YOLO V1,V2,V3总结
内容概要:
-
YOLOV1
-
YOLOV2
-
YOLOV3
YOLOV1:
论文地址:http://arxiv.org/abs/1506.02640
参考文章:
https://blog.csdn.net/c20081052/article/details/80236015
https://blog.csdn.net/qq_38232598/article/details/88695454?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
https://zhuanlan.zhihu.com/p/24916786
https://zhuanlan.zhihu.com/p/25053311
YOLOV1用一个单独的网络,把目标检测当做回归问题,直接在整张图上进行bbox的预测和相关的类别预测,实现了端到端的目标检测,而先前的方法主要是利用分类器来检测。
YOLO检测分为三步:将图resize;run一个CNN网络;设置阈值获得结果

YOLO的优势:非常快,在 Titan X 的 GPU 上 能够达到 45 帧每秒;预测能基于整张图像,假阳率低;能学到目标的广义特征;
YOLO的不足:定位不准,尤其是小物体和小的一群物体,这是因为一个网格中只预测了两个框,并且只属于一类;对测试图像中,同一类物体出现的新的不常见的长宽比和其他情况是。泛化能力偏弱
算法详解:
算法核心:
将图像划为s*s的网格,物体的中心处于哪个网格,哪个网格负责检测该物体。每个网格预测B个bbox,每个bbox预测5个值,x,y,w,h,c(c为置信度)。其中,x,y为物体中心点相对于对应网格左上角的偏移量,归一化为0~1,w,h是相对整张图大小归一化后的值,范围是0~1,c是P(obj)*IOU(truth&pred),体现是否有物体及预测准确度两个含义。每个网格还会预测C个条件类别概率。对于SxS个网格,每个网格要预测B个bounding box还要预测C个categories。输出就是S x S x (5*B+C)的一个tensor。

网络结构:

24个卷积层,2个全连接层,堆叠1*1,3*3卷积层,很好地减少了参数量。现在ImageNet上预训练,再训练目标检测
-
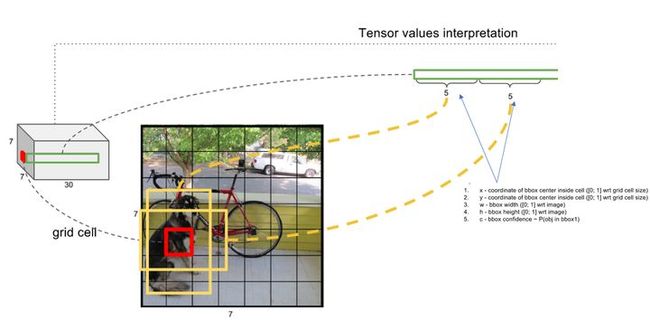
在test的时候,每个网格预测的class信息和bounding box预测的confidence信息相乘,就得到每个bounding box的class-specific confidence score:

等式左边第一项就是每个网格预测的类别信息,第二三项就是每个bounding box预测的confidence。这个乘积即encode了预测的box属于某一类的概率,也有该box准确度的信息。 -
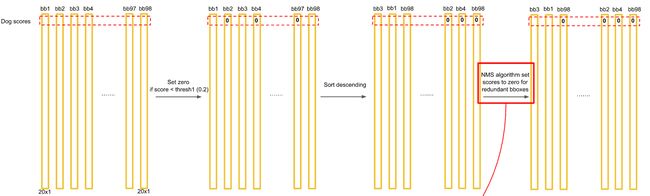
得到每个box的class-specific confidence score以后,设置阈值,滤掉得分低的boxes,对保留的boxes进行NMS处理,就得到最终的检测结果。
损失函数:
包括回归损失,置信度损失和分类损失,都是用的sum-squared error。

具体做了一些改进:
第一,8维的localization error和20维的classification error同等重要显然是不合理的;
第二,如果一个网格中没有object(一幅图中这种网格很多),那么就会将这些网格中的box的confidence push到0,相比于较少的有object的网格,这种做法是overpowering的,这会导致网络不稳定甚至发散。
-
- 更重视8维的坐标预测,给这些损失前面赋予更大的loss weight, 记为
 在pascal VOC训练中取5。
在pascal VOC训练中取5。 - 对没有object的box的confidence loss,赋予小的loss weight,记为
 在pascal VOC训练中取0.5。
