2021电赛F题(智能送药小车)参赛总结【视觉部分】
2021电赛F题(智能送药小车)参赛总结【视觉部分】
前言
在2021年全国大学生电子设计竞赛中,我们小组做的是F题(智能送药小车)。我在小组中主要负责小车视觉功能的实现,所以在本篇参赛总结中只会涉及小车视觉功能实现的思路和过程。
提示:下文中所提出的实现方法不一定是最优解,如果有其他更好的建议和想法,我衷心欢迎大家与我交流,一起学习进步!
一、题目解读
完整规则太多了,这里仅引入一些与视觉部分相关的内容。
通读题目后,不难发现,能用到视觉的有两方面:
- 小车寻迹
- 数字(病房号)识别
二、实现思路
1. 小车寻迹
小车寻迹任务主要是寻找红色的道路中线,保证小车不偏不倚地行进且不会压黑线。我们可将整个寻迹分为两个部分:直道和路口。任务为实时告知主控板当前红色中线和小车的相对位置,以及是否到达路口。
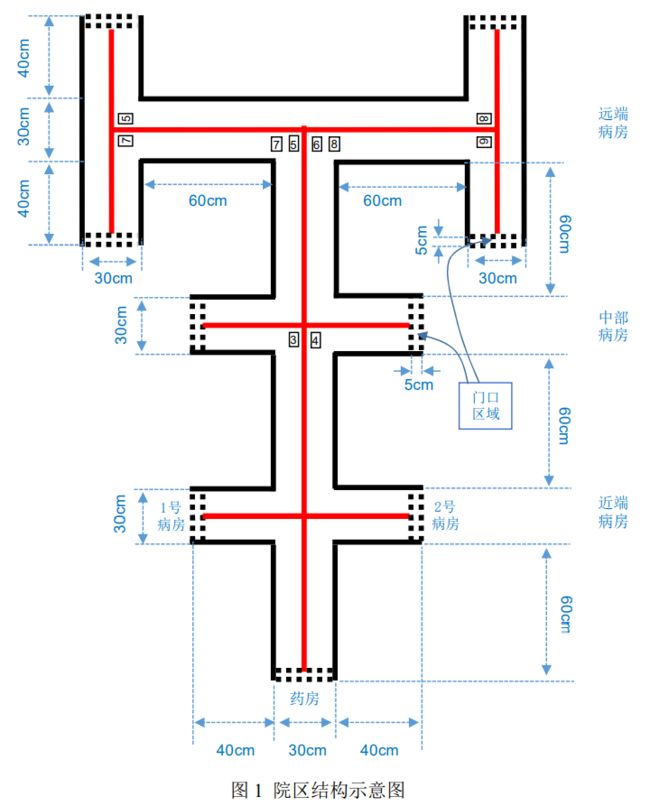
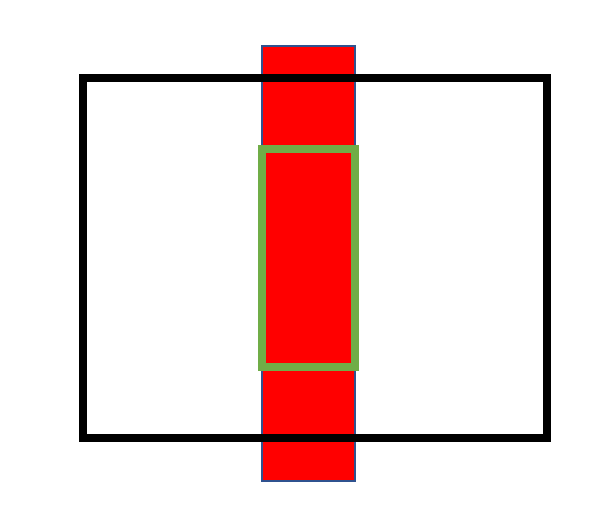
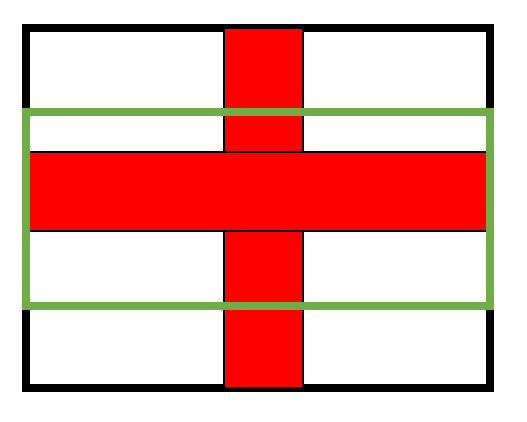
我们决定使用openmv作为视觉传感器,openmv寻找红色中线主要是使用find_blobs()根据设定好的LAB阈值进行色块查找。但是在实际使用过程中会出现反光(赛道红线使用红色电工胶布制成),为了解决这个问题,我们将摄像头小车底盘(透明亚克力板)摄像头区域进行遮挡使之不透光。车前和车尾遮挡不完全,防止反光影响色块查找划定上图中绿色区域作为ROI(0,30,160,60),摄像头帧尺寸采用QQVGA([w:160 h:120])。如下图所示:

直道寻迹
openmv置于小车底盘中央位置,镜头方向向下,使摄像头画面中红线竖直在画面中央,宽度占比1:5左右,如下图所示。
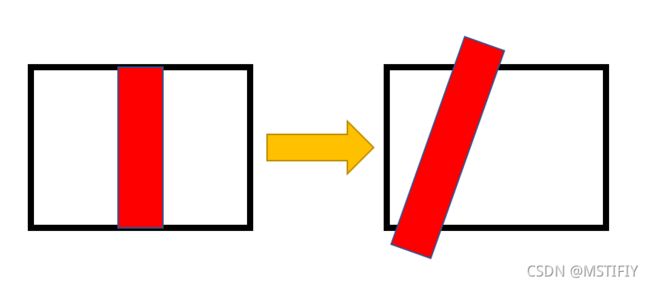
我们将上图左边图像视为小车理想位置,当出现右边情况时,此时小车实际位置与理想位置会产生一个距离偏移和角度偏移。所以,我们需要实时通过openmv得到这两个偏移量,通过串口发送给主控板以便其控制电机完成偏移量的减少。之于如何计算这两个量值,可以参看micropython官方文档Blob 类 – 色块对象中的cx(),cy(),rotation()方法。
路口寻迹
在地图上会出现的路口情况如下图所示(除去右上角那张),分别为十字路口和T形路口。
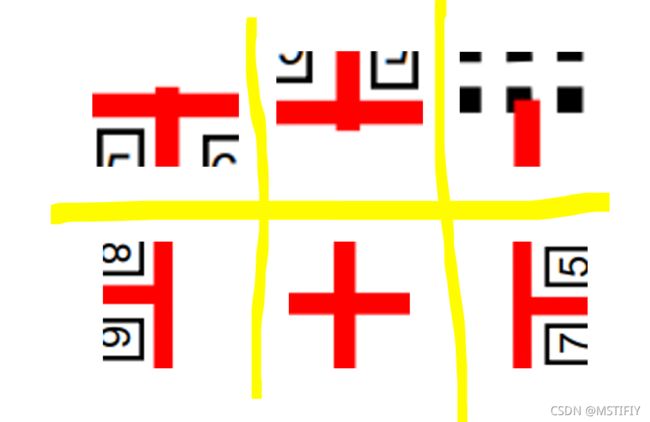
那么如何判断小车行至路口了呢?这里我们使用如下方法进行判断。
在find_blobs查找色块后,会得到返回一个包括每个色块的色块对象的列表。为了防止干扰,我们可以取最大的色块作为目标色块。得到目标色块blob包围矩形,上两图分别是直道和路口的包围矩形(绿色边框)。可以看到,直道和路口的矩形框在形状上有所区别,直道矩形h>w,路口矩形hblob[7])进行路口和直道的判别。通过blob[7]*53-90得到我们平时认知中的红线偏离竖直中心轴的角度值,当小车在直道上行进时,这个值应当在大约在(-45,45)之间波动,遇到路口时,这个值会突变到到(-90,-70)和(70,90)之间,因此通过角度偏移量的突变感知到路口的出现。
至于是否到达路口这一点的判断逻辑是在主控板上,openmv的功能就是一直发送距离和角度的偏移量。
主要micropython函数:find_blobs()
Openmv寻迹代码
import sensor, image, time, pyb
import math
from pyb import UART
# LAB threshold for red line
road_threshold = (0, 39, 21, 127, -128, 127)
sensor.reset()
sensor.set_pixformat(sensor.RGB565)
sensor.set_framesize(sensor.QQVGA) # QQVGA:[w:160 h:120]
sensor.skip_frames(n = 800)
sensor.set_auto_gain(False)
sensor.set_auto_whitebal(False)
uart = UART(3, 115200)
