MySQL笔记
一、SQL快速入门
MySQL笔记
MySQL函数
MySQL 数值型函数
| 函数名称 | 作 用 |
|---|---|
| ABS | 求绝对值 |
| SQRT | 求二次方根 |
| MOD | 求余数 |
| CEIL 和 CEILING | 两个函数功能相同,都是返回不小于参数的最小整数,即向上取整 |
| FLOOR | 向下取整,返回值转化为一个BIGINT |
| RAND | 生成一个0~1之间的随机数,传入整数参数是,用来产生重复序列 |
| ROUND | 对所传参数进行四舍五入 |
| SIGN | 返回参数的符号 |
| POW 和 POWER | 两个函数的功能相同,都是所传参数的次方的结果值 |
| SIN | 求正弦值 |
| ASIN | 求反正弦值,与函数 SIN 互为反函数 |
| COS | 求余弦值 |
| ACOS | 求反余弦值,与函数 COS 互为反函数 |
| TAN | 求正切值 |
| ATAN | 求反正切值,与函数 TAN 互为反函数 |
| COT | 求余切值 |
MySQL 字符串函数
| 函数名称 | 作 用 |
|---|---|
| LENGTH | 计算字符串长度函数,返回字符串的字节长度 |
| CONCAT | 合并字符串函数,返回结果为连接参数产生的字符串,参数可以使一个或多个 |
| INSERT | 替换字符串函数 |
| LOWER | 将字符串中的字母转换为小写 |
| UPPER | 将字符串中的字母转换为大写 |
| LEFT | 从左侧字截取符串,返回字符串左边的若干个字符 |
| RIGHT | 从右侧字截取符串,返回字符串右边的若干个字符 |
| TRIM | 删除字符串左右两侧的空格 |
| REPLACE | 字符串替换函数,返回替换后的新字符串 |
| SUBSTRING | 截取字符串,返回从指定位置开始的指定长度的字符换 |
| REVERSE | 字符串反转(逆序)函数,返回与原始字符串顺序相反的字符串 |
MySQL 日期和时间函数
| 函数名称 | 作 用 |
|---|---|
| CURDATE 和 CURRENT_DATE | 两个函数作用相同,返回当前系统的日期值 |
| CURTIME 和 CURRENT_TIME | 两个函数作用相同,返回当前系统的时间值 |
| NOW 和 SYSDATE | 两个函数作用相同,返回当前系统的日期和时间值 |
| UNIX_TIMESTAMP | 获取UNIX时间戳函数,返回一个以 UNIX 时间戳为基础的无符号整数 |
| FROM_UNIXTIME | 将 UNIX 时间戳转换为时间格式,与UNIX_TIMESTAMP互为反函数 |
| MONTH | 获取指定日期中的月份 |
| MONTHNAME | 获取指定日期中的月份英文名称 |
| DAYNAME | 获取指定曰期对应的星期几的英文名称 |
| DAYOFWEEK | 获取指定日期对应的一周的索引位置值 |
| WEEK | 获取指定日期是一年中的第几周,返回值的范围是否为 0〜52 或 1〜53 |
| DAYOFYEAR | 获取指定曰期是一年中的第几天,返回值范围是1~366 |
| DAYOFMONTH | 获取指定日期是一个月中是第几天,返回值范围是1~31 |
| YEAR | 获取年份,返回值范围是 1970〜2069 |
| TIME_TO_SEC | 将时间参数转换为秒数 |
| SEC_TO_TIME | 将秒数转换为时间,与TIME_TO_SEC 互为反函数 |
| DATE_ADD 和 ADDDATE | 两个函数功能相同,都是向日期添加指定的时间间隔 |
| DATE_SUB 和 SUBDATE | 两个函数功能相同,都是向日期减去指定的时间间隔 |
| ADDTIME | 时间加法运算,在原始时间上添加指定的时间 |
| SUBTIME | 时间减法运算,在原始时间上减去指定的时间 |
| DATEDIFF | 获取两个日期之间间隔,返回参数 1 减去参数 2 的值 |
| DATE_FORMAT | 格式化指定的日期,根据参数返回指定格式的值 |
| WEEKDAY | 获取指定日期在一周内的对应的工作日索引 |
MySQL 聚合函数
| 函数名称 | 作用 |
|---|---|
| MAX | 查询指定列的最大值 |
| MIN | 查询指定列的最小值 |
| COUNT | 统计查询结果的行数 |
| SUM | 求和,返回指定列的总和 |
| AVG | 求平均值,返回指定列数据的平均值 |
MySQL 流程控制函数
| 函数名称 | 作用 |
|---|---|
| IF | 判断,流程控制 |
| IFNULL | 判断是否为空 |
| CASE | 搜索语句 |
MySQL常用函数
日期函数

