py文件。
对于管道的使用,大致的流程是这样的:
定义需要下载的数据的数据结构(items.py) - - - > 封装管道(pipelines.py) - - - > 设置settings配置文件(settings.py) - - - > 书写调用管道的代码(爬虫文件)
下面,我们按照这个顺序,依次进行讲解。
II. 定义items数据结构
首先,我们在开始之前,先任意创建一个scrapy框架项目:
打开之前创建过的文件夹,用终端进入这个文件夹(如果之前笔记没有看过的朋友,直接新建一个空文件夹即可,之后用终端进入该文件夹):
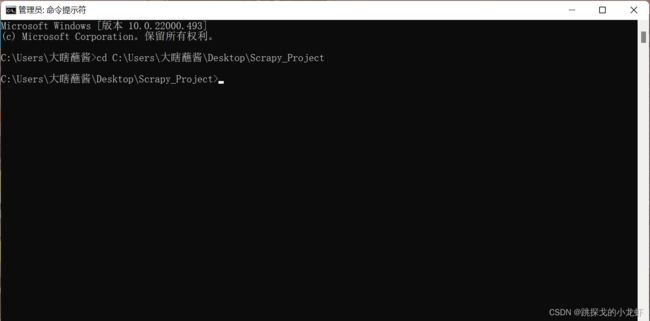
运行项目生成指令:
scrapy startproject pipedemo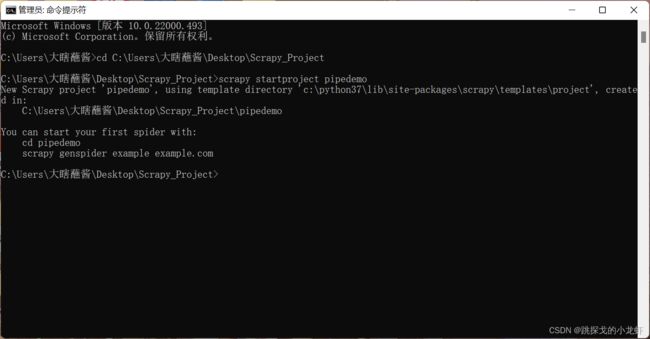
之后,我们创建对应的爬虫文件:
首先终端进入Spiders文件夹:
cd pipedemo/pipedemo/spiders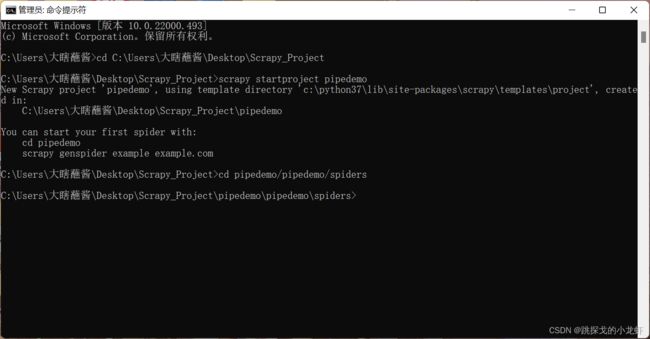
运行爬虫文件生成指令:
scrapy genspider demo https://www.xxx其中 demo 是生成的爬虫文件的文件名,大家可以任意起名,url随便打一个即可,因为我们此时并不真正实现下载,而是作为教学使用。
之后我们就完成了项目的创建,接下来我们把目光转向定义“数据结构”:
我们用pycharm打开项目文件,进入到items.py文件:
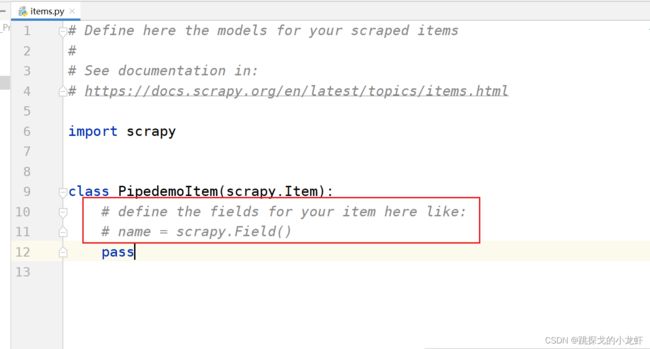
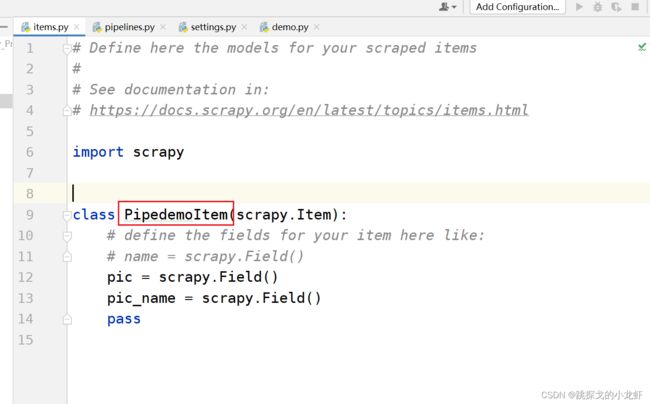
红圈中的注释,其实是告诉我们定义数据结构的语法是怎么样的。我们举一个例子,比如说我们想要下载图片、图片的名字这两项内容,并把图片存成本地的jpg或png格式,图片的名字写入一个json文件中,那么在这里,我们定义数据结构的代码是这样的:
class PipedemoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pic = scrapy.Field()
pic_name = scrapy.Field()
pass可以看出,数据结构的定义代码是很简单的,与注释中的语法完全一致。
下面的部分,我们继续围绕着这个需求去准备:下载图片、图片的名字这两项内容,并把图片存成本地的jpg或png格式,图片的名字写入一个json文件中(多管道同时下载)
III. 封装管道文件
解决了数据结构,接下来我们需要封装一下管道:
打开pipelines.py文件:
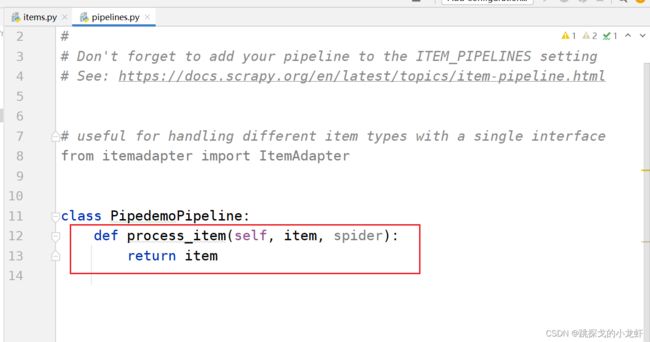
接下来是一个小知识点:管道的核心代码大部分都在它的名叫 process_item(self,item,spider) 这个函数中。
我们于是锁定这个函数体,第二个小知识点是,process_item(self,item,spider) 函数的传参item,是我们在items.py中定义的数据结构对应的数据,也就是说item本身包含了我们传入的初步数据,回忆scrapy框架的工作原理,管道是对数据的二次处理,所以我们会先在爬虫文件中对数据进行解析,解析后的数据才会放进item中,并传入到process_item(self,item,spider) 函数。
