学习opencv-python笔记
因为学校内一个项目设计的实验课,需要我们用opencv去做一些图像处理,以前一直没有做过类似的东西,对于编程也并不是很熟悉,从小白开始学起,写这篇文章的想法是去整合自己学习过程中找到的一些资料,以及自己在调试中遇到的一些小问题,希望可以帮到那些和我一样同样从头开始学习的uu们。废话很多,当然可能也会有一些不是很准确的说法,望各位指正交流!
学习资料
我是在GitHub上找到的一个讲opencv-python的博主的文章,里面讲的很基础很详细,但是对于小白来说效果着实不错,大佬们就不用浪费时间在我这里啦,这里送上链接:http://codec.wang/#/opencv/http://codec.wang/#/opencv/ http://codec.wang/#/opencv/
http://codec.wang/#/opencv/
但是实际上更全面更权威的是opencv的官方文档,有能力的话查阅官方文档能更好的理解学习,如果是第一次看全英文的说明文件可能会比较恶心,但是实际上大部分人都必须经历这么一段时间来适应, 读原文才能更好的悟原理,经过一段时间的磨练,看英文文档就会变得很轻松,毕竟你所涉及到的领域的专业词汇也就只有那么多,所以有时间不妨去看看原文,你和大师之间的差距可能就是你不敢去挑战自己,附上opencv的英文说明文档:
https://docs.opencv.org/4.0.0/modules.htmlhttps://docs.opencv.org/4.0.0/modules.html
问题一:cv2.VideoCapture()无法打开视频文件,cv2.imread()无法打开照片文件
在确保安装了opencv-python的库、程序中正确import cv2以后,照着例程尝试去打开文件,但是cv2.imread()并不能如愿打开照片:代码如下:
img = cv2.imread('C:\Users\mi\Desktop\xjpic')
while(True):
cv2.imshow('picture', img)
if cv2.waitKey(1) == ord('q'):
break但是运行后发现报错:SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated \UXXXXXXXX escape
查询后发现:在文件夹中复制地址时,地址用 \ 来分隔不同文件夹,但是python识别地址认的是 / 分割的地址
因此只需要将地址中的 \ 全部改为 / 就可以了,当然这是最直接最简单的方法,还有其它的使用转义等方法解决,把链接给大家送上:
https://blog.csdn.net/qq_45797116/article/details/110423429https://blog.csdn.net/qq_45797116/article/details/110423429https://blog.csdn.net/qq_45797116/article/details/110423429
But改掉之后换了个报错:'NoneType' object is not subscriptable
这个是因为虽然我的照片命名并没有带后缀,但是在给程序的时候是需要后缀的,要不然它识别不了到底是要打开哪个文件,我的这张照片是 jfif 类型的文件,因此最后代码改为下面这样就可以了:
img = cv2.imread('C:/Users/mi/Desktop/xjpic.jfif')这下运行再也不会报错了!!!
同样的,cv2.VideoCapture()无法打开视频文件也先去看看文件路径是不是符合上面说的,可千万不能在这种小地方浪费太多时间,伟大的祖国还等着我们去建设呢。如果还是无法解决,可能是缺少ffmpeg的支持,本菜狗幸运的并没有遇到这个问题,但是还是给各位客官献上链接:
https://blog.csdn.net/u014114109/article/details/83070757https://blog.csdn.net/u014114109/article/details/83070757https://blog.csdn.net/u014114109/article/details/83070757https://blog.csdn.net/chenshida_/article/details/115151441?spm=1001.2101.3001.6650.5&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Edefault-5.no_search_link&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Edefault-5.no_search_linkhttps://blog.csdn.net/chenshida_/article/details/115151441?spm=1001.2101.3001.6650.5&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Edefault-5.no_search_link&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Edefault-5.no_search_linkhttps://blog.csdn.net/chenshida_/article/details/115151441?spm=1001.2101.3001.6650.5&utm_medium=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromBaidu~default-5.no_search_link&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromBaidu~default-5.no_search_link
问题二:阈值分割不会用?