字符串函数
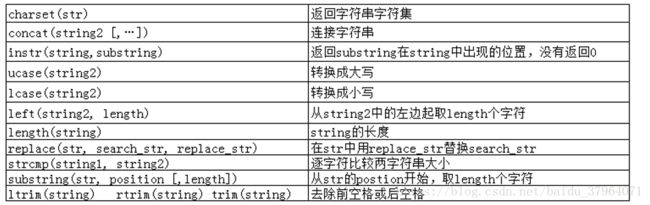
select device_id,gender,age,university from user_profile
字符匹配
一般形式为:列名 [NOT ] LIKE
匹配串中可包含如下四种通配符:
_:匹配任意一个字符;
%:匹配0个或多个字符;
[ ]:匹配[ ]中的任意一个字符(若要比较的字符是连续的,则可以用连字符“-”表 达 );
[^]:不匹配[ ]中的任意一个字符。
例23.查询学生表中姓‘张’的学生的详细信息。
SELECT` `* ``FROM` `学生表 ``WHERE` `姓名 ``LIKE` `‘张%’
例24.查询姓“张”且名字是3个字的学生姓名。
SELECT` `* ``FROM` `学生表 ``WHERE` `姓名 ``LIKE` `'张__’
如果把姓名列的类型改为nchar(20),在SQL Server 2012中执行没有结果。原因是姓名列的类型是char(20),当姓名少于20个汉字时,系统在存储这些数据时自动在后边补空格,空格作为一个字符,也参加LIKE的比较。可以用rtrim()去掉右空格。
SELECT` `* ``FROM` `学生表 ``WHERE` `rtrim(姓名) ``LIKE` `'张__'
例25.查询学生表中姓‘张’、姓‘李’和姓‘刘’的学生的情况。
SELECT` `* ``FROM` `学生表 ``WHERE` `姓名 ``LIKE` `'[张李刘]%’
例26.查询学生表表中名字的第2个字为“小”或“大”的学生的姓名和学号。
SELECT` `姓名,学号 ``FROM` `学生表 ``WHERE` `姓名 ``LIKE` `'_[小大]%'
例27.查询学生表中所有不姓“刘”的学生。
SELECT` `姓名 ``FROM` `学生 ``WHERE` `姓名 ``NOT` `LIKE` `'刘%’
例28.从学生表表中查询学号的最后一位不是2、3、5的学生信息。
SELECT` `* ``FROM` `学生表 ``WHERE` `学号 ``LIKE` `'%[^235]'
这道题主要考察的是模糊查询 字段名 like ‘匹配内容’
- _ :下划线 代表匹配任意一个字符;
- % :百分号 代表匹配0个或多个字符;
- []: 中括号 代表匹配其中的任意一个字符;
- [^]: ^尖冒号 代表 非,取反的意思;不匹配中的任意一个字符。
tips:面试常问的一个问题:你了解哪些数据库优化技术? SQL语句优化也属于数据库优化一部分,而我们的like模糊查询会引起全表扫描,速度比较慢,应该尽量避免使用like关键字进行模糊查询。
知识点
一、UNION–联合查询
使用 UNION可以实现将多个查询结果集合并为一个结果集。
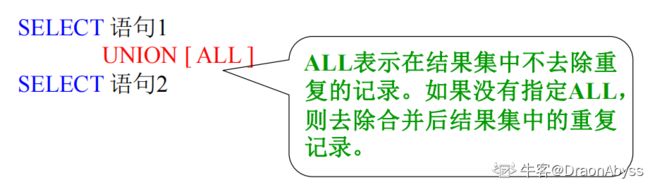
所有查询语句中列的个数和列的顺序必须相同。
所有查询语句中对应列的数据类型必须兼容。
ORDER BY语句要放在最后一个查询语句的后边。
例46.查询系号是1和2的班级的班号、班名、系号,系号是1 的记录在前,2在后。
SELECT` `班号, 班名, 系号``FROM` `班级表 ``WHERE` `系号= 1``UNION``SELECT` `班号, 班名, 系号``FROM` `班级表 ``WHERE` `系号= 2
等价于:
SELECT` `班号, 班名, 系号``FROM` `班级表 ``WHERE` `系号 ``IN` `(1,2) ``ORDER` `BY` `系号
例47.查询要求同例46,但将查询结果按系号从大到小排序。
SELECT` `班号, 班名, 系号``FROM` `班级表 ``WHERE` `系号= 1``UNION``SELECT` `班号, 班名, 系号``FROM` `班级表 ``WHERE` `系号= 2``ORDER` `BY` `系号 ``DESC
多表联合查询-不去重
题目:现在运营想要分别查看学校为山东大学或者性别为男性的用户的device_id、gender、age和gpa数据,请取出相应结果,结果不去重。
# 查看学校为山东大学或者性别为男性的用户的device_id、gender、age和gpa数据,请取出相应结果,结果不去重
# 题目要求不去重,所以根据条件1:学校为山东大学,条件2:性别为男性,分别查询,最后将查询结果拼接起来
select device_id, gender, age,gpa from user_profile where university = '山东大学'
union all
select device_id, gender, age,gpa from user_profile where gender = 'male';
# 使用以下语句,会去重
where university = '山东大学' or gender = 'male'
#注意
union 会去重, union all 不会去重
二、字段中多个值–包含查询
if (StringUtils.isNotBlank(queryDTO.getTypeId())) {
queryWrapper.lambda().apply(" locate({0},type_id) >0", queryDTO.getTypeId());
}
三、字符串截取函数

