【AI视野·今日CV 计算机视觉论文速览 第184期】Thu, 28 May 2020
AI视野·今日CS.CV 计算机视觉论文速览
Thu, 28 May 2020
Totally 52 papers
上期速览✈更多精彩请移步主页

Interesting:
***AutoSweep 从单张图像中获取可编辑的三维目标, (from 上海科技大学)
假设大多数人造物体可以通过基本几何体构建。首先通过GeoNet获取目标的语义mask标签,随后通过扫描识别出的轮廓来识别轮廓与主体的关系,并优化mask与几何体间的匹配关系,最终生成出带有纹理的三维模型。

使用GeoNet从输入图像获取cuboid profile, cuboid body, cylinder profile, and cylinder body四种类型的实例mask。右图是本文中用于仿真的三维形状。




code and datasets
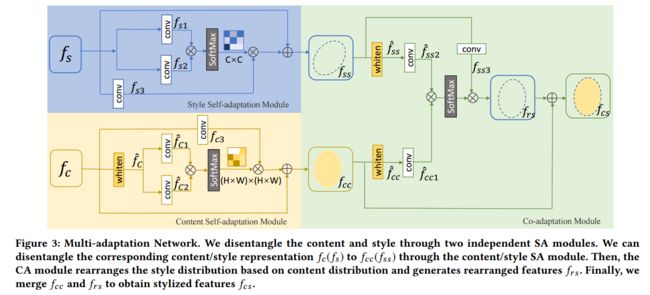
任意风格的图像迁移, 提出了一种基于自适应模块与协作适应模块来对特征进行解构和重构实现了更为高质量的图像风格迁移。(from: 中科院大学与模式识别国家重点实验室,ACM MM ’20)

多适应网络的细节:

lab
基于Yolov3的高速高精度实例分割, 将yolo中的检测头替换成了更高分辨的输出map(from University of Ostrava 捷克)


Daily Computer Vision Papers
| 4D Visualization of Dynamic Events from Unconstrained Multi-View Videos Authors Aayush Bansal, Minh Vo, Yaser Sheikh, Deva Ramanan, Srinivasa Narasimhan 我们提出了一种数据驱动的方法,用于通过手持多个摄像机捕获的视频对动态事件进行4D时空可视化。我们方法的关键是使用特定于场景的自我监督神经网络来构成事件的静态和动态方面。尽管从离散的角度捕获了该模型,但该模型使我们能够在事件的时空范围内连续移动。通过此模型,我们可以创建虚拟摄像机,以促进1冻结时间和浏览视图2冻结视图并随时间移动以及3同时更改时间和视图。如果给定视图在其他视图中可见,我们还可以编辑视频并显示被遮挡的对象。我们验证了我们使用多达15部移动摄像机捕获的野外活动中挑战的方法。 |
| Improve bone age assessment by learning from anatomical local regions Authors Dong Wang, Kexin Zhang, Jia Ding, Liwei Wang 骨骼年龄评估BAA作为一项重要的影像学检查,旨在评估人体骨骼的生物学和结构成熟度。在临床实践中,Tanner和Whitehouse TW2方法是放射科医生执行BAA的一种广泛使用的方法。 TW2方法将手分成感兴趣区域ROI,并分别分析每个解剖ROI以估计骨骼年龄。由于考虑了对本地信息的分析,TW2方法在实践中显示出准确的结果。遵循TW2的精神,我们提出了一种称为“解剖局部感知网络ALA网络”的新颖模型,用于自动骨龄评估。在ALA Net中,引入了解剖局部提取模块以学习手的结构并提取局部信息。此外,我们设计了解剖补丁训练策略,以在训练过程中提供额外的正则化。我们的模型可以以端对端的方式检测解剖ROI,并共同估算骨骼年龄。实验结果表明,我们的ALA Net在公开的RSNA数据集上实现了3.91平均绝对误差MAE的最新单模型性能。由于我们模型的设计与公认的TW2方法完全一致,因此对于临床使用而言,它是可解释且可靠的。 |
| Center3D: Center-based Monocular 3D Object Detection with Joint Depth Understanding Authors Yunlei Tang, Sebastian Dorn, Chiragkumar Savani 仅给定单眼RGB图像,在3D空间中定位对象并了解其相关3D属性是一项挑战。透视投影期间深度信息的丢失使情况更加复杂。我们提出了Center3D,这是一种无锚的一级方法,仅使用单眼RGB图像即可有效地估计3D位置和深度。通过利用2D和3D中心之间的差异,我们能够一致地估计深度。与单独使用每种方法相比,Center3D结合使用分类和回归来更可靠地了解隐藏的深度信息。我们的方法采用两种联合方法:1 LID为分类主导的方法,具有顺序线性递增离散化。 2 DepJoint回归主导的方法,具有多个用于深度估计的本征变换。通过对中等物体的KITTI数据集进行评估,Center3D将BEV中的AP从29.7提高到42.8,将3D中的AP从18.6提高到39.1。与先进的检测器相比,Center3D在实时单眼目标检测中取得了最佳的速度精度折衷。 |
| AVGZSLNet: Audio-Visual Generalized Zero-Shot Learning by Reconstructing Label Features from Multi-Modal Embeddings Authors Pratik Mazumder, Pravendra Singh, Kranti Kumar Parida, Vinay P. Namboodiri 在本文中,我们解决了多模态环境下的广义零镜头学习问题,在该模式下,我们在测试过程中拥有新颖的音频视频类别,而在培训过程中却没有看到。我们证明了将音频和视频嵌入投影到类标签文本特征空间可以使我们将文本嵌入的语义相关性用作零镜头学习的一种方法。重要的是,即使在测试时缺少模态,我们的多模零击学习方法也可以工作。我们的方法利用了交叉模式解码器,该模式强制执行以下约束:可以从数据点的音频和视频嵌入中重建类标签文本特征,以便在多模式零镜头学习任务中更好地执行任务。我们使用KL发散损耗进一步减小了音频和视频嵌入分布之间的差距。我们在零镜头分类和检索任务上测试了我们的方法,并且在存在单一模态以及存在多种模态的情况下,该方法的性能要优于其他模型。 |
| Weakly Supervised Vessel Segmentation in X-ray Angiograms by Self-Paced Learning from Noisy Labels with Suggestive Annotation Authors Jingyang Zhang, Guotai Wang, Hongzhi Xie, Shuyang Zhang, Ning Huang, Shaoting Zhang, Lixu Gu 通过卷积神经网络CNN在X射线血管造影中对冠状动脉进行分割是有希望的,但由于需要对大量训练图像中的所有像素进行精确注释而受到限制,这非常费力,尤其是对于复杂的冠状动脉树。为了减轻注释者的负担,我们提出了一种新型的弱监督训练框架,该框架从自动血管增强产生的嘈杂伪标签中学习,而不是从通过完全手动注释获得的准确标签中学习。典型的自定进度学习方案用于使训练过程对标签噪声具有鲁棒性,同时受到伪标签中的系统偏差的挑战,从而导致CNN在测试时的性能下降。为了解决这个问题,我们提出了一种注释提炼自定进度学习框架AR SPL,以使用提示性注释来纠正潜在的错误。不仅基于训练中的CNN,还基于直接从原始数据得出的冠状动脉的几何特征,提出了详细的模型血管不确定性估计值,以实现建议性注释的最小注释成本。实验表明,我们提出的框架与完全监督学习的框架具有1个可比的准确性,也大大优于其他弱监督学习框架。2大大降低了注释成本,即节省了75.18的注释时间,并且仅需要对3.46的图像区域进行注释和3高效的干预流程,以更少的人工交互即可实现卓越的性能。 |
