八, Hive基础函数和窗口函数全解析
文章目录
- 八, Hive相关的函数
-
- 8.1 查看内置函数
- 8.2 常用系统内置函数
-
- 1. 空字段赋值(NVL(列名, default_value))
- 2. 流程控制结构(case..when...)
- 3. 行转列
- 4. 列转行
- 8.3 窗口函数
-
- 8.3.1 窗口函数概述
- 8.3.2 over子函数的基本写法
- 8.3.3 `聚合函数(sum, max, avg...)` + over子函数(partition by m,n... order by m,n...)
- 8.3.4 对窗口范围控制相关的函数和参数
-
- 8.3.4.1 lag和lead 函数
- 8.3.4.2 ntile函数
- 8.3.5 Rank() Denserank() 和 Row_number(), 排名相关的函数
-
- 8.3.5.1 rank, dense_rank, row_number 三者的区别
- 8.3.6 first_value(col) 和 last_value(col) 函数
- 8.3.7 cume_dist()
- 8.4 自定义函数
八, Hive相关的函数
8.1 查看内置函数
- 查看系统内置函数(hive> show functions;)
- 显示内置函数用法(hive> desc function xx;)
- 详细显示内置函数用法(hive> desc extended function xx;)
8.2 常用系统内置函数
1. 空字段赋值(NVL(列名, default_value))
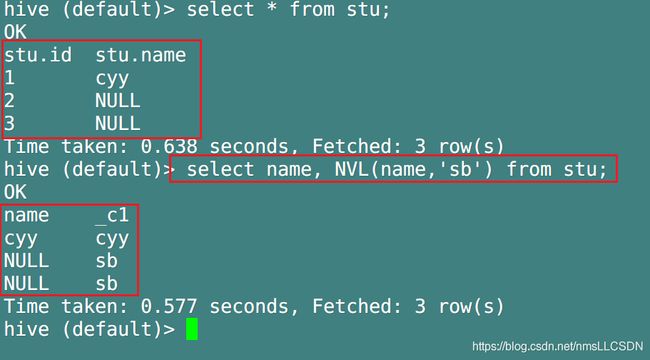
[函数说明]
NVL: 给某一列值为NULL的数据复制, 如果某一列的数据为NULL, 则赋值为default_value, 不为空则不变
[案例实操]
2. 流程控制结构(case…when…)
[写法]
case 列名
when 列名=? then 执行语句
when 列名=? then 执行语句
else 执行语句
end
[案例实操]

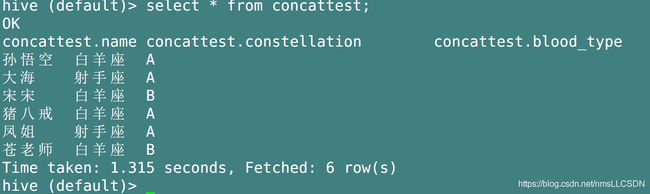
3. 行转列
[数据准备]
- 建表-导数据-查询
孙悟空 白羊座 A
大海 射手座 A
宋宋 白羊座 B
猪八戒 白羊座 A
凤姐 射手座 A
苍老师 白羊座 B
相关函数说明:
-
concat(列名/'字符串', 列名/'字符串')–> 返回输入字符串连接后的结果, 支持任意个输入字符串; -
concat_ws(separator, str1/col, str2/col,....)----> 是一个特殊形式的concat, 第一个参数是分隔符(separator),用来作为后面各个参数之间的分隔符, 若分隔符是null, 那么返回值也是null.此外, concat_ws中的所有参数必须是string/array类型.

-
collect_set(col), 只接受基本数据类型, 它的主要作用是将某列的值去重汇总(也就是把同一列的所有符合条件的字段转为一行数据输出,只接受基本数据类型, 它的主要作用是将某列的值去重汇总, 叫行转列), 产生Array类型字段.
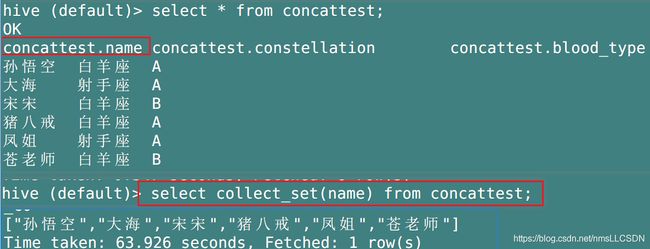
[案例实操]
- Q: 把星座(constellation)和血型(blood_type)一样的人归类到一起
### 子查询: 在查询了星座和血型结合体 和姓名的子查询基础上, 进一步查询
#####1. 对原有表进行处理, 题目要求星座和血型都相同的这一条件,
###我们可以把这两个列合为一列,
#####在这个查询出来的字表基础上进一步往下查询进而得到最终结果
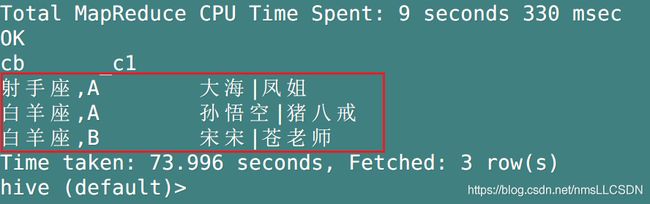
SELECT name, CONCAT_WS(',',constellation, blood_type)
FROM concattest;
#### 2. 在上一步查询结果基础上进行分组筛选, 并限定输出的格式, 所以最终答案如下:
SELECT cb, CONCAT_WS('|', collect_set(name))
FROM (
SELECT name, CONCAT_WS(',',constellation, blood_type) AS cb
FROM concattest
)ct_1
GROUP BY cb;
- 输出结果为:
题外话:
collect_set() 去重, collect_list() 不去重, 其他功能均相同.
