Kubernetes 应用存储和持久化数据卷:核心知识
本次课程的分享主要围绕以下三个部分:
- K8s Volume 使用场景
- PVC/PV/StorageClass 基本操作和概念解析
- PVC+PV 体系的设计与实现原理
一、Volumes 介绍
Pod Volumes
首先来看一下 Pod Volumes 的使用场景:
- 场景一:如果 pod 中的某一个容器在运行时异常退出,被 kubelet 重新拉起之后,如何保证之前容器产生的重要数据没有丢失?
- 场景二:如果同一个 pod 中的多个容器想要共享数据,应该如何去做?
以上两个场景,其实都可以借助 Volumes 来很好地解决,接下来首先看一下 Pod Volumes 的常见类型:
- 本地存储,常用的有 emptydir/hostpath;
- 网络存储:网络存储当前的实现方式有两种,一种是 in-tree,它的实现的代码是放在 K8s 代码仓库中的,随着k8s对存储类型支持的增多,这种方式会给k8s本身的维护和发展带来很大的负担;而第二种实现方式是 out-of-tree,它的实现其实是给 K8s 本身解耦的,通过抽象接口将不同存储的driver实现从k8s代码仓库中剥离,因此out-of-tree 是后面社区主推的一种实现网络存储插件的方式;
- Projected Volumes:它其实是将一些配置信息,如 secret/configmap 用卷的形式挂载在容器中,让容器中的程序可以通过POSIX接口来访问配置数据;
- PV 与 PVC 就是今天要重点介绍的内容。

Persistent Volumes
接下来看一下 PV(Persistent Volumes)。既然已经有了 Pod Volumes,为什么又要引入 PV 呢?我们知道 pod 中声明的 volume 生命周期与 pod 是相同的,以下有几种常见的场景:
- 场景一:pod 重建销毁,如用 Deployment 管理的 pod,在做镜像升级的过程中,会产生新的 pod并且删除旧的 pod ,那新旧 pod 之间如何复用数据?
- 场景二:宿主机宕机的时候,要把上面的 pod 迁移,这个时候 StatefulSet 管理的 pod,其实已经实现了带卷迁移的语义。这时通过 Pod Volumes 显然是做不到的;
- 场景三:多个 pod 之间,如果想要共享数据,应该如何去声明呢?我们知道,同一个 pod 中多个容器想共享数据,可以借助 Pod Volumes 来解决;当多个 pod 想共享数据时,Pod Volumes 就很难去表达这种语义;
- 场景四:如果要想对数据卷做一些功能扩展性,如:snapshot、resize 这些功能,又应该如何去做呢?
以上场景中,通过 Pod Volumes 很难准确地表达它的复用/共享语义,对它的扩展也比较困难。因此 K8s 中又引入了 Persistent Volumes 概念,它可以将存储和计算分离,通过不同的组件来管理存储资源和计算资源,然后解耦 pod 和 Volume 之间生命周期的关联。这样,当把 pod 删除之后,它使用的PV仍然存在,还可以被新建的 pod 复用。

