强化学习入门笔记 | UCL silver RL | UC Berkely cs285 DRL
学习情况:
先后听了两门课程,分别是David Silver的RL和Sergey Levin的DRL。各耗时一周左右,后者更难一些。对RL基本概念、常用算法原理及其伪代码有了大致了解。但是因为时间有点赶,没有敲完整的算法代码。
由于已经有写得比较好的课程笔记 (RL 和 DRL),就不重复造轮子了。两位博主对课程内容理解得都相对透彻,尤其是前者,解答了我很多看视频没太听懂的疑惑。
这份笔记是我在听完两门课程后想梳理的一些东西,并不描述算法、公式的推导细节,大概只是对这些天学的RL基础知识的一份简单梳理,可以说只是一个目录。大致思路跟着Silver的课整理,对部分算法补充cs285讲的内容。cs285的课程要难很多,讲的很多内容都涉及到复杂的数学公式推导,感觉很多part都能单独出长笔记,在这篇基础笔记中就不提及了。挖坑以后写。
由于初学,了解得比较浅薄,可能有理解错误的地方。也欢迎帮我指出错误。阅读这篇笔记时最好有一定RL基础,因为有些名词出现时可能不做解释。全文共1.2w字,纯手敲。
目录
RL基础概念
动态规划DP
Policy Iteration
Value Iteration
蒙特卡洛MC
时序差分TD
n-step TD
TD(λ)
SARSA
Q-learning
DQN
Nature DQN
DDQN
Prioritized Repay DQN
Dueling DQN
Policy Gradient
REINFORCE
Actor-Critic
DPG
DDPG
A3C
Model-based method
Dyna
Dyna-Q
MCTS
RL基础概念
RL (Reinforcement Learning) 是一门决策学科,而且解决的是Sequential Decision。关于RL的意义,Sergey在cs285中讲到,它提供了一种build intelligent model的新方式,不是模拟大脑结构(神经网络),而是模拟人的成长过程。图灵说,"与其通过程序模拟成人,不如通过程序模拟儿童,并给予适当的教育"。
Sequential Decision的意思是,做的上一个决策会影响到下一个决策。agent做出的action会对environment造成影响,交互使得该agent的下个state受影响,进而影响下个action决策。
model-free RL:数据驱动。通过大量采样,使用sampling模拟,估计agent的value function,从而优化策略![]()
model-based RL:最优控制。首先建立具体问题的模型,通过高斯过程(GP)或贝叶斯网络(BN)等方法。然后对问题求解,使用模型预测控制(MPC)、线性二次调节器(LQR)、线性二次高斯(LQG)、迭代学习控制(ICL)等方法求解。![]()
最开始想把所有算法分到model-free和model-based中,但是理思路时候感觉RL算法分类并不是非黑即白的,有些RL算法间的边界是模糊的。并不像传统的ML可以直接分为监督学习和非监督学习(它们之间的界限很明确)。
分类方式很多,但是应该每种分类方式都有相交的部分。model-free/model-based,policy-based/value-based/actor-critic,引入DL否,on-policy/off-policy,同步/异步。
RL情景大概为,在某个state下,agent依据policy,采取action,与environment交互,agent获得反馈reward。agent获得的reward会指导policy改进,在state'下选择action'。循环往复,policy不断被优化。
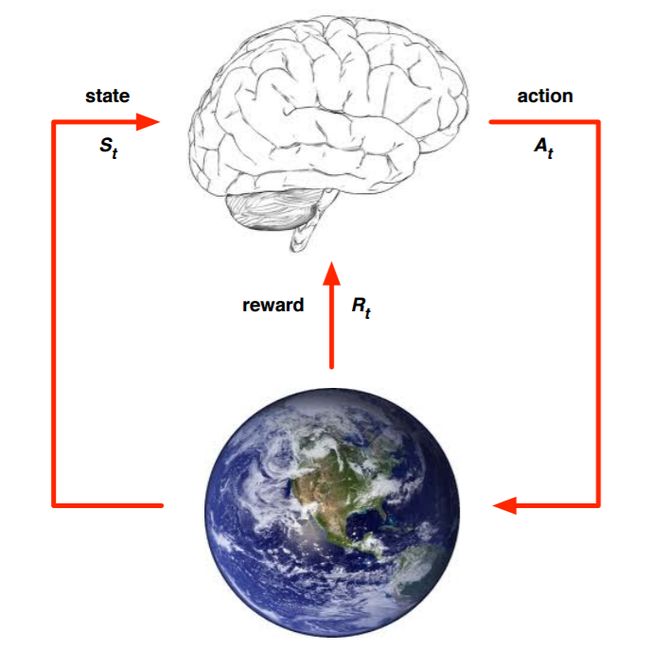
比如学生 (agent) 上英语课 (state) 选择睡觉 (action),考了59分被家长一顿打 (reward<0);他上课选择学习 (action),考100分且被一顿夸 (reward>0),下次就知道在上语文课(state)该选择干什么了(action)。
在RL中Reward很显然是一种延时价值,比如考了59分(action)后才挨了打(reward),动作后才知道这个动作的价值。所以Reward这个反馈出现在动作执行之后
在什么state下该采取怎样的action,这就是策略policy。策略分为deterministic policy和stochastic policy两种。
deterministic policy指每个state都有确定的action,即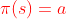 。经典的deterministic policy,如Q-learning,SARSA,TD.
。经典的deterministic policy,如Q-learning,SARSA,TD.
stochastic policy指state下可以采取不同action。它用条件概率表示,![]() ,输出的是在该state下采取不同action的概率。经典的stochastic policy,如Vanilla/Nature PG,REINFORCE,Natural Actor-Critic.
,输出的是在该state下采取不同action的概率。经典的stochastic policy,如Vanilla/Nature PG,REINFORCE,Natural Actor-Critic.
为什么要输出概率呢?举一个例子,比如我 (agent) 站在宿舍门口(state),Π判断我往前走的概率是0.7,向后/左/右走的概率各是0.1,那么policy会随机选择我接下来的action(概率大的被选到的可能性大)。这样agent就能自主移动啦。
RL算法目的为,优化策略policy,以更好地决策。agent根据policy自主与环境交互。而policy的好坏由reward评估。
RL有两个基本问题,其一是预测问题,或者叫策略评估(Policy Evaluation)。例如对model-free模型中,是给定状态集S,动作集A,即时奖励R,衰减因子γ,策略Π,求解该策略的状态价值函数v(Π)。其二是控制问题,或者叫策略提升(Policy Improvment)。给定状态集S,动作集A,即时奖励R,衰减因子γ,探索率ε,求解最优价值函数![]() 和最优策略
和最优策略![]() 。在model-based中还给定了概率转移矩阵P。
。在model-based中还给定了概率转移矩阵P。
实际环境是复杂的,建模很麻烦。于是引入马尔可夫性质定义问题,它指,"The future is independent of the past given the present",即未来只与现在有关。
则将RL情景定义为MDP (Markov Decision Process):

上图中,参数,如S,P,R的定义都用是Markovian的
策略Π也由MDP定义为:![]() ,即在状态s时采取动作a的概率只与挡墙状态s有关,与过去状态无关
,即在状态s时采取动作a的概率只与挡墙状态s有关,与过去状态无关
状态的价值v(利用Bellman Equation):
其中,G(t)是从当前状态开始的一条trajectory上的reward,用了discount factor是为了削弱较远状态的影响
在状态s下采取动作a的价值q(利用Bellman Equation):
v和q关系:![]()
通常使用v或q评估policy的好坏、以及指导policy优化(![]() )
)
动态规划DP
动态规划(Dynamic Programming ,DP)用于解决model-based RL problem,它需要提前知道模型的状态转移矩阵P(即知道某个state采取某个action后next state的分布情况)。
DP用于求value,它将problem划分成更小的sub-problem。在回溯更新某个状态的价值时,需要回溯该状态所有的后续价值。![]()
讲一讲使用动态规划的Policy Iteration 和 Value Iteration。
Policy Iteration
就是这个图:
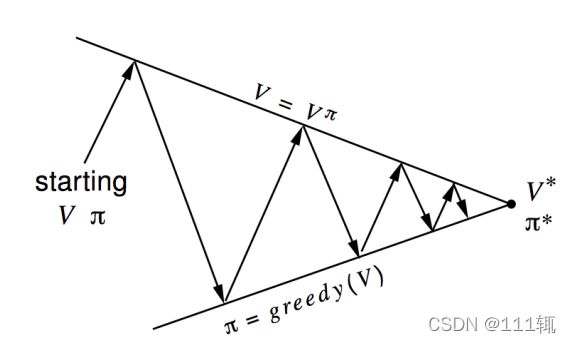
好好看懂这个图Π是怎么收敛的就懂这个算法的意思了。这里是deterministic policy
具体步骤silver的ppt讲得特别明白,一遍没看懂,第二遍就看懂个七八十了,写得很清晰:


Value Iteration
从上面的算法流程得知,Policy Iteration中value是不断通过更新的策略得出的。但是,通过![]() 定义得出value 后,其实可以不用显式地定义policy,直接每次贪婪地选择value最大的action就可以了
定义得出value 后,其实可以不用显式地定义policy,直接每次贪婪地选择value最大的action就可以了
蒙特卡洛MC
蒙特卡洛(Monte Carlo,MC)通过sampling近似求解,通过采样若干经历complete episode评估状态的真实价值,真实价值是多条episode的G(t)的均值,即 ![]()
由Incremental Mean推导公式,得出价值函数和状态-价值函数: ![]()
![]()
根据是否计算序列中重复状态的G(t),分为first-visit MC和every-visit MC,后者用得更多。
Policy Evaluation时,套上面的V或Q公式就行了。Policy Improment时,相对于动态规划的优化![]() ,MC一般优化
,MC一般优化![]() 。在使用deterministic policy选择action时,不同于DP一般用贪婪,MC一般用ε-贪婪,增加Exploaration,ε会逐渐减小至0便于收敛
。在使用deterministic policy选择action时,不同于DP一般用贪婪,MC一般用ε-贪婪,增加Exploaration,ε会逐渐减小至0便于收敛
时序差分TD
时序差分(Temporal-Difference,TD)通过sampling近似求解,通过采样若干incomplete sequence评估状态的真实价值,由Bellman Equation,
![]()
这种用TD目标值(![]() )代替G(t)的过程称为引导(bootstrapping)。TD误差为
)代替G(t)的过程称为引导(bootstrapping)。TD误差为![]()
对TD,同样的,价值函数和状态-价值函数定义为:
![]()
![]()
其中,α∈[0,1]
n-step TD
n-step TD就是不只往前看一步了。比如2-step往前多看两步,此时某个状态的价值变成![]()
TD(λ)
TD(λ)为了避免n-step TD不知道怎么选n的问题,引入了参数λ以便于调超参,sampling时G(t)变成![]()
Policy Evaluation时,套TD的Q公式就行了。Policy Improvment时,TD常见的on-policy是SARSA,常见的off-policy是Q-learning。TD思想是主流RL的基础。
on-policy是指只使用1个policy 选择动作实际与环境交互 和 更新价值函数。off-policy指使用2个policy,1个policy用于选择动作与环境交互(为了保证Exploration;一般用ε-贪婪),1个policy用于优化价值函数(为了保证Exploitation;一般用贪婪)
SARSA
SARSA (state → action → reward → state → action),是TD思想的算法。Policy Evaluation部分和TD的v(s)一样,Policy Improvment时使用on-policy,价值迭代公式也与TD一样,使用ε-贪婪选择action。其实SARSA就是最简单的TD思想的体现。
Q-learning
TD采样模拟求q(s,a),off-policy。想想off-policy这个想法的提出还真是挺妙的,相较于ε-贪婪更能在E&E间取平衡

关于Q-learning受数据影响较大的问题:
Q-learing直接学习最优策略,而最优策略对训练数据的依赖性较大(后面的算法使用buffer降低数据的相关性和策略的数据依赖性),所以受数据影响较大。如果训练数据的方差很大,这可能会影响Q函数的收敛,可能陷入一些特殊的最优"陷阱",比如"Cliff Walk"。
因此在实际生产中,如果在模拟环境中训练强化学习模型,推荐使用Q-learning。如果是在线生产环境中训练模型,则推荐使用SARSA
Q-learning算法的tips:


DQN
DQN (Deep Q-learning) 和Q-learning的不同之处就在于使用神经网络来模拟q![]() 其中,w是神经网络的权重。DQN向神经网络中输入state,神经网络会自动映射出q(其实还有一种是向其输入s和a,自动映射出q)。神经网络用CNN、RNN等都可以。
其中,w是神经网络的权重。DQN向神经网络中输入state,神经网络会自动映射出q(其实还有一种是向其输入s和a,自动映射出q)。神经网络用CNN、RNN等都可以。

很显然的Q-learning和DQN都是value-based method
为了适应大规模复杂问题,向RL中引入DL。传统的RL算法,如SARSA、Q-learning需要保存一张很大的Q(state,action),当问题规模增大,内存溢出。所以不想保存Q表,需要一种从(s,a)到s直接映射到Q的方法,线性近似、决策树、最近邻、傅里叶变换、神经网络等都能用,目前最主流的是神经网络,所以向RL中引入了DL。DRL算法比如DQN,通过神经网络构建从state到action的映射,即向神经网络输入state,直接就能输出action,不需要保存Q表,保存网络参数就行,所需存储空间小了很多。
Nature DQN
DQN中目标Q的计算和训练Q都是用一个模型计算的,相关性太强了,不利于收敛。于是Nature DQN想到了用两个Q网络。一个current Q网络用来选择动作,更新模型参数。另一个target Q'网络用于计算目标Q值。target Q'网络的参数不需要一直更新,过段时间从current Q网络复制过来就行了。两个网络结构是完全一样的,才可以复制
DDQN
它也用了像Nature DQN一样的两个网络。但是它改动了一点,就是对target Q的计算。Q-learning和DQN在计算target Q的时候都是通过贪婪直接得到的,即取Qmax的那个。但是这容易陷入Over Estimate,使模型有很大bias。
DDQN将target Q的选择解耦合为两步,第一步是选择Qmax的action,第二步将这个action代入计算target Q
对比下
DQN的target Q:![]()
DDQN的target Q:![]()
Prioritized Repay DQN
它也像Nature DQN一样有两个网络。它对buffer中取样改进了一点,不再是随机取样了,而是给样本赋予了权重。TD误差大的赋予的权重高(因为对神经网络误差反向传播有利)

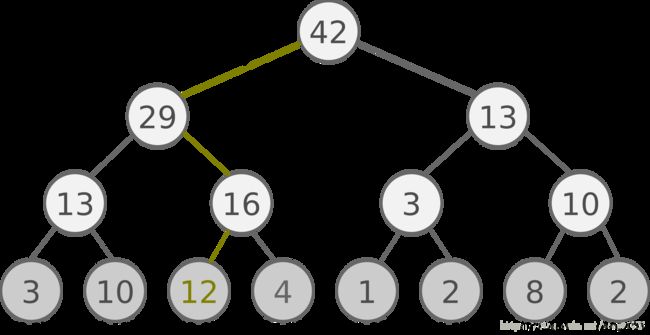
如何根据样本权重选择样本:SumTree。其叶子节点是样本权重,往上加和。
比如想在[0-42]间抽样一个优先级,肯定是[13-25]这个区间长的被抽到啊。比如抽到了20,顺着树往下找,就找到12了。而优先级高的区间长。真挺巧妙的。
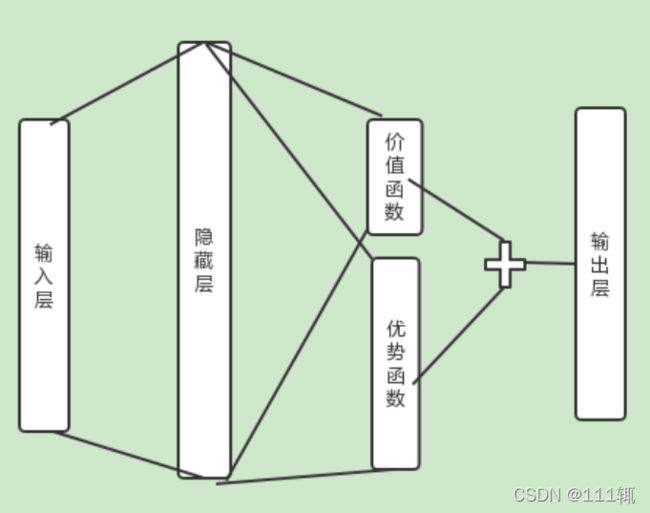
Dueling DQN
Dueling DQN在Nature DQN上就改进了一点,将神经网络的结构稍微改了一下,将最终Q值输出变成两部分,一部分是只与状态s有关的Value Fuction V,另一部分是同时与状态s和动作a有关的Advantage Function A。
![]()
Policy Gradient
比较主流的是Nature DQN,Prioritized DQN和Dueling DQN。三种算法思路不相互排斥,可以混着用。当然还有很多对DQN的改进,比如改网络什么的。但是DQN有一个缺陷是只能处理离散的动作,对于连续动作的处理能力不行,policy-based method可以解决这个问题,因为![]() 是一个连续函数,不同于value-based method的
是一个连续函数,不同于value-based method的![]() 。value-based method还有一个问题是一般都是取max value的动作,直接贪婪。但是有时候现实问题是随机的,不是每次都要做最好的选择,这时也可以考虑用policy-based method
。value-based method还有一个问题是一般都是取max value的动作,直接贪婪。但是有时候现实问题是随机的,不是每次都要做最好的选择,这时也可以考虑用policy-based method
就像在value-based method中对q做近似:![]() ,在policy-based method中可以对策略Π做近似:
,在policy-based method中可以对策略Π做近似:![]() ,然后对参数θ(模型权重)求解优化就好了,以下还是用DL神经网络做近似,其它传统ML的近似方法应该也可以。
,然后对参数θ(模型权重)求解优化就好了,以下还是用DL神经网络做近似,其它传统ML的近似方法应该也可以。
定义一个优化目标,可以用状态s的价值的期望,![]() ,然后基于这个目标函数梯度上升就行了。对θ求导得梯度,
,然后基于这个目标函数梯度上升就行了。对θ求导得梯度,![]() 。
。
cs285这节课推导比前几节课多太多了,就手推了一下几个公式。有时候看看不懂,但是动笔推一遍就差不多懂了
在实践中,对PG的一些训练tips:
- 调非常大batch size(由于MC从trajectory积累reward求期望,PG的variance很大,gradient噪声也较大)
- PG学习率比较难调(因为gradient噪声大),勉强能用ADAM。一般使用PG专用的自动确定学习步长的方式,如PPO/TRPO
REINFORCE
一个最简单policy gradient:REINFORCE

可见在policy-based method,确实可以讲没有value function V,但是确实有每个状态的value v啊。value指导policy的参数的优化。
Actor-Critic
结合了一下value-based method和policy-based method
其中,Actor(演员)是策略函数,负责生成action,与环境交互。Critic(批判者)是价值函数,负责评估、优化Actor的表现,即优化策略。
在PG,用MC计算每个状态的价值,其实也相当于一种Critic,但是场景比较受限(需要多条完整episode路径)。在Actor-Critic中将Critic的功能进一步加重,这里使用了类似DQN中的价值函数
在Critic-Actor中需要对q和Π都做近似,即
![]()
![]()
具体过程为,Critic通过神经网络计算评估点(可以是state value function / state-action value funciton / advantage function / TD误差 ),Actor使用神经网络梯度反向传播(目标函数是Critic的评估点)不断更新策略函数的参数θ。 Critic和Actor的神经网络可以是相同的,也可以是不同的。

DPG
DPG (Deterministic policy gradient)。deterministic就是策略不随机了,在某个state下就采取这个action:![]()
DDPG