于是这里我们先实现保存图片的名称这一步:
class ScrapyDemoPipeline:
def open_spider(self, sipder):
self.fp = open('pic.json','w',encoding = 'utf-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self,spider):
self.fp.close()解释一下,首先,除了process_item()函数外,open_spider()和close_spider()这两个函数也是常用的、scrapy框架中被定义过的函数,只是它们不会默认生成,需要我们自行书写,同时这两个函数有下面的特点:
open_spider()函数和close_spider()函数分别在项目的启动和终止时各自被调用一次。
有了这个特点,我们可以避免反复打开和关闭文件,而是把打开文件和关闭文件的操作放入这两个函数中,在process_item()函数中执行具体写入操作。
在process_item()中,根据刚才的分析,item应该是已经处理好的数据,那我们只需要直接执行内容写入即可。
下面实现同时下载图片的操作:
所谓同时,指的是我们需要再开启一条管道,与之前的管道同时工作,这在scrapy框架中实现的方法是这样的:
我们复制pipelines.py文件中默认给我们生成的类"ScrapyDemoPipeline",并在类的外面黏贴一份,简单的改一个名字:
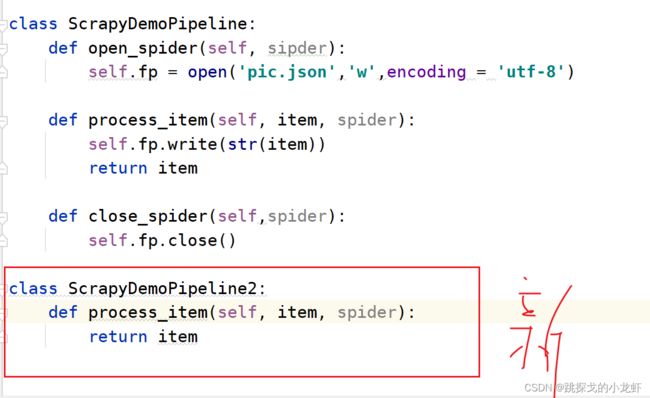
新的类,由于执行的是图片的下载,我们无需open和close函数,默认生成的函数足够。最后只需要在process_item()中写入具体的下载代码即可,思路仍然是通过item提供的url,调用urllib库中的urlopen函数执行下载,于是伪代码可以是这样的:
import urllib.request
class ScrapyDemoPipeline2:
def process_item(self, item, spider):
url = str(item)
urllib.request.urlopen(url,'pic_name')
return itemIV. 设置settings配置文件
上一步,我们封装了管道,那么可能会有一个疑问:我们自己定义的“新管道”,会被执行吗?这里给出肯定的回答:如果不修改其他的内容,刚才定义的管道,甚至是最开始默认生成的管道,都不会被执行。
于是我们在实现管道下载之前,必须必须必须 要修改settings.py配置文件:
打开settings.py文件,找到被注释的一个字典:ITEM_PIPELINES
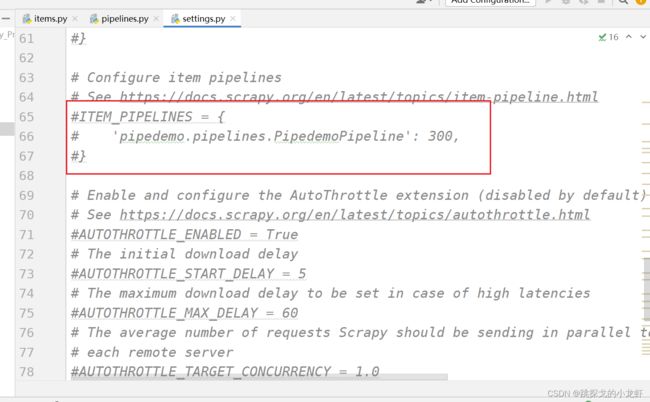
这字典是对默认生成的管道的定义,我们可以发现默认情况下,它是被注释的,于是我们先把它的注释解开,此时默认生成的管道可以工作了。
接下来,我们复制这个字典,黏贴在它的下面,通过观察不难发现,字典里的“键”的部分的最后一截是管道类的类名,于是我们修改类名为我们定义的新管道的类名:
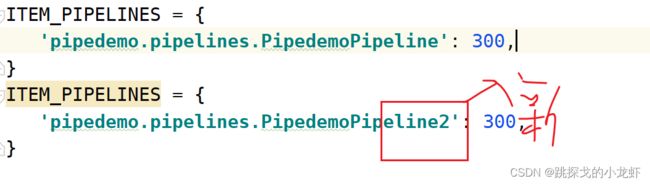
这里对字典的"值"稍作说明:
300,指的是该管道的优先级的大小,这个值在[1,1000]之间,值越小,优先级越高,并且当多个管道同时启用时,该值才有效,我们这里把两个管道都设置为相同优先级即可。