clock = time.clock()
def find_max(blobs):
max_size=0
for blob in blobs:
if blob.pixels() > max_size:
max_blob=blob
max_size = blob.pixels()
return max_blob
while (True):
clock.tick()
img = sensor.snapshot()
blobs = img.find_blobs([road_threshold], roi = (0, 30, 160, 60), x_stride = 20, y_stride = 20, pixels_threshold = 100)
if blobs:
b = find_max(blobs)
img.draw_rectangle(b[0:4])
img.draw_line((b[5], b[6], b[5] + int(50 * math.cos(b[7])), b[6] + int(50 * math.sin(b[7]))), color = (0, 255, 0))
uart.write('D%03dA%03dE' % (b[5] - 80, b[7] * 53 - 90+7)) # 这里的角度偏移值"+7"是实际测试中出现的误差的补偿量
print('D%03dA%03dE' % (b[5] - 80, b[7] * 53 - 90+7))
else:
uart.write('D%03dA%03dE' % (999, 999)) # 没有找到中线(中线不在摄像头视野内)
print('D%03dA%03dE' % (999, 999))
print(clock.fps())
Tips
road_threshold这个阈值是通过openmv官方IDE上的阈值选择器确定的。- 上面代码的相关偏移量计算是要配合主控板的判断逻辑的,不同的主控判断逻辑对openmv发送的内可能会有所差异。
- 当然,寻迹功能也不一定要使用摄像头。很多队伍也采用灰度传感器进行寻迹,听说不仅简单,而且效果还是不错的。我们之前也是考虑做的,但是今年物资太少,现买灰度传感器时间上来不及,所以就用手头的openmv做寻迹了。
2. 数字(病房号)识别
第一次看到数字识别,想到的是K210跑yolo模型。果不其然,开赛不久,网上一老哥就做出来了。看了结果后,发现K210的缺点还是有的。首先就是摄像头视角问题,手上买的官方maix-bit套件中的摄像头视角太小,不能同时看完远端病房路口处的四个数字,得换一个广角镜头才行。然后就是误识别,容易把1看做7,5看做6,这可能是数据集太少的原因(不过后来又跑过某个兄弟的每类1000+训练图片量的目标检测模型,发现5和6还是分不清,麻了)。我这个人本来就对采集数据集和标注发怵的,而且时间缺失,K210的方案果断放弃了。
摒弃K210后,掏出了之前管学长借的一块树莓派4b,开搞!(今年组委会规则开放使用树莓派)经一番思考后,我们决定放弃训练目标检测模型,使用传统图像处理+机器学习的方案解决。摄像头我们采用一个USB免驱150度广角摄像头,树莓派系统为官方桌面版系统(2021.5.7),开发环境为python+opencv,还外接了一块7英尺显示屏(用来显示信息)。
同样,我们可将整个数字识别过程分为两个部分: 数字图像提取和分类。
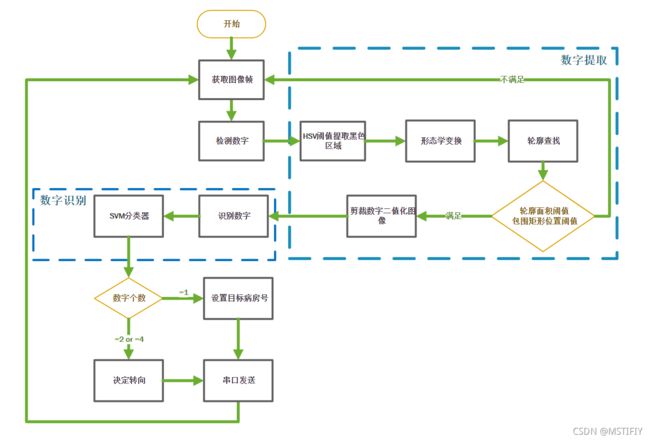
树莓派上位机任务如下:
- 获取目标病房号
- 发送转向指令
流程图大致如下:
数字提取
下图为手机拍摄的输入源图像,实际摄像头输入图像左右视角应当更宽。

思路为:根据颜色找到图像中的数字、标签边框和道路边界,形态学操作去掉噪点和标签边框。查找轮廓,得到轮廓包围矩形。根据矩形位置阈值滤去道路边界,最后根据数字的矩形框剪裁得到数字二值化图像。
HSV颜色阈值确定
通过下面这个脚本确定黑色数字的HSV阈值。
hsv_choose.py
import cv2
import numpy as np
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 1080)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 960)
def nothing(x):