PVC 设计意图

了解 PV 后,应该如何使用它呢?
用户在使用 PV 时其实是通过 PVC,为什么有了 PV 又设计了 PVC 呢?主要原因是为了简化K8s用户对存储的使用方式,做到职责分离。通常用户在使用存储的时候,只用声明所需的存储大小以及访问模式。
访问模式是什么?其实就是:我要使用的存储是可以被多个node共享还是只能单node独占访问(注意是node level而不是pod level)?只读还是读写访问?用户只用关心这些东西,与存储相关的实现细节是不需要关心的。
通过 PVC 和 PV 的概念,将用户需求和实现细节解耦开,用户只用通过 PVC 声明自己的存储需求。PV是有集群管理员和存储相关团队来统一运维和管控,这样的话,就简化了用户使用存储的方式。可以看到,PV 和 PVC 的设计其实有点像面向对象的接口与实现的关系。用户在使用功能时,只需关心用户接口,不需关心它内部复杂的实现细节。
既然 PV 是由集群管理员统一管控的,接下来就看一下 PV 这个对象是怎么产生的。
Static Volume Provisioning
第一种产生方式:静态产生方式 - 静态 Provisioning。
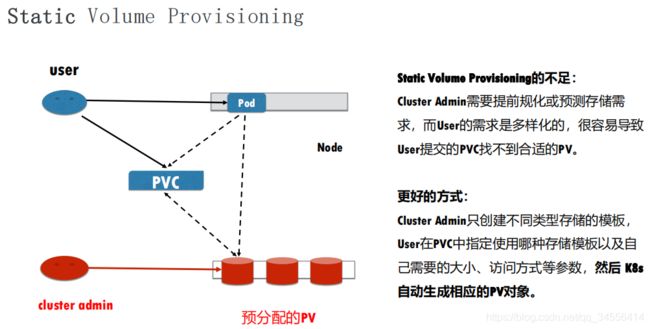
静态 Provisioning:由集群管理员事先去规划这个集群中的用户会怎样使用存储,它会先预分配一些存储,也就是预先创建一些 PV;然后用户在提交自己的存储需求(也就是 PVC)的时候,K8s 内部相关组件会帮助它把 PVC 和 PV 做绑定;之后用户再通过 pod 去使用存储的时候,就可以通过 PVC 找到相应的 PV,它就可以使用了。
静态产生方式有什么不足呢?可以看到,首先需要集群管理员预分配,预分配其实是很难预测用户真实需求的。举一个最简单的例子:如果用户需要的是 20G,然而集群管理员在分配的时候可能有 80G 、100G 的,但没有 20G 的,这样就很难满足用户的真实需求,也会造成资源浪费。有没有更好的方式呢?
Dynamic Volume Provisioning
第二种访问方式:动态 Dynamic Provisioning。
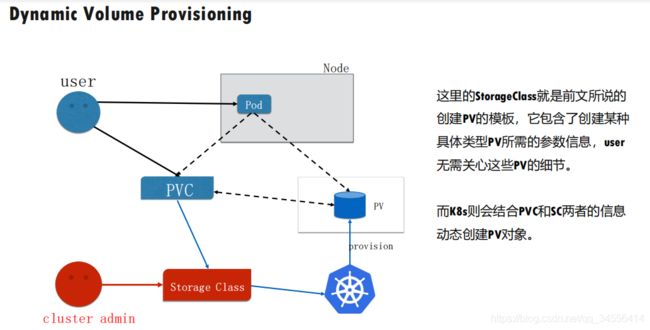
动态供给是什么意思呢?就是说现在集群管理员不预分配 PV,他写了一个模板文件,这个模板文件是用来表示创建某一类型存储(块存储,文件存储等)所需的一些参数,这些参数是用户不关心的,给存储本身实现有关的参数。用户只需要提交自身的存储需求,也就是PVC文件,并在 PVC 中指定使用的存储模板(StorageClass)。
K8s 集群中的管控组件,会结合 PVC 和 StorageClass 的信息动态,生成用户所需要的存储(PV),将 PVC 和 PV 进行绑定后,pod 就可以使用 PV 了。通过 StorageClass 配置生成存储所需要的存储模板,再结合用户的需求动态创建 PV 对象,做到按需分配,在没有增加用户使用难度的同时也解放了集群管理员的运维工作。
二、用例解读
接下来看一下 Pod Volumes、PV、PVC 及 StorageClass 具体是如何使用的。
Pod Volumes 的使用

首先来看一下 Pod Volumes 的使用。如上图左侧所示,我们可以在 pod yaml 文件中的 Volumes 字段中,声明我们卷的名字以及卷的类型。声明的两个卷,一个是用的是 emptyDir,另外一个用的是 hostPath,这两种都是本地卷。在容器中应该怎么去使用这个卷呢?它其实可以通过 volumeMounts 这个字段,volumeMounts 字段里面指定的 name 其实就是它使用的哪个卷,mountPath 就是容器中的挂载路径。
这里还有个 subPath,subPath 是什么?
先看一下,这两个容器都指定使用了同一个卷,就是这个 cache-volume。那么,在多个容器共享同一个卷的时候,为了隔离数据,我们可以通过 subPath 来完成这个操作。它会在卷里面建立两个子目录,然后容器 1 往 cache 下面写的数据其实都写在子目录 cache1 了,容器 2 往 cache 写的目录,其数据最终会落在这个卷里子目录下面的 cache2 下。
还有一个 readOnly 字段,readOnly 的意思其实就是只读挂载,这个挂载你往挂载点下面实际上是没有办法去写数据的。
另外emptyDir、hostPath 都是本地存储,它们之间有什么细微的差别呢?emptyDir 其实是在 pod 创建的过程中会临时创建的一个目录,这个目录随着 pod 删除也会被删除,里面的数据会被清空掉;hostPath 顾名思义,其实就是宿主机上的一个路径,在 pod 删除之后,这个目录还是存在的,它的数据也不会被丢失。这就是它们两者之间一个细微的差别。
静态 PV 使用

