Python的CNN笔记
降维方法
有PCA(主成分分析)和LDA(线性判别分析,Fisher Linear Discriminant Analysis
1:Tensorflow中examples.tutorials.mnist中 input_data数据类
在tensorflow最初时一直用的就是最经典的mnist手写字符识别中的数据集了,而且在tensorflow中直接封装好的是mnist手写字符的数据集类,方便直接用input_data.*中的方法调用其读取数据,读取数据标签
2:mnist = input_data.read_data_sets(‘MNIST_data/’, one_hot=True)
说明:mnist数据集不能直接使用,需要通过input_data模块进行初始化,否则会报mnist is not defined
3:
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding=‘SAME’)
strides在官方定义中是一个一维具有四个元素的张量,其规定前后必须为1,所以我们可以改的是中间两个数,中间两个数分别代表了水平滑动和垂直滑动步长值。
4:tf.truncated_normal
从截断的正态分布中输出随机值.
生成的值遵循具有指定平均值和标准偏差的正态分布,不同之处在于其平均值大于 2 个标准差的值将被丢弃并重新选择.
5:tf.summary.histogram
数据显示出来 tf.summary.histogram()将输入的一个任意大小和形状的张量压缩成一个由宽度和数量组成的直方图数据结构.假设输入 [0.5, 1.1, 1.3, 2.2, 2.9, 2.99],则可以创建三个bin,分别包含0-1之间/1-2之间/2-3之间的所有元素,即三个bin中的元素分别为[0.5]/[1.1,1.3]/[2.2,2.9,2.99].
通过可视化张量在不同时间点的直方图来显示某些分布随时间变化
6: tf.matmul(
a,
b,)
将矩阵 a 乘以矩阵 b,生成a * b
VScode终端无法输入
左上角->文件->首选项->设置->Runinterminal->打上对勾
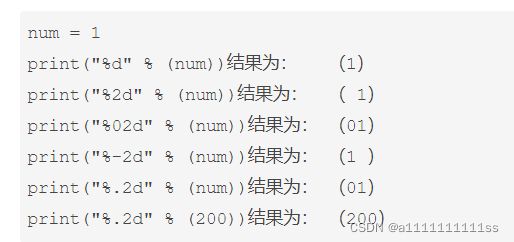
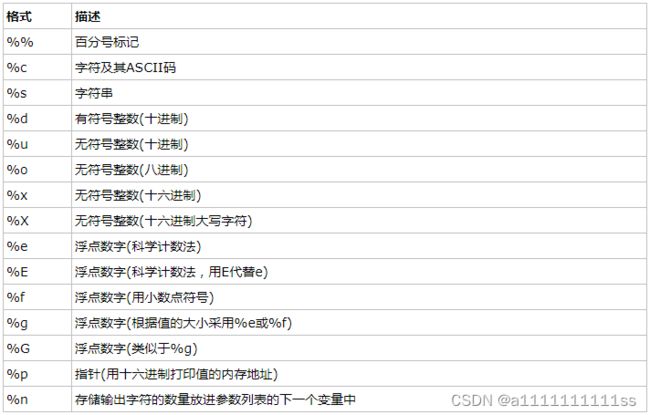
print的%d
Python中的[:]
[1:]意思是去掉列表中第一个元素(下标为0),去后面的元素进行操作
a[::-1]相当于 a[-1:-len(a)-1:-1],也就是从最后一个元素到第一个元素复制一遍。
[-3:] 是输入一行中最后三个,按顺序输出
print的end用法

数据初始化
层初始化
层带值
main
数据-(步长)卷积-池化-(随机)W-b(常数)
增层(初始化 Wby灭活)均查看
增层(带值 卷积 池化 Wb)
正确率-替换变量 判断相等 降维loss 运行
main 整理数据-添加层结构-loss-参数初始化-训练
初始化mnist
mnist = input_data.read_data_sets
前后必须1 中间为水平竖直方向
strides=[1,step,step,1]
用正态分布创建数据 stddev 标准差
initial = tf.truncated_normal(shape,stddev=0.1)
创建常量(tf.constant)
keep_prob = 1 神经元全不死
显示数据
tf.summary.histogram(
name_scope()
只决定“对象”属于哪个范围,并不会对“对象”的“作用域”产生任何影响。
z_dim: g网输入的噪声数据z的维度
强制替换变量
global prediction
equal 判断相等
tf.equal(tf.arg_max(y_data,1))
placeholder用于定义过程,在执行的时候再赋具体的值,Session.run 的函数的 feed_dict 参数指定
dtype:数据类型。常用的是tf.float32,tf.float64等数值类型
shape:数据形状。默认是None,就是一维值,也可以多维,比如:[None,3],表示列是3,行不一定
name:名称
将n个784个向量,变成n个28*28的#
x_image = t# softmax_cross_entropy_with_logits
但是一张图就对应着一个类,class在图片中是独立的,并且一张图中只能有一个class,
# 直观表现为label形式为[0,0,…,1,0,…0],1000个元素中有且只有一个元素是1,其余都是0。
# 参数labels:类维度的每个向量应该保持有效的概率分布,比如10分类[0,0,0,0,0,0,0,1,0,0]
# logits:(全连接层的输出)
# tf.summary可视化查看f.reshape(xs,[-1,28,28,1])
Adam优化算法
train = tf.train.AdamOptimizer(1e-4).minimize(loss)
变量初始化
init = tf.initialize_all_variables()