对于行转列(多行name转为了一行name), hive的主要实现函数是collect_set, 对应于MySQL中的函数为:group_concat, 不过像上面这种 concat_ws(’-’, collect_set(col))没有效果. 对于普通的字符倒是可以用.
- 相关文章-- MySQL 列转行与行转列的写法
4. 列转行
相关函数说明
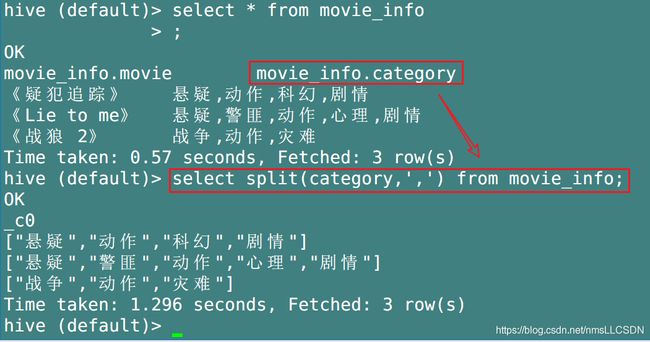
- split(str, regex): 将某列的值str按照给定的分隔符regex进行切分, 生成一个字符数组;
比如下面, 我们把category按照其分隔符’,'拆分出来, 生成了一个字符数组.
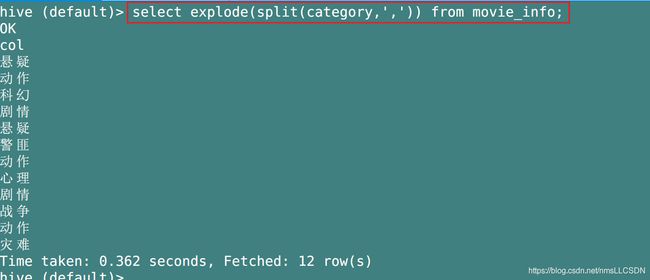
2. explode(col): 将一行的数据拆分为多行,它的参数col必须是map或array类型, 这个函数经常和split一起使用.
比如我们用explode处理上面split函数生成的category字符数组, 可以看到, 一行字符数组被拆分出了多行数据出来.
- 那么, 我们如何让movie字段跟explode处理后的字段进行一一对应呢? 注意: hive不支持下面的写法:

- lateral view :
- lateral view用于和split, explode等UDTF一起使用,它能够将一行数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。
- lateral view首先为原始表的每行调用UDTF,UTDF会把一行拆分成一或者多行,lateral view再把结果组合,产生一个支持别名表的虚拟表。
SELECT movie, movie_category
FROM movie_info
lateral VIEW explode(split(category, ',')) another_virtual_table AS movie_category;
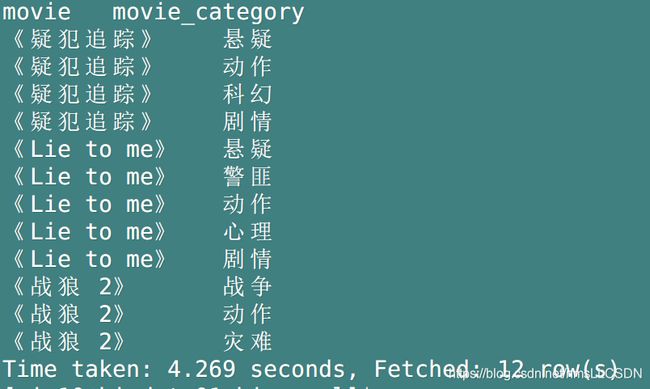
相关文章: 有关lateral view 更多的例子
8.3 窗口函数
平常我们使用 hive或者 mysql时,一般聚合函数用的比较多。但对于某些偏分析的需求,group by可能很费力,子查询很多,这个时候就需要使用窗口分析函数了~
8.3.1 窗口函数概述
-
Group By + 普通聚合函数(max, sum, avg)每个组只返回一条汇总记录, 而开窗函数则可以为设定
窗口中的每一行数据都返回一条相同记录, 如何设置窗口呢? 我们会在下面展开介绍. -
普通聚合函数聚合的行集是组, 开窗函数聚合的行集是窗口, 此外, 如果** Group By和开窗函数over()搭配的话, over()是把分组后的整个结果作为窗口的**!
-
(注意了, 由于Group BY + over()子函数, 处理的是分组后的数据, 即每一组分别处理, 以每一组为单位(窗口)输出, 所以我们要
从分组后的数据进行思考, 而不是想当然的去思考全表) -
对上面举例说明:
- 普通聚合函数(分组并分别统计每一个组内的成员个数(count), 每一组只输出这一个组的总个数)
select cookieid, count(cookieid)
from overtest
group by cookieid;
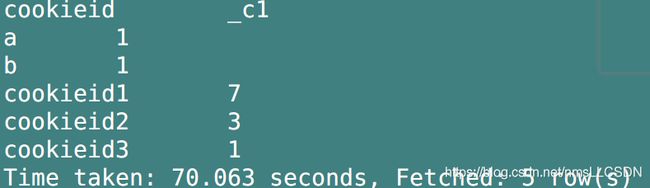
从上面的例子可以看到, 在普通聚合函数中, 对于每一组(cookieid相同的为一组), 我们只得到一个count(*)计数, 我们不会去考量每个组中具体的组成员.
- over函数例子1(用窗口函数求表中最大值)-
对窗口中的数据进行分析计算(count, sum,max ...),并以窗口为单位为窗口中的每一行都返回聚合后的数据
select pv, max(pv) over()
from overtest;
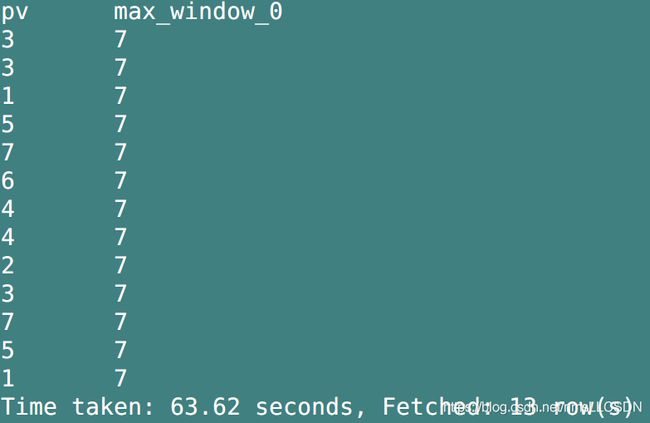
我们不在over()写任何东西, 那么over()就默认把查询出来的整个表作为一个窗口, 然后再进行聚合,并对应输出窗口中的每条数据.
- over函数例子2(用窗口函数求分组后的总行数)-(分组时使用over(), 是
以分组后的结果为一个窗口进行计算,然后聚合计算, 并对应输出窗口中的每一行数据.)
- 比如下面这个例子, 按cookieid进行分组后, 产生了五条数据, over()就会在这五条数据的基础上进行count(cookied)的运算, 并把运算结果5逐条对应输出.
select cookied, count(cookieid) over()
from overtest
group by cookieid

8.3.2 over子函数的基本写法
[开窗函数的基础结构]
分析函数(如: sum(), max(), row_number()...) + 窗口字句(over函数)
[over函数的写法]
over(partition by [column_n] order by [column_m])
## 比如, over(order by cookieid order by createtime), 现根据cookieid进行分区, 每个分区根据createtime字段排序(默认是升序)
over()括号里面的内容是用来限定窗口的范围, 不写范围的话就是表中所有的数据为一个窗口, 窗口中的每一行都要进行处理(如何处理? 看over()前面是哪一个聚合函数, 是count()就对窗口中的行数相加, 是sum()就对窗口中的每行数据进行相加)
官方文档- 关于partition by 和 order by 的各种写法和案例
案例实操:
- 创建表, 导入数据:
- overtest.txt
cookieid1,2017-12-10,1
cookieid1,2017-12-11,5
cookieid1,2017-12-12,7
cookieid1,2017-12-13,3
cookieid1,2017-12-14,2
cookieid1,2017-12-15,4
cookieid1,2017-12-16,4
cookieid2,2017-12-16,6
cookieid2,2017-12-12,7
cookieid3,2017-12-22,5
cookieid2,2017-12-24,1
a,2017-12-01,3
b,2017-12-00,3
- overtest表
CREATE TABLE overtest(
cookieid string,
createtime string,
pv int
)
row FORMAT delimited fields terminated BY ',';
LOAD data local inpath '/opt/module/data/hive-data/input/overtest.txt' INTO TABLE overtest;
over(partition by cookieid order by createtime)先根据cookieid字段分区,相同的cookieid分为一区,每个分区内根据createtime字段排序(默认升序),
简单来说,
over(partititon m order by n)意味着over()函数分区和排序后的一条数据就是一个窗口, 而over(partition)意味着分区后的若干条数据是一个窗口.