| GSTO: Gated Scale-Transfer Operation for Multi-Scale Feature Learning in Pixel Labeling Authors Zhuoying Wang, YongtaoWang, Zhi Tang, Yangyan Li, Ying Chen, Haibin Ling, Weisi Lin 现有的基于CNN的像素标记方法在很大程度上依赖于多尺度特征,以满足语义理解和细节保存的要求。现有技术的像素标记神经网络广泛地利用了常规的尺度转换操作,即,上采样和下采样以学习多尺度特征。在这项工作中,我们发现这些运算会导致尺度混淆特征和次优性能,因为它们是空间不变的,并且无需空间选择即可直接跨尺度传递所有特征信息。为了解决此问题,我们建议使用门控比例尺转换操作GSTO来将空间滤波特征正确过渡到另一个比例尺。特别是,GSTO可以在有或没有额外监督的情况下工作。无监督的GSTO是从特征本身中学习的,而受监督的GSTO是由受监督的概率矩阵指导的。两种形式的GSTO都很轻巧,即插即用,可以灵活地集成到网络或模块中,以学习更好的多尺度功能。特别是,通过将GSTO插入HRNet,我们获得了功能更强大的主干,即GSTO HRNet,用于像素标记,它在COCO基准(用于人体姿势估计)和其他语义分割基准(包括Cityscapes,LIP和Pascal上下文,具有可忽略的额外计算成本。此外,实验结果表明,GSTO还可以显着提高PPM和ASPP等多尺度特征聚合模块的性能。代码将在以下位置提供 |
| NDD20: A large-scale few-shot dolphin dataset for coarse and fine-grained categorisation Authors Cameron Trotter, Georgia Atkinson, Matt Sharpe, Kirsten Richardson, A. Stephen McGough, Nick Wright, Ben Burville, Per Berggren 我们介绍了Northumberland Dolphin Dataset 2020 NDD20,这是一个具有挑战性的图像数据集,注释了粗糙和精细的实例分割和分类。此数据集是NDD的第一个发行版,是为了响应计算机视觉迅速扩展到保护研究和生产适用于极端环境条件(很少有开源数据集的区域)的现场可部署系统而产生的。 NDD20包含大量的两种不同海豚物种的水上和水下图像,用于传统的粗粒和细粒分割。 NDD20中包含的所有数据都是通过在英国诺森伯兰郡海岸线附近的北海通过手工收集获得的。我们目前使用标准的深度学习网络架构(通过NDD20训练)进行实验,并报告基准结果。 |
| Tackling the Problem of Large Deformations in Deep Learning Based Medical Image Registration Using Displacement Embeddings Authors Lasse Hansen, Mattias P. Heinrich 尽管基于深度学习的医学图像配准目前开始显示出可喜的进展,但通常在配准准确性方面仍落后于传统框架。对于存在较大变形的应用尤其如此,例如患者间腹部MRI的配准或吸气以呼出CT肺的配准。当前大多数作品都使用类似U Net的体系结构,以在不同的有监督和无监督设置下,根据输入图像预测密集位移场。我们认为,即使使用多级策略,U Net体系结构本身也会在一定程度上限制预测大变形的能力,因此提出了一种新颖的方法,其中将输入图像映射到位移空间中,并根据该嵌入来重建最终配准。吸气呼出CT肺的实验表明,我们的体系结构能够通过网络预测单个向前路径中的大变形,从而导致2mm以下的误差。 |
| Joint Learning of Vessel Segmentation and Artery/Vein Classification with Post-processing Authors Liangzhi Li, Manisha Verma, Yuta Nakashima, Ryo Kawasaki, Hajime Nagahara 视网膜成像是诊断各种疾病的宝贵工具。然而,即使对于有经验的专家而言,读取视网膜图像也是一项困难且耗时的任务。自动化视网膜图像分析的基本步骤是血管分割和动脉静脉分类,可提供有关潜在疾病的各种信息。为了提高现有的用于视网膜图像分析的自动化方法的性能,我们提出了两步血管分类。我们采用基于UNet的模型SeqNet来从背景中准确分割血管,并对血管类型进行预测。我们的模型按顺序进行细分和分类,从而减轻了标签分配偏差的问题并促进了训练。为了进一步细化分类结果,我们考虑船只之间的结构信息对它们进行后期处理,以向周围船只传播高度可信的预测。我们的实验表明,对于DRIVE数据集,该方法可以将AUC的分割精度提高到0.98,分类的精度提高到0.92。 |
| AutoSweep: Recovering 3D Editable Objectsfrom a Single Photograph Authors Xin Chen, Yuwei Li, Xi Luo, Tianjia Shao, Jingyi Yu, Kun Zhou, Youyi Zheng 本文提出了一种全自动框架,可直接从单张照片中提取可编辑3D对象。与以前的恢复深度图,点云或网格曲面的方法不同,我们的目标是恢复具有语义部分并可以直接编辑的3D对象。我们的工作基于这样一个假设:大多数人造物体都是由零件组成的,而这些零件可以由广义基元很好地表示。我们的工作试图恢复两种原始形状的对象,即广义长方体和广义圆柱体。为此,我们建立了一个新颖的实例感知分割网络,以实现精确的零件分离。我们的GeoNet输出一组标记为轮廓和实体的平滑零件级蒙版。然后在关键阶段,我们同时识别轮廓主体关系,并通过沿其轮廓扫掠已识别的轮廓来恢复3D零件,并共同优化几何形状以与恢复的蒙版对齐。定性和定量实验表明,我们的算法可以恢复高质量的3D模型,并且在实例分割和3D重建方面均优于现有方法。可从https chenxin.tech AutoSweep.html获得AutoSweep的数据集和代码。 |
| Iteratively Optimized Patch Label Inference Network for Automatic Pavement Disease Detection Authors Wenhao Tang, Qiming Zhao, Sheng Huang, Ren Li, Luwen Huangfu 我们提出了一种新颖的深度学习框架,称为迭代优化补丁标签推理网络IOPLIN,可自动检测各种路面疾病,而不仅限于特定的疾病,例如裂缝和坑洼。通过使用“期望最大化启发式斑块标签蒸馏EMIPLD”策略,可以仅对图像标签进行IOPLIN迭代训练,并通过从路面图像中推断出斑块标签来很好地完成此任务。与最先进的单分支CNN模型(例如GoogLeNet和EfficientNet)相比,IOPLIN具有许多理想的属性。它能够处理任何分辨率的图像,并充分利用图像信息,特别是对于高分辨率图像。而且,它可以粗略地定位路面遇险,而无需在训练阶段使用任何先前的定位信息。为了更好地评估我们的方法在实践中的有效性,我们构建了一个名为CQU BPDD的大规模沥青路面疾病检测数据集,该数据集包含60059张高分辨率路面图像,这些图像是在不同时间,不同地区采集的。该数据集上的大量结果证明,在自动路面疾病检测中,IOPLIN优于现有的图像分类方法。 |
