
数据同步的方式
数据同步的2大方式
基于SQL查询的 CDC(Change Data Capture):
- 离线调度查询作业,批处理。把一张表同步到其他系统,每次通过查询去获取表中最新的数据。也就是我们说的基于SQL查询抽取;
- 无法保障数据一致性,查的过程中有可能数据已经发生了多次变更;
- 不保障实时性,基于离线调度存在天然的延迟;
- 工具软件以Kettle(Apache Hop最新版)、DataX为代表,需要结合任务调度系统使用。
基于日志的 CDC:
- 实时消费日志,流处理,例如 MySQL 的 binlog 日志完整记录了数据库中的变更,可以把 binlog 文件当作流的数据源;
- 保障数据一致性,因为 binlog 文件包含了所有历史变更明细;
- 保障实时性,因为类似 binlog 的日志文件是可以流式消费的,提供的是实时数据;
- 工具软件以Flink CDC、阿里巴巴Canal、Debezium为代表。
基于SQL查询增量数据同步原理
我们考虑用SQL如何查询增量数据? 数据有增加、修改、删除
删除数据采用逻辑删除的方式,比如定义一个is_deleted字段标识逻辑删除
如果数据是 UPDATE的,也就是会被修改的,那么 where update_datetime >= last_datetime(调度滚动时间)就是增量数据
如果数据是 APPEND ONLY 的除了用更新时间还可以用where id >= 调度上次last_id
结合任务调度系统
调度时间是每日调度执行一次,那么 last_datetime = 当前调度开始执行时间 - 24小时,延迟就是1天
调度时间是15分钟一次,那么 last_datetime = 当前调度开始执行时间 - 15分钟,延迟就是15分钟
这样就实现了捕获增量数据,从而实现增量同步
DolphinScheduler + Datax 构建离线增量数据同步平台
本实践使用
单机8c16g
DataX 2022-03-01 官网下载
DolphinScheduler 2.0.3(DolphinScheduler的安装过程略,请参考官网)
DolphinScheduler 中设置好DataX环境变量
DolphinScheduler 提供了可视化的作业流程定义,用来离线定时调度DataX Job作业,使用起来很是顺滑
基于SQL查询离线数据同步的用武之地
为什么不用基于日志实时的方式?不是不用,而是根据场合用。考虑到业务实际需求情况,基于SQL查询这种离线的方式也并非完全淘汰了
特别是业务上实时性要求不高,每次调度增量数据没那么大的情况下,不需要分布式架构来负载,这种情况下是比较合适的选择
场景举例:
网站、APP的百万级、千万级的内容搜索,每天几百篇内容新增+修改,搜索上会用到ES(ElasticSearch),那么就需要把 MySQL内容数据增量同步到ES
DataX就能满足需求!