注:不加 partition by 的话则把整个数据集当作一个分区,不加 order by的话会对某些函数统计结果产生影响,如sum().
select cookieid, createtime, pv, sum(pv) over(partition by cookieid order by createtime)
from overtest;
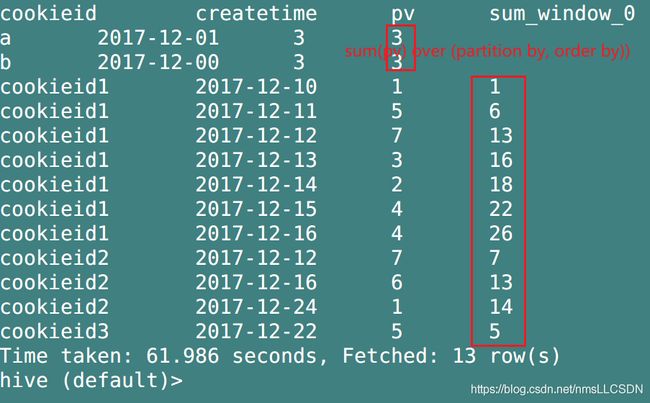
首先 PARTITION BY cookieid,根据cookieid分区,各分区之间默认根据字典顺序排序,ORDER BY createtime,指定的是每个分区内部的排序,默认为升序
我们可以清晰地看到,窗口函数和聚合函数的不同,sum()函数可以根据每一个窗口的每一行返回各自行对应的值,有多少行记录就有多少个sum值,而group by只能计算每一组的sum,每组只有一个值!
其中sum()计算的是分区内排序后一个个叠加的值,和order by有关!
- 如果不加order by 会怎么样:
select cookieid, createtime, pv, sum(pv) over(partition by cookieid)
from overtest;
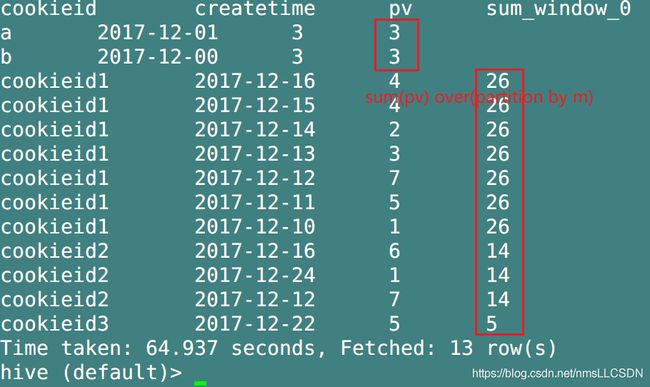
可以看到,如果没有order by,不仅分区内没有排序,sum()计算的pv也是整个分区的pv
注:max()函数无论有没有order by 都是计算整个分区的最大值
8.3.3 聚合函数(sum, max, avg...) + over子函数(partition by m,n… order by m,n…)
前面我们讨论了聚合函数+over子函数构成的窗口函数的用法, 下面我们直接上栗子来具体实践一下:
- 建表, 导入数据
数据表: business.txt
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,94
建表并导入数据
# 建表
CREATE TABLE business(
name string,
orderdate string,
cost int
)
row FORMAT delimited fields terminated BY ',';
load data local inpath '/opt/module/data/hive-data/input/business.txt' INTO TABLE business;
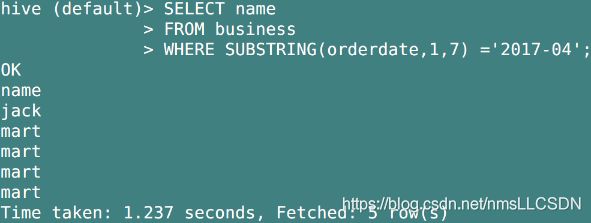
Q1:查询在 2017 年 4 月份购买过的顾客及总人数
- 我们从business表中取出2017年04月购买了商品的人的name;
- 如果我们按照姓名分组, 并对每一组累加行数, 这个显示结果是2017年4月每人购买商品的次数
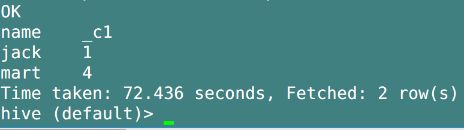
- 然而, 我们该如何求2017年4月总共有多少人购买了商品呢?