接下来再看一下,PV 和 PVC 是怎么使用的。
先看一个静态 PV 创建方式。静态 PV 的话,首先是由管理员来创建的,管理员我们这里以 NAS,就是阿里云文件存储为例。我需要先在阿里云的文件存储控制台上去创建 NAS 存储,然后把 NAS 存储的相关信息要填到 PV 对象中,这个 PV 对象预创建出来后,用户可以通过 PVC 来声明自己的存储需求,然后再去创建 pod。创建 pod 还是通过我们刚才讲解的字段把存储挂载到某一个容器中的某一个挂载点下面。
那么接下来看一下 yaml 怎么写。集群管理员首先是在云存储厂商那边先去把存储创建出来,然后把相应的信息填写到 PV 对象中。

刚刚创建的阿里云 NAS 文件存储对应的PV,有个比较重要的字段:capacity,即创建的这个存储的大小,accessModes,创建出来的这个存储它的访问方式,我们后面会讲解总共有几种访问方式。
然后有个 ReclaimPolicy,ReclaimPolicy 的意思就是:这块存储在被使用后,等它的使用方 pod 以及 PVC 被删除之后,这个 PV 是应该被删掉还是被保留呢?其实就是PV的回收策略。
接下来看看用户怎么去使用该PV对象。用户在使用存储的时候,需要先创建一个 PVC 对象。PVC 对象里面,只需要指定存储需求,不用关心存储本身的具体实现细节。存储需求包括哪些呢?首先是需要的大小,也就是 resources.requests.storage;然后是它的访问方式,即需要这个存储的访问方式,这里声明为ReadWriteMany,也即支持多node读写访问,这也是文件存储的典型特性。

上图中左侧,可以看到这个声明:它的 size 和它的access mode,跟我们刚才静态创建这块 PV 其实是匹配的。这样的话,当用户在提交 PVC 的时候,K8s 集群相关的组件就会把 PV 的 PVC bound 到一起。之后,用户在提交 pod yaml 的时候,可以在卷里面写上 PVC声明,在 PVC声明里面可以通过 claimName 来声明要用哪个 PVC。这时,挂载方式其实跟前面讲的一样,当提交完 yaml 的时候,它可以通过 PVC 找到 bound 着的那个 PV,然后就可以用那块存储了。这是静态 Provisioning到被pod使用的一个过程。
动态 PV 使用
然后再看一下动态 Provisioning。动态 Provisioning 上面提到过,系统管理员不再预分配 PV,而只是创建一个模板文件。

这个模板文件叫 StorageClass,在StorageClass里面,我们需要填的重要信息:第一个是 provisioner,provisioner 是什么?它其实就是说我当时创建 PV 和对应的存储的时候,应该用哪个存储插件来去创建。(其实就是在原来基础上面加了这个,其余的都不变)
这些参数是通过k8s创建存储的时候,需要指定的一些细节参数。对于这些参数,用户是不需要关心的,像这里 regionld、zoneld、fsType 和它的类型。ReclaimPolicy跟我们刚才讲解的 PV 里的意思是一样的,就是说动态创建出来的这块 PV,当使用方使用结束、Pod 及 PVC 被删除后,这块 PV 应该怎么处理,我们这个地方写的是 delete,意思就是说当使用方 pod 和 PVC 被删除之后,这个 PV 也会被删除掉。
接下来看一下,集群管理员提交完 StorageClass,也就是提交创建 PV 的模板之后,用户怎么用,首先还是需要写一个 PVC 的文件。

apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: prometheus
namespace: ops
spec:
storageClassName: "managed-nfs-storage"
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi