OPENCV学习记录|CSDN创作打卡
文章目录
-
- 1、opencv的基本元素-图片
- 2、使用摄像头
- 3、图像基本操作
- 4、颜色空间转换
- 5、阈值分割图像
- 6、图像几何变换
- 7、实现绘图功能
- 8、图像混合
- 9、图像平滑
- 10、边缘检测
- 11、腐蚀与膨胀
- 12、轮廓特征
本文用到的参考(官方文档,中文说明,大佬的教程):
- https://docs.opencv.org/4.0.0/d7/d1b/group__imgproc__misc.html#ggaa9e58d2860d4afa658ef70a9b1115576a147222a96556ebc1d948b372bcd7ac59
- https://opencv.apachecn.org/#/docs/4.0.0/4.3-tutorial_py_thresholding?id=%e7%ae%80%e5%8d%95%e9%98%88%e5%80%bc%e6%b3%95
- http://codec.wang/#/opencv/start/06-image-thresholding
1、opencv的基本元素-图片
加载 显示 保存图片
OpenCV函数:cv2.imread(), cv2.imshow(), cv2.imwrite()
电脑上的彩色图是以RGB(红-绿-蓝,Red-Green-Blue)颜色模式显示的,但OpenCV中彩色图是以B-G-R通道顺序存储的,灰度图只有一个通道。图像坐标的起始点是在左上角,所以行对应的是y,列对应的是x
最基本读取
import cv2
filepath = '../Resources/'
img = cv2.imread(filepath+'lean.png', 0)
- 关注参数2:读入方式
cv2.IMREAD_COLOR:彩色图,默认值(1)
cv2.IMREAD_GRAYSCALE:灰度图(0)
cv2.IMREAD_UNCHANGED:包含透明通道的彩色图(-1)
显示
import cv2
filepath = '../Resources/'
img = cv2.imread(filepath+'lena.png', 0)
cv2.imshow('lena', img)
cv2.waitKey(0)
- 注意第一个窗口名,第二个是图像句柄
或者使用
# 先定义窗口,后显示图片
cv2.namedWindow('lena2', cv2.WINDOW_NORMAL)
cv2.imshow('lena2', img)
cv2.waitKey(0)
先创建一个窗口,之后在显示图片,第二个参数可选择,可以是窗口适应图片或者窗口可调整之类的
保存
cv2.imwrite('lena_gray.jpg', img)
2、使用摄像头
摄像头捕获照片、播放本地视频、录制视频
打开摄像头
import cv2
capture = cv2.VideoCapture(0)
while(True):
# 获取一帧
ret, frame = capture.read()
# 将这帧转换为灰度图
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imshow('frame', gray)
if cv2.waitKey(1) == ord('q'):
break
就是一帧帧的死循环展示图像,这样就是打开摄像头的意思了
- 关注一下里面提到的waitkey
是–是在一个给定的时间内(单位ms)等待用户按键触发,如果是0无限制等待
单位是ms,这样就是1ms一帧图像了,当然要看主机是不是处理的过来
然后是ord(),就是将q转换为ascll值
然后是有的版本代码要写成cv2.waitKey(1) & 0xFF == ord(‘q’),因为ascll值的范围是0-255,用这个运算保证这个值始终在0-255
然后还可以关注下这个函数
通过 cap.get(propId) 可以获取摄像头的一些属性,比如捕获的分辨率,亮度和对比度等。propId是从0~18的数字,代表不同的属性,一共是18个参数
| cv2.VideoCapture.get(0) | 视频文件的当前位置(播放)以毫秒为单位 |
|---|---|
| cv2.VideoCapture.get(1) | 基于以0开始的被捕获或解码的帧索引 |
| cv2.VideoCapture.get(2) | 视频文件的相对位置(播放):0=电影开始,1=影片的结尾。 |
| cv2.VideoCapture.get(3) | 在视频流的帧的宽度 |
| cv2.VideoCapture.get(4) | 在视频流的帧的高度 |
| cv2.VideoCapture.get(5) | 帧速率 |
| cv2.VideoCapture.get(6) | 编解码的4字-字符代码 |
| cv2.VideoCapture.get(7) | 视频文件中的帧数 |
| cv2.VideoCapture.get(8) | 返回对象的格式 |
| cv2.VideoCapture.get(9) | 返回后端特定的值,该值指示当前捕获模式 |
| cv2.VideoCapture.get(10) | 图像的亮度(仅适用于照相机) |
| cv2.VideoCapture.get(11) | 图像的对比度(仅适用于照相机) |
| cv2.VideoCapture.get(12) | 图像的饱和度(仅适用于照相机) |
| cv2.VideoCapture.get(13) | 色调图像(仅适用于照相机) |
| cv2.VideoCapture.get(14) | 图像增益(仅适用于照相机)(Gain在摄影中表示白平衡提升) |
| cv2.VideoCapture.get(15) | 曝光(仅适用于照相机) |
| cv2.VideoCapture.get(16) | 指示是否应将图像转换为RGB布尔标志 |
| cv2.VideoCapture.get(17) | × 暂时不支持 |
| cv2.VideoCapture.get(18) | 立体摄像机的矫正标注(目前只有DC1394 v.2.x后端支持这个功能) |
上表摘自这个链接 https://www.jianshu.com/p/676bef32e655
常用的就两个吧感觉
width, height = capture.get(3), capture.get(4)
# 放大一倍
capture.set(cv2.CAP_PROP_FRAME_WIDTH, width * 2)
capture.set(cv2.CAP_PROP_FRAME_HEIGHT, height * 2)
图像高宽,这里我试了调整好像不太行啊,可能是摄像头支持还是咋地,不清楚
没摄像头还可以用视频流
# 网络视频读取
video = "http://admin:[email protected]:8081/"
cap = cv2.VideoCapture(video)
while True:
success, img = cap.read()
cv2.imshow("video",img)
if cv2.waitKey(5) & 0xFF == ord('q'):
break
cap.release()
需要手机下载一个ip摄像头的工具,就可以了