DDPG (Deep Deterministic policy gradient) 是使用了双Actor(这俩结构相同)和双Critic结构(这俩结构相同),就是DQN到Nature DQN的思想
这个博主就对这四个网络的功能总结得挺好:

DDPG还有两个挺有意思的点,其一,当前网络从目标网络复制参数w、θ的时候,不是一下全部复制过来的,而是加了一个更新系数(一般取0.1/0.01),即每次改变一点点。其二是在Actor当前网络中选择动作的时候,为了增加随机性,会给动作加点噪声,即![]()
其实DDPG中的Critic当前网络、Critic目标网络和DDQN中的当前Q网络、目标Q网络的功能差不多。但是DDQN中没有单独的policy function Π(因为是value-based method),每次选择动作就用ε-贪婪这样的方法。在Actor-Critic的DDPG中,Actor网络来选动作,就不用ε-贪婪了。
A3C
A3C中用了多线程。一个主线程负责更新Actor网络和Critic网络的参数,多个辅线程负责与环境交互,得到梯度更新值,汇总更新主线程的参数(异步并发)。所有辅线程定期从主线程更新网络参数。这些辅线程起到了类似DQN中经验回放的作用。
A3C中的多个辅线程还改进累类似repay experience的问题,就是buffer中的数据相关性比较强。比如一直跟一个人下棋,那水平很难得到提高。应该跟有不同思考方式的多个人对弈。
A3C中的Critic用了Advantage Function作为评估点,![]() ,这里的V(s)其实就相当于baseline的作用,因为V(s)代表该状态价值,是Q关于所有action的期望,代表了所有state-action的平均好坏。如果A>0,则在该状态下采取该动作会更好,反之则更差。而advantage function中的Q可以用V表示出来,即
,这里的V(s)其实就相当于baseline的作用,因为V(s)代表该状态价值,是Q关于所有action的期望,代表了所有state-action的平均好坏。如果A>0,则在该状态下采取该动作会更好,反之则更差。而advantage function中的Q可以用V表示出来,即![]() 。则优势函数表示为,
。则优势函数表示为,![]() 。A3C中用了n-step sampling,则优势函数进一步表示为,
。A3C中用了n-step sampling,则优势函数进一步表示为,![]()
Model-based method
model-based method要知道环境转换的模型,即用状态转移概率(s采取动作a到s'的概率),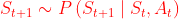 和Reward
和Reward![]() 描述
描述
表示环境模型,即表示这两个问题:![]() 和
和 ![]() 。很显然,前者是分类问题,后者是回归问题。用传统的监督学习算法求解就可以了。
。很显然,前者是分类问题,后者是回归问题。用传统的监督学习算法求解就可以了。
有模型时,就知道state下采取action后会到什么状态,能得到什么动作奖励,就不必和环境交互了。model-based method是从模型中学习,而不是从与环境交互的过程中学习。所以环境模型的表示十分重要
model-based method整体流程:
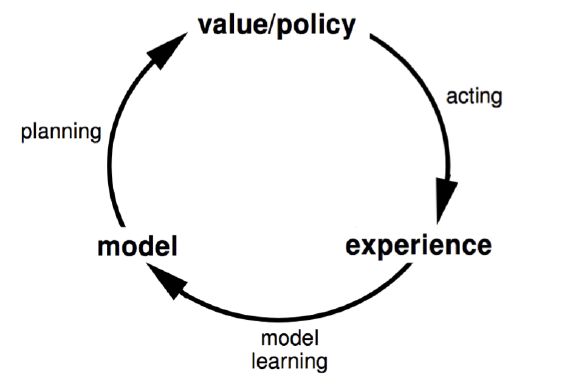
model-based method一般不单独用,而是与model-free method结合起来,比如Dyna、MCTS。
Dyna
Dyna不是具体的算法,而是一类算法框架的统称。它结合了model-based method 和 model-free method,即既从模型中学习,也从实际与环境交互中学习,从而更新策略函数或价值函数。Dyna和不同model-free强化学习算法结合起来,就能得到不同算法。
Dyna-Q

MCTS