在pascal VOC训练中取0.5。 - 有object的box的confidence loss和类别的loss的loss weight正常取1。
- 更重视8维的坐标预测,给这些损失前面赋予更大的loss weight, 记为
-
对不同大小的box预测中,相比于大box预测偏一点,小box预测偏一点肯定更不能被忍受的。而sum-square error loss中对同样的偏移loss是一样。
为了缓和这个问题,作者用了一个比较取巧的办法,就是将box的width和height取平方根代替原本的height和width。这个参考下面的图很容易理解,小box的横轴值较小,发生偏移时,反应到y轴上相比大box要大。 -
一个网格预测多个box,希望的是每个box predictor专门负责预测某个object。具体做法就是看当前预测的box与ground truth box中哪个IoU大,就负责哪个。这种做法称作box predictor的specialization。
训练时:
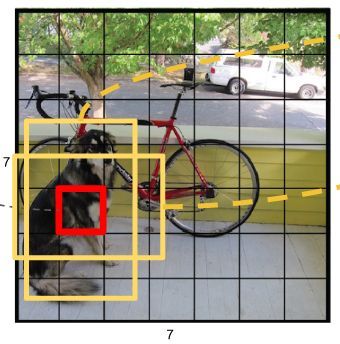
-
- 每个网格还要预测类别信息,论文中有20类。7x7的网格,每个网格要预测2个 bounding box 和 20个类别概率,输出就是 7x7x(5x2 + 20) 。 (通用公式: SxS个网格,每个网格要预测B个bounding box还要预测C个categories,输出就是S x S x (5*B+C)的一个tensor。 注意:class信息是针对每个网格的,confidence信息是针对每个bounding box的)
测试时:
-
- 等式左边第一项就是每个网格预测的类别信息,第二三项就是每个bounding box预测的confidence。这个乘积即encode了预测的box属于某一类的概率,也有该box准确度的信息。
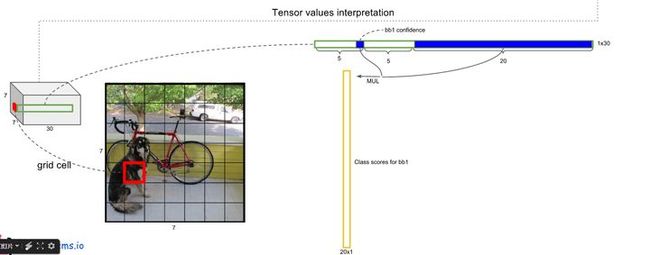
- 对每一个网格的每一个bbox执行同样操作: 7x7x2 = 98 bbox (每个bbox既有对应的class信息又有坐标信息)

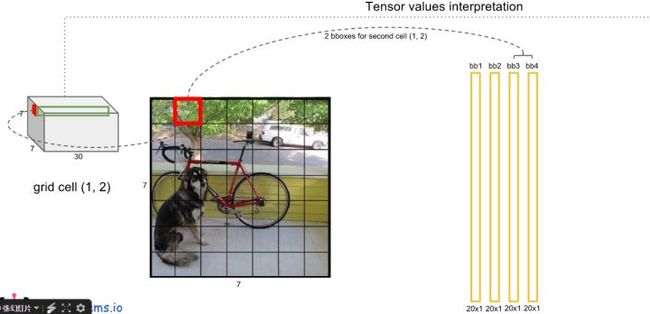
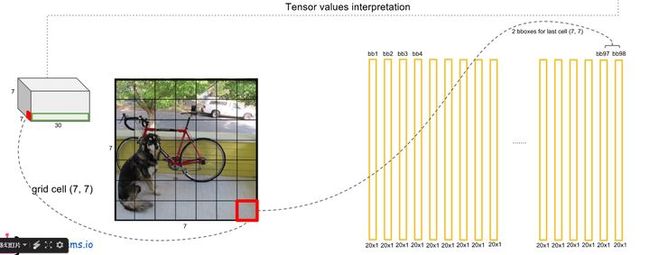
- 等式左边第一项就是每个网格预测的类别信息,第二三项就是每个bounding box预测的confidence。这个乘积即encode了预测的box属于某一类的概率,也有该box准确度的信息。
- 得到每个bbox的class-specific confidence score以后,设置阈值,滤掉得分低的boxes,对保留的boxes进行NMS处理,就得到最终的检测结果。
YOLOV2:
论文地址:https://arxiv.org/pdf/1612.08242v1.pdf
参考文章:https://blog.csdn.net/shanlepu6038/article/details/84778770
YOLOV2是在YOLOV1基础上,加入了其他论文中好的方法,提升了YOLO的效果,同时提出了新的联合训练策略,使YOLO能对9000多种类进行检测识别,称为YOLO9000。
改进的方式:
1、在所有卷积层中加入BN,mAP提升2%
2、改用高分辨率分类器:原来用224*224做预训练,再用448*448做检测,但是直接切换分辨率,检测模型可能难以快速适应高分辨率。改为用448*448在分类网络中fine-tune 10个epoch,这可以使得模型在检测数据集上finetune之前已经适用高分辨率输入,然后再做检测,mAP提升4%
3、使用Anchor Boxes:YOLOv2借鉴了Faster R-CNN中RPN网络的先验框(anchor boxes,prior boxes,SSD也采用了先验框)策略。RPN预测的是边界框相对于先验框的offsets值(其实是transform值,详细见Faster R_CNN论文),采用先验框使得模型更容易学习。YOLOV2去掉最后的全连接层,去掉一个pooling,使网络输出更高分辨率,输入图像改为416*416,使特征图有奇数个位置,t同时为每个anchor box预测类别和目标,而不是同一个网格共享一个类别。mAP稍微降低,召回率提升81%->88%
