前言
最近有个新项目,需要实现类似工作流引擎的效果,如果不知道是啥,看完本文就懂了。
公司内其实也有些自研的,可能就是不像开源的这些那样,还支持这个那个规范,都是基于需求定制开发的,扩展性稍微差点。
所以,这次其实几个同事,分工调研了几个开源的和公司内的,开源的包括activiti、flowable、camunda,我这边主要调研了flowable、camunda,同事调研了activiti和公司内部的。
最终看下来,我们的需求,其实不需要用到这么复杂的开源框架,公司内的一个框架更符合一些。开源的框架,会建很多表,表也不符合公司内的建表规范,所以还需要阅读源码,去改造之类的,也比较麻烦。会引入很多jar包,总体来说,还是比较重。
文末有几个引擎的对比,大家有兴趣可以看看,也可以加我微信和我探讨(只花了两天时间,可能也了解得也比较粗略)。
最终来说,技术还是服务于需求的,不是因为框架牛逼就硬上,合适最重要。
先说说uml和omg
学过软件工程的同学,肯定知道uml,全称Unified Modeling Language,统一建模语言。建模,为啥要建模,因为软件研发过程较为抽象,一个需求来了,肯定要先分析分析,建个模(通俗就是:画个图),但是每个人画出来的图都不一样,比如uml里用一个小人来表示用户,有的人就不愿意用小人。所以,为了业界内人士沟通交流更方便,就定义了一套标准,每种图应该怎么画,包含了哪些部分。
比如uml包含了如下类型的图,每种图里,都有固定的图例来代表固定的意思(仅部分):
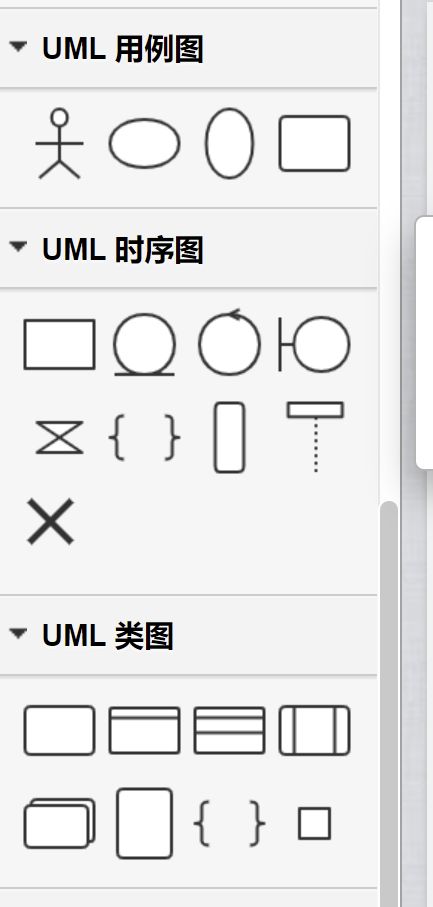
ok,大家明白了uml,我再说说omg是啥,omg是个标准化组织,致力于提出uml这样类似的标准,和业界的公司进行讨论交流,各公司的人、学术界的人、omg的人,共同讨论,提出一个大家都能接受的方案,然后大家就按照这个标准来进行实现。
世界上的标准化机构很多,omg手里拿出来的,现在广为使用的,被iso采纳的,有如下几个。

主要就是uml和bpmn,注意,没有xml(图里右上角那个是xmi)。
bpmn
图形规范
bpmn(Business Process Model And Notation)是啥,也是一种建模语言,和uml类似,就是规定:xxx,用这个来表示,yyy,用那个来表示。
bpmn主要是对工作流进行建模,大家公司里的oa系统,基本就是工作流的典范,比如下面这样一个用户请假流程,就是遵循bpmn规范的。

这个图里,哪些地方用空心圆,哪些地方是矩形,哪些地方用菱形,都是有讲究,这就是bpmn规范里定义的。

xml规范
bpmn对图形有规范,对图形背后的存储格式也有定义,这个图,最终会转化为一份xml,这份xml也是遵循特定的schema的。
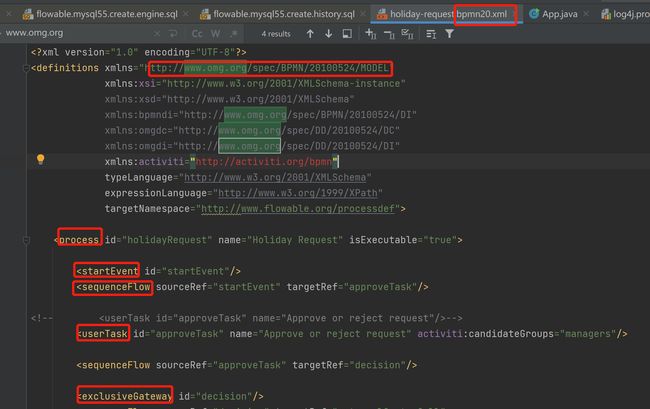
上图这个xml,就是遵循omg官方的schema,里面最外层是一个process元素,里面的元素则只能是startEvent、sequenceFlow等。
这样标准化了之后,业界各个厂商,就可以各自开发一套实现,只要这套实现,最终能生成上面这样的xml,那就是符合bpmn的,拿这份bpmn文件到其他厂商那里,其他厂商的程序也能正确解析该文件,因此就实现了互联互通,这就是标准的力量。
bpmn版本历史
主要是4个版本,现在业界基本都是基于2010年的最新版本2.0进行实现,也就是bpmn2.0
| VERSION | ADOPTION DATE | URL |
|---|---|---|
| 2.0 | 十二月 2010 | https://www.omg.org/spec/BPMN/2.0/ |
| 1.2 | 一月 2009 | https://www.omg.org/spec/BPMN/1.2/ |
| 1.1 | 一月 2008 | https://www.omg.org/spec/BPMN/1.1/ |
| 1.0 | 三月 2007 | https://www.omg.org/spec/BPMN/1.0/ |
bpmn 2.0的业界实现
实现还是挺多的,近10多个。现在大家比较用得多的,还是红框的几个,Activiti、Camunda、Flowable、jBPM。