它也是一种比较流行的model-based和model-free method结合的RL算法,是基于模拟的搜索(stimulate based search),适合海量数据。两个关键点,其一是stimulate,即数据不是真实地与环境交互得来的,而是"模拟"的。其二是search,是利用stimulated data找策略(到底该采取什么样的action才能使value最大化)
基本MCTS就是根据模拟的输出结果,按照节点构造搜索树。于MCTS的树结构,如果是最简单的方法,只需要在节点上保存状态对应的历史胜负记录。在每条边上保存采样的动作。这样MCTS的搜索需要走4步
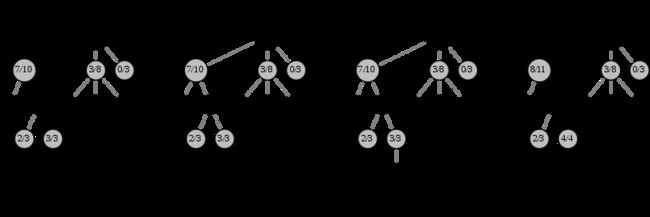
第一步是选择(Selection):这一步会从根节点开始,每次都选一个“最值得搜索的子节点”,一般使用UCT(Upper Confidence Bound Applied to Trees, 上限置信区间算法,为达E&E平衡)选择分数最高的节点,直到来到一个“存在未扩展的子节点”的节点(没有后续走法),如图中的 3/3 节点。
第二步是扩展(Expansion),在这个搜索到的存在未扩展的子节点,加上一个0/0的子节点,表示没有历史记录参考。
第三步是仿真(simulation),从上面这个没有试过的着法开始,用一个简单策略比如快速走子策略(Rollout policy)走到底,得到一个胜负结果。快速走子策略一般适合选择走子很快可能不是很精确的策略。因为如果这个策略走得慢,结果虽然会更准确,但由于耗时多了,在单位时间内的模拟次数就少了,所以不一定会棋力更强,有可能会更弱。这也是为什么一般只模拟一次,因为如果模拟多次,虽然更准确,但更慢。
第四步是回溯(backpropagation), 将最后得到的胜负结果回溯加到MCTS树结构上。
还有一些其它有意思的点:
上述这些算法的Reward都是基于人工设计的,这就引入了人工知识,也在一定程度上引入了偏差。也有一些在寻求避免人工设计Reward的方法(cs285第一课)。第一种是learning from demonstrations,要么是从以往案例中学习,imitation learning,要么是agent基于人类样例学习reward如何表示,即IRL (Inverse RL)。第二种是learning from observing the world,这个每太听懂,好像就是model-based对环境建模。第三种是learning from other tasks,包括transfer learning(从其它任务中学会知识以迁移)和meta-learning(从其它任务中学会学习的方法)
参考资料
上确界(sup)和下确界(inf)
共轭函数通俗解释1:线性函数yTx和原始函数f(x)的最大gap
共轭函数数学定义2
Daul Ascent对偶上升法
对偶函数也称为拉格朗日对偶函数(Lagrange daul function)
Daul Ascent将优化目标的约束条件转化为优化目标的一部分,
从而将对目标函数在约束下进行优化的过程等价为直接优化对偶目标函数的行为。
s.t.指约束条件
Jocab矩阵(一阶导)和Hessian矩阵(二阶导)
矩阵求导
LQR和iLQR
贝叶斯
联合概率、边际概率、条件概率
特征向量表示了向量的"变换"特征
在机器学习里面,张量通常意味着数组,没有实际物理意义。如TensorFlow的意思是:N维数组从数据流图的一端流动到另一端的计算过程。
极大似然估计,通俗理解来说,就是利用已知的样本结果信息,反推最具有可能(最大概率)导致这些样本结果出现的模型参数值。换句话说,极大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”
KL divergence指当某分布q(x)被用于近似p(x)时的信息损失。即q(x)能在多大程度上表达p(x)所包含的信息,KL divergence越大,表达效果越差
on-policy和off-policy区别