DolphinScheduler中配置DataX MySQL To ElasticSearch工作流
工作流定义
工作流定义 > 创建工作流 > 拖入1个SHELL组件 > 拖入1个DATAX组件
SHELL组件(文章)
脚本
echo '文章同步 MySQL To ElasticSearch'DATAX组件(t_article)
用到2个插件mysqlreader、elasticsearchwriter^[1]
选 自定义模板:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://${biz_mysql_host}:${biz_mysql_port}/你的数据库?useUnicode=true&zeroDateTimeBehavior=convertToNull&characterEncoding=UTF8&autoReconnect=true&useSSL=false&&allowLoadLocalInfile=false&autoDeserialize=false&allowLocalInfile=false&allowUrlInLocalInfile=false"
],
"querySql": [
"select a.id as pk,a.id,a.title,a.content,a.is_delete,a.delete_date,a.create_date,a.update_date from t_article a.update_date >= '${biz_update_dt}';"
]
}
],
"password": "${biz_mysql_password}",
"username": "${biz_mysql_username}"
}
},
"writer": {
"name": "elasticsearchwriter",
"parameter": {
"endpoint": "${biz_es_host}",
"accessId": "${biz_es_username}",
"accessKey": "${biz_es_password}",
"index": "t_article",
"type": "_doc",
"batchSize": 1000,
"cleanup": false,
"discovery": false,
"dynamic": true,
"settings": {
"index": {
"number_of_replicas": 0,
"number_of_shards": 1
}
},
"splitter": ",",
"column": [
{
"name": "pk",
"type": "id"
},
{
"name": "id",
"type": "long"
},
{
"name": "title",
"type": "text"
},
{
"name": "content",
"type": "text"
}
{
"name": "is_delete",
"type": "text"
},
{
"name": "delete_date",
"type": "date"
},
{
"name": "create_date",
"type": "date"
},
{
"name": "update_date",
"type": "date"
}
]
}
}
}
],
"setting": {
"errorLimit": {
"percentage": 0,
"record": 0
},
"speed": {
"channel": 1,
"record": 1000
}
}
}
}reader和writer的字段配置需保持一致
自定义参数:
biz_update_dt: ${global_bizdate}
biz_mysql_host: 你的mysql ip
biz_mysql_port: 3306
biz_mysql_username: 你的mysql账号
biz_mysql_password: 你的mysql密码
biz_es_host: 你的es地址带协议和端口 http://127.0.0.1:9200
biz_es_username: 你的es账号
biz_es_password: 你的es密码配置的自定义参数将会自动替换json模板中的同名变量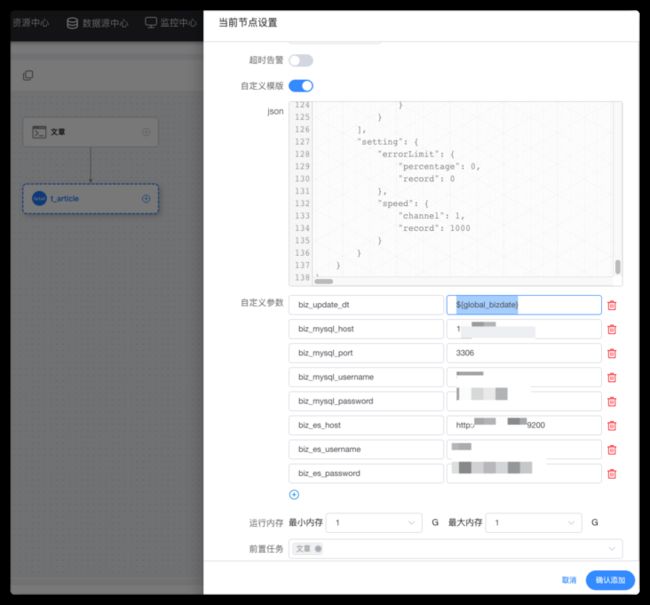
reader mysqlreader插件中关键配置: a.update_date >= '${biz_update_dt}' 就是实现增量同步的关键配置
writer elasticsearchwriter插件中关键配置: ``
"column": [
{
"name": "pk",
"type": "id"
},
......
]type = id 这样配置,就把文章主键映射到es主键 _id 从而实现相同主键id重复写入数据,就会更新数据。如果不这样配置数据将会重复导入es中
保存工作流
全局变量设置global_bizdate: $[yyyy-MM-dd 00:00:00-1]
global_bizdate 引用的变量为 DolphinScheduler 内置变量,具体参考官网文档^[2]
结合调度时间设计好时间滚动的窗口时长,比如按1天增量,那么这里时间就是减1天

最终的工作流DAG图为:

by 流水理鱼|wwek
参考
1. DataX ElasticSearchWriter 插件文档
2. Apache DolphinScheduler 内置参数
本文首发于流水理鱼博客,如要转载请注明出处。
欢迎关注我的公众号:流水理鱼(liushuiliyu),全栈、云原生、Homelab交流。
如果您对相关文章感兴趣,也可以关注我的博客:www.iamle.com 上面有更多内容