V. 调用管道执行下载
最后一步,我们需要调用管道,开启下载操作。
首先,先想一下为什么需要这步操作:我们回忆一下之前写的scrapy框架项目,会发现每一次我们都是运行的爬虫文件来执行整个项目,也就是说,我们想要使用管道,那么管道必须在爬虫文件中被调用,否则我们封装的管道将失去作用,于是我们转向爬虫文件:demo.py
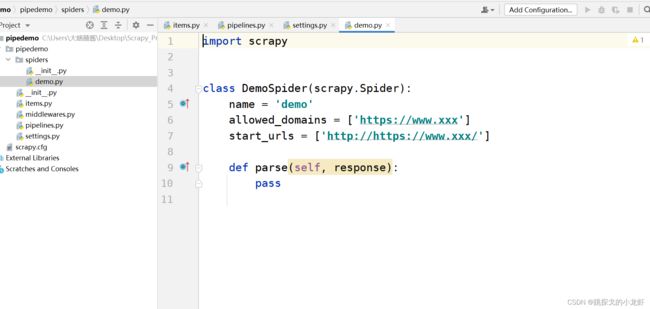
根据之前的经验,我们知道核心代码是写在parse()函数中的,那么我们需要在里面写什么呢:
依照我们前面提到的需求,那么我们需要首先在parse()函数中,提取从服务器发回的响应response,并通过解析response,把合适的数据:图片的url和图片的名称,传给管道,于是伪代码可以这样表示:
def parse(self, response):
pic = response.xpath('...')
pic_name = response.xpath('...')
pass提取数据后,我们传数据到管道之前,还有一小步操作:导入items数据结构:
我们首先再次打开items.py文件,复制一下items.py文件中的类名:
之后回到demo.py文件,在最上面写上导入数据结构的代码:
from pipedemo.items import PipedemoItem这句导入代码的格式是这样的:
from 项目名.items import items文件中的类名
导入数据结构后,我们在传入数据给管道之前,肯定要先定义这个数据,也就是说我们要先定义变量item:
item = PipedemoItem(pic = pic,pic_name = pic_name)我们解释一下传进去的两个参数:pic和pic_name,细心的人应该发现了,这里的pic和pic_name与我们前面在items.py文件中定义的两个数据结构的名字完全一样(因为它们本来就是一回事)。所以我们这里其实是创建了一个对应我们定义的数据结构的对象(面向对象思想)。
最后,我们通过yield关键字,执行item向管道的传入:
yield item没错,只需要一句代码,即可调用管道。那么关于demo.py完整的代码应该是这样的:
import scrapy
from pipedemo.items import PipedemoItem
class DemoSpider(scrapy.Spider):
name = 'demo'
allowed_domains = ['https://www.xxx']
start_urls = ['http://https://www.xxx/']
def parse(self, response):
pic = response.xpath('...')
pic_name = response.xpath('...')
item = PipedemoItem(pic = pic,pic_name = pic_name)
yield item
pass最后,我们再理一下整个的思路:
首先,我们需要定义数据结构
其次,我们需要封装管道
接下来,我们需要在settings配置文件中修改管道配置
最后,我们需要在爬虫文件中完成:响应解析、数据结构对象定义、调用管道
以上是对scrapy框架管道使用的详细介绍,觉得有帮助可以三连支持一下!