四、窗口函数
一、窗口函数有什么用?
在日常工作中,经常会遇到需要在每组内排名,比如下面的业务需求:
排名问题:每个部门按业绩来排名
topN问题:找出每个部门排名前N的员工进行奖励
面对这类需求,就需要使用sql的高级功能窗口函数了。
什么是窗口函数?
窗口函数,也叫OLAP函数(Online Anallytical Processing,联机分析处理),可以对数据库数据进行实时分析处理。
窗口函数的基本语法如下:
<窗口函数> over (partition by <用于分组的列名>
order by <用于排序的列名>)
那么语法中的<窗口函数>都有哪些呢?
<窗口函数>的位置,可以放以下两种函数:
1) 专用窗口函数,包括后面要讲到的rank, dense_rank, row_number等专用窗口函数。
2) 聚合函数,如sum. avg, count, max, min等
因为窗口函数是对where或者group by子句处理后的结果进行操作,所以窗口函数原则上只能写在select子句中。
二、如何使用?
接下来,就结合实例,给大家介绍几种窗口函数的用法。
1.专用窗口函数rank
例如下图,是班级表中的内容
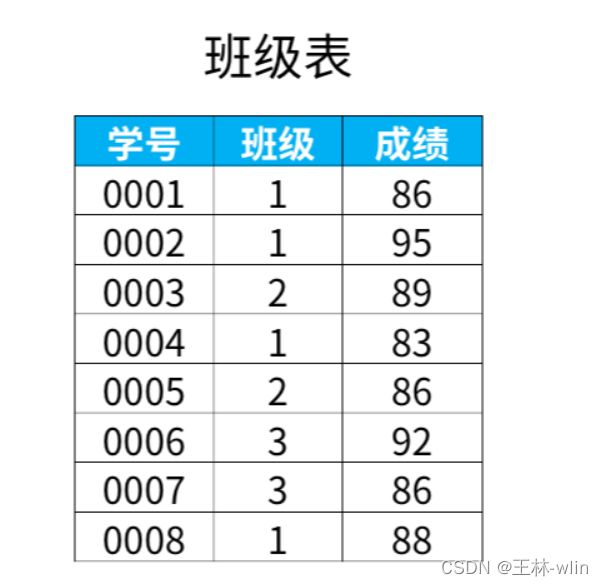
如果我们想在每个班级内按成绩排名,得到下面的结果。