阈值分割主要的方法有固定阈值、自适应阈值和Otsu阈值法,针对的都是灰度图像,其中最简单粗暴的就是固定阈值分割了,大于设定值是一个取值方法,小于设定又是一个取值方法,根据这个取值方法的不同又分为五种,具体见下:cv::ThresholdTypeshttps://docs.opencv.org/4.0.0/d7/d1b/group__imgproc__misc.html#gaa9e58d2860d4afa658ef70a9b1115576
但是这种固定的阈值在很多情况下效果并不好,尤其是对于明暗分布混乱的图片,这个时候自适应阈值【cv2.adaptiveThreshold()】就显得智能多了,它可以根据小区域内的像素点灰度值自动调整阈值大小,阈值的计算方法可以是均值或高斯卷积,同时阈值的取值方法还是有上述的五种。该方法需要五个参数,分别对应原图、最大阈值(一般是255)、阈值计算方法(均值或高斯)、小区域的面积、修正值,修正值作用是:最终阈值等于小区域计算出的阈值再减去此值,经过测试,这个修正值越大,图片的轮廓就会越明显,可以把图片一步做成简笔画。给大家看下代码和效果:
img = cv2.imread('C:/Users/mi/Desktop/test.jfif', 0)
# 固定阈值
ret, pic1 = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)
# 自适应阈值
pic2 = cv2.adaptiveThreshold(
img, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 20)
pic3 = cv2.adaptiveThreshold(
img, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 17, 20)
titles = ['Original', 'fix thre(v = 127)', 'Adaptive Mean thre', 'Adaptive Gaussian thre']
images = [img, pic1, pic2, pic3]
for i in range(4):
plt.subplot(2, 2, i + 1), plt.imshow(images[i], 'gray')
plt.title(titles[i], fontsize=8)
plt.xticks([]), plt.yticks([])
plt.show()
这个是修正值为20,我把它改为4的时候效果如下:
问题三:cv2的图像几何变换都有哪些,具体怎么用?
cv2可以实现图片的缩放、翻转、平移、旋转等等。
- 缩放:
cv2.resize(InputArray src, OutputArray dst, Size, fx, fy, interpolation)参数对应的分别是输入图片、输出图片、输出图片的大小、坐标轴的缩放比例,以及插入方式。可以直接指定Size的大小进行缩放,也可以指定横纵轴的缩放比例。插入方式有:
附上官方文档:INTER_NEAREST 最近邻插值 INTER_LINEAR 双线插值 INTER_CUBIC 双三次插值 INTER_AREA 使用像素区域关系进行重采样 INTER_LANCZOS4 8x8像素邻域的Lanczos插值 INTER_LINEAR_EXACT 位精确双线性插值 INTER_MAX 插补码掩码 WARP_FILL_OUTLIERS 填充满放大后的目标图像,如果目标图像中对应原图的像素已经溢出,则将其置0 WARP_INVERSE_MAP 反变换
http:// enum cv::InterpolationFlagshttp:// enum cv::InterpolationFlags
附上代码各位直接去调试参数看看效果:
img = cv2.imread('C:/Users/mi/Desktop/test.png', 0)
img1 = cv2.resize(img, (200, 350))
img2 = cv2.resize(img, None, fx=2, fy=2, interpolation=cv2.INTER_NEAREST)
img3 = cv2.resize(img, None, fx=2, fy=2, interpolation=cv2.INTER_LINEAR)
img4 = cv2.resize(img, None, fx=2, fy=2, interpolation=cv2.INTER_CUBIC)
img5 = cv2.resize(img, None, fx=2, fy=2, interpolation=cv2.INTER_AREA)
img6 = cv2.resize(img, None, fx=2, fy=2, interpolation=cv2.INTER_LANCZOS4)
img7 = cv2.resize(img, None, fx=2, fy=2, interpolation=cv2.INTER_LINEAR_EXACT)
images = [img, img1, img2, img3, img4, img5, img6, img7]
titles = ['original', 'INTER_NEAREST', 'INTER_LINEAR', 'INTER_CUBIC', 'INTER_AREA', 'INTER_LANCZOS4',
'INTER_LINEAR_EXACT']
for i in range(7):
plt.subplot(3, 3, i + 1), plt.imshow(images[i], 'gray')
plt.title(titles[i], fontsize=8)
plt.xticks([]), plt.yticks([])
plt.show()效果图如下,事实上区别并不是很明显,一般情况下插入方式使用默认值就可以了
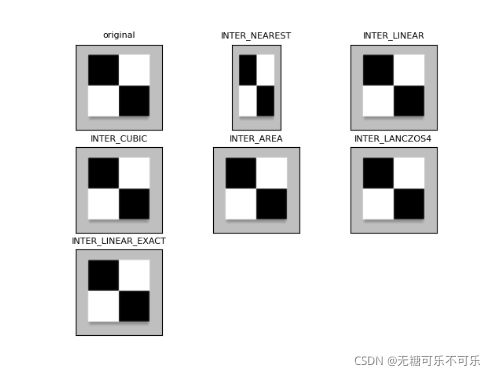
2.翻转:cv2.flip(scr,flipCode[,dst]):
第一个参数是输入图片,第二个参数是是翻转方向:
| flipCode | 翻转方向 |
| >0 | 水平翻转 |
| 0 | 垂直翻转 |
| <0 | 水平垂直翻转 |
演示代码如下:
img = cv2.imread('C:/Users/mi/Desktop/test.jfif')
img1 = cv2.flip(img, 1)
img2 = cv2.flip(img, 0)
img3 = cv2.flip(img, -1)
images = [img, img1, img2, img3]
titles = ['original', 'axis_x', 'axis_y', 'axis_xy']
for i in range(4):
plt.subplot(2, 2, i + 1), plt.imshow(images[i], 'gray')
plt.title(titles[i], fontsize=8)
plt.xticks([]), plt.yticks([])
plt.show()效果如下:

3.平移图片:cv2.warpAffine(),官方给出的参数如下:
| warpAffine | ( | InputArray | src, |
| OutputArray | dst, | ||
| InputArray | M, | ||
| Size | dsize, | ||
| int | flags = INTER_LINEAR, |
||
| int | borderMode = BORDER_CONSTANT, |
||
| const Scalar & | borderValue = Scalar() |
||
| ) |
Parameters
| src | input image. |
| dst | output image that has the size dsize and the same type as src . |
| M | 2×3 transformation matrix. |
| dsize | size of the output image. |
| flags | combination of interpolation methods (see InterpolationFlags) and the optional flag WARP_INVERSE_MAP that means that M is the inverse transformation ( dst→src ). |
| borderMode | pixel extrapolation method (see BorderTypes); when borderMode=BORDER_TRANSPARENT, it means that the pixels in the destination image corresponding to the "outliers" in the source image are not modified by the function. |
| borderValue | value used in case of a constant border; by default, it is 0. |
全英文看起来可能不太好理解,但是其实很简单,这个方法实际上主要用的就三个参数,一个是输入图片scr,一个是变换矩阵M(2x3),矩阵的格式一般是固定的,就是[[1,0,dx],[0,1,dy]],dx、dy分别代表平移的距离,矩阵可以用numpy的方法生成,dsize是输出的图片大小,如果太小的话可能照片有一部分会移到“框架”之外不显示。至于这个变换是怎么做到的,事实上也很简单,就是普通的仿射变换,说的再通俗点,就是原本的横纵坐标直接加上偏移量,公式如下:dst(x,y)=src(M11x+M12y+M13,M21x+M22y+M23),看起来很复杂,但是我们的M11=1M22, M12=M21=0,因此实际上dst(x,y)=src(x+M13,y+M23)。当然改变M的值,甚至可以做到伸缩变换,这个时候就需要flags(插入方式)参数,具体见上面的伸缩变换。
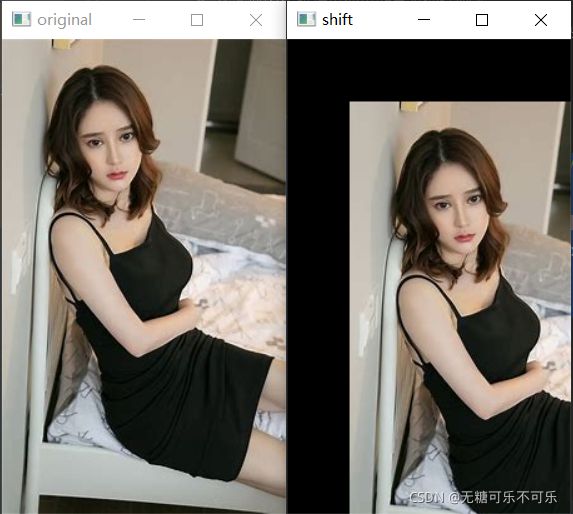
给大家展示下代码,我的dsize设置的是原图片的大小,因此平移后一定有一部分超出屏幕之外了:
img = cv2.imread('C:/Users/mi/Desktop/test.jfif')
rows, cols = img.shape[:2]
M = np.float32([[1, 0, 50], [0, 1, 50]])
dst = cv2.warpAffine(img, M, (cols, rows))
cv2.imshow('original', img)
cv2.imshow('shift', dst)
cv2.waitKey(0)效果图:
4.旋转cv2.getRotationMatrix2D(center,angle,scale),官方给出的参数有三个:
| Point2f | center |
| double | angle |
| double | scale |
center就是旋转中心,angle是旋转的角度,顺时针旋转为正,逆时针为负,scale是缩放比例,它的数学原理也并不难,实际上这个函数计算的是下面这个矩阵:
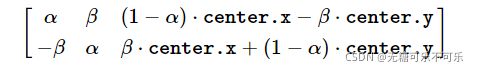
其中:α=scale⋅cosangle,β=scale⋅sinangle。
得到该矩阵后,再进行仿射变换cv2.warpAffine()。代码如下,大家可以自己调试参数看效果:
img = cv2.imread('C:/Users/mi/Desktop/test.jfif')
rows, cols = img.shape[:2]
M = cv2.getRotationMatrix2D((cols / 2, rows / 2), 30, 0.5)
dst = cv2.warpAffine(img, M, (cols, rows))
cv2.imshow('rotation', dst)
cv2.imshow('original', img)
cv2.waitKey(0)