4、使用聚类的方式得到anchor box的尺寸:YOLOv2采用k-means聚类方法对训练集中的边界框做了聚类分析,实验证明使用先验,使学习更容易,回归效果更好
5、直接的位置预测:沿用YOLOV1的预测方法,预测相对于网格的坐标偏移量,预测边界框中心点相对于对应cell左上角位置的相对偏移值,为了将边界框中心点约束在当前cell中,使用sigmoid函数处理偏移值,这样预测的偏移值在(0,1)范围内(每个cell的尺度看做1)
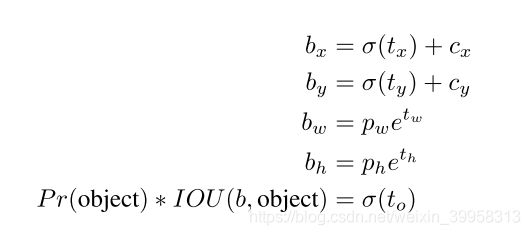
6、使用passthrough layer获得细粒度特征: passthrough层与ResNet网络的shortcut类似,以前面更高分辨率的特征图为输入,然后将其连接到后面的低分辨率特征图上。将输出层的上一层通过将相邻特征叠加到不同通道,变为低分辨率特征后,concatenates在一起,前面的特征图维度是后面的特征图的2倍,passthrough层抽取前面层的每个2*2的局部区域,然后将其转化为channel维度,对于26*26*512的特征图,经passthrough层处理之后就变成了13*13*2048的新特征图(特征图大小降低4倍,而channles增加4倍,图6为一个实例),这样就可以与后面的13*13*1024特征图连接在一起形成13*13*3072的特征图,然后在此特征图基础上卷积做预测。mAP提升1%
passthrough实例:

7、多尺度训练:将输入图像resize成多种尺度大小,输入图片大小选择一系列为32倍数的值:![]() ,在训练过程,每隔10个iterations随机选择一种输入图片大小,然后只需要修改对最后检测层的处理就可以重新训练
,在训练过程,每隔10个iterations随机选择一种输入图片大小,然后只需要修改对最后检测层的处理就可以重新训练
改进的过程:

网络设计:
YOLOv2采用了一个新的基础模型(特征提取器),称为Darknet-19,包括19个卷积层和5个maxpooling层,如图4所示。Darknet-19与VGG16模型设计原则是一致的,主要采用3*3卷积,采用2*2的maxpooling层之后,特征图维度降低2倍,而同时将特征图的channles增加两倍。与NIN(Network in Network)类似,Darknet-19最终采用global avgpooling做预测,并且在3*3卷积之间使用1*1卷积来压缩特征图channles以降低模型计算量和参数。Darknet-19每个卷积层后面同样使用了batch norm层以加快收敛速度,降低模型过拟合。在ImageNet分类数据集上,Darknet-19的top-1准确度为72.9%,top-5准确度为91.2%,但是模型参数相对小一些。使用Darknet-19之后,YOLOv2的mAP值没有显著提升,但是计算量却可以减少约33%。
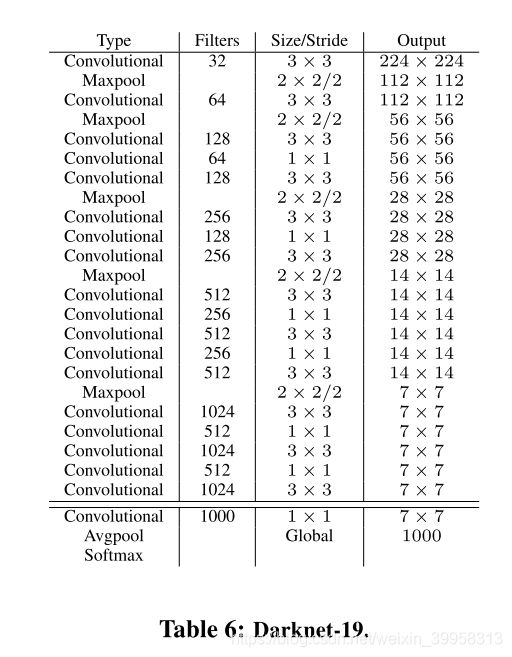
YOLOV2训练:
YOLOv2训练的三个阶段

YOLOv2和YOLOv1的损失函数一样,为均方差函数。但是我看了YOLOv2的源码(训练样本处理与loss计算都包含在文件region_layer.c中,YOLO源码没有任何注释,反正我看了是直摇头),并且参考国外的blog以及allanzelener/YAD2K(Ng深度学习教程所参考的那个Keras实现)上的实现,发现YOLOv2的处理比原来的v1版本更加复杂。先给出loss计算公式:
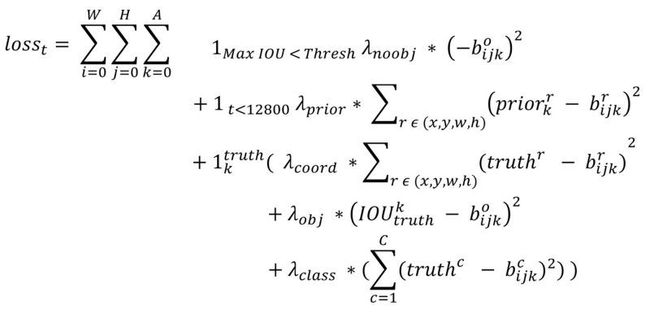