以班级“1”为例,这个班级的成绩“95”排在第1位,这个班级的“83”排在第4位。上面这个结果确实按我们的要求在每个班级内,按成绩排名了。
得到上面结果的sql语句代码如下:
select *,
rank() over (partition by 班级
order by 成绩 desc) as ranking
from 班级表
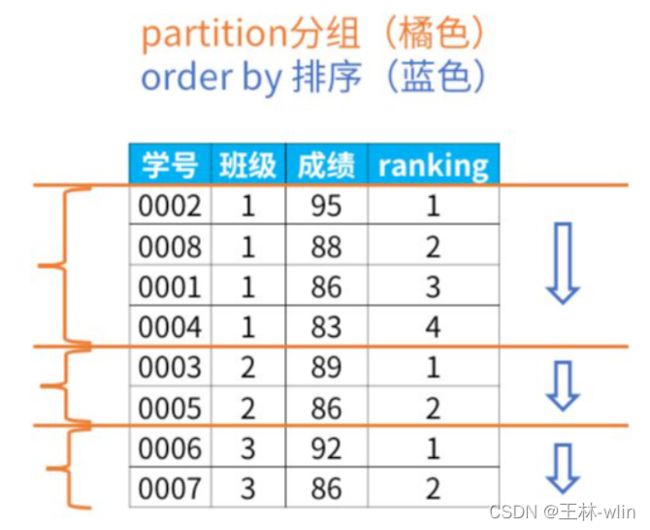
我们来解释下这个sql语句里的select子句。rank是排序的函数。要求是“每个班级内按成绩排名”,这句话可以分为两部分:
1)每个班级内:按班级分组
partition by用来对表分组。在这个例子中,所以我们指定了按“班级”分组(partition by 班级)
2)按成绩排名
order by子句的功能是对分组后的结果进行排序,默认是按照升序(asc)排列。在本例中(order by 成绩 desc)是按成绩这一列排序,加了desc关键词表示降序排列。
通过下图,我们就可以理解partiition by(分组)和order by(在组内排序)的作用了。
窗口函数具备了我们之前学过的group by子句分组的功能和order by子句排序的功能。那么,为什么还要用窗口函数呢?
这是因为,group by分组汇总后改变了表的行数,一行只有一个类别。而partiition by和rank函数不会减少原表中的行数。例如下面统计每个班级的人数。

# 相信通过这个例子,你已经明白了这个窗口函数的使用:
select *,
rank() over (partition by 班级
order by 成绩 desc) as ranking
from 班级表
现在我们说回来,为什么叫“窗口”函数呢?这是因为partition by分组后的结果称为“窗口”,这里的窗口不是我们家里的门窗,而是表示“范围”的意思。
简单来说,窗口函数有以下功能:
1)同时具有分组和排序的功能
2)不减少原表的行数
3)语法如下:
<窗口函数> over (partition by <用于分组的列名>
order by <用于排序的列名>)
2.其他专业窗口函数
专用窗口函数:rank, dense_rank, row_number有什么区别呢?
它们的区别我举个例子,你们一下就能看懂:
select *,
rank() over (order by 成绩 desc) as ranking,
dense_rank() over (order by 成绩 desc) as dese_rank,
row_number() over (order by 成绩 desc) as row_num
from 班级表
得到结果:
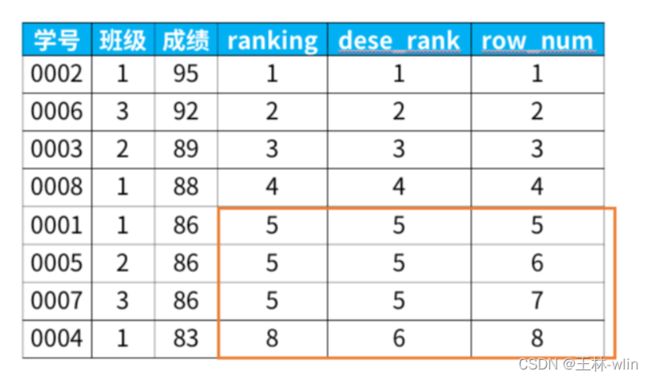
从上面的结果可以看出:
rank函数:这个例子中是5位,5位,5位,8位,也就是如果有并列名次的行,会占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是:1,1,1,4。
dense_rank函数:这个例子中是5位,5位,5位,6位,也就是如果有并列名次的行,不占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是:1,1,1,2。
row_number函数:这个例子中是5位,6位,7位,8位,也就是不考虑并列名次的情况。比如前3名是并列的名次,排名是正常的1,2,3,4。
这三个函数的区别如下:

最后,需要强调的一点是:在上述的这三个专用窗口函数中,函数后面的括号不需要任何参数,保持()空着就可以。
现在,大家对窗口函数有一个基本了解了吗?
3.聚合函数作为窗口函数
聚和窗口函数和上面提到的专用窗口函数用法完全相同,只需要把聚合函数写在窗口函数的位置即可,但是函数后面括号里面不能为空,需要指定聚合的列名。
我们来看一下窗口函数是聚合函数时,会出来什么结果:
select *,
sum(成绩) over (order by 学号) as current_sum,
avg(成绩) over (order by 学号) as current_avg,
count(成绩) over (order by 学号) as current_count,
max(成绩) over (order by 学号) as current_max,
min(成绩) over (order by 学号) as current_min
from 班级表
得到结果:

有发现什么吗?我单独用sum举个例子:
如上图,聚合函数sum在窗口函数中,是对自身记录、及位于自身记录以上的数据进行求和的结果。比如0004号,在使用sum窗口函数后的结果,是对0001,0002,0003,0004号的成绩求和,若是0005号,则结果是0001号~0005号成绩的求和,以此类推。
不仅是sum求和,平均、计数、最大最小值,也是同理,都是针对自身记录、以及自身记录之上的所有数据进行计算,现在再结合刚才得到的结果(下图),是不是理解起来容易多了?

比如0005号后面的聚合窗口函数结果是:学号0001~0005五人成绩的总和、平均、计数及最大最小值。
如果想要知道所有人成绩的总和、平均等聚合结果,看最后一行即可。
三、窗口函数作用
这样使用窗口函数有什么用呢?聚合函数作为窗口函数,可以在每一行的数据里直观的看到,截止到本行数据,统计数据是多少(最大值、最小值等)。同时可以看出每一行数据,对整体统计数据的影响。
四、注意事项
partition子句可以省略,省略就是不指定分组,结果如下,只是按成绩由高到低进行了排序:
select *,
rank() over (order by 成绩 desc) as ranking
from 班级表
得到结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Buo6hDyn-1640008700614)(C:\Users\小王子\AppData\Roaming\Typora\typora-user-images\image-20211204144953248.png)]
但是,这就失去了窗口函数的功能,所以一般不要这么使用。
五、总结
1.窗口函数语法
<窗口函数> over (partition by <用于分组的列名>
order by <用于排序的列名>)
<窗口函数>的位置,可以放以下两种函数:
1) 专用窗口函数,比如rank, dense_rank, row_number等
2) 聚合函数,如sum. avg, count, max, min等
2.窗口函数有以下功能:
1)同时具有分组(partition by)和排序(order by)的功能
2)不减少原表的行数,所以经常用来在每组内排名
3.注意事项
窗口函数原则上只能写在select子句中
4.窗口函数使用场景
1)业务需求“在每组内排名”,比如:
排名问题:每个部门按业绩来排名
topN问题:找出每个部门排名前N的员工进行奖励
五、MySQL-locate()函数
判断字符串(string)中是否包含另一个字符串(subStr)
locate(subStr,string) :函数返回subStr在string中出现的位置
# 如果字符串 string 包含 subStr
locate(subStr,string) > 0
# 如果字符串 string 不包含 subStr
locate(subStr,string) = 0
使用方式
SELECT *
FROM party_course_study
WHERE LOCATE(findCode, '00001') >0
# 注:Mybatis使用场景,需要加
SELECT *
FROM party_course_study
WHERE 0 ]]>
功能类似的函数(不做详细介绍)
- LOCATE(substr,str)
- LOCATE(substr,str,pos)
- POSITION(substr IN, str)
- INSTR(str,substr)
题型练习
一、分组查询
问题分解:
- 限定条件:平均发贴数低于5或平均回帖数小于20的学校,
avg(question_cnt)<5 or avg(answer_cnt)<20,聚合函数结果作为筛选条件时,不能用where,而是用having语法,配合重命名即可; - 按学校输出:需要对每个学校统计其平均发贴数和平均回帖数,因此
group by university
细节问题:
- 表头重命名:as
- 用having不用where
完整代码:
``select``
``university,``
``avg``(question_cnt) ``as` `avg_question_cnt,``
``avg``(answer_cnt) ``as` `avg_answer_cnt`
`from` `user_profile`
`group` `by` `university`
`having` `avg_question_cnt<5 ``or` `avg_answer_cnt<20
二、子查询
题解 | 浙江大学用户题目回答情况
这题有两种解法
第一种:创建一张临时表用,获取浙江大学device_id对用户题目回答明细进行过滤。
select``device_id,``question_id,``result``
from question_practice_detail``
where device_id = (select ``device_id`` from user_profile where university = ``'浙江大学'``)
第二种:先将两张表关联在一起,然后再筛选出浙江大学的明细数据。
select t1.device_id,question_id,result
from question_practice_detail t1
