MySQL 窗口函数/视图
目录
- 窗口函数
-
- 窗口函数中的元素
- 窗口函数类别
- 视图
窗口函数
窗口函数可以进行排序,生成序列号等一般的聚合函数无法实现的高级操作。只有SELECT和ORDER BY 子句直接支持窗口函数。窗口函数也称为OLAP函数,即对数据库数据进行实时分析处理。窗口函数就是为了实现OLAP而添加的标准SQL功能。窗口函数语法:其中[]中的内容可以省略
<窗口函数> over ([partition by <列清单>] order by <排序用列清单>)
窗口函数中的元素
窗口函数的行为描述出现在函数的OVER子句中,并涉及多个元素。3个核心元素分别是分区、排序和框架。不是所有的窗口函数都支持这3个元素。
分区
分区元素是由PARTITION BY子句定义,并被所有的窗口函数支持。对当前计算的窗口函数进行限制,仅仅那些在结果集的分区列中与当前行有相同值的行才能进入窗口。如果没有指定PARTITION BY子句,窗口就没有限制。换种说法就是:如果没有显示指定分区,则默认分区就是把整个查询结果集当作一个分区。同一个查询中的不同函数,可能会有不同的分区描述。
排序
排序元素定义计算的顺序,如果与分区有关,则是在分区内的顺序。针对不同的函数类别,排序元素有轻微的不同意义。对于排名函数,排序是直观的。而聚合窗口函数的排序和排名窗口的排序略有意义上的不同。在聚合中,排序与聚合的顺序无关;然而,排序元素为下面将描述的框架选项赋予一定的含义,换句话说,排序元素帮助限定在窗口内的行。
框架
从本质上来说,框架是一个在分区内对行进行进一步限制的筛选器。它适用于聚合窗口函数,也适用于三个偏移函数:FIRST_VALUE、LAST_VALUE、NTH_VALUE。把这个窗口元素想成是基于给定的排序,在当前行所在分区中定义两个点,这两个点形成的框架之间的行才会参与计算。
在标准的框架描述中,包含一个ROWS或RANGE选项,用来定义框架的开始行和结束行,这两行也可以形成“框架外”(框架内的行被排除在计算外)窗口选项。
ROWS选项允许用相对当前行的偏移行数来指定框架的起点和终点。RANGE选项更具灵活性,可以以框架起终点的值于当前行的值的差异来定义偏移行数。“框架外”窗口选项用来定义如何对当前行及具有相同值的行进行处置。
窗口函数类别
窗口函数大体可以分为:
【1】能够作为窗口函数的聚合函数(sum,avg,count,max,min)
【2】rank、dense_rank、row_number等专用窗口函数
【3】分布函数
【4】偏移函数
语法的基本使用方法:
rank函数
rank函数是用来计算记录排序的函数。
select product_name, product_type, sale_price,
rank () over (partition by product_type
order by sale_price) as ranking
from Product;
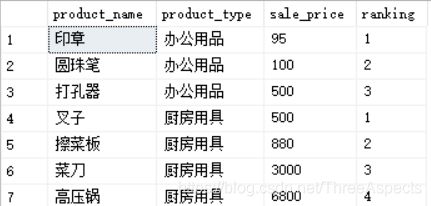
partition by 能够设定排序的对象范围,类似于group by语句。order by能够指定哪一列,何种顺序进行排序,也可以通过asc,desc来指定升序降序。窗口函数兼具分组和排序两种功能。通过partition by分组后的记录集合称为窗口。
专用函数的种类:
rank函数:计算排序时,如果存在相同位次的记录,则会跳过之后的位次。
dense_rank函数:同样是计算排序,即使存在相同位次的记录,也不会跳过之后的位次。
row_number函数:赋予唯一的连续位次。
由于窗口函数无需参数,因此通常括号里都是空的。窗口函数的适用范围:只能在select子句中使用。作为窗口函数使用的聚合函数:
sum函数
select product_id, product_name, sale_price,