pass
cv2.namedWindow("Tracking")
cv2.createTrackbar("LH", "Tracking", 0, 255, nothing)
cv2.createTrackbar("LS", "Tracking", 0, 255, nothing)
cv2.createTrackbar("LV", "Tracking", 0, 255, nothing)
cv2.createTrackbar("UH", "Tracking", 0, 180, nothing)
cv2.createTrackbar("US", "Tracking", 0, 255, nothing)
cv2.createTrackbar("UV", "Tracking", 0, 255, nothing)
while True:
# 读取图片
_, frame = cap.read()
# 压缩图像
frame = cv2.resize(frame, (400, 400 * frame.shape[0] // frame.shape[1]))
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
l_h = cv2.getTrackbarPos("LH", "Tracking")
l_s = cv2.getTrackbarPos("LS", "Tracking")
l_v = cv2.getTrackbarPos("LV", "Tracking")
u_h = cv2.getTrackbarPos("UH", "Tracking")
u_s = cv2.getTrackbarPos("US", "Tracking")
u_v = cv2.getTrackbarPos("UV", "Tracking")
l_g = np.array([l_h, l_s, l_v]) # lower green value
u_g = np.array([u_h, u_s, u_v])
mask = cv2.inRange(hsv, l_g, u_g)
res = cv2.bitwise_and(frame, frame, mask = mask) # src1,src2
cv2.imshow("frame", frame)
cv2.imshow("mask", mask)
key = cv2.waitKey(1)
if key == 27: # Esc
break
cv2.destroyAllWindows()
数字识别
数字识别采用SVM分类器分类方法。首先采集各类数字图片,再进行训练得到svm.dat。在主程序中只需加载SVM分类器对提取得到的二值化数字图像进行分类即可。
SVM训练部分这里就不详述了,大家可以自行百度。或者后面有时间的话,我会单独写一篇关于SVM训练的博客。
预测部分代码片段:
def predict(label_img):
model = cv2.ml.SVM_load("svm.dat") # 切记,如果设置树莓派自启动,此处需填绝对路径
label_img = cv2.resize(label_img, (20, 20), interpolation = cv2.INTER_AREA)
label_img = preprocess_hog([label_img]) # 方向梯度直方图
# 识别
resp = model.predict(label_img)[1].ravel()
number = chr(resp[0])
predict_result = number
return predict_result
树莓派Python代码
F_rasp.py
import cv2
import numpy as np
from numpy.linalg import norm
import serial
import time
import threading
"""全局调试参数"""
# 摄像头
CAMERA_PATH = -1
# FRAME_WIDTH = 3000
# FRAME_HEIGHT = 960
# 模式选择
COLLECT_MODE = False # 图片采集
DEBUG_MODE = False # 调试
RESULT_MODE = False # 显示结果