我们来一点点解释,首先W,H分别指的是特征图(13*13)的宽与高,而A指的是先验框数目(这里是5),各个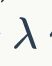 值是各个loss部分的权重系数。第一项loss是计算background的置信度误差,但是哪些预测框来预测背景呢,需要先计算各个预测框和所有ground truth的IOU值,并且取最大值Max_IOU,如果该值小于一定的阈值(YOLOv2使用的是0.6),那么这个预测框就标记为background,需要计算noobj的置信度误差。第二项是计算先验框与预测框的坐标误差,但是只在前12800个iterations间计算,我觉得这项应该是在训练前期使预测框快速学习到先验框的形状。第三大项计算与某个ground truth匹配的预测框各部分loss值,包括坐标误差、置信度误差以及分类误差。先说一下匹配原则,对于某个ground truth,首先要确定其中心点要落在哪个cell上,然后计算这个cell的5个先验框与ground truth的IOU值(YOLOv2中bias_match=1),计算IOU值时不考虑坐标,只考虑形状,所以先将先验框与ground truth的中心点都偏移到同一位置(原点),然后计算出对应的IOU值,IOU值最大的那个先验框与ground truth匹配,对应的预测框用来预测这个ground truth。在计算obj置信度时,在YOLOv1中target=1,而YOLOv2增加了一个控制参数rescore,当其为1时,target取预测框与ground truth的真实IOU值。对于那些没有与ground truth匹配的先验框(与预测框对应),除去那些Max_IOU低于阈值的,其它的就全部忽略,不计算任何误差。这点在YOLOv3论文中也有相关说明:YOLO中一个ground truth只会与一个先验框匹配(IOU值最好的),对于那些IOU值超过一定阈值的先验框,其预测结果就忽略了。这和SSD与RPN网络的处理方式有很大不同,因为它们可以将一个ground truth分配给多个先验框。尽管YOLOv2和YOLOv1计算loss处理上有不同,但都是采用均方差来计算loss。另外需要注意的一点是,在计算boxes的和误差时,YOLOv1中采用的是平方根以降低boxes的大小对误差的影响,而YOLOv2是直接计算,但是根据ground truth的大小对权重系数进行修正:l.coord_scale * (2 - truth.w*truth.h),这样对于尺度较小的boxes其权重系数会更大一些,起到和YOLOv1计算平方根相似的效果(参考YOLO v2 损失函数源码分析)。
值是各个loss部分的权重系数。第一项loss是计算background的置信度误差,但是哪些预测框来预测背景呢,需要先计算各个预测框和所有ground truth的IOU值,并且取最大值Max_IOU,如果该值小于一定的阈值(YOLOv2使用的是0.6),那么这个预测框就标记为background,需要计算noobj的置信度误差。第二项是计算先验框与预测框的坐标误差,但是只在前12800个iterations间计算,我觉得这项应该是在训练前期使预测框快速学习到先验框的形状。第三大项计算与某个ground truth匹配的预测框各部分loss值,包括坐标误差、置信度误差以及分类误差。先说一下匹配原则,对于某个ground truth,首先要确定其中心点要落在哪个cell上,然后计算这个cell的5个先验框与ground truth的IOU值(YOLOv2中bias_match=1),计算IOU值时不考虑坐标,只考虑形状,所以先将先验框与ground truth的中心点都偏移到同一位置(原点),然后计算出对应的IOU值,IOU值最大的那个先验框与ground truth匹配,对应的预测框用来预测这个ground truth。在计算obj置信度时,在YOLOv1中target=1,而YOLOv2增加了一个控制参数rescore,当其为1时,target取预测框与ground truth的真实IOU值。对于那些没有与ground truth匹配的先验框(与预测框对应),除去那些Max_IOU低于阈值的,其它的就全部忽略,不计算任何误差。