sum(sale_price) over (order by product_id) as current_sum
from Product;
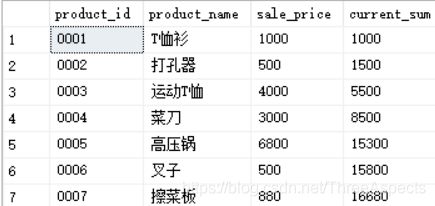
以累计的方式进行计算出商品编号小于自己的商品的销售单价的合计值。
avg函数
select product_id, product_name, sale_price,
avg(sale_price) over (order by product_id) as current_sum
from Product;
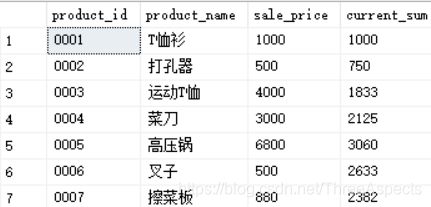
作为的统计对象同样是排在自己之上的记录。
计算移动平均
窗口函数就是将表以窗口为单位进行分割,并在其中进行排序的函数。其中还包含在窗口中指定更加详细的汇总范围的备选功能,该备选功能中的汇总范围称为框架。
//指定最靠近的3行做为汇总对象
select product_id, product_name, sale_price,
avg (sale_price) over (order by product_id
rows 2 preceding) as moving_avg
from Product;
//指定框架(汇总范围):这里使用的rows(行)和preceding(之前)两个关键字,
//将框架指定为截止到之前?行,因此rows 2 preceding就是将框架指定为截止到之前2行,
//也就是将作为汇总对象的记录限定为如下的最靠近3行
使用关键字following(之后)替换preceding,就可以将框架改为截止到之后n行。
select product_id, product_name, sale_price,
avg(sale_price) over (order by product_id
rows between 1 preceding and 1 following) as moving_avg--使用between规划范围,语句意思为rows 1 preceding --到rows 1 following
from Product;
1.之前1行的记录
2.当前记录
3.之后1行的记录
分布函数
窗口分布函数主要为静态统计服务提供数据的分布情况。排名分布函数有两种:PERCENT_RANK(百分位排名)和CUME_DIST(累积分布),逆分布函数也有两个:PERCENT_CONT(百分位连续)和PERCENTILE_DISC(百分位离散)。
根据标准SQL,分布函数计算数据行在窗口分区中的相对排名,把它表达成介于0~1之间的比值——百分比。假设rk 为数据行的RANK值,RANK函数的窗口描述与分布函数的窗口描述相同。假设nr为窗口分区内数据行的行数。假设np为领先或与当前行的排序值相同的行的数目(为比当前rk减1大的最小rk值,如果当前的rk为最大值,np则等于nr)。PERCENT_RANK(百分位排名)计算公式如下:(rk-1)/(nr-1),PERCENT_RANK(百分位排名)的计算公式如下:np/nr。
逆分布函数,通常叫百分位,我们可以把它执行的计算当作是排名分布函数的倒数。
PERCENTILE_DISC(百分位离散)函数(DISC为离散分布模型)返回组中第一个符合条件的值,条件是:其累计分布(CUME_DIST函数)大于等于输入值。
PERCENT_CONT(百分位连续)函数(CONT为连续分布函数)比较难理解(PERCENT_CONT(@pct) WITHIN GROUP(ORDER BY 分数))。举个简单示例,想象对一行数为偶数的组进行中值计算。需要内插值来支持连续分布假定,插入的值落在两个中间点的中间,意味着它是两个中间点的平均值。
偏移函数