| Accelerating Neural Network Inference by Overflow Aware Quantization Authors Hongwei Xie, Shuo Zhang, Huanghao Ding, Yafei Song, Baitao Shao, Conggang Hu, Ling Cai, Mingyang Li 深度神经网络固有的繁重计算阻止了它们的广泛应用。加速模型推断的一种广泛使用的方法是量化,方法是使用定点值替换网络的输入操作数。然后,大多数计算成本集中在整数矩阵乘法累加上。实际上,高位累加器导致部分浪费的计算,而低位累加器通常遭受数值溢出。为了解决这个问题,我们提出了一种通过设计可训练的自适应不动点表示来了解溢出的量化方法,以优化每个输入张量的位数,同时在计算过程中禁止数值溢出。利用所提出的方法,我们能够充分利用计算能力来最小化量化损失并获得优化的推理性能。为了验证我们方法的有效性,我们分别在ImageNet,Pascal VOC和COCO数据集上进行图像分类,对象检测和语义分割任务。实验结果表明,所提出的方法可以与现有的量化方法实现可比的性能,同时将推理过程加速约2倍。 |
| Poly-YOLO: higher speed, more precise detection and instance segmentation for YOLOv3 Authors Petr Hurtik, Vojtech Molek, Jan Hula, Marek Vajgl, Pavel Vlasanek, Tomas Nejezchleba 我们提供了性能更好的YOLO新版本,并扩展了名为Poly YOLO的实例细分。 Poly YOLO建立在YOLOv3的原始思想的基础上,消除了它的两个弱点,包括大量的重写标签和无效的锚分配。 Poly YOLO通过使用阶梯式上采样通过超列技术聚合轻型SE Darknet 53主干的特征,从而减少了问题,并产生了高分辨率的单标度输出。与YOLOv3相比,Poly YOLO仅有60个可训练参数,但mAP却提高了40倍。我们还展示了具有更少参数和更低输出分辨率的Poly YOLO lite。它具有与YOLOv3相同的精度,但它的体积小三倍,速度快两倍,因此适用于嵌入式设备。最后,Poly YOLO使用边界多边形执行实例分割。训练网络以检测在极坐标网格上定义的尺寸无关的多边形。预测每个多边形的顶点具有可信度,因此Poly YOLO生成具有不同数量顶点的多边形。 |
| Zoom in to the details of human-centric videos Authors Guanghan Li, Yaping Zhao, Mengqi Ji, Xiaoyun Yuan, Lu Fang 呈现高分辨率HR人的外观对于以人为本的视频始终至关重要。但是,当前的成像设备几乎无法始终捕获HR详细信息。现有的超分辨率算法仅通过考虑图像补丁的通用优先级和低优先级就无法缓解该问题。相反,我们的算法通过利用HR人的外观定义的高级优先级,偏向于人体超分辨率。首先,运动分析模块从HR参考视频中提取固有运动模式,以改进低分辨率LR序列的姿态估计。此外,人体重建模块将参考帧中的HR纹理映射到3D网格模型上。因此,以原始LR视频以及少量HR参考帧为条件,生成输入的LR视频得到超分辨的HR人为序列。对现有数据集和混合摄像头捕获的现实世界数据进行的实验表明,与传统方法相比,我们的方法可产生出色的人体视觉质量。 |
| Arbitrary Style Transfer via Multi-Adaptation Network Authors Yingying Deng, Fan Tang, Weiming Dong, Wen Sun, Feiyue Huang, Changsheng Xu 任意样式转移是一个具有研究价值和应用前景的重要课题。考虑到内容图像和参考样式画,所需的样式转移将使内容图像具有样式画的色调和生动的笔触样式,同时保持样式详细的内容结构信息。常见的样式转移方法是先学习内容和样式参考的内容和样式表示,然后生成由这些样式引导的风格化图像 |
| Concurrent Segmentation and Object Detection CNNs for Aircraft Detection and Identification in Satellite Images Authors Damien Grosgeorge SAS , Maxime Arbelot SAS , Alex Goupilleau SAS , Tugdual Ceillier SAS , Renaud Allioux SAS 在卫星图像中检测和识别对象是一项非常具有挑战性的任务,感兴趣的对象通常很小,即使使用非常高分辨率的图像也可能难以识别特征。对于大多数应用,这意味着在召回率和精度之间进行权衡。我们在这里提出了一种专用的方法来检测和识别飞机,它结合了两个非常不同的卷积神经网络CNN,基于改进的U网络架构的分割模型和基于RetinaNet架构的检测模型。我们目前的结果表明,这种组合明显优于每个单一模型,从而大大降低了假阴性率。 |
| Extrapolative-Interpolative Cycle-Consistency Learning for Video Frame Extrapolation Authors Sangjin Lee, Hyeongmin Lee, Taeoh Kim, Sangyoun Lee 视频帧外推是在给出过去帧时预测未来帧的任务。与以前通常专注于模块设计或网络构建的研究不同,我们提出了一种使用预训练帧内插模块的新型外推内插循环EIC损失,以提高外推性能。循环一致性损失已用于许多视觉任务中两个功能空间之间的稳定预测。我们使用两个映射函数框架外推和内插来公式化此循环一致性。由于就物体遮挡和运动不确定性而言,预测中间帧比预测未来帧要容易,因此插值模块可以有效地提供指导信号,以训练外推功能。 EIC损失可应用于任何现有的外推算法,并保证在不久的将来以及将来的长帧中进行一致的预测。实验结果表明,简单地将EIC损失添加到现有基准中,可以提高UCF101和KITTI数据集的外推性能。 |
| TIME: Text and Image Mutual-Translation Adversarial Networks Authors Bingchen Liu, Kunpeng Song, Yizhe Zhu, Gerard de Melo, Ahmed Elgammal 针对文本到图像T2I的生成,我们提出了文本和图像互译对抗网络TIME,这是一个轻量级但有效的模型,可以在生成对抗网络框架下共同学习T2I生成器G和图像字幕鉴别器D。尽管以前的方法将T2I问题作为单向任务解决,并使用预先训练的语言模型来增强图像文本的一致性,但是TIME既不需要额外的模块,也不需要预先训练。我们表明,通过与D作为语言模型一起训练G,可以大大提高G的性能。具体来说,我们采用Transformers对图像特征与词嵌入之间的交叉模式连接进行建模,并设计一个铰链式和退火条件式损失,以动态平衡对抗性学习。在我们的实验中,TIME在CUB数据集上建立了最先进的初始得分4.88,并在文本到图像和图像字幕任务上显示了MS COCO的竞争性能。 |