SERIAL_MODE = True # 串口通信
MES_MODE = False # GUI提示
# 串口
# SERIAL_WIN_PORT = "COM10"
SERIAL_LIN_PORT = "/dev/ttyUSB0"
# 图像阈值
LOWER_HSV = [0, 0, 0]
UPPER_HSV = [180, 255, 75]
MORPH_KERNEL_SIZE = 3 # 开闭操作核大小
MORPH_OPEN_NUM = 0 # 开操作次数
MORPH_CLOSE_NUM = 1 # 闭操作次数
CONTOUR_AREA_MAX = 3000 # 轮廓面积阈值
CONTOUR_AREA_MIN = 500
ROI_SPACES = (100, 10, 2, 2) # 识别ROI相对画面位置:上,下,左,右
# 通信参数初始化
global ser
target_number = 0 # 目标病房号码,0:无病房,1~8:1~8病房
turn_flag = 4 # 转向标志位,1:直行,2:左转,3:右转 4:无效
detect_flag = 0 # 检测标志位,0:停止检测,1:开启检测
controlFrame = "T%01d%01dE" # %01d 对应turn_flag或者target_number
wait_target_list = []
WAIT_FRAME_NUM = 60
loop_send_flag = 1
if MES_MODE:
message_text = ""
if COLLECT_MODE:
count = 0
# 来自opencv的sample,用于svm训练 返回直方图
def preprocess_hog(digits):
samples = []
for img in digits:
gx = cv2.Sobel(img, cv2.CV_32F, 1, 0)
gy = cv2.Sobel(img, cv2.CV_32F, 0, 1)
mag, ang = cv2.cartToPolar(gx, gy)
bin_n = 16
_bin = np.int32(bin_n * ang / (2 * np.pi))
bin_cells = _bin[:10, :10], _bin[10:, :10], _bin[:10, 10:], _bin[10:, 10:]
mag_cells = mag[:10, :10], mag[10:, :10], mag[:10, 10:], mag[10:, 10:]
hists = [np.bincount(b.ravel(), m.ravel(), bin_n) for b, m in zip(bin_cells, mag_cells)]
hist = np.hstack(hists)
# transform to Hellinger kernel
eps = 1e-7
hist /= hist.sum() + eps
hist = np.sqrt(hist)
hist /= norm(hist) + eps
samples.append(hist)
return np.float32(samples)
def detect(srcImg):
# print(srcImg.shape)
if COLLECT_MODE:
global count
dst = srcImg.copy()
if DEBUG_MODE or RESULT_MODE:
w, h = dst.shape[1], dst.shape[0]
cv2.rectangle(dst, (ROI_SPACES[2], ROI_SPACES[0]), (w - ROI_SPACES[3], h - ROI_SPACES[1]), (255, 0, 0))
num_mask = np.zeros((srcImg.shape[0], srcImg.shape[1]), np.uint8)
# if DEBUG_MODE:
# cv2.imshow("srcImg", srcImg)
# 把 BGR 转为 HSV
hsv = cv2.cvtColor(srcImg, cv2.COLOR_BGR2HSV)
# HSV中黑色范围
lower_hsv = np.array(LOWER_HSV)
upper_hsv = np.array(UPPER_HSV)