这点在YOLOv3论文中也有相关说明:YOLO中一个ground truth只会与一个先验框匹配(IOU值最好的),对于那些IOU值超过一定阈值的先验框,其预测结果就忽略了。这和SSD与RPN网络的处理方式有很大不同,因为它们可以将一个ground truth分配给多个先验框。尽管YOLOv2和YOLOv1计算loss处理上有不同,但都是采用均方差来计算loss。另外需要注意的一点是,在计算boxes的和误差时,YOLOv1中采用的是平方根以降低boxes的大小对误差的影响,而YOLOv2是直接计算,但是根据ground truth的大小对权重系数进行修正:l.coord_scale * (2 - truth.w*truth.h),这样对于尺度较小的boxes其权重系数会更大一些,起到和YOLOv1计算平方根相似的效果(参考YOLO v2 损失函数源码分析)。
最终的YOLOv2模型在速度上比YOLOv1还快(采用了计算量更少的Darknet-19模型),而且模型的准确度比YOLOv1有显著提升,详情见paper。
YOLO9000:
提出一种分级分类的方式,构建WordTree,将分类数据和检测数据都合并起来参与训练,分类数据帮助提升模型的分类能力,检测数据帮助提升模型的定位能力。这种训练策略,在其他任务上,也可以借鉴。
YOLOV3:
论文地址:https://pjreddie.com/media/files/papers/YOLOv3.pdf
参考文章:https://blog.csdn.net/litt1e/article/details/88907542
https://blog.csdn.net/leviopku/article/details/82660381
网络结构:
图画的很赞,来自 https://blog.csdn.net/leviopku/article/details/82660381
DBL:代码中的Darknetconv2d_BN_Leaky,是yolo_v3的基本组件。就是卷积+BN+Leaky relu。
resn:n代表数字,有res1,res2, … ,res8等等,表示这个res_block里含有多少个res_unit。
concat:张量拼接。将darknet中间层和后面的某一层的上采样进行拼接。拼接的操作和残差层add的操作是不一样的,拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变。
v3用上采样的方法来实现这种多尺度的feature map,可以结合图1和图2右边来看,图1中concat连接的两个张量是具有一样尺度的(两处拼接分别是26x26尺度拼接和52x52尺度拼接,通过(2, 2)上采样来保证concat拼接的张量尺度相同)。作者并没有像SSD那样直接采用backbone中间层的处理结果作为feature map的输出,而是和后面网络层的上采样结果进行一个拼接之后的处理结果作为feature map。为什么这么做呢? 我感觉是有点玄学在里面,一方面避免和其他算法做法重合,另一方面这也许是试验之后并且结果证明更好的选择,再者有可能就是因为这么做比较节省模型size的
DarkNet-53:
整个v3结构里面,是没有池化层和全连接层的。前向传播过程中,张量的尺寸变换是通过改变卷积核的步长来实现的,比如stride=(2, 2),这就等于将图像边长缩小了一半(即面积缩小到原来的1/4)。在yolo_v2中,要经历5次缩小,会将特征图缩小到原输入尺寸的1/32。输入为416x416,则输出为13x13(416/32=13)。
yolo_v3也和v2一样,backbone都会将输出特征图缩小到输入的1/32。所以,通常都要求输入图片是32的倍数。可以对比v2和v3的backbone看看:(DarkNet-19 与 DarkNet-53)
backbone看看:(DarkNet-19 与 DarkNet-53)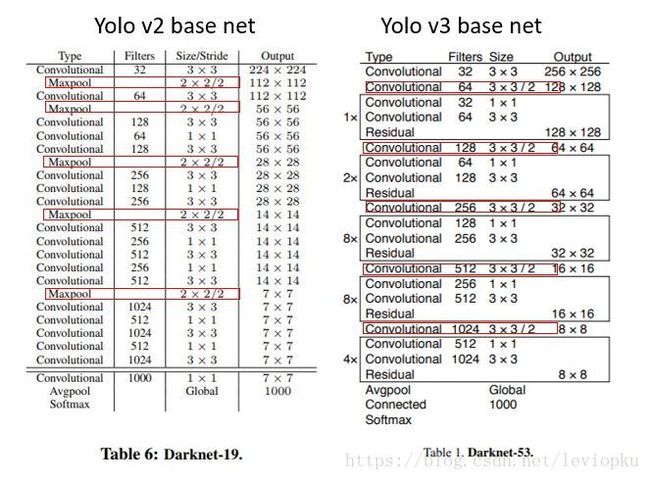
Loss函数:
YOLO v3现在对图像中检测到的对象执行多标签分类。
早期YOLO,作者曾用softmax获取类别得分并用最大得分的标签来表示包含再边界框内的目标,在YOLOv3中,这种做法被修正。softmax来分类依赖于这样一个前提,即分类是相互独立的,换句话说,如果一个目标属于一种类别,那么它就不能属于另一种。但是,当我们的数据集中存在人或女人的标签时,上面所提到的前提就是去了意义。这就是作者为什么不用softmax,而用logistic regression来预测每个类别得分并使用一个阈值来对目标进行多标签预测。比阈值高的类别就是这个边界框真正的类别。
用简单一点的语言来说,其实就是对每种类别使用二分类的logistic回归,即你要么是这种类别要么就不是,然后便利所有类别,得到所有类别的得分,然后选取大于阈值的类别就好了。
logistic回归用于对anchor包围的部分进行一个目标性评分(objectness score),即这块位置是目标的可能性有多大。这一步是在predict之前进行的,可以去掉不必要anchor,可以减少计算量。
如果模板框不是最佳的即使它超过我们设定的阈值,我们还是不会对它进行predict。不同于faster R-CNN的是,yolo_v3只会对1个prior进行操作,也就是那个最佳prior。而logistic回归就是用来从9个anchor priors中找到objectness score(目标存在可能性得分)最高的那一个。logistic回归就是用曲线对prior相对于 objectness score映射关系的线性建模。
xy_loss = object_mask * box_loss_scale * K.binary_crossentropy(raw_true_xy, raw_pred[..., 0:2],
from_logits=True)
wh_loss = object_mask * box_loss_scale * 0.5 * K.square(raw_true_wh - raw_pred[..., 2:4])
confidence_loss = object_mask * K.binary_crossentropy(object_mask, raw_pred[..., 4:5], from_logits=True) + \
(1 - object_mask) * K.binary_crossentropy(object_mask, raw_pred[..., 4:5],
from_logits=True) * ignore_mask
class_loss = object_mask * K.binary_crossentropy(true_class_probs, raw_pred[..., 5:], from_logits=True)
xy_loss = K.sum(xy_loss) / mf
wh_loss = K.sum(wh_loss) / mf
confidence_loss = K.sum(confidence_loss) / mf
class_loss = K.sum(class_loss) / mf
loss += xy_loss + wh_loss + confidence_loss + class_loss
以上是一段keras框架描述的yolo v3 的loss_function代码。忽略恒定系数不看,可以从上述代码看出:除了w, h的损失函数依然采用总方误差之外,其他部分的损失函数用的是二值交叉熵。最后加到一起。那么这个binary_crossentropy又是个什么玩意儿呢?就是一个最简单的交叉熵而已,一般用于二分类,这里的两种二分类类别可以理解为"对和不对"这两种
总结:
YOLOV1提出一种实时目标检测框架,速度快,准确率有待提升;YOLOV2借鉴了好的训练方法,BN、anchor box,多尺度,聚类获取先验框等,及网络架构的调整,将效果提升不少;YOLOV3保证实时性的同时,进一步提升准确率,增多卷积层,使用FPN等。要理解YOLO更透彻,还需多看看代码啊。