这些实现,互相有些关系,就像log4j的维护人后来又创建了logback一样。

目前主要就是在 Camunda/flowable 6/ activiti里面去选择。
flowable 内嵌模式快速了解
创建maven工程(文末有代码)
如果一上来,直接就开始比较各框架的差异,大家由于对其中任意一个都不了解,所以也没法参照。这里先讲一下flowable框架(目前最先了解这个框架)。
flowable 引擎,支持两种运行模式,一种是内嵌到业务服务中,咱们先讲这种。
先建一个普通的maven工程,加入flowable引擎的依赖以及h2内嵌数据库的依赖(正式项目会换成mysql等持久化数据库)
org.flowable
flowable-engine
6.7.2
com.h2database
h2
1.4.192
创建流程引擎实例
以下,先创建一个引擎实例出来:
import org.flowable.engine.ProcessEngine;
import org.flowable.engine.ProcessEngineConfiguration;
import org.flowable.engine.impl.cfg.StandaloneProcessEngineConfiguration;
public class HolidayRequest {
public static void main(String[] args) {
ProcessEngineConfiguration cfg = new StandaloneProcessEngineConfiguration()
.setJdbcUrl("jdbc:h2:mem:flowable;DB_CLOSE_DELAY=-1")
.setJdbcUsername("sa")
.setJdbcPassword("")
.setJdbcDriver("org.h2.Driver")
.setDatabaseSchemaUpdate(ProcessEngineConfiguration.DB_SCHEMA_UPDATE_TRUE);
ProcessEngine processEngine = cfg.buildProcessEngine();
}
}
接下来,我们就可以往这个引擎实例上部署一个流程xml。比如,假设我们最终想建立一个员工请假流程,那么,我们可以通过各种办法(如flowable自带的web-ui拖拽的方式或手动创建xml等),来建立一个下面这样的,符合bpmn2.0规范的流程定义xml(holiday-request.bpmn20.xml)。
这个xml是不是比较抽象?这个xml就类似于一种标准格式,就像java的class文件一样,实现跨平台的效果。
该xml对应的流程图如下:
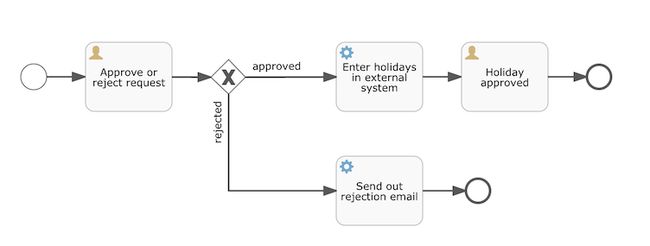
接下来,我们就把这个文件,传给流程引擎,让它基于该文件,创建一个工作流。
RepositoryService repositoryService = processEngine.getRepositoryService();
Deployment deployment = repositoryService.createDeployment()
.addClasspathResource("holiday-request.bpmn20.xml")
.deploy();
创建后,实际就写到内存数据库h2了,此时,我们还可以把它查出来
ProcessDefinition processDefinition = repositoryService.createProcessDefinitionQuery()
.deploymentId(deployment.getId())
.singleResult();
System.out.println("Found process definition : " + processDefinition.getName());
创建工作流实例
工作流实例,一开始需要一些输入参数,员工不是需要请假吗,我们就需要:员工姓名、请假天数、事由等。
Scanner scanner= new Scanner(System.in);
System.out.println("Who are you?");
String employee = scanner.nextLine();
System.out.println("How many holidays do you want to request?");
Integer nrOfHolidays = Integer.valueOf(scanner.nextLine());
System.out.println("Why do you need them?");
String description = scanner.nextLine();
RuntimeService runtimeService = processEngine.getRuntimeService();
Map variables = new HashMap();
variables.put("employee", employee);
variables.put("nrOfHolidays", nrOfHolidays);
variables.put("description", description);
ok,参数准备好了,就准备传给工作流了:
ProcessInstance processInstance =
runtimeService.startProcessInstanceByKey("holidayRequest", variables);
此时,就会根据流程定义里的:
创建一个任务,任务有个标签,就是candidate group,这里是manager,可以猜得出,是给manager建了个审批任务。
manager查询并审批任务
以下,基于manager查询任务:
TaskService taskService = processEngine.getTaskService();
List tasks = taskService.createTaskQuery().taskCandidateGroup("managers").list();
System.out.println("You have " + tasks.size() + " tasks:");
for (int i=0; i 我们可把任务打印出来看看:
System.out.println("Which task would you like to complete?");
int taskIndex = Integer.valueOf(scanner.nextLine());
Task task = tasks.get(taskIndex - 1);
Map processVariables = taskService.getVariables(task.getId());
System.out.println(processVariables.get("employee") + " wants " +
processVariables.get("nrOfHolidays") + " of holidays. Do you approve this?");
审批任务:
boolean approved = scanner.nextLine().toLowerCase().equals("y");
variables = new HashMap();
variables.put("approved", approved);
taskService.complete(task.getId(), variables);
这里就是把全局变量 approved,设为了true,然后提交给引擎。引擎就会根据这里的变量为true还是false,走不同分支。对应了:
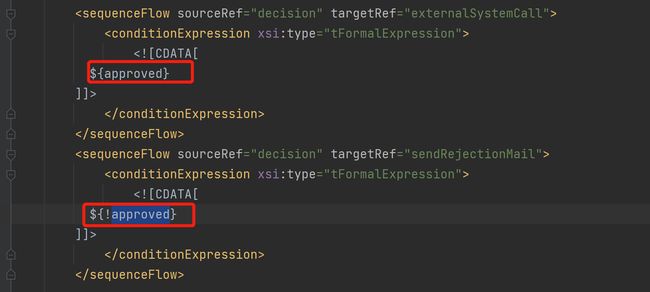
回调用户代码--用户开始休假
上面审批后,就会进入下一个节点:休假。
这里有个class,就是需要我们自己实现的。