| Learning to segment from misaligned and partial labels Authors Simone Fobi, Terence Conlon, Jayant Taneja, Vijay Modi 为了大规模地提取信息,研究人员越来越多地将语义分割技术应用于遥感图像。虽然完全监督的学习可以进行精确的像素分割,但是编译所需的详尽数据集通常会非常昂贵。结果,许多非城市环境都缺乏准确分割所需的基本事实。这些区域的现有开源基础设施数据可能不准确且不完整。诸如OpenStreetMaps OSM之类的开源基础结构注释可代表此问题,而OSM标签可提供有关道路和建筑足迹的全局信息,嘈杂的和部分注释会限制从中学习的分割算法的性能。在本文中,我们提出了一种新颖且可推广使用的两阶段框架,该框架能够在给定未对齐和缺少注释的情况下改善像素级图像分割。首先,我们引入Alignment Correction Network纠正不正确注册的开源标签。接下来,我们演示一种指针分割网络的分割模型,该模型使用校正后的标签来预测基础设施的占用空间,尽管缺少注释。我们在AIRS数据集上测试顺序性能,更重要的是,联合得分的平均交集为0.79,随着我们减少现有注释的比例,模型性能保持稳定。我们通过将比对校正网络应用于OSM标签来校正建筑物的占地面积,证明了我们方法对低质量数据的可移植性,同时,我们还展示了指针分割网络根据中分辨率数据预测加利福尼亚农田边界的准确性。总体而言,我们的方法对于存在各种数量的训练数据的多种应用程序是可靠的,从而提供了一种从嘈杂的部分数据中提取可靠信息的方法。 |
| Generative Adversarial Networks (GANs): An Overview of Theoretical Model, Evaluation Metrics, and Recent Developments Authors Pegah Salehi, Abdolah Chalechale, Maryam Taghizadeh 统计信号处理和机器学习中最重大的挑战之一是如何获得一个可以生成大规模数据分布样本(例如图像和语音)的生成模型。生成对抗网络GAN是解决此问题的有效方法。 GAN提供了一种学习深度表示的合适方法,而无需广泛使用带标签的训练数据。这种方法在无需对概率密度函数PDF进行精确建模的情况下就可以生成大量数据,因此吸引了许多计算机视觉研究人员的注意力。在GAN中,生成模型是通过竞争过程估算的,在该过程中,生成器和鉴别器网络同时受到训练。生成器学习生成合理的数据,鉴别器学习将生成器创建的假数据与真实数据样本区分开。考虑到GAN在过去几年中的快速增长及其在各个领域的应用,有必要对这些网络进行准确的调查。本文在介绍了GAN的主要概念和理论之后,比较了两种新的深度生成模型,并解释了文献中使用的评估指标以及GAN的挑战。此外,对最杰出的GAN架构进行了分类和讨论。最后,研究了计算机视觉中的基本应用。 |
| False Positive Removal for 3D Vehicle Detection with Penetrated Point Classifier Authors Sungmin Woo, Sangwon Hwang, Woojin Kim, Junhyeop Lee, Dogyoon Lee, Sangyoun Lee 最近,研究人员一直在利用LiDAR点云来提高3D车辆检测的准确性。大多数现有技术方法都是基于深度学习的,但很容易受到对象上生成的点数的影响。此漏洞会导致在较高召回率的位置出现许多误报框,在这些位置偶尔会以很少的分数预测对象。为了解决这个问题,我们基于不能在车辆后方生成点的LiDAR的基础属性引入了穿透点分类器PPC。它确定在预测框的车辆后面是否存在点,如果存在,则将该框区分为假阳性。我们在KITTI数据集上评估了我们直接但前所未有的方法,并提高了PointRCNN的性能,这是最先进的方法之一。实验结果表明,在中等和困难程度的汽车上,最高召回位置的精度分别显着提高了15.46个百分点和14.63个百分点。 |
| SSM-Net for Plants Disease Identification in LowData Regime Authors Shruti Jadon 植物病害检测是提高农业产量的必要步骤。由于难以检测疾病,农民将各种形式的农药喷洒在农作物上以保存它们,从而对农作物生长和食品标准造成危害。深度学习可以帮助发现此类疾病。但是,收集有关特定植物物种的各种疾病的大量数据非常不便。在本文中,我们提出了一种基于新指标的少击学习SSM网络体系结构,该体系结构由堆叠的暹罗和匹配的网络组件组成,以解决低数据状态下的疾病检测问题。我们展示了使用SSM网络堆叠式暹罗匹配方法,我们能够实现更好的决策边界和94.3的准确性,与使用传统的转移学习方法VGG16和Xception net相比增加了5,而与原始匹配网络相比增加了3。此外,我们使用SSM Net能够获得0.90的F1分数,比使用转移学习的0.30和使用原始匹配网络的0.80有所提高。 |
| PAI-Conv: Permutable Anisotropic Convolutional Networks for Learning on Point Clouds Authors Zhongpai Gao, Guangtao Zhai, Junchi Yan, Xiaokang Yang 在许多3D计算机视觉应用中,对点云上有效表示学习的需求正在增长。卷积神经网络CNN在图像分析方面的最新成功表明,将CNN的洞察力应用于点云的价值。但是,与欧几里德结构化的图像不同,点云是不规则的,因为每个点的相邻点之间都不同。已经开发出了使用各向同性滤波器或应用加权矩阵来克服点云上结构不一致的各种点神经网络。但是,各向同性滤波器或加权矩阵会限制表示功率。在本文中,我们提出了一种可置换各向异性卷积运算PAI Conv,它根据球体表面上一组均匀分布的核点为每个点计算软置换矩阵,并像CNN一样执行共享各向异性滤波器。 PAI Conv具有物理意义,可以有效地与随机点采样方法配合使用。全面的实验表明,与最先进的方法相比,PAI Conv在分类和语义分割任务中产生了竞争性结果。 |
| Robust Trajectory Forecasting for Multiple Intelligent Agents in Dynamic Scene Authors Yanliang Zhu, Dongchun Ren, Mingyu Fan, Deheng Qian, Xin Li, Huaxia Xia 动态场景中多个交互代理的轨迹预测或轨迹预测对于许多应用(例如机器人系统和自动驾驶)是一个重要问题。由于代理之间的复杂交互以及它们与周围场景的交互,这个问题是一个巨大的挑战。在本文中,我们提出了一种用于动态场景中多个智能主体的鲁棒轨迹预测的新方法。所提出的方法由三个主要的相互关联的组件组成:用于全局时空交互特征提取的交互网络,用于解码动态场景(即代理的周围道路拓扑)的环境网,以及结合时空特征,场景特征的预测网,智能体的过去轨迹和一些随机噪声,用于智能体的稳健轨迹预测。在行人步行和车辆行人异构数据集上的实验表明,该方法在预测准确性方面优于最新的预测方法。 |