left JOIN user_profile t2 on t1.device_id = t2.device_id
where university = "浙江大学";
三、链接查询
题意明确:
计算每个学校用户不同难度下的用户平均答题题目数
问题分解:
- 限定条件:无;
- 每个学校:按学校分组
group by university - 不同难度:按难度分组
group by difficult_level - 平均答题数:总答题数除以总人数
count(qpd.question_id) / count(distinct qpd.device_id) - 来自上面信息三个表,需要联表,up与qpd用device_id连接,qd与qpd用question_id连接。
细节问题:
- 表头重命名:as
- 平均值精度未明确要求,忽略
完整代码:
select
university,
difficult_level,
count(qpd.question_id) / count(distinct qpd.device_id) as avg_answer_cnt
from question_practice_detail as qpd
left join user_profile as up
on up.device_id=qpd.device_id
left join question_detail as qd
on qd.question_id=qpd.question_id
group by university, difficult_level;
四、组合查询
# 查看学校为山东大学或者性别为男性的用户的device_id、gender、age和gpa数据,请取出相应结果,结果不去重
# 题目要求不去重,所以根据条件1:学校为山东大学,条件2:性别为男性,分别查询,最后将查询结果拼接起来
select device_id, gender, age,gpa from user_profile where university = '山东大学'
union all
select device_id, gender, age,gpa from user_profile where gender = 'male';
使用以下语句,会去重
where university = '山东大学' or gender = 'male'
union 会去重, union all 不会去重
avatar
44 浏览
五、条件函数
例题一
题解 | #计算25岁以上和以下的用户数量#
方法一:是case的写法,就是case when 条件1 then 值1 …… end
SELECT
case
when age < 25 or isnull(age) then '25岁以下'
when age >= 25 then '25岁及以上'
end age_cut,
count(*) number
FROM
user_profile
GROUP BY
age_cut;
方法二:就是if的写法,就是if(条件,‘为真则是此值’,‘为假则是此值’),相对于上边这个少了一个null值的判断,因为这是分为两类,所以就可以这样直接写另一类忽视判断
SELECT
if (age >= 25, '25岁及以上','25岁以下') age_cut,
count(*) number
FROM
user_profile
GROUP BY
age_cut;
例题二
题目:现在运营想要将用户划分为20岁以下,20-24岁,25岁及以上三个年龄段,分别查看不同年龄段用户的明细情况,请取出相应数据。(注:若年龄为空请返回其他。)
select device_id,gender,
case
when age < 20 then '20岁以下'
when age between 20 and 24 then '20-24岁'
when age > 24 then '25岁及以上'
else '其他'
end
as age_cut
from user_profile;
六、日期函数
例题一
题解 | #计算用户8月每天的练题数量#
SELECT DAY(date) as day,
COUNT(question_id) as question_cnt
FROM question_practice_detail
WHERE YEAR(date)="2021" and month(date)="08"
GROUP BY day;
记录一下日期函数year(),month(),day()
例题二
题解 | #计算用户的平均次日留存率#
题解:计算用户的平均次日留存率
题目分析
所谓次日留存,指的是同一用户(在本题中则为同一设备,即device_id)在当天和第二天都进行刷题。注意,在这题我们不关心同一用户(设备)在这天答了什么题、答题结果如何,只关心他是否答题,因此对于这题来说存在重复的数据(如下图红框所示),需要使用 DISTINCT 去重。 
而次日留存率可以这样表示:
次日留存率=去重的数据表中符合次日留存的条目数目÷去重的数据表中所有条目数目
具体而言,使用两个子查询,查询出两个去重的数据表,并使用条件(q2.date应该是q1.date的后一天)进行筛选,如下所示(数据未显示完全,从左至右顺序,列表名为 q1.device_id, q1.date, q2.device_id, q2.date)

