trdimp代码配置(pytracking,ubuntu18.04 + cuda11.3)
trdimp代码在这里:594422814/TransformerTrack (github.com)
由于其使用了trdimp框架,所以需要先配置pytracking框架,给出简要配置方案
另附上pytracking的 github链接,里面其实有比较详细的安装教程了,网上也有一些配置教程
GitHub - visionml/pytracking: Visual tracking library based on PyTorch.
1. Create and activate a conda environment
conda create --name pytracking python=3.7 conda activate pytracking
2. Install PyTorch(30系卡不支持cuda10,所以用cuda11,可以用cuda10尽量和作者保持一致)
(注意,使用pip安装下面有几率会遇到坑,建议使用conda安装)
cuda11.2和11.1在编译roipooling时有compute_86问题,实测11.3可以用
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch
3. 安装一大堆包
conda install matplotlib pandas tqdm pip install opencv-python visdom tb-nightly scikit-image tikzplotlib gdown
Install the coco and lvis toolkits
conda install cython pip install pycocotools pip install lvis
Install ninja-build for Precise ROI pooling
To compile the Precise ROI pooling module (https://github.com/vacancy/PreciseRoIPooling), you may additionally have to install ninja-build.(这个external的编译对cuda11极其不友好,实测cuda11.和cuda11.1无法编译,11.3可以)
sudo apt-get install ninja-build
pip install spatial-correlation-sampler
sudo apt-get install libturbojpeg pip install jpeg4py
4.补全链接库
直接使用git的命令会缺失一些文件
git submodule update --init如果报错,就需要挂梯子,或者手动下载,再加入目录里面
主要是这里的文件
有问题找 https://github.com/ClementPinard/Pytorch-Correlation-extension
正常编译后,运行eval和train都会出现

5. 配置环境,下载数据集并放到对应位置
预训练模型 github下载链接:https://github.com/594422814/TransformerTrack/releases/download/model/trdimp_net.pth.tar
考虑到梯子问题,建议自己下好,放到对应目录即可(对应位置同样可以查看local.py文件)
trdimp的源码自带两个local文件,不需要pytracking教程的生成过程

在生成的local文件编辑数据集路径和模型路径,这点还是挺人性化的(train和eval的数据集路径不同)

6. 运行测试代码
先开第一个终端,运行 python -m visdom.server
(如果是服务器需要转到本机可视化,可以使用xshell的隧道)
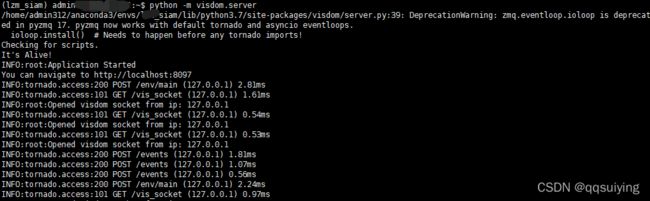
另开一个终端,同样的conda环境
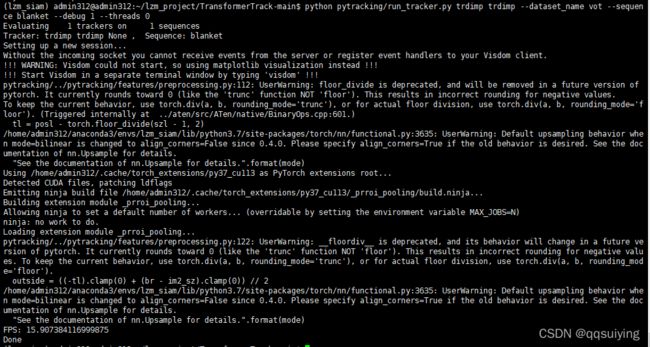
python pytracking/run_tracker.py trdimp trdimp --dataset_name vot --sequence blanket --debug 1 --threads 0
python pytracking/run_tracker.py --tracker_name trdimp --tracker_param trdimp --dataset_name vot --sequence blanket
会有错误和warnings,解决方案我放在文末,warning影响不大可以不管,也是版本问题hhh
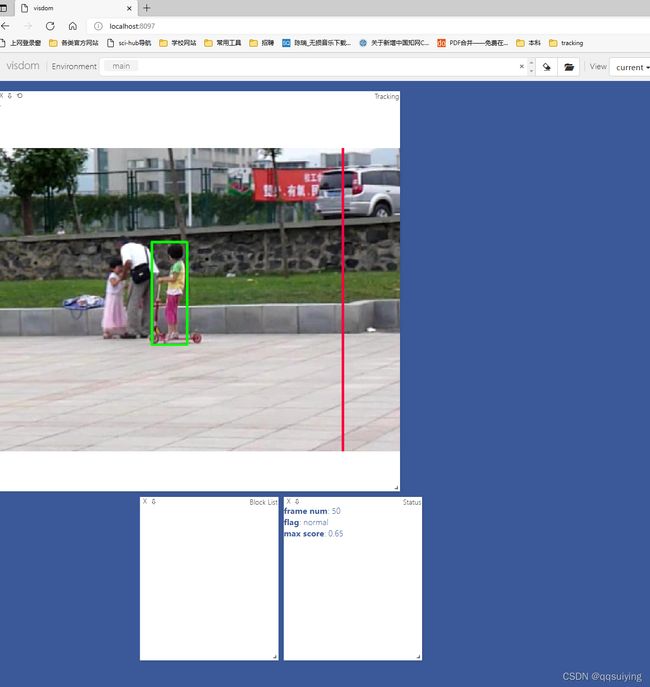
可视化结果:
7.模型训练及效果复现