# 获得黑色区域的mask
mask = cv2.inRange(hsv, lower_hsv, upper_hsv)
mask = cv2.medianBlur(mask, 5)
if DEBUG_MODE:
cv2.imshow("hsv mask img", mask)
# 形态学变换
element = cv2.getStructuringElement(cv2.MORPH_RECT, (MORPH_KERNEL_SIZE, MORPH_KERNEL_SIZE)) # 获取核
for i in range(MORPH_OPEN_NUM):
mask = cv2.morphologyEx(mask, cv2.MORPH_OPEN, element)
for i in range(MORPH_CLOSE_NUM):
mask = cv2.morphologyEx(mask, cv2.MORPH_CLOSE, element)
if DEBUG_MODE:
cv2.imshow("morph img", mask)
# 轮廓查找
contours, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
if DEBUG_MODE:
cv2.drawContours(dst, contours, -1, (0, 0, 255))
labels = []
for index, contour in enumerate(contours):
# print(cv2.contourArea(contour))
if CONTOUR_AREA_MAX > cv2.contourArea(contour) > CONTOUR_AREA_MIN: # 轮廓包围大小阈值
if DEBUG_MODE:
cv2.drawContours(dst, contours, index, (0, 255, 0))
contour_poly = cv2.approxPolyDP(contour, 3, True)
x, y, w, h = cv2.boundingRect(contour_poly)
if w / h > 1.5:
continue
if srcImg.shape[1] - ROI_SPACES[3] < x + w or x < ROI_SPACES[2] or srcImg.shape[0] - ROI_SPACES[
1] < y + h or y < ROI_SPACES[0]: # 过滤道路
continue
num_mask = cv2.drawContours(num_mask, contours, index, 255, -1)
_mask = cv2.add(mask, np.zeros(np.shape(mask), dtype = np.uint8), mask = num_mask)
if DEBUG_MODE:
cv2.imshow("number mask", _mask)
# 将标号向四周扩充
pre_img = _mask[y:y + h, x:x + w]
if h > w:
pre_img = cv2.copyMakeBorder(pre_img, 5, 5, int((h + 10 - w) / 2), int((h + 10 - w) / 2),
cv2.BORDER_CONSTANT,
value = [0, 0, 0])
else:
pre_img = cv2.copyMakeBorder(pre_img, int((w + 10 - h) / 2), int((w + 10 - h) / 2), 5, 5,
cv2.BORDER_CONSTANT, value = [0, 0, 0])
if COLLECT_MODE:
# 录制采集
global count
cv2.imshow("collect image", cv2.resize(pre_img, (100, 100)))
cv2.waitKey(30)
print("keep or abandon? enter q to abandon,enter Enter to keep.")
if cv2.waitKey(0) & 0xff is not ord('q'):
cv2.imwrite("./images/" + str(count) + ".jpg", pre_img)
count += 1
print("keep")
else:
print("abandon")
cv2.destroyWindow("collect image")
result = predict(pre_img)
labels.append({"image": _mask[y:y + h, x:x + w], "rect": (x, y, w, h), "result": result})
if 0 < len(labels) < 5:
# 对目标进行排序,从左到右依次为0,1,2,3
sorted_labels = sorted(labels, key = lambda keys: keys["rect"][0])
for index, l in enumerate(sorted_labels):
cv2.rectangle(dst, (l["rect"][0], l["rect"][1]), (l["rect"][0] + l["rect"][2], l["rect"][1] + l["rect"][3]),
(0, 255, 0), 2)
cv2.putText(dst, str(l["result"]), (l["rect"][0], l["rect"][1]), cv2.FONT_HERSHEY_SIMPLEX, 2, (255, 0, 0),
4, 8)
if RESULT_MODE or DEBUG_MODE:
cv2.putText(dst, "TA: " + str(target_number) + " TU: " + str(turn_flag), (50, 50),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
cv2.imshow("detect result", cv2.resize(dst, (0, 0), fx = 1, fy = 1))
if MES_MODE:
cv2.moveWindow("detect result", 0, 0)
return sorted_labels
else:
if RESULT_MODE or DEBUG_MODE:
cv2.putText(dst, "TA: " + str(target_number) + " TU: " + str(turn_flag), (50, 50),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
cv2.imshow("detect result", cv2.resize(dst, (0, 0), fx = 1, fy = 1))
if MES_MODE:
cv2.moveWindow("detect result", 0, 0)
return None
def predict(label_img):
model = cv2.ml.SVM_load("svm.dat") # 切记,如果设置树莓派自启动,此处需填绝对路径
label_img = cv2.resize(label_img, (20, 20), interpolation = cv2.INTER_AREA)
label_img = preprocess_hog([label_img]) # 方向梯度直方图
# 识别
resp = model.predict(label_img)[1].ravel()
number = chr(resp[0])
predict_result = number
return predict_result
def open_detect(_frame):
global target_number
global loop_send_flag
global message_text
global turn_flag
if target_number != 0:
print("target number is: " + str(target_number))
if MES_MODE:
message_text += "target number is: " + str(target_number) + "\n"
else:
print("not get target number!")
if MES_MODE:
message_text += "not get target number!" + "\n"
# 识别数字标签
ls = detect(_frame)
if ls is not None:
ls_number = [_l["result"] for _l in ls]
# print(ls_number)
if 1 < len(ls_number) < 5:
loop_send_flag = 0
if len(ls_number) == 1: # 一张标签的情况
global WAIT_FRAME_NUM
if len(wait_target_list) < WAIT_FRAME_NUM:
print("Target_number setting...[" + str(len(wait_target_list)) + "]")
if MES_MODE:
message_text += "Target_number setting...[" + str(len(wait_target_list)) + "]" + "\n"
wait_target_list.append(ls_number[0])
else:
result = {}
for i in set(wait_target_list):
result[i] = wait_target_list.count(i)
target_number = sorted(result.items(), key = lambda item: item[1], reverse = True)[0][0]
print("Target_number set finish!")
if MES_MODE:
message_text += "Target_number set finish!" + "\n"
loop_send_flag = 1
wait_target_list.clear()
turn_flag = 4
elif len(ls_number) == 2: # 2张标签的情况
for index, i in enumerate(ls_number):
if int(i) == int(target_number) and index == 0: # 目标病房在左边,左转
turn_flag = 2
break
elif int(i) == int(target_number) and index == 1: # 目标病房在右边,右转
turn_flag = 3
break
else: # 无目标病房,直行
turn_flag = 1
send(turn_flag, target_number)
elif len(ls_number) == 4: # 4张标签的情况
for index, i in enumerate(ls_number):
if int(i) == int(target_number) and (index == 0 or index == 1): # 目标病房在左边,左转
turn_flag = 2
break
elif int(i) == int(target_number) and (index == 2 or index == 3): # 目标病房在右边,右转
turn_flag = 3
break
else: # 无目标病房,直行
turn_flag = 1
send(turn_flag, target_number)
else:
turn_flag = 4
print("the number of labels is incorrect!")
else:
wait_target_list.clear()
turn_flag = 4
print("not find number label!")