因为使用的是q1左级联q2,所以q1的所有信息是显示的;而q2中只显示留存的信息,否则为null。
最后,分别统计q1.device_id 和 q2.device_id 作去重后的所有条目数和去重后的次日留存条目数,即可算出次日留存率。
具体实现
SELECT
COUNT(q2.device_id) / COUNT(q1.device_id) AS avg_ret
FROM
(SELECT DISTINCT device_id, date FROM question_practice_detail)as q1
LEFT JOIN
(SELECT DISTINCT device_id, date FROM question_practice_detail) AS q2
ON q1.device_id = q2.device_id AND q2.date = DATE_ADD(q1.date, interval 1 day)
注意,MySQL中 COUNT在对列进行计数时不统计值为 null的条目
七、文本函数
例题一
题解 | #统计每种性别的人数#
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UllQbNUU-1640008700617)(C:\Users\小王子\AppData\Roaming\Typora\typora-user-images\image-20211204135952570.png)]
(1)SUBSTRING_INDEX的写法
SELECT SUBSTRING_INDEX(profile,",",-1) gender,COUNT(*) number
FROM user_submit
GROUP BY gender;
(2)LIKE的写法【mark一下,原来有IF(profile LIKE ‘%female’,‘female’,‘male’) 这样的方式】
SELECT IF(profile LIKE '%female','female','male') gender,COUNT(*) number
FROM user_submit
GROUP BY gender;
例题二
题意明确:把用户的个人博客用户名字段提取出来单独记录为一个新的字段
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YQ7CT4bE-1640008700618)(C:\Users\小王子\AppData\Roaming\Typora\typora-user-images\image-20211204140358802.png)]
问题分解:
-
限定条件:无;
-
提取字段内信息:个人博客字段中的用户名是被字符/分隔的最后一个子串,使用substring_index函数可以按特定字符串截取源字符串 substring_index(FIELD, sep, n)可以将字段FIELD按照sep分隔:
(1).当n大于0时取第n个分隔符(n从1开始) 左边 的全部内容;
(2).当n小于0时取 倒数第-n个 分隔符(n从-1开始) 右边 的全部内容; 因此,本题可以用
substring_index(blog_url, '/', -1)取出用户名. -
substring_index函数解析
细节问题:
- 表头重命名:as
完整代码:
select device_id,
substring_index(blog_url, '/', -1) as user_name
from user_submit
例题三
题解 | #截取出年龄#
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2IJ843p6-1640008700619)(C:\Users\小王子\AppData\Roaming\Typora\typora-user-images\image-20211204141327475.png)]
题意明确: 统计每个年龄的用户分别有多少参赛者
- 问题分解: 限定条件:无;
- 每个年龄:按年龄分组group by age,但是没有age字段,需要从profile字段截取,按字符,分割后取出即可。可使用substring_index函数可以按特定字符串截取源字符串。substring_index
题解 | #截取出年龄#
select substring_index(SUBSTRING_INDEX(profile,',',3),',',-1) as age,count(device_id)
from user_submit a
group by age
substring_index 用法。
先截取至年龄
SUBSTRING_INDEX(profile,``','``,3)
返回的是
180cm,75kg,27
165cm,45kg,26
178cm,65kg,25
171cm,55kg,23
168cm,45kg,22
再把年龄拿出来
substring_index(SUBSTRING_INDEX(profile,``','``,3),``','``,-1)
取刚才那段东西,用’,‘分隔的’-1’位,从右往左数,第一次遇到’,'的右边全部内容。
八、窗口函数
题目:现在运营想要找到每个学校gpa最低的同学来做调研,请你取出每个学校的最低gpa。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4xSGI66b-1640008700620)(C:\Users\小王子\AppData\Roaming\Typora\typora-user-images\image-20211204150139990.png)]
题解 | #找出每个学校GPA最低的同学#
SELECT device_id,university,min(gpa) FROM user_profile GROUP BY university;
因为学校与学生是一对多的关系,如果仅用min求出gpa最低的学生,查询结果中的id与学生不一定是对应的关系,因此此方法错误。
(1)方法一:将表a的device_id,university,gpa和表b的university,min(gpa)连接起来找。
SELECT a.device_id,a.university,a.gpa FROM user_profile a
JOIN (SELECT university,min(gpa) gpa FROM user_profile GROUP BY university) b
on a.university=b.university and a.gpa=b.gpa
ORDER BY university;
(2)方法二:窗口函数
复制代码
SELECT device_id,university,gpa FROM
(SELECT device_id,university,gpa,
RANK() over (PARTITION BY university ORDER BY gpa) rk FROM user_profile) a
WHERE a.rk=1;
九、综合练习
例题一:
题目: 现在运营想要了解复旦大学的每个用户在8月份练习的总题目数和回答正确的题目数情况,请取出相应明细数据,对于在8月份没有练习过的用户,答题数结果返回0