可以看到这里提供了这个ip,输入ip传入读取的函数就可以了,效果如下

播放本地视频
import cv2
filepath = '../Resources/'
capture = cv2.VideoCapture(filepath+'test_video.mp4')
while(capture.isOpened()):
ret, frame = capture.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imshow('frame', gray)
if cv2.waitKey(30) == ord('q'):
break
还是一眼的哦,这里视频25-30帧即可
录制视频
import cv2
capture = cv2.VideoCapture(0)
# 定义编码方式并创建VideoWriter对象
fourcc = cv2.VideoWriter_fourcc(*'MJPG')
outfile = cv2.VideoWriter('output.avi', fourcc, 25., (640, 480))
while(capture.isOpened()):
ret, frame = capture.read()
if ret:
outfile.write(frame) # 写入文件
cv2.imshow('frame', frame)
if cv2.waitKey(1) == ord('q'):
break
else:
break
- 录制视频的操作
首先是准备好录制什么视频,文件名,编码方式,帧率,分辨率
其次就是write写入文件这个操作了
3、图像基本操作
获取和修改像素点的值
import cv2
filepath = '../Resources/'
img = cv2.imread(filepath+'lena.png', 1)
px = img[100,90]
print(px)
# 只获取蓝色blue通道的值
px_blue = img[100, 90, 0] #这里是bgr,那么蓝绿红最大就是2
print(px_blue)
修改值
import cv2
filepath = '../Resources/'
img = cv2.imread(filepath+'lena.png', 1)
px = img[100,90]
print(px)
img[100,90]=[255,255,255]
print(img[100,90])
打印出来可以看出像素点的值被修改
图片属性
这里我们用lena图来做测试,可以看出它是一张512-512-3的大小的图像
import cv2 as cv
import numpy as np
if __name__ == '__main__':
img = cv.imread("../Resources/lena.png")
print(img.shape)
height, width, channels = img.shape
print(img.dtype) #返回数据类型
print(img.size) #返回图像的总数据大小 就是512*512*3
返回图像数据的元祖,后面的数据类型一般是uint8,图像的总像素大小

ROI
import cv2
import numpy as np
if __name__ == '__main__':
img = cv2.imread("../Resources/lena.png")
# 截取脸部ROI
face = img[204:372, 179:360]
cv2.imshow('face', face)
cv2.waitKey(0)
通道分离
import cv2
import numpy as np
if __name__ == '__main__':
img = cv2.imread("../Resources/OIP-C.jpg")
b, g, r = cv2.split(img)
cv2.imshow("Blue", r)
cv2.imshow("Red", g)
cv2.imshow("Green", b)
cv2.waitKey(0)
cv2.destroyAllWindows()
这个还不明显,换一张看看就明显了

但是据说这个用切分的方法速度慢,用numpy索引的方式比较快,下面我用索引的方式来试试
import cv2
import numpy as np
if __name__ == '__main__':
img = cv2.imread("../Resources/OIP-C.jpg")
b = img[:, :, 0]
g = img[:, :, 1]
r = img[:, :, 2]
cv2.imshow('b', b)
cv2.imshow('g', g)
cv2.imshow('r', r)
cv2.waitKey(0)
效果是一样的,这里就不贴图了,具体参数的含义为:
- 用img[:,:,0]分离出0通道或b通道,img[:,:,1]对应g通道,img[:,:,2]对应r通道,如果有img[:,:,3]则对应alpha通道。
分离之后就可以合并了,官方函数是merge函数,用已有的多个通道图像构造成一个元组传递给merge(),实现图像的合并。
这里注意一定要是bgr这个顺序,不然会有很奇怪的图片出现
import cv2
import numpy as np
if __name__ == '__main__':
img = cv2.imread("../Resources/OIP-C.jpg")
b = img[:, :, 0]
g = img[:, :, 1]
r = img[:, :, 2]
cv2.imshow('b', b)
cv2.imshow('g', g)
cv2.imshow('r', r)
img2 = cv2.merge((b, g, r))
cv2.imshow('hebing', img2)
cv2.waitKey(0)
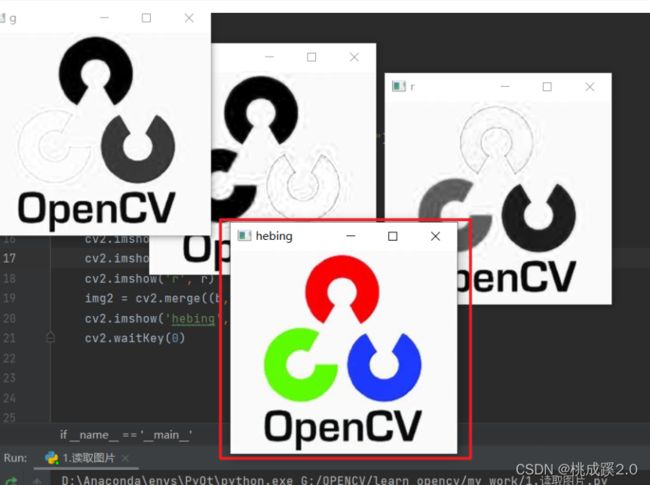
4、颜色空间转换
灰度转换
import cv2
import numpy as np
if __name__ == '__main__':
img = cv2.imread("../Resources/OIP-C.jpg")
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cv2.imshow('img', img)
cv2.imshow('gray', img_gray)
cv2.waitKey(0)
cv2.cvtColor()用来进行颜色模型转换,参数1是要转换的图片,参数2是转换模式, COLOR_BGR2GRAY表示BGR→Gray
根据颜色来追踪物体
这里说明一般用hsv的颜色模型,HSV的方式相比BGR更易区分颜色,转换模式用COLOR_BGR2HSV表示,关于HSV的说明我以看我之前的博客介绍
代码如下
import cv2
import numpy as np
capture = cv2.VideoCapture(1)
#颜色阈值范围
lower_blue = np.array([100, 110, 110])
upper_blue = np.array([130, 255, 255])
while(True):
ret, frame = capture.read()
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV) #转为hsv的格式
mask = cv2.inRange(hsv, lower_blue, upper_blue) #低于阈值变为0,高于阈值变为0
res = cv2.bitwise_and(frame, frame, mask=mask) #求交集
cv2.imshow('frame', frame)
cv2.imshow('mask', mask)
cv2.imshow('res', res)
if cv2.waitKey(1) == ord('q'):
break
效果如下
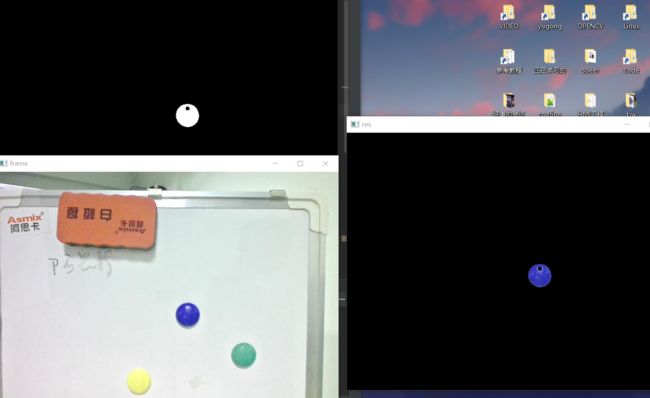
5、阈值分割图像
- 固定阈值
- 自适应阈值
- 大津法(OSTU阈值法)
固定阈值分割
大于阈值变为一类,小于变为一类,这个在上面已经展示过了
import cv2
# 灰度图读入
img = cv2.imread('../Resources/lena.png', 0)
# 阈值分割
ret, th = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)
cv2.imshow('thresh', th)
cv2.waitKey(0)
第一个参数就是传入的图像(需要灰度),第二个是阈值范围,第三个参数是 maxval,它表示像素值大于(有时小于)阈值时要给定的值。opencv 提供了不同类型的阈值,由函数的第四个参数决定。不同的类型有:

上图为官方文档的图,后面的公式是说明,用代码对一张渐变的黑白图处理可以看到效果
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('../Resources/jianbian.jpg',0)
ret,thresh1 = cv.threshold(img,127,255,cv.THRESH_BINARY)
ret,thresh2 = cv.threshold(img,127,255,cv.THRESH_BINARY_INV)
ret,thresh3 = cv.threshold(img,127,255,cv.THRESH_TRUNC)
ret,thresh4 = cv.threshold(img,127,255,cv.THRESH_TOZERO)
ret,thresh5 = cv.threshold(img,127,255,cv.THRESH_TOZERO_INV)
titles = ['Original Image','BINARY','BINARY_INV','TRUNC','TOZERO','TOZERO_INV']
images = [img, thresh1, thresh2, thresh3, thresh4, thresh5]
for i in range(6):
plt.subplot(2,3,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
效果如下,详见上面函数参数后面的解释:
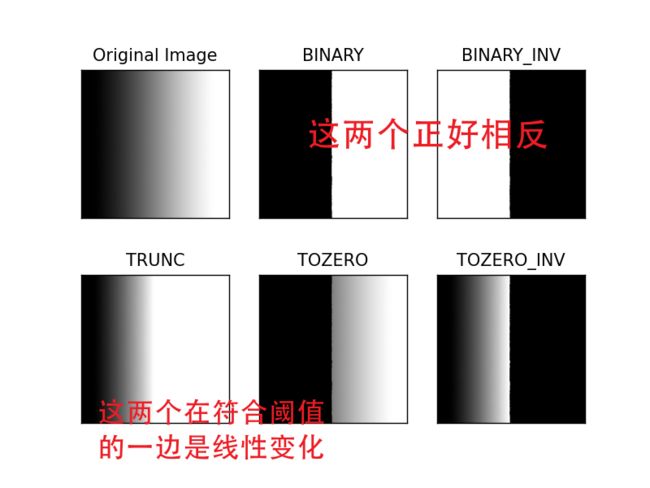
自适应阈值分割
自适应阈值会每次取图片的一小部分计算阈值,固定阈值是每次对整张图片进行处理,这种对于图片明暗不均的其实效果不好,自适应可以解决这个问题
import cv2
from matplotlib import pyplot as plt
# 自适应阈值对比固定阈值
img = cv2.imread('../Resources/sudoku.jpg', 0)
# 固定阈值
ret, th1 = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)
# 自适应阈值
th2 = cv2.adaptiveThreshold(
img, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 4)
th3 = cv2.adaptiveThreshold(
img, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 17, 6)
titles = ['Original', 'Global(v = 127)', 'Adaptive Mean', 'Adaptive Gaussian']
images = [img, th1, th2, th3]
for i in range(4):
plt.subplot(2, 2, i + 1), plt.imshow(images[i], 'gray')
plt.title(titles[i], fontsize=8)
plt.xticks([]), plt.yticks([])
plt.show()
效果如下:
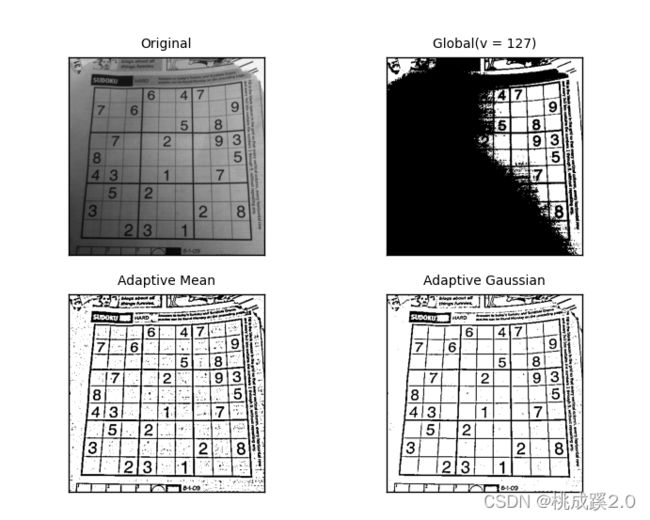
可以看出,首先是使用 adaptiveThreshold函数,然后后面的阈值计算方式有两种:
- ADAPTIVE_THRESH_MEAN_C 小区域取均值,根据均值来判断
- ADAPTIVE_THRESH_GAUSSIAN_C 使用高斯核来加权求和
然后阈值变黑还是变白这里只能使用THRESH_BINARY和THRESH_BINARY_INV,后面为小区域面积11就是11*11,最后一个参数是补充值,就是算出来的值减去这个值为最终值,利用这个最终值去比较
大津法(OSTU阈值法)
就是前面阈值都是127-255,但是不知道255是不是合适的,所以就直接输入0-255,然后传入cv.THRESH_OTSU这个参数去搜索,找到最合适的值,然后这个东西跟图像的直方图有关,这个我也不太清楚,官方的解释如下:
- 一个双峰图像(简单来说,双峰图像是一个直方图有两个峰值的图像),Otsu 二值化可以近似地取这些峰值中间的一个值作为阈值。
- 如果不是双峰图像呢,那二值化将不准确,就是效果会不好
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('../Resources/noisy.jpg',0)
# 全局阈值
ret1,th1 = cv.threshold(img,127,255,cv.THRESH_BINARY)
# Otsu 阈值
ret2,th2 = cv.threshold(img,0,255,cv.THRESH_BINARY+cv.THRESH_OTSU)
# 经过高斯滤波的 Otsu 阈值
blur = cv.GaussianBlur(img, (5, 5), 0)
ret3,th3 = cv.threshold(blur,0,255,cv.THRESH_BINARY+cv.THRESH_OTSU)
# 画出所有的图像和他们的直方图
images = [img, 0, th1,
img, 0, th2,
blur, 0, th3]
titles = ['Original Noisy Image','Histogram','Global Thresholding (v=127)',
'Original Noisy Image','Histogram',"Otsu's Thresholding",
'Gaussian filtered Image','Histogram',"Otsu's Thresholding"]
for i in range(3):
plt.subplot(3,3,i*3+1),plt.imshow(images[i*3],'gray')
plt.title(titles[i*3]), plt.xticks([]), plt.yticks([])
plt.subplot(3,3,i*3+2),plt.hist(images[i*3].ravel(),256)
plt.title(titles[i*3+1]), plt.xticks([]), plt.yticks([])
plt.subplot(3,3,i*3+3),plt.imshow(images[i*3+2],'gray')
plt.title(titles[i*3+2]), plt.xticks([]), plt.yticks([])
plt.show()
效果如下:

1
6、图像几何变换
缩放图片 cv2.resize
import cv2
img = cv2.imread('../Resources/lena.png')
# 按照指定的宽度、高度缩放图片
res = cv2.resize(img, (216, 216))
# 按照比例缩放,如x,y轴均放大一倍
res2 = cv2.resize(img, None, fx=0.5, fy=2, interpolation=cv2.INTER_LINEAR)
cv2.imshow('shrink', res), cv2.imshow('zoom', res2)
cv2.waitKey(0)
翻转图片 cv2.flip
使用filp()函数实现图像翻转
| 第二个参数 | 含义 |
|---|---|
| 1 | 水平翻转 |
| 0 | 垂直翻转 |
| -1 | 水平垂直翻转 |
import cv2
img = cv2.imread('../Resources/lena.png')
res = cv2.flip(img,1)
res2 = cv2.flip(img,0)
res3 = cv2.flip(img,-1)
cv2.imshow('shuiping', res), cv2.imshow('chuizhi', res2),cv2.imshow('shuipingchuizhi', res3)
cv2.waitKey(0)
效果如下
平移图片 cv2.warpAffine
import cv2
# 平移图片
import numpy as np
img = cv2.imread('../Resources/lena.png')
rows, cols = img.shape[:2]
# 实现平移,x-100,y50
M = np.float32([[1, 0, -100], [0, 1, 50]])
#仿射变换实现平移
dst = cv2.warpAffine(img, M, (cols, rows))
cv2.imshow('shift', dst)
cv2.waitKey(0)
旋转图片 cv2.getRotationMatrix2D()
import cv2
# 平移图片
import numpy as np
img = cv2.imread('../Resources/lena.png')
rows, cols = img.shape[:2]
# 旋转中心 旋转角度,缩放比例
M = cv2.getRotationMatrix2D((cols / 2, rows / 2), 45, 0.5)
dst = cv2.warpAffine(img, M, (cols, rows))
cv2.imshow('rotation', dst)
cv2.waitKey(0)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZOUEZOlU-1642927002554)(https://img1.imgtp.com/2022/01/23/u6VJBz1p.png)]
7、实现绘图功能
- 画线 cv2.line()
- 画圆 cv2.circle()
- 画矩形 cv2.rectangle()
- 添加文字 cv2.putText()
共同的参数:
- img 图像
颜色 color
线宽 默认是1 thickness
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 准备一张黑色图片
img = np.zeros((512, 512, 3), np.uint8)
# 起点,终点,颜色,线宽
cv2.line(img, (0, 0), (512, 512), (255, 0, 0), 5)
cv2.imshow('img',img)
cv2.waitKey(0)
注意:
- 终点起点什么的不在图像内部没关系,看不到就是了,线宽为0的话实际大小还是1
- 绘制多边形看起来比较像把点都连起来的样子(不闭合的情况),就相当于多cv2.line,但是他的速度比cv2.line快很多
- 文字的左下角是文字的起始点,所以如果文字的y取得比较小就很容易被遮住
示例如下:
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 准备一张黑色图片
img = np.zeros((512, 512, 3), np.uint8)
# 起点,终点,颜色,线宽
cv2.line(img, (0, 0), (512, 512), (255, 0, 0), 5)
# 起点 终点 颜色 线宽
cv2.rectangle(img,(50,50),(100,520),(255, 0, 0),0)
# 圆心,半径,颜色,线宽
cv2.circle(img,(256,256),50,(0,255,0),2)
# 椭圆 圆心 x,y轴的长度,旋转角度 起始角度,结束角度
cv2.ellipse(img,(255,100),(100,60),0,0,360,(0,0,255),2)
# 指定多边形的定顶点坐标,之后变成矩阵才可以绘制
pts = np.array([[10, 5], [50, 10], [70, 20], [20, 30]], np.int32)
pts = pts.reshape((-1,1,2))
cv2.polylines(img,[pts],True,(0,0,255)) # 这里的参数true决定多边形是否闭合
# 添加文本,起始坐标(左下角为起点) 字体 文字大小
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img, 'lx2035', (10, 100), font, 2, (255, 255, 255), 2, lineType=cv2.LINE_AA)
cv2.imshow('img',img)
cv2.waitKey(0)
效果如下:

8、图像混合
本质是图像之间的混合运算
图像混合
import cv2
import numpy as np
import matplotlib.pyplot as plt
img = cv2.imread('../Resources/lena.png')
img1 = cv2.resize(img,(174,174))
img2 = cv2.imread('../Resources/logo.png')
img3 = cv2.addWeighted(img1,0.6,img2,0.4,0)
cv2.imshow('add',img3)
cv2.waitKey(0)
注意
- 图像大小一定要相同
- 两个参数都是1的时候就等效于图像相加,直接叠加

按位操作(与或非)
import cv2
img1 = cv2.imread('../Resources/lena.png')
img2 = cv2.imread('../Resources/logo.png')
rows, cols = img2.shape[:2]
roi = img1[:rows, :cols]
img2gray = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
ret, mask = cv2.threshold(img2gray, 10, 255, cv2.THRESH_BINARY)
mask_inv = cv2.bitwise_not(mask)
# 保留除logo外的背景
img1_bg = cv2.bitwise_and(roi, roi, mask=mask_inv)
dst = cv2.add(img1_bg, img2) # 进行融合
img1[:rows, :cols] = dst # 融合后放在原图上
cv2.imshow('img',img1),cv2.imshow('mask',mask_inv) #看看扣完的是啥图
cv2.waitKey(0)
类似抠图,就是把不符合的去掉

9、图像平滑
用于模糊/平滑图像,消除噪点
这里我没太懂,大概就是用卷积的办法,然后卷积啥意思可以看下这篇文章:
https://cloud.tencent.com/developer/article/1913657
这里简单记录下我的理解,详细的还是看原博客
- 下面这个就是卷积了,可以看到就是把像素点这样依次叠加得到另一张图,计算公式在图的右上角,5怎么来的就是那个公式了。
- 然后他这个是移位计算,不是按照3个平分,这样保证不管图像是咋样的都可以卷完

然后滤波就是用了这么个卷积的方式,然后下面列一下常见的滤波方式
均值滤波
import cv2
img = cv2.imread('../Resources/lena.png')
blur = cv2.blur(img, (3, 3)) # 均值模糊
cv2.imshow('img_orgin',img)
cv2.imshow('img',blur)
cv2.waitKey(0)
看的有点模糊了,一点点不太明显

之后我又在网上看到可以生成噪声图片,感谢这位博主提供生成两种噪声的代码 https://blog.csdn.net/qq_45832961/article/details/122309422
def sp_noise(image, prob):
"""
添加椒盐噪声
prob:噪声比例
"""
output = np.zeros(image.shape,np.uint8)
thres = 1 - prob
for i in range(image.shape[0]):
for j in range(image.shape[1]):
rdn = random.random()
if rdn < prob:
output[i][j] = 0
elif rdn > thres:
output[i][j] = 255
else:
output[i][j] = image[i][j]
return output
def gasuss_noise(image, mean=0, var=0.001):
"""
添加高斯噪声
mean : 均值
var : 方差
"""
image = np.array(image/255, dtype=float)
noise = np.random.normal(mean, var ** 0.5, image.shape)
out = image + noise
if out.min() < 0:
low_clip = -1.
else:
low_clip = 0.
out = np.clip(out, low_clip, 1.0)
out = np.uint8(out*255)
return out
import numpy as np
import cv2
import random
src = cv2.imread('../Resources/lena.png')
img = src.copy()
img_sp = sp_noise(img, prob=0.02) #设置噪声比为0.02
# 均值滤波
blur = cv2.blur(img_sp, (3, 3))
cv2.imshow("sp", img_sp)
cv2.imshow("blur", blur)
cv2.waitKey(0)
这次效果比较明显了