然后,基本流程就自己走完了。
flowable rest-api模式
简介
上面那种,是其作为一个jar,内嵌到我们的程序里,创建引擎对下。由我们业务程序去驱动引擎的运行。引擎和业务代码在同一个进程。
其实,flowable也可以作为一个独立服务运行,提供rest-api出来,这样的话,非java语言的开发者也可以使用该引擎了。
这个只需要我们下载官方的zip包,里面有个rest的war包,我们丢到tomcat里运行。
上传工作流定义xml文件,部署工作流
如果要实现上面java-api那样的功能,我们就需要调接口来实现

下面就开始启动工作流:

其他接口就不一一展示了。可以参考文档。
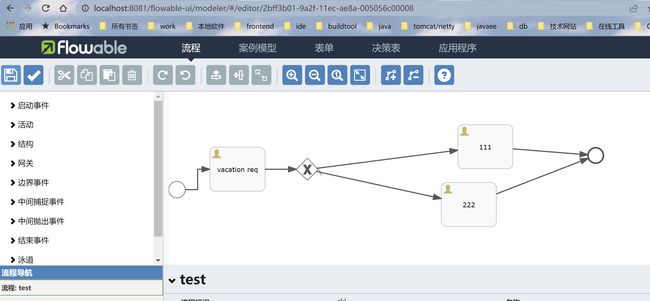
flowable-ui,通过web ui进行流程xml建模
上面手工建立xml,还是比较累的,我们可以通过其提供的web ui来建模,省点力气。(不过也不是很好用,各种名词比较费解,大家可能还是要自己做一套前端界面,调用自己的接口,来生成一个xml文件)
上面的rest那一节,tomcat里就部署了一个flowable-ui的。
就可以通过下面这样的方式来建模。
其他方面
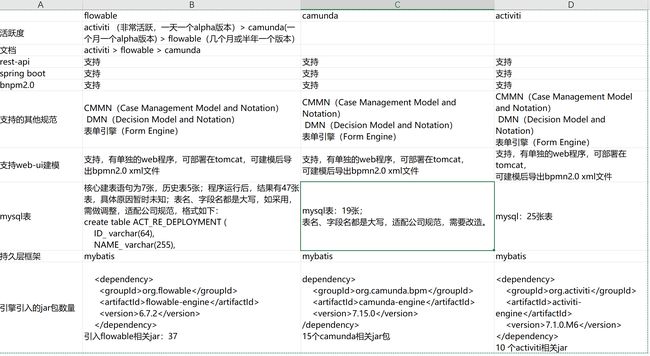
活跃程度:activiti是最活跃的,activiti (非常活跃,一天一个alpha版本)> camunda(一个月一个alpha版本) > flowable(几个月或半年一个版本)
依赖:会引入37个jar包,当前最新的6.7.2版本
mysql:核心建表语句为7张,历史表5张;程序运行后,结果有47张表,具体原因暂时没去研究
持久层框架:写mysql表时,使用mybatis
引擎对比
总结
demo代码:
https://gitee.com/ckl111/all-simple-demo-in-blog/tree/master/flowable-test