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QPXkCgyt-1640008700620)(C:\Users\小王子\AppData\Roaming\Typora\typora-user-images\image-20211208091733507.png)]
SELECT
a.device_id,
a.university,
count(q.question_id) as question_cnt,
count(if((q.result = 'right'),1,null)) right_question_cnt
FROM
question_practice_detail q
right join
(SELECT device_id,university
FROM user_profile
WHERE university = '复旦大学') a
on a.device_id = q.device_id and month(q.date) = 8
group by a.device_id;
例题二:
题目:现在运营想要了解浙江大学的用户在不同难度题目下答题的正确率情况,请取出相应数据,并按照准确率升序输出。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-22hKpccD-1640008700621)(C:\Users\小王子\AppData\Roaming\Typora\typora-user-images\image-20211208094408756.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MJNuNSQH-1640008700622)(C:\Users\小王子\AppData\Roaming\Typora\typora-user-images\image-20211208094422974.png)]
题解 | #浙大不同难度题目的正确率#
发表于 2021-09-09 09:33:42
浙江大学的用户在不同难度题目下答题的正确率情况,请取出相应数据,并按照准确率升序输出。
输出:题目难度,正确率=正确题数/总题数
qd.difficult_lever
sum(if(qpd.result='right',1,0))/count(qpd.device_id) AS correct_rate
筛选:浙江大学
where u.university = ``'浙江大学'
分类:不同难度
GROUP BY qd.difficult_level
排序:按照正确率,升序排列
ORDER BY correct_rate
由于输出中正确率的参数主要来源于gpd因此联结时完整保留gpd信息
question_practice_detail AS qpd``LEFT JOIN user_profile AS u``ON qpd.device_id = u.device_id` `LEFT JOIN question_detail AS qd``ON qpd.question_id = qd.question_id
用整理查询语句顺序得正确答案
复制代码
SELECT qd.difficult_level,
sum(if(qpd.result='right',1,0))/count(qpd.device_id) AS correct_rate
FROM
(question_practice_detail AS qpd
LEFT JOIN user_profile AS u
ON qpd.device_id = u.device_id
LEFT JOIN question_detail AS qd
ON qpd.question_id = qd.question_id)
WHERE u.university = '浙江大学'
GROUP BY qd.difficult_level
ORDER BY correct_rate ASC;
例题三:
题目: 现在运营想要了解2021年8月份所有练习过题目的总用户数和练习过题目的总次数,请取出相应结果
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xn6HJDh8-1640008700623)(C:\Users\小王子\AppData\Roaming\Typora\typora-user-images\image-20211208095531797.png)]
题意明确:2021年8月份所有练习过题目的总用户数和练习过题目的总次数
问题分解:
- 限定条件:2021年8月份,匹配date字段即可,匹配方法主要有三种:
(1)like语法:date like "2021-08%"
(2)year、month函数:year(date)='2021' and month(date)='08';
(3)date_format函数:date_format(date, '%Y-%m')='2021-08'; - 2:总用户数:count函数计数,因为用户有重复,所以需要distinct去重,即
count(distinct device_id) - 3:总次数:count(question_id)即可
细节问题:
- 表头重命名:as语法
完整代码:
复制代码
select
count(distinct device_id) as did_cnt,
count(question_id) as question_cnt
from question_practice_detail
where year(date)='2021' and month(date)='08';
二、SQL进阶挑战
题型练习
增删改查
插入记录
三、MySQL高级
MySQL架构介绍
目录

概述

MySQL常用命令
# 查看是否安装mysql
rpm -qa|grep -i mysql
ls -1
# 安装 i:是云速度
rpm -ivh
#查看linux中mysql用户和用户组
cat /etc/passwd|grep mysql
cat /etc/group|grep mysql
#查看版本
mysql -V
mysqladmin --version
#启动mysql
service mysql start
# 关闭mysql
service mysql stop
# 查看linux 使用了多久
top
# 进入mysql
mysql -uroot -p
# 设置开机自启动
chkconfig mysql on
# 查看运行级别
cat /etc/inittab
ntsysv

给root用户设置密码
设置开机自启动

索引优化分析
目录

索引的创建时机
适合创建索引的情况
- 主键自动建立唯一索引;
- 频繁作为查询条件的字段应该创建索引
- 查询中与其它表关联的字段,外键关系建立索引
- 单键/组合索引的选择问题, 组合索引性价比更高
- 查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
- 查询中统计或者分组字段
不适合创建索引的情况
- 表记录太少
- 经常增删改的表或者字段
- Where 条件里用不到的字段不创建索引
- 过滤性不好的不适合建索引
查询截取分析
目录

MySQL锁机制
目录

主从复制
时间复杂度