还有方框滤波,高斯滤波,中值滤波,双边滤波这几种,就直接在上面代码添加吧
def sp_noise(image, prob):
"""
添加椒盐噪声
prob:噪声比例
"""
output = np.zeros(image.shape,np.uint8)
thres = 1 - prob
for i in range(image.shape[0]):
for j in range(image.shape[1]):
rdn = random.random()
if rdn < prob:
output[i][j] = 0
elif rdn > thres:
output[i][j] = 255
else:
output[i][j] = image[i][j]
return output
def gasuss_noise(image, mean=0, var=0.001):
"""
添加高斯噪声
mean : 均值
var : 方差
"""
image = np.array(image/255, dtype=float)
noise = np.random.normal(mean, var ** 0.5, image.shape)
out = image + noise
if out.min() < 0:
low_clip = -1.
else:
low_clip = 0.
out = np.clip(out, low_clip, 1.0)
out = np.uint8(out*255)
return out
import numpy as np
import cv2
import random
src = cv2.imread('../Resources/lena.png')
img = src.copy()
img_sp = sp_noise(img, prob=0.02) #设置噪声比为0.02
# 均值滤波
blur = cv2.blur(img_sp, (3, 3))
# 方框滤波 normalize=True时候等效均值滤波,为false的时候,相当于求每个卷积区域像素和
blur1 = cv2.boxFilter(img_sp, -1, (3, 3), normalize=False)
# 高斯滤波,高斯滤波卷积核中间权重大,有点像正态分布曲线
gaussian = cv2.GaussianBlur(img, (5, 5), 1)
# 中值滤波,所有数排序之后取中位数的值
median = cv2.medianBlur(img, 5)
# 双边滤波,相比其他滤波优化了对边缘的处理
blur2 = cv2.bilateralFilter(img, 9, 75, 75)
cv2.imshow("sp", img_sp)
cv2.imshow("blur", blur)
cv2.imshow("blur1", blur1)
cv2.imshow("gaussian", gaussian)
cv2.imshow("median", median)
cv2.imshow("blur2", blur2)
cv2.waitKey(0)
效果如下:
10、边缘检测
canny算子
import cv2
import numpy as np
img = cv2.imread('../Resources/num2.jpg', 0)
edges = cv2.Canny(img, 30, 70) 阈值区间
cv2.imshow('canny', np.hstack((img, edges))) # 叠加图像的另一种方式
cv2.waitKey(0)

但是当图像轮廓不清晰的时候效果不好,提升效果可以看我的另一篇文章,采用 cv.findContours() 对二值图像寻找轮廓,函数 cv2.drawContours() 绘制轮廓。
链接如下:https://blog.csdn.net/m0_51220742/article/details/122610764?spm=1001.2014.3001.5501

看下效果:

可以看出效果得到了一定提升。
使用阈值来修改参数
根据上面的canny算子可以知道,canny算子比较依赖这个区间,所以可以用opencv的滑块来调节这个滑块,代码如下:
import cv2
img=cv2.imread('../Resources/lena.png')
cv2.namedWindow('Canny_set')
# 滑动条的回调函数
def nothing(x):
pass
cv2.createTrackbar('threshold1','Canny_set',100,300,nothing)
cv2.createTrackbar('threshold2','Canny_set',100,300,nothing)
while(1):
threshold1=cv2.getTrackbarPos('threshold1','Canny_set') #滑动条返回值
threshold2=cv2.getTrackbarPos('threshold2','Canny_set')
img_edges=cv2.Canny(img,threshold1,threshold2)
cv2.imshow('original',img)
cv2.imshow('Canny_set',img_edges)
if cv2.waitKey(1)==ord('q'):
break
cv2.destroyAllWindows()
效果如下:

11、腐蚀与膨胀
这个在我之前的答题记录记录过了较详细的操作,详情可见opencv技能树答题记录
先理解下,这是后面的基础,知道这个也好理解和记忆后面的内容
- 腐蚀就是变瘦
- 膨胀就是变胖
- 开运算就是先腐蚀再膨胀
- 闭运算就是先膨胀再腐蚀
import cv2
import numpy as np
img = cv2.imread('../Resources/j.bmp')
kernel = np.ones((5, 5), np.uint8)
kernel1 = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
erosion = cv2.erode(img, kernel) # 腐蚀
dilation = cv2.dilate(img, kernel) # 膨胀
opening = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel1) # 开运算
closing = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel1) # 闭运算
img_concat = np.concatenate(
(img,erosion, dilation,opening,closing),
axis=1
)
cv2.imwrite("bug_band.jpg", img_concat)
cv2.imshow('connect',img_concat)
cv2.waitKey(0)
cv2.destroyAllWindows()
效果如下

结合上图可以很好的明白这四个操作的用处,可以看出开闭运算好像对图像没有什么影响
现在我们换一张图,原图中内部有很多咋点,可以看出闭运算把内部杂点消除了,但是开运算却把杂点放大了