| Efficient Pig Counting in Crowds with Keypoints Tracking and Spatial-aware Temporal Response Filtering Authors Guang Chen, Shiwen Shen, Longyin Wen, Si Luo, Liefeng Bo 养猪计数是大规模养猪的一项关键任务,通常由人类目测完成。但是此过程非常耗时且容易出错。很少有文献研究开发出自动生猪计数方法。现有方法仅集中于使用单个图像进行生猪计数,其准确性受到几个因素的挑战,包括生猪运动,遮挡和重叠。特别地,单个图像的视野非常有限,并且不能满足大型猪舍的养猪要求。为此,我们仅使用一台带检查机器人的单眼鱼眼镜头在人群中展示了一种实时的自动猪计数系统。我们的系统表明,它所产生的准确结果超过了人类。我们的管道从一种新颖的自下而上的生猪检测算法开始,以避免由于生猪的重叠,阻塞和变形而引起的假阴性。深度卷积神经网络CNN用于检测猪的身体部位的关键点,并将这些关键点关联起来以识别单个猪。此后,一种有效的在线跟踪方法用于跨视频帧关联猪。最后,提出了一种新颖的空间感知时间响应滤波STRF方法来预测猪的数量,该方法可以有效地抑制由猪或摄像机运动或跟踪失败引起的误报。整个管道已部署在边缘计算设备中,并证明了其有效性。 |
| Towards Mesh Saliency Detection in 6 Degrees of Freedom Authors Xiaoying Ding, Zhenzhong Chen 传统的3D网格显着性检测算法和相应的数据库是在一些限制下提出的,例如提供有限的观看方向并且不考虑对象的运动。在这项工作中,开发了一个新颖的6DoF网格显着性数据库,该数据库同时提供了受试者的6DoF数据和眼睛运动数据。与传统数据库不同,实验中的对象可以自由移动以在虚拟现实环境中观察3D网格。基于该数据库,我们首先分析观察者之间的变化以及观察方向对对象视觉注意力的影响,然后提供关于对象在观察过程中视觉注意力偏差的进一步研究。此外,我们提出了一种基于唯一性度量和偏倚偏好的6DoF网格显着性检测算法。为了评估所提出的方法,我们还设计了一种评估指标,该指标将6DoF信息考虑在内,并扩展了一些最先进的3D显着性检测方法以进行比较。实验结果证明了我们的方法在6DoF网格显着性检测方面的优越性能,此外还为提供的6DoF网格显着性数据库提供了基准。该数据库和相应的算法将公开提供用于研究目的。 |
| TRIE: End-to-End Text Reading and Information Extraction for Document Understanding Authors Peng Zhang, Yunlu Xu, Zhanzhan Cheng, Shiliang Pu, Jing Lu, Liang Qiao, Yi Niu, Fei Wu 由于现实世界中无处不在的文件,例如发票,票据,简历和传单都包含丰富的信息,因此自动理解文件图像已成为热门话题。大多数现有的工作将问题分解为两个独立的任务,一个是阅读文本以检测和识别图像中的文本,另一个是提取信息以分析和提取先前提取的纯文本中的关键元素。然而,他们主要集中在改进信息提取任务上,而忽略了文本阅读和信息提取相互关联的事实。在本文中,我们提出了一个统一的端到端文本阅读和信息提取网络,这两个任务可以相互促进。具体而言,将文本阅读的多模式视觉和文本特征融合在一起以进行信息提取,进而,信息提取中的语义有助于优化文本阅读。在具有从固定布局到可变布局,从结构化文本到半结构化文本的各种文档图像的三个现实世界数据集上,我们提出的方法在效率和准确性上均明显优于最新方法。 |
| SPIN: Structure-Preserving Inner Offset Network for Scene Text Recognition Authors Chengwei Zhang, Yunlu Xu, Zhanzhan Cheng, Shiliang Pu, Yi Niu, Fei Wu, Futai Zou 任意文本外观在场景文本识别任务中提出了巨大挑战。现有的作品大多考虑形状变形来解决该问题,包括透视变形,线曲率或其他样式变化。因此,对基于空间变换器的方法进行了广泛的研究。但是,复杂场景中的色差问题并未引起足够的重视。在这项工作中,我们引入了一个新的可学习的几何无关模块,即“结构保留内部偏移网络SPIN”,该模块允许对网络内源数据进行颜色处理。可以在任何识别体系结构之前插入此可区分模块,以简化下游任务,从而使神经网络能够主动转换输入强度,而不是现有的空间校正。它也可以作为已知空间变换的补充模块,并以独立和协作的方式与它们一起工作。广泛的实验表明,与现有技术相比,使用SPIN可以显着改善多个文本识别基准。 |
| Object-QA: Towards High Reliable Object Quality Assessment Authors Jing Lu, Baorui Zou, Zhanzhan Cheng, Shiliang Pu, Shuigeng Zhou, Yi Niu, Fei Wu 在物体识别应用中,物体图像通常以不同的质量等级出现。实际上,为了提高应用程序的性能,例如,指示对象图像质量非常重要。过滤掉低质量的目标图像帧,以保持强大的视频目标识别结果并加快推理速度。然而,没有先前的工作被明确提出来解决该问题。在本文中,我们首次定义了对象质量评估的问题,并提出了一种称为对象QA的有效方法来评估对象图像的高可靠质量得分。具体而言,对象质量检查首先使用设计良好的相对质量评估模块,该模块通过参考对象图像与其估计的模板之间的差异来学习类内级别的质量得分。然后,设计一个绝对质量评估模块,以通过调整班际间的质量得分分布来生成最终质量得分。此外,对象QA可以仅使用对象级别的注释来实现,并且还可以轻松地部署到各种对象识别任务中。据我们所知,这是提出该问题的定义并进行定量评估的第一项工作。对5个不同数据集的验证表明,对象QA不仅可以根据人类的认知评估高可靠的质量得分,而且可以提高应用程序性能。 |
| Evolutionary NAS with Gene Expression Programming of Cellular Encoding Authors Clifford Broni Bediako, Yuki Murata, Luiz Henrique Mormille, Masayasu Atsumi 神经体系结构搜索NAS的复兴已经看到了经典方法,例如遗传算法GA和遗传编程GP被用于卷积神经网络CNN体系结构。尽管最近的工作在视觉感知任务上取得了令人鼓舞的性能,但GA和GP的直接编码方案都存在功能复杂性缺陷,并且在CNN之类的大型体系结构上无法很好地扩展。为了解决这个问题,我们提出了一种新的生成编码方案,即符号线性生成编码SLGE,该简单但功能强大的方案将局部图变换嵌入线性固定长度字符串的染色体中,以通过基因表达编程的进化过程来开发具有不同形状和大小的CNN架构。在实验中,SLGE的有效性体现在发现可改善CIFAR 10和CIFAR 100图像分类任务的手工CNN架构性能的体系结构,并使用较少的GPU资源使用现有NAS方法获得具有竞争力的分类错误率。 |
| Road Segmentation on low resolution Lidar point clouds for autonomous vehicles Authors Leonardo Gigli, B Ravi Kiran, Thomas Paul, Andres Serna, Nagarjuna Vemuri, Beatriz Marcotegui, Santiago Velasco Forero 在自动驾驶情况下用于感知任务的点云数据集通常依赖于高分辨率的64层光检测和测距LIDAR扫描仪。在现实世界中通常采用16个32层激光雷达的自动驾驶传感器架构上部署它们的成本很高。我们评估了基于密集点云的子采样图像表示对道路分割任务准确性的影响。在我们的实验中,通过对原始64层数据进行二次采样来模拟低分辨率的16 32层LIDAR点云,以便随后将其转换为点云的Bird View View BEV和SphericalView SV表示形式的特征图。我们介绍使用局部法线向量和LIDAR的球坐标作为现有LoDNN体系结构的输入通道。我们证明了这种局部法线特征与经典特征相结合,不仅提高了全分辨率点云上二元道路分割的性能,而且与单独使用经典特征相比,还降低了对密集点云进行二次采样时对精度的负面影响。我们通过对两个数据集KITTI道路分割基准和最近发布的语义KITTI数据集进行了几次实验,评估了我们的方法。 |
| Multi-task deep learning for image segmentation using recursive approximation tasks Authors Rihuan Ke, Aur lie Bugeau, Nicolas Papadakis, Mark Kirkland, Peter Schuetz, Carola Bibiane Sch nlieb 全面监督的深度神经网络用于分割通常需要大量的像素级标签,而这些标签的创建成本很高。在这项工作中,我们开发了一种多任务学习方法来缓解此约束。我们将分割问题视为一系列递归定义的逼近子问题,并在不断提高的逼近精度中。子问题由一个框架处理,该框架包括:1分割任务,从小部分图像的像素级地面真相分割掩模中学习; 2递归逼近任务,该任务进行部分对象区域学习,以及从局部开始的数据驱动掩模演变每个对象实例的遮罩,以及其他3个面向问题的辅助任务,这些任务都经过稀疏注释训练并促进了专用功能的学习。大多数训练图像仅由不包含精确对象边界的粗糙局部遮罩标记,而不是由其完整的分割遮罩标记。在训练阶段,逼近任务将学习这些局部蒙版的统计信息,然后通过以完全数据驱动的方式从分割任务中学习到的信息,将局部区域递归地增加到对象边界。在极少量的精确分割图像和大量粗标签上对网络进行训练。因此可以以廉价的方式获得注释。我们通过显微镜图像和超声图像证明了我们的方法在三种应用中的有效性。 |
| Pay Attention to What You Read: Non-recurrent Handwritten Text-Line Recognition Authors Lei Kang, Pau Riba, Mar al Rusi ol, Alicia Forn s, Mauricio Villegas 尽管我们观察到不同书写风格的差异很大,但递归神经网络用于手写识别的出现标志着一个重要的里程碑,它实现了令人印象深刻的识别精度。顺序体系结构非常适合建模文本行,这不仅是因为文本固有的时间方面,而且是学习字符和单词序列上的概率分布。但是,使用此类循环范式在训练阶段要付出代价,因为它们的顺序管道会阻止并行化。在这项工作中,我们介绍了一种非周期性方法,通过使用转换器模型来识别手写文本。我们提出了一种绕过任何复发的新颖方法。通过在视觉和文本阶段使用多头自我注意层,我们能够解决字符识别以及学习与语言相关的待解码字符序列的依赖性。我们的模型不受任何预定义词汇的约束,能够识别出词汇中的单词,即未出现在训练词汇中的单词。我们大大超越了现有技术,并证明即使在很少的镜头学习场景中也能产生令人满意的识别精度。 |
| ALBA : Reinforcement Learning for Video Object Segmentation Authors Shreyank N Gowda, Panagiotis Eustratiadis, Timothy Hospedales, Laura Sevilla Lara 我们考虑了零镜头视频对象分割VOS的挑战性问题。也就是说,无需任何手动初始化即可完全自动地分割和跟踪视频中的多个运动对象。我们通过利用对象建议并就空间和时间上的分组进行联合推断,将其视为分组问题。我们提出了一种网络体系结构,用于方便地执行提案选择和联合分组。至关重要的是,我们然后展示了如何通过强化学习来训练该网络,从而使其学会执行最佳的非近视分组决策序列来分割整个视频。与标准监督技术不同,这还使我们能够直接优化用于评估VOS的基于不可微重叠的指标。我们显示,在三个基准测试DAVIS 2017 2,FBMS 20和Youtube VOS 27上,我们提出的称为ALBA的方法优于现有技术。 |
| How to do Physics-based Learning Authors Michael Kellman, Michael Lustig, Laura Waller 本教程的目的是逐步解释如何实现基于物理的学习,以快速构建计算成像系统的原型。我们提供了基于物理的学习,基于物理的网络的构建及其简化实践的基本概述。具体来说,我们提倡两次利用自动微分功能,一次建立基于物理学的网络,再一次进行基于物理学的学习。因此,用户只需为其系统实施前向建模过程,即可缩短原型开发时间。我们提供了基于物理网络的Pytorch开源实现以及针对通用稀疏恢复问题的培训程序 |
| Kernel methods library for pattern analysis and machine learning in python Authors Pradeep Reddy Raamana 事实证明,内核方法是用于各种领域的模式分析和机器学习ML的强大技术。但是,它们的许多原始或高级实现仍保留在Matlab中。随着ML在ML和数据科学领域的兴起和普及,显然需要一个定义明确的库,该库不仅可以使用流行的内核,而且还可以轻松定义定制的内核,以对它们进行微调以适应各种需求。应用程序。 kernelmethods库以领域不可知的方式填补了python ML生态系统中的重要空白,使样本数据类型可以是数值,分类,图形或它们的组合中的任何一种。此外,该库提供了许多定义明确的类,以使各种基于内核的操作对大规模数据集有效,对模块进行模块化以简化域适应,并且可以在不同的生态系统之间互操作。该库位于 |
| Gram filtering and sinogram interpolation for pixel-basis in parallel-beam X-ray CT reconstruction Authors Ziyu Shu, Alireza Entezari 平行光束X射线CT的关键方面是正向和反向投影,但是其计算负担仍然是应用的障碍。我们提出了一种方法,可以通过精确计算Gram滤波器并最佳地插值正弦图信号来提高相关算法的性能。此外,探测器模糊效果可以有效地包含在我们的模型中。我们在分析体模和真实CT图像上的实验中均显示了反投影和迭代重建的速度和质量方面的改进。 |
| Segmentation Loss Odyssey Authors Jun Ma 损失函数是基于深度学习的医学图像分割方法的关键要素之一。现有文献中已经提出了许多损失函数,但是需要单独研究或仅在很少其他损失的情况下进行研究。在本文中,我们提出了一种系统的分类法,将现有损失函数分为四个有意义的类别。这有助于揭示它们之间的联系和基本相似之处。此外,我们探索了基于传统区域的损失与基于边界的损失函数之间的关系。这些损失函数的PyTorch实现可在url上公开获得 |
| A Multi-modal Approach to Fine-grained Opinion Mining on Video Reviews Authors Edison Marrese Taylor, Cristian Rodriguez Opazo, Jorge A. Balazs, Stephen Gould, Yutaka Matsuo 尽管最近在针对书面评论的观点挖掘方面取得了进步,但很少有作品能够解决其他评论来源上的问题。鉴于此问题,我们提出了一种多模式方法,用于从视频评论中挖掘细粒度的意见,该方法能够确定正在讨论的评论项目的各个方面以及针对这些观点的情感取向。我们的方法在句子级别工作,不需要时间注释,并使用从其内容的音频,视频和语言转录中衍生的功能。我们在两个数据集上评估了我们的方法,结果表明,与仅基于文本的基准相比,利用视频和音频模式始终可以提高性能,这证明这些额外的模式对于更好地理解视频评论至关重要。 |
| Data-Driven Continuum Dynamics via Transport-Teleport Duality Authors Jong Hoon Ahn 近年来,机器学习方法已被广泛用于研究物理系统,这些物理系统难以用控制方程求解。但是,大多数学习体系结构并没有以连续性方程的形式固有地包含守恒定律,它们需要密集的数据来学习守恒量的连续动力学。在这项研究中,我们为运输现象的机器学习提出了一个数学框架。通过推导的对合,连续性方程式成为零速度的量的消失和重新出现的逐点运算。通过使用稀疏的观察对过程进行建模,我们可以确定和预测物理系统的动态。该方法不需要明确使用控制方程,而仅取决于观测数据。 |
| Earballs: Neural Transmodal Translation Authors Andrew Port, Chelhwon Kim, Mitesh Patel 正如谚语所表达的,一幅图片价值一千个单词,当使用口语交流视觉信息时,简洁可能是一个挑战。这项工作描述了一种新颖的技术,可以利用机器学习的特征嵌入将视觉和其他类型的信息转换为可感知的音频域,从而允许用户仅使用其听觉能力即可感知到此信息。明确地说,这项工作的目的是提出一种提供信息保存映射的机制,用户可以使用其听觉系统学习用来查看或感知其他信息。该系统使用预训练的图像嵌入网络提取视觉特征并将其嵌入欧几里德空间的紧凑子集,这会将图像转换为特征向量,其L 2距离可用作相似性的有意义度量。然后,使用生成对抗网络从特征向量的此度量空间到目标音频数据集和基于梅尔频率倒谱的心理声学距离度量定义的度量空间中找到一个距离保留图。我们通过将人脸图像转换成像语音一样的人类语音来演示这种技术。 GAN成功地找到了一个保留度量的映射,在人类受试者测试中,用户仅使用我们模型输出的音频就能够成功地对面部图像进行分类。 |
| An Entropy Based Outlier Score and its Application to Novelty Detection for Road Infrastructure Images Authors Jonas Wurst, Alberto Flores Fern ndez, Michael Botsch, Wolfgang Utschick 在这项工作中提出了一种新颖的无监督离群值,可以将其嵌入基于图的降维技术中。分数使用这些技术的有向最近邻图。因此,用于将数据投影到较低维度的相同相似性度量也用于确定离群值。异常值是通过相似度的加权归一化熵实现的。该分数将应用于道路基础设施图像。目的是在给定预先收集的基础数据集的情况下识别新观察到的基础结构。检测未知场景是加速自动驾驶汽车验证的关键。结果表明,该技术具有很高的潜力。为了验证离群值得分的泛化能力,它还被应用于各种现实世界数据集。与现有技术相比,使用提出的方法识别异常值的总体平均性能更高。为了生成基础结构映像,作为该工作的一部分,开发了用于Matlab的openDRIVE解析和绘图工具。该工具以及基于熵的离群值得分的实现与统一流形近似和投影相结合,已公开可用。 |
| Co-Heterogeneous and Adaptive Segmentation from Multi-Source and Multi-Phase CT Imaging Data: A Study on Pathological Liver and Lesion Segmentation Authors Ashwin Raju, Chi Tung Cheng, Yunakai Huo, Jinzheng Cai, Junzhou Huang, Jing Xiao, Le Lu, ChienHuang Liao, Adam P Harrison 在医学成像中,在当前可公开获得且具有完整注释的数据集上训练的器官病理学分割模型通常不能很好地表示实际环境中遇到的异构模式,阶段,病理和临床情况。另一方面,许多现代临床中心存储着大量的未标记患者成像扫描。在这项工作中,我们提出了一种新颖的分割策略,共异源和自适应分割CHASe,它只需要一个小的标记的单相成像数据队列即可适应可能具有新临床情况和病理的任何未标记的异质多相数据队列。为此,我们提出了一个通用框架,该框架融合了基于外观的半监督,基于掩码的对抗域自适应和伪标记。我们还介绍了协同异构训练,这是协同训练和异质模式学习的一种新型集成。我们已使用临床综合且具有挑战性的多相CT成像多阶段CT成像研究数据对1147例患者和4577个3D体积进行评估。与以前的现有基准水平相比,CHASe可以进一步改善病理性肝面罩Dice Sorensen系数,范围为4.2 sim 9.4,具体取决于相结合,例如在非对比CT上从84.6到94.0。 |
| On Mutual Information in Contrastive Learning for Visual Representations Authors Mike Wu, Chengxu Zhuang, Milan Mosse, Daniel Yamins, Noah Goodman 近年来,已经显示了视觉中的几种无监督的对比学习算法,可以学习在传输任务上表现出色的表示形式。我们证明了这一系列算法最大化了图像的两个或多个视图之间的互信息下限,典型的视图来自图像增强的组合。我们的边界概括了InfoNCE目标,以支持从难以对比的有限区域进行负采样。我们发现,选择1个否定样本和2个视图对于对比学习的成功至关重要,而对比学习的成功很大程度上尚未得到开发。相互信息重构也简化并稳定了以前的学习目标。实际上,我们的新目标所产生的表示要优于以前的方法,这些方法可以转移到分类,边界框检测,实例分割和关键点检测方面。互信息框架提供了对比学习方法的统一和严格的比较,并揭示了影响表征学习的选择。 |