- 先按不同name进行分组

- 对分组后函数进行开窗函数处理, count(*) over(), 对按name分组后的所有行进行累加(count)处理
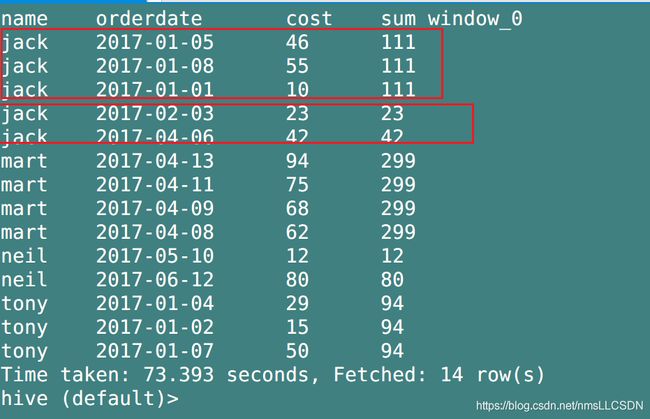
Q2: 查询顾客的购买明细及每个人每月的购买总额
SELECT name, orderdate, cost, sum(cost) OVER(partition BY name, MONTH(orderdate))
FROM business;
8.3.4 对窗口范围控制相关的函数和参数
| 函数/参数 | 说明和用法 |
|---|---|
| current row | 当前行 |
| n preceding | 往前n行数据,当前行与前n行数据做聚合 |
| n following | 往后n行数据, 当前行与后n行数据做聚合 |
| unbounded | 起点, 其中unbounded preceding表示从前面的起点开始, unbounded following表示到后面的终点 |
| lag(col, n, default_val) | 往前第n行数据 |
| lead(col, n, default_val) | 往后第n行数据 |
| ntile(n) | 把有序窗口的行分发到指定数据的组中, 各个组有编号, 编号从1开始, 对于每一行, ntile返回此行所属的组的编号. 注意: n必须为int类型 |
[栗子堆]
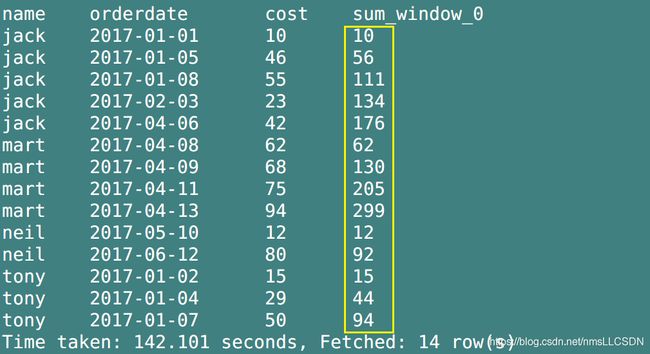
- 从开始到到当前行的数据(order by 默认的数据聚合方式)
When ORDER BY is specified with missing WINDOW clause, the WINDOW specification defaults to
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW.(只写order by 不限定 rows between … and … 代表从第一行到当前行进行聚合, 这也是前面我们看到使用order by orderdate那个例子中, sum(cost)出现递增相加的原因)

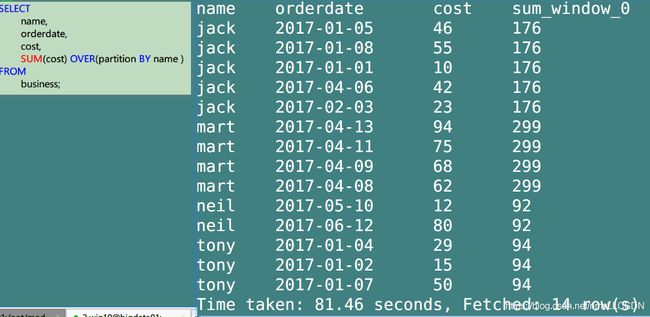
When both ORDER BY and WINDOW clauses are missing, the WINDOW specification defaults to
ROW BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING.(如果连order by都不写(只有一个partition by 分区), 那么默认就是每一行数据都是从窗口的开始到末尾聚合得到的.)