窗口偏移函数包括两种类型的函数。一种是偏移量是相对于当前行的,这个类别的包括LAG和LEAD函数;另一个类别函数的偏移量是相对于窗口框架的开始和结尾的,这个类别包括FIRST_VALUE、LAST_VALUE和NTH_VALUE。第一类别中的函数(LAG和LEAD)支持窗口分区子句以及窗口排序子句。当然,后者的存在赋予偏移量以逻辑意义。第二类别中的函数(FIRST_VALUE、LAST_VALUE和NTH_VALUE)在支持窗口分区子句和排序子句的基础上,还支持窗口框架子句。
LAG和LEAD函数允许我们从窗口分区中,根据给定的相对于当前行的前偏移量(LAG)和后偏移量(LEAD),返回对应行的值。如果没有指定,偏移量默认为1。
FIRST_VALUE和FIRST_VALUE分别返回框架的第一行和最后一行所有查询的值。NTH_VALUE函数作用是中的相对窗口框架第一行或最后一行的偏移量,使得可以取得对应这个偏移量的记录值。
视图
对于复杂的查询事件,每次查询都需要编写MySQL代码效率低下。为了解决这个问题,数据库提供了视图(view)功能。视图是数据库中由真实的数据表查询语句定义而成的一种虚拟表,视图本身不存储数据只是存储查询数据的定义。基本表数据发生改变,视图中的数据会随之发生变化。
创建视图:CREATE VIEW 视图名(列1,列2...) AS SELECT (列1,列2...) FROM ...;
视图的优点:
1、使用视图,可以定制用户数据,聚焦特定的数据
2、使用视图,可以简化数据操作
3、使用视图,基表中的数据就有了一定的安全性
4、可以合并分离的数据,创建分区视图
视图使用场景:
- 计算列的需要,数据库设计范式要求减少冗余字段,因此现在很多数据表都没有计算列字段,如采购单:有价格、数量、税率、含税金额,多半没有不含税金额、税额,而这些字段在很多报表中有都会用到,所以可以创建一个含有计算列字段的视图来解决这个问题
- 不同表字段聚合,信息重组
- 安全性需要。合理利用视图则可以减少很多授权工作和保证数据安全性
视图与表的区别
数据库中的数据都是存储在表中的,而视图只是一个或多个表依照某个条件组合而成的结果集,一般来说可以用update,insert,delete等sql语句修改表中的数据,而对视图只能进行select操作。视图和表的区别:
1、视图没有实际的物理记录,而表有
2、表占用物理空间而视图不占用物理空间,视图只是逻辑概念的存在,表可以及时对它进行修改,但视图只能有创建的语句来修改
3、视图是查看数据表的一种方法,可以查询数据表中某些字段构成的数据,只是一些SQL语句的集合。从安全的角度说,视图可以不给用户接触数据表,从而不知道表结构
4、视图的建立和删除只影响视图本身,不影响对应的基本表
视图与数据变更
将表中的数据进行更新,再通过视图检索,可以看到视图的结果也同步发生了变化,因此,再次证明:视图不是表,不保存数据,只是一张虚拟表。
视图增删改数据操作
通常情况下,视图是可以更新的,更新一个视图将更新其基表。不是所有的视图都可以更新,视图更新必须遵循以下规则:
(1)若视图的字段是来自字段表达式或常数,则不允许对此视图执行INSERT、UPDATE操作,允许执行DELETE操作
(2)where不能包含子查询
(3)若视图的定义中有GROUP BY子句或聚集函数时,则此视图不允许更新
(4)若视图的定义中有DISTINCT任选项,则此视图不允许更新
(5)若视图是由两个以上的基表导出的,此视图不允许更新
所以,一般情况下,应该只将视图用于检索(SELECT),而不用于更新(INSERT,UPDATE,DELETE)。
不能在一张由多张关联表连接而成的视图上做同时修改两张表的操作
以下操作可以在视图上进行:
1、视图与表是一对一关系情况:如果没有其它约束(如视图中没有的字段,在基本表中是必填字段情况),是可以进行增删改数据操作
2、视图与表是一对多关系情况:如果只修改一张表的数据,且没有其它约束(如视图中没有的字段,在基本表中是必填字段情况),是可以进行改数据操作