# 串口发送
def send(t_flag, t_number):
global message_text
content = controlFrame % (int(t_flag), int(t_number))
if SERIAL_MODE:
ser.write(content.encode())
print("Send: " + content)
if MES_MODE:
message_text += "Send: " + content + "\n"
def message(text):
bg = np.zeros((100, 600, 3), np.uint8) # 生成一个空灰度图像
fontFace = cv2.FONT_HERSHEY_SIMPLEX
fontScale = 1
fontColor = (0, 255, 0) # BGR
thickness = 1
lineType = 2
y0, dy = 50, 25
for i, txt in enumerate(text.split('\n')):
y = y0 + i * dy
cv2.putText(bg, txt, (50, y), fontFace, fontScale, fontColor, thickness, lineType)
cv2.namedWindow("F_CAR_GUI")
cv2.moveWindow("F_CAR_GUI", 0, 500)
cv2.imshow("F_CAR_GUI", bg)
def main():
# 摄像头参数初始化
cap = cv2.VideoCapture(CAMERA_PATH)
assert cap is not None, "未能打开目标路径下的摄像头,可尝试修改CAMERA_PATH"
# cap.set(cv2.CAP_PROP_FRAME_WIDTH, FRAME_WIDTH)
# cap.set(cv2.CAP_PROP_FRAME_HEIGHT, FRAME_HEIGHT)
if MES_MODE:
cv2.namedWindow("F_CAR_GUI")
while True:
global message_text
message_text = ""
print("**************FRAME_BEGIN**************")
# 读取图片
_, frame = cap.read()
if frame is None:
break
# 压缩图像
frame = cv2.resize(frame, (400, 400 * frame.shape[0] // frame.shape[1]))
open_detect(frame)
if target_number and loop_send_flag:
if SERIAL_MODE:
ser.write((controlFrame % (4, int(target_number))).encode())
print("send: " + controlFrame % (4, int(target_number)))
if MES_MODE:
message_text += "send: " + controlFrame % (4, int(target_number)) + "\n"
print("***************FRAME_END***************\n\n\n")
if MES_MODE:
message(message_text)
if cv2.waitKey(30) & 0xFF == 27:
break
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
print("程序开始运行...")
if SERIAL_MODE:
ser = serial.Serial(SERIAL_LIN_PORT, 115200, timeout = 0.5)
# import platform
# if platform.system() == 'Windows':
# ser = serial.Serial(SERIAL_WIN_PORT, 115200, timeout = 0.5)
# elif platform.system() == 'Linux':
# ser = serial.Serial(SERIAL_LIN_PORT, 115200, timeout = 0.5)
main()
本方案与下位机通信逻辑如下:
树莓派开机自动运行本脚本,此时下位机并未复位。将目标病房号标签放置于摄像头下进行识别设置目标数字值,此过程可根据程序所提供的的简单UI进行。识别成功后拿走标签,上位机会持续发送无效转向值和目标数字值(因为如果目标值是1或2,需要在第一个无标签路口转向)。下位机复位后,小车开始行进,到达一定距离后(小车电机闭环控制)急刹(此时下位机接收累加器清零,开始累加接收到的转向值)开始缓慢向前行驶一小段距离,此时摄像头正好看到路口标签,开始进行标签识别,并发送有效转向值和目标数字值。小车缓慢行驶一段距离后,对接收累加器的值进行取平均,平均值作为本路口的转向参考。向前行驶到达路口,进行转向(直行也属于转向)。如果没有发送任何转向信息,小车会认为到达病房,停止行进。校车转向记录会在下位机进行压栈,返回时直接出栈就行。
Tips
- 树莓派系统安装细节
最好不要设置用户名和密码,防止后面设置自启动失败。
- 树莓派开机自启动
之前看了很多篇解决方法都不行,被坑了好久,最后成功解决的方法如下:树莓派4b——开机后自动打开终端Terminal并执行指定代码或python代码
- 树莓派opencv_python安装
参考博文如下:树莓派python3使用pip3安装opencv3.4
我是使用文中第三种方法安装的,并且安装的是opencv_python-3.4.3.18!!!之前不指定版本,直接pip默认下载最新的4.x,总是安装不上。但是安装opencv_python-3.4.3.18后,上面的代码需要进行修改,contours, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)需要更改为_, contours, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE),这是opencv版本差异所致的。
总结
这次电赛最终没能取得十分理想的成绩,主要是我背锅。电赛四天三夜里我个人有效参赛时间可能就两天,因为比赛和专业结课考试冲突了,导致来回在相隔十多公里的新老区之间往返(比赛场地在新区,考试在老区。)也耽误了不少时间。主要还是没熬夜,不敢熬。就挺对不起队友的,唉~总之,就是很遗憾,明明可以做得更好。
最后的最后,如果上面文章中有任何叙述不详和不妥之处,欢迎大家和我交流,一起进步~