- 查询当前行的前三行到当前行的数据
rows between 3 preceding and current row
- 查询当前行的前1行到当前行的数据
SELECT
name,
orderdate,
cost,
SUM(cost) OVER(partition BY name, MONTH(orderdate) ORDER BY orderdate rows BETWEEN 1 preceding AND CURRENT row)
FROM
business;
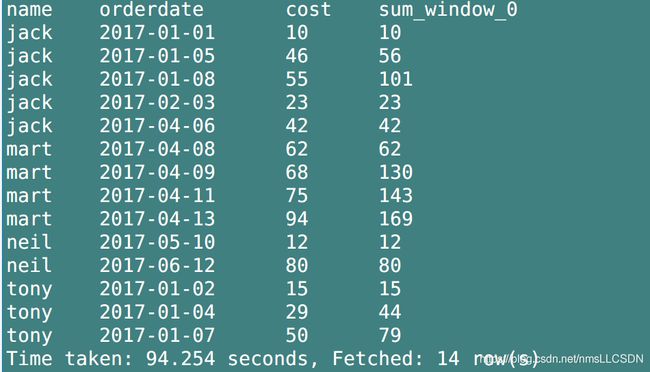
rows between 1 preceding and current, 表示当前行的前1行和当前行进行聚合((本例是前一行的cost与当前行相加得到当前行的cost, 当然了相加前提是两行同属于一个窗口中的数据)
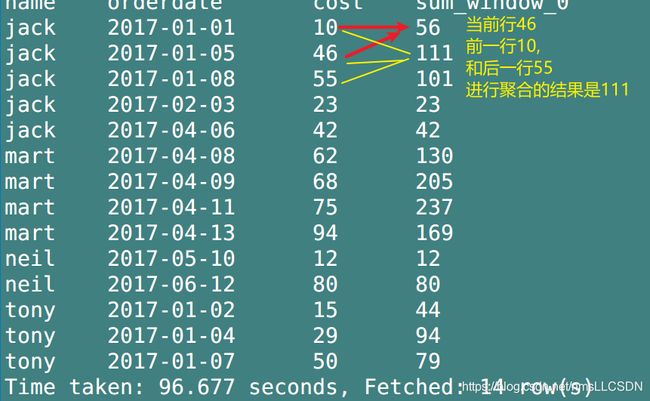
- 查询当前行的前1行及其后1行的数据
rows between 1 preceding and 1 following
SELECT
name,
orderdate,
cost,
SUM(cost) OVER(partition BY name, MONTH(orderdate) ORDER BY orderdate rows BETWEEN 1 preceding and 1 following)
FROM
business;
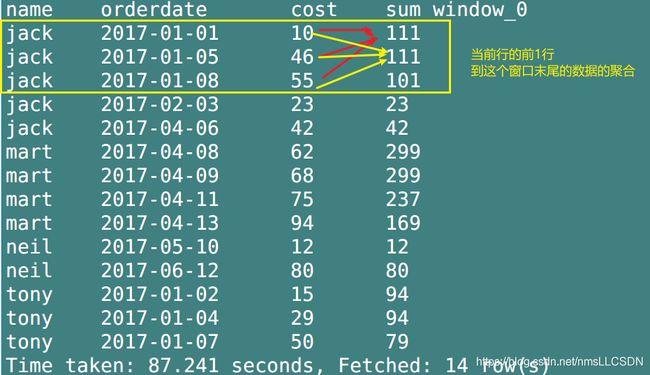
- 查询当前行前1数据到末尾的数据
rows between 1 preceding and unbounded following.
SELECT
name,
orderdate,
cost,
SUM(cost) OVER(partition BY name, MONTH(orderdate) ORDER BY orderdate rows BETWEEN 1 preceding and unbounded following)
FROM
business;
对窗口范围进行控制的总结:
- 无论是当前行的前多少行还是后多少行进行聚合, 请一定要记住这个前提:
聚合必须局限在每一个单独的窗口中!!!rows 必须跟在 order by 子句之后,对排序的结果进行限制,使用固定的行数来限制分 区中的数据行数量
8.3.4.1 lag和lead 函数
lag(col, n, fault), lag函数用于统计同一窗口内从当前行往上n行数据(肯定不会包含当前行的数据啦, 不然我们用 n preceding 都能代替这个函数了).第一个参数 col代表聚合的目标列
第二个参数代表往上n行
第三个参数是往上n行遇到null值显示的默认值, 不为空则不显示, 不写这个参数的话, 遇到空就显示null.
Q3: 查看顾客前一次的购买时间, 倒数第二次的购买时间.
select
name,
lag(ordertime, 1) over(partition by name order by ordertime) as lag1,
lag(ordertime, 2, '未购买') over(partition by name order by ordertime) as time2
from
business;
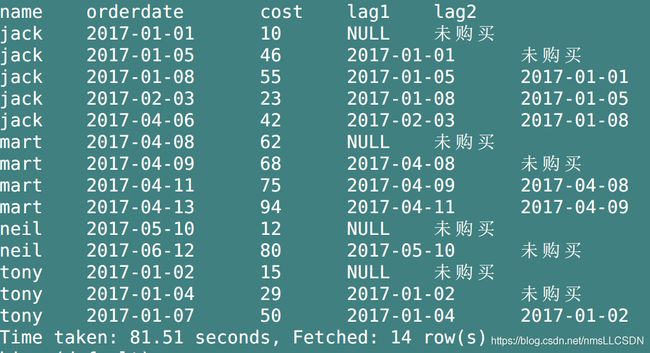
LEAD 函数则与 LAG 相反:LEAD(col,n,DEFAULT) 用于统计窗口内往下第n行值。第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL)
8.3.4.2 ntile函数
ntile(n) over(order by colm)
- 用于
将分组数据按照顺序(colm的顺序)切分为n片,返回当前的切片值- 如果切片不均匀, 默认会增加第一个切片的分布
- ntile 不支持 rows between …and…
用途: ntile主要用于取出前m%(或后…或中间…)的数据
Q4: 查询前20%时间的订单信息.
- 先切片,由于是前20%时间, 如果我们把时间切分为5片, 那么后期只需从其中取出第一片, 即为想要的结果
select
name,
orderdate,
cost,
ntile(5) over(order by orderdate) as split
from
business;
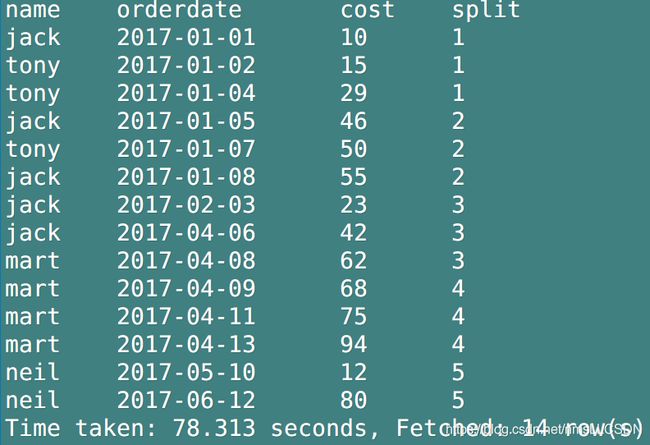
- 从切片后生成的表中取出第一号切片(
之所以这样称呼, 是因为**每一块切片中的数据行数是不固定的**, 我们不关心行数有多少, 只需要取出5块切片中的属于第一片的数据, 自然就是前20%的数据)
select
name,
orderdate,
cost
from(
select
name,
orderdate,
cost,
ntile(10) over(order by orderdate) as split
from
business
)splits
where splits.split=1 and ;

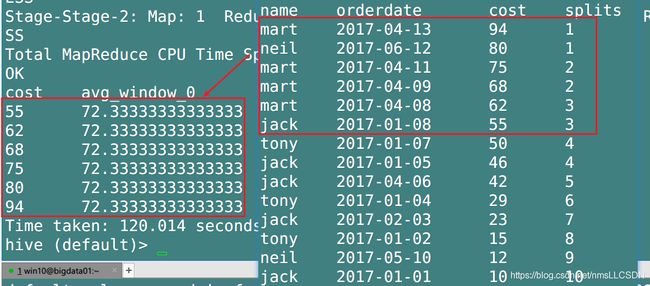
Q4: 查询前30%花费的平均值.
- 切片30% 10片
select
name,
orderdate,
cost,
ntile(10) over(order by cost desc) as splits
from
business;
- 取出三片求平均值
select
cost,
avg(cost) over()
from(
select
name,
orderdate,
cost,
ntile(10) over(order by cost desc) as splits
from
business
)t1
where t1.splits in (1,2,3);
8.3.5 Rank() Denserank() 和 Row_number(), 排名相关的函数
- 准备数据 score.txt
孙悟空,语文,87
孙悟空,数学,95
孙悟空,英语,68
大海,语文,94
大海,数学,56
大海,英语,84
宋宋,语文,64
宋宋,数学,86
宋宋,英语,84
婷婷,语文,65
婷婷,数学,85
婷婷,英语,78
- 建表 score
create table score(
name string,
subject string,
score int
)
row format delimited fields terminated by ',';
load data local inpath '/opt/module/data/hive-data/input/score.txt' into table score;
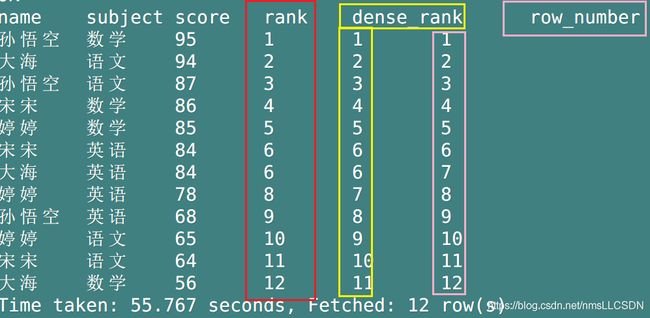
8.3.5.1 rank, dense_rank, row_number 三者的区别
[举例说明]
- 三者的简单对比:
select
name,
subject,
score,
rank() over(partition by subject order by score desc) rank,
dense_rank() over(partition by subject order by score desc) dense_rank,
row_number() over(partition by subject order by score desc) row_number
from
score;
[总结]
- 三者
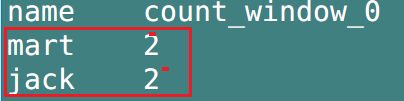
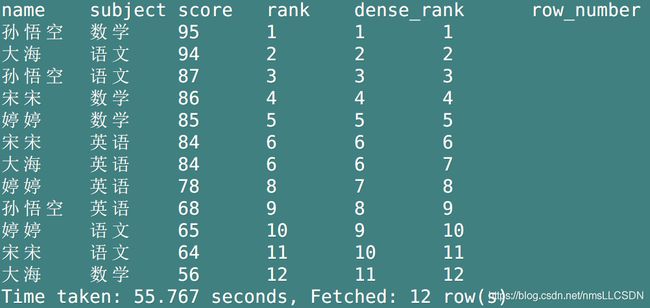
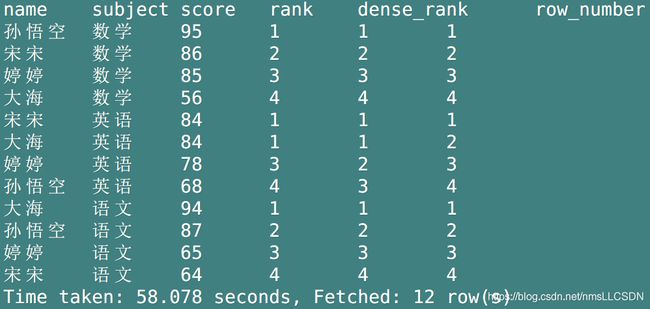
都是对每一个窗口内已经排好序的每一行数据进行计数, - 区别在于:
- row_number在窗口内从1到2…
连续计数, 什么都不用考虑. - rank在窗口内
连续计数, 但是遇到重复的会出现相同计数, 继续往下的计数会加上+重复的次数,窗口内的数据总数不会改变 - dense_rank在窗口内
连续计数,遇到重复的数据也会出现相同计数, 继续往下的计数从上次重复的数+1,窗口内的数据总数会减去重复的个数
- 由下图, 可见, row_number连续计数,不考虑重复;
- rank遇到重复出现相同计数, 继续往下的计数从上次重复的数+重复的次数(>1), 因此窗口的数据总数不变;
- dense_rank遇到重复出现相同计数, 继续往下的计数从上次重复的数+1(连续), 窗口的数据会比数据综述减少重复次数个.
[案例实操]
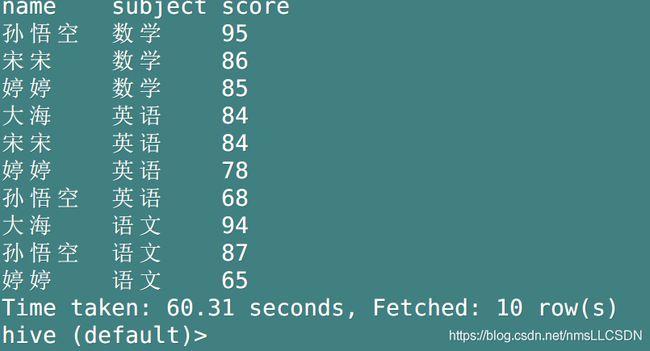
Q: 求出每门学科前三名的学生
- 需要使用一个嵌套查询, 子查询是窗口函数, 求出每门学科下学生分数由高到低的一个结果
- 外部查询是对每门学科(即每个窗口)下输出结果的一个限定
- 子查询
select
name,
subject,
score,
dense_rank() over(partition by subject order by score desc)
from
score;
- 最终结果
select
name,
subject,
score
from(
select
*,
dense_rank() over(partition by subject order by score desc) rk
from
score
)t1
where rk <=3;
8.3.6 first_value(col) 和 last_value(col) 函数
first_value 取分组内排序后, 截止到当前行, 第一个值
select
name,
subject,
score,
first_value(score) over(partition by subject order by score desc) as first_val_in_window
from
score;
LAST_VALUE 函数则相反:LAST_VALUE 取分组内排序后,截止到当前行,最后一个值。
这两个函数还是经常用到的(往往和排序配合使用),比较实用!
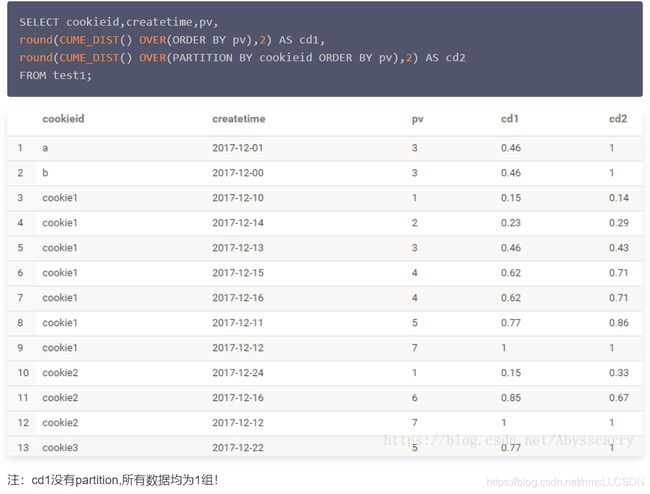
8.3.7 cume_dist()
cume_dist 返回小于等于当前值的行数/分组内总行数。
比如,我们可以统计小于等于当前薪水的人数,所占总人数的比例。
8.4 自定义函数