训练时长和作者在github回复相符(作者讲4张1080ti训练50个epoch,30小时,我使用两张3060跑一个epoch大约65分钟,跑50个就得两天多了)batch还可以大一点,两天左右一次迭代算勉强可以接受吧
打游戏3060不如1080ti,不过拿来跑训练似乎还行

另外感慨下跑tracking也蛮吃cpu的,xeon4114虽然20核但2.5的主频实在是有点拉胯了,跑测试的时候cpu瓶颈很明显,原作者的测试帧数github上很多人也达不到,猜测作者应该是用了个比较猛的cpu
出现的错误及解决方案:
1.
raise Exception('Could not read file {}'.format(path))
Exception: Could not read file /data3/publicData/Datasets/OTB/OTB2015/BlurCar1/groundtruth_rect.txt
错误原因:
groundtruth_rect.txt格式与读取格式不对应
解决办法:
打开pytracking/utils/load_text.py更改函数:
def load_text_numpy(path, delimiter, dtype)
为如下:
def load_text_numpy(path, delimiter, dtype):
if isinstance(delimiter, (tuple, list)):
for d in delimiter:
try:
# ground_truth_rect = np.loadtxt(path, delimiter=d, dtype=dtype)
# to deal with different delimeters
import io
with open(path,'r') as f:
ground_truth_rect=np.loadtxt(io.StringIO(f.read().replace(',',' ')))
return ground_truth_rect
except:
pass
raise Exception('Could not read file {}'.format(path))
else:
ground_truth_rect = np.loadtxt(path, delimiter=delimiter, dtype=dtype)
return ground_truth_rect2. 警告 floor_divide
module 'torch' has no attribute 'floor_divide'
3.使用otb数据集报错
Exception: Could not read file /home/tracking/OTB2015/Human4/groundtruth_rect.txt
查看文件,human4里面确实很奇怪,不知道是不是我下载的数据集有问题

暂时换用otb了
4.使用otb数据集,默认路径有问题
有些人的配置里,所有图片是放在一个大文件夹color中的
我下的这个不是,在整个工程中全局查找,删掉路径中color就好
参考链接
pytracking系列跟踪算法的配置(LWL, KYS, PrDiMP, DiMP and ATOM Trackers)(Ubuntu版本)_博博有个大大大的Dream-CSDN博客_pytracking训练
(5条消息) [Object Tracking][环境配置流程][Ubuntu16.04]ATOM【CVPR2019】pytracking_llzxz9628的博客-CSDN博客
Ubuntu之cuda11.4安装_月生的静心苑-CSDN博客