二者区别在于采样的policy和improve的policy是否相同
①on-policy只有行为策略,就是跟实际数据产生、实际与环境交互相关的,是训练中的策略
②off-policy同时有行为策略和目标策略,目标策略根据行为策略优化、调整
Sarsa和Q-learning区别
①都属于TD算法(temporal difference RL)(时序差分算法)
②Sarsa是on-policy,Q-learning是off-policy
③Q-learning的行为策略和Sarsa相同,都是利用该状态S的即时奖励和下个状态S’的Q值来更新S的Q值,但是其选择的下个状态价值对(s’,a’)中的a’是根据ε-greedy策略选取的,具备一定的Exploration;其目标策略和行为策略唯一的不同是选取下个状态价值对(s’,a’)是选的最大Q值的,更加贪婪
全连接FC到卷积CNN
卷积神经网络基础概念
卷积神经网络channel
池化:减少冗余信息,看一下这个回答中的卷积、池化的两个动图就发现区别了。池化一般选滑动窗口中最值/均值,不是像卷积核一样带权重地滑动
DQN
Policy Gradient
贝叶斯神经网络(BNN)
BNN(Bayesian Neural Network)将权重看作服从μ,δ的高斯分布。普通CNN优化的是权重,BNN优化的是权重的均值和方差,所以其优化参数是普通CNN的两倍。
在预测时,BNN会从每个高斯分布中采样,得到权重值,反向传播。
BNN(二值化神经网络)
跟上面那个不一样。还查资料查串了最后发现。BNN (Binary Neural Network) 的结构和CNN一样,只是在梯度下降、权值更新、卷积运算熵做了一些改进。其权值、激活值只能为1或-1。
FCN:解决图像分割问题
熵、信息量、相对熵(KL convergence)、交叉熵
熵是不确定性的度量,是对所有可能发生的事件产生的信息量的期望。信息量和确定性成反比。相对熵(KL convergence)一般衡量两个分布p(x)和q(x)的差异,如样本的真实分布和预测分布。交叉熵其实就是把相对熵中的常数部分去掉了,作为优化的目标。其实用KL convergence也一样。
softmax
将输入映射为(0,1),可视为多分类的概率
书籍PRML(Pattern Recognition And Machine Learning)第十章:Approximate Inference
近似计算有随机和确定两种方法,变分是后者。
mean field是统计物理学中常用思想,将无法处理得复杂多体问题分解成可以处理得单体问题来近似。例如在计算某个分布的积分时,可以变成多个较低维度的积分。这是一种可分解的变分近似思想。
变分推断,实际就是用形式简单、做积分比较容易的分布,去近似形式复杂、不易求积分的分布,衡量分布差异大小用到了KLD。最小化KLD为优化目标。使用coordinate ascent收敛至局部最优
Online learning:其实就是跑一个样本更新一次参数
Online learning和batch learning这两者存在于对机器学习算法的训练中,是训练方法。以训练神经网络为例,训练神经网络时需要计算损失函数,根据损失函数计算参数的梯度,从而去更新参数。这就涉及到神经网络学习多少样本后去计算损失函数,更新参数了。如果每学习一个样本,就去更新参数的话,这就是online learning。如果学习所有样本后,再去更新参数,这就是batch learning。显然,batch learning的优点是容易找到全局最优解,但样本较大时训练过程很慢。而online learning则相反。为了折中,出现了小批量学习,即学习小批量样本后更新参数,这个小批量的样本数量自己制定。
Boostrap是一种抽样方法,在ensemble learning中很常见。是指对样本每次有放回的抽样,抽样K个,一共抽N次
反向传播
回归问题用于建模和分析变量间的关系,多用于预测问题,如根据某地多年房价预测今年的
LQR
PID控制
sum tree