| Microstructure and Water Absorption of Ancient Concrete from Pompeii: An Integrated Synchrotron Microtomography and Neutron Radiography Characterization Authors Ke Xu, Anton S. Tremsin, Jiaqi Li, Daniela M. Ushizima, Catherine A. Davy, Amine Bouterf, Ying Tsun Su, Milena Marroccoli, Anna Maria Mauro, Massimo Osanna, Antonio Telesca, Paulo J. M. Monteiro 人们对使用先进技术表征古罗马混凝土有了新的兴趣。在目前的工作中,从庞培的医院中钻取了样品,并通过同步辐射显微断层照相术uCT和中子射线照相术进行了分析,以研究微观结构(包括诱发裂缝的存在)如何影响其吸水率。通过中子射线照相术定量水的分布和吸收率。使用先进的成像方法从uCT结果中分析了3D裂纹扩展,孔径分布和方向,曲折度和连通性。具体的表征还包括经典方法,例如差示热重分析法,X射线衍射法和扫描电子显微镜。一旦引入裂纹,就观察到韧性断裂模式。与波特兰水泥砂浆混凝土相比,庞贝样品具有较高的孔隙率,较低的连通性和相似的毛细渗透系数。此外,渗透率是根据渗流理论和孔隙结构数据通过模型预测的,以评估流体的传输特性。 |
| Benchmarking Differentially Private Residual Networks for Medical Imagery Authors Sahib Singh, Harshvardhan Sikka 医院和其他医疗机构通常拥有大量的医疗数据,当用于推进研究时可以提供巨大的价值。但是,此数据通常本质上是敏感的,因此,由于隐私问题,因此不容易在研究环境中使用。在本文中,我们在与肺炎有关的差分私有图像数据集上测量了深度神经网络的性能。我们分析了模型的准确性和图像之间的摄动规模之间的权衡。在这些情况下,了解模型的精度在差分私人医学图像的各种摄动水平之间如何变化是有用的。鉴于日冕病毒大流行,这项工作具有重要的背景意义,因为由于其感染COVID 19可能具有致命的并发症,肺炎已经引起了更大的关注。 |
| Prediction of Thrombectomy FunctionalOutcomes using Multimodal Data Authors Zeynel A. Samak, Philip Clatworthy, Majid Mirmehdi 最近的随机临床试验表明,由于颅内大血管闭塞而导致的缺血性中风患者将从血管内血栓切除术中受益。然而,预测单个患者的治疗结果仍然是一个挑战。我们提出了一种新颖的深度学习方法,可以直接利用多模式数据临床元数据信息,影像数据以及从图像中提取的影像生物标志物来评估血管内治疗的成功。我们在架构中纳入了一种关注机制,以在通道方面和空间方面对全局要素相互依赖性进行建模。我们使用单峰和多峰数据进行比较实验,以预测功能结果修改的Rankin量表评分,mRS,二分式mRS评分达到0.75 AUC,单个mRS评分达到0.35分类准确度。 |
| Instance Explainable Temporal Network For Multivariate Timeseries Authors Naveen Madiraju, Homa Karimabadi 尽管深层网络已被广泛采用,但其缺点之一是其黑盒性质。机器学习中的一个特别困难的问题是多元时间序列MVTS分类。 MVTS数据出现在许多应用中,并且由于传感器和IoT设备的爆炸性增长而变得越来越普遍。在这里,我们提出了一个新颖的网络IETNet,该网络可以为每个推理实例识别分类决策中的重要通道。此功能还可以识别和删除非预测变量,否则将导致过度拟合和/或模型不准确。 IETNet是将时态特征提取,变量选择和联合变量交互结合到一个学习框架中的端到端网络。 IETNet利用一维卷积实现时间特征,使用新颖的通道门层进行变量类别分配,并使用关注层执行跨通道推理并执行分类目标。为了深入了解学习到的时间特征和通道,我们沿时间和通道提取了感兴趣的区域注意图。该网络的可行性通过来自N个人体模拟的多元时间序列数据和航天器传感器数据得到证明。 |
| Kernel Self-Attention in Deep Multiple Instance Learning Authors Dawid Rymarczyk, Jacek Tabor, Bartosz Zieli ski 多实例学习MIL是一种弱监督学习,它假设整个实例包中仅提供一个标签。这样,它出现在医学图像分析的许多问题中,例如活检的整个幻灯片图像分类。最近,MIL还通过引入聚合运算符而应用于深层体系结构,该运算符专注于包的关键实例。在本文中,我们通过自我关注机制丰富了这一思想,以考虑到实例之间的依赖性。我们进行了几次实验,结果表明,使用各种类型内核的方法提高了准确性,尤其是在非标准MIL假设的情况下。这对于真实单词医疗问题很重要,后者通常满足基于在场或基于阈值的假设。 |
| Learning to rank music tracks using triplet loss Authors Laure Pr tet, Ga l Richard, Geoffroy Peeters 大多数音乐流媒体服务依靠自动推荐算法来利用其庞大的音乐目录。这些算法旨在根据与目标音乐曲目的相似性来检索音乐曲目的排名列表。在这项工作中,我们提出了一种基于音频内容的直接推荐方法,而无需明确标记音乐曲目。为此,我们提出了几种从排名列表中进行三重态挖掘的策略。我们训练卷积神经网络以通过三重态损失学习相似性。针对基于自动标记的方法,在大规模实验中对这些不同的策略进行了比较和验证。获得的结果突显了我们系统的效率,特别是与自动池化层关联时。 |
| Gaze-based Autism Detection for Adolescents and Young Adults using Prosaic Videos Authors Karan Ahuja, Abhishek Bose, Mohit Jain, Kuntal Dey, Anil Joshi, Krishnaveni Achary, Blessin Varkey, Chris Harrison, Mayank Goel 在青少年和成人中,自闭症通常仍未被诊断。先前的研究表明,自闭症患者通常表现出非典型的注视和注视方式。在这篇简短的论文中,我们证明了通过监视用户观看普通视点(即非专业,结构化或编码的视频)时的注视,我们可以识别出患有自闭症谱系障碍的个体。我们招募了35位自闭症患者和25位非自闭症患者,并使用连接到笔记本电脑的现成的眼动仪捕捉了他们的目光。在15秒内,我们的方法在识别自闭症诊断者中的准确率为92.5。我们设想在例如网络媒体的消费期间应用这样的自动检测,这可以允许被动筛选和适应用户界面。 |
| End-to-end Optimized Video Compression with MV-Residual Prediction Authors XiangJi Wu, Ziwen Zhang, Jie Feng, Lei Zhou, Junmin Wu 我们在本文中提出了一种针对P帧压缩的端到端可训练框架。联合运动矢量MV和残差预测网络MV Residual旨在通过将两个连续帧作为输入来提取运动表示和残差信息的组合特征。潜在表示的先验概率由超优先级自动编码器建模,并与MV残差网络一起进行训练。特别地,将空间移位卷积应用于视频帧预测,其中学习每个像素的运动核,以通过将核应用于源图像中的移位位置来生成预测像素。最后,考虑到挑战的位约束,采用新颖的速率分配和后处理策略来产生最终的压缩位。验证集上的实验结果表明,所提出的优化框架可以为P帧压缩竞争产生最高的MS SSIM。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com