再换一张图原图中外部有很多咋点,可以看出开运算把外部杂点消除了,但是必运算却把杂点放大了

上面的原因从步骤来考虑很快就能明白,这里不做赘述,代码如下:
import cv2
import numpy as np
img = cv2.imread('../Resources/j_noise_out.bmp')
kernel = np.ones((5, 5), np.uint8)
kernel1 = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
opening = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel1) # 开运算
closing = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel1) # 闭运算
img_concat = np.concatenate(
(img, opening,closing),
axis=1
)
cv2.imwrite("bug_band.jpg", img_concat)
cv2.imshow('connect',img_concat)
cv2.waitKey(0)
cv2.destroyAllWindows()
12、轮廓特征
轮廓的函数上面已经记录过了,主要是cv2.findContours这个函数在理解下:
cv2.findContours(image, mode, method, contours=None, hierarchy=None, offset=None)
- img: 必须是二值图片
- mode:轮廓检索模式
cv2.findContours 只检测外轮廓
cv2.RETR_LIST 检测到的轮廓没有等级关系
cv2.RETR_CCOMP 建立两个等级的轮廓,上面的一层为外边界,里面的一层为内孔的边界信息
cv2.RETR_TREE 建立一个等级树结构的轮廓 - method 轮廓的近似办法,常用的:
cv2.CHAIN_APPROX_NONE 存储所有的轮廓点,相邻的两个点的像素位置差不超过1
cv2.CHAIN_APPROX_SIMPLE 压缩水平方向,垂直方向,对角线方向的元素,只保留该方向的终点坐标
返回值信息:
- contours 就是有几个轮廓
- hierarchy 就是每个轮廓每级轮廓的索引,就是每个轮廓好几级然后这个就是对应的所以,注意是二重索引,先是轮廓号,后面才是对应下的索引号
下面主要记录下轮廓的特征 (面积、周长、最小外接矩形)
import cv2
import numpy as np
img = cv2.imread('../Resources/num3.jpg', 0)
_, thresh = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
contours, hierarchy = cv2.findContours(thresh, 3, 2)
cnt =contours[0]
img_color1 = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
img_color2 = np.copy(img_color1)
cv2.drawContours(img_color1, [cnt], 0, (0, 0, 255), 2)
cv2.imshow('canny', np.hstack((img_color1, img_color2)))
cv2.waitKey(0)
找到外接轮廓

-
周长:
cv2.arcLength(cnt,True) true表示闭合 -
面积
cv2.contourArea(cnt) -
图形矩
cv2.moments(cnt)
import cv2
import numpy as np
img = cv2.imread('../Resources/num3.jpg', 0)
_, thresh = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
contours, hierarchy = cv2.findContours(thresh, 3, 2)
cnt =contours[0]
img_color1 = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
img_color2 = np.copy(img_color1)
cv2.drawContours(img_color1, [cnt], 0, (0, 0, 255), 2)
cv2.imshow('canny', np.hstack((img_color1, img_color2)))
print('周长:',cv2.arcLength(cnt,True),'面积',cv2.contourArea(cnt),'图像矩',cv2.moments(cnt))
cv2.waitKey(0)
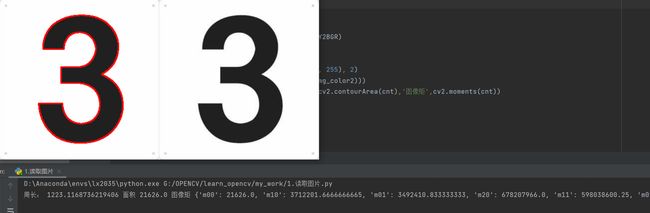
这里关注下这个图形矩
官网api来源:https://docs.opencv.org/4.0.0/db/dfc/modules_2core_2include_2opencv2_2core_2types_8hpp.html
如下所示:

下面只说几个比较重要的用法:
-
m00 就是面积
-
质心(平面图形,质心就是形心):cx,cy = M[‘m10’] / M[‘m00’], M[‘m01’] / M[‘m00’]
-
外接矩形
cv2.boundingRect(cnt)
cv2.minAreaRect(cnt) 最小外接矩形 -
最小外接圆
cv2.minEnclosingCircle(cnt) -
拟合椭圆
cv2.fitEllipse(cnt)
import cv2
import numpy as np
img = cv2.imread('../Resources/num3.jpg', 0)
_, thresh = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
contours, hierarchy = cv2.findContours(thresh, 3, 2)
cnt =contours[0]
img_color1 = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
img_color2 = np.copy(img_color1)
# 外接矩形
x, y, w, h = cv2.boundingRect(cnt)
cv2.rectangle(img_color2, (x, y), (x + w, y + h), (255, 0, 0), 2)
#最小外接矩形
rect = cv2.minAreaRect(cnt)
box = np.int0(cv2.boxPoints(rect)) # 取整函数
cv2.drawContours(img_color2, [box], 0, (0, 255, 0), 2)
# 最小外接圆
(x, y), radius = cv2.minEnclosingCircle(cnt)
(x, y, radius) = np.int0((x, y, radius)) # 取整函数
cv2.circle(img_color2, (x, y), radius, (0, 0, 255), 2)
#拟合椭圆
ellipse = cv2.fitEllipse(cnt)
cv2.ellipse(img_color2, ellipse, (0, 255, 255), 2)
cv2.imshow('canny', np.hstack((img_color1, img_color2)))
cv2.waitKey(0)
效果如下:

- 形状匹配
cv2.matchShapes(),用于检测两个形状之间的相似度。根据返回值来判定,返回值越小,越相似。
import cv2
img = cv2.imread('../Resources/2.jpg', 0)
_, thresh = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
contours, hierarchy = cv2.findContours(thresh, 2, 2)
cnt_a, cnt_b = contours[0], contours[1]
print(cv2.matchShapes(cnt_a, cnt_b, 1, 0.0)) # 打印出两个轮廓的相似度