PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud
1.Motivation
- 相对与2D数据而言,3D数据的语义分割性越强;
- 由于点云的不规则性,前人经常将点云投影到鸟瞰图或者正面图或者转换为体素形式,但是在进行量化过程中都会造成信息损失。
2.Contribution
- 本论文提出一种新的bottom-up的bbox生成算法,通过先将点云进行前景分割从而来生成少量且质量高的3D proposal。
- 在第二个stage中提出bbox提出边缘细化。通过将第一阶段得到的bbox先进行坐标标准化,然后进行细化。相关消融实验结果表明,该操作使得回归损失收敛更快,能获得更高的查全率。
3.正文
3.1 网络框架

3.2 通过点云分割自底向上生成3D proposal
本论文首先通过学习点特征来对原始点云进行语义分割,然后基于分割得到的前景信息来生成3D proposal,这样一方面能避免大量的3D proposal的生成,限制了3D proposal的搜索空间,另一方面能生成质量较高的3D bbox。
3.2.1 点云特征提取
首先先对点云特征进行学习,论文采用了PointNet++作为backbone,也可以使用VoxelNet,来对点云进行初步的特征提取。
3.2.2 前景分割
接收前面backbone得到的点云特征,在backbone后添加了两个head。一个是用作segmentation,另外一个用作3D proposals的生成。论文考虑到大规模室外场景,前景点的数量比背景点数量少很多,因此采用focal loss来处理类不平衡问题。
3.2.3 Bin-based 3D bounding box generation
在前景分割之后,使用另外一个head从分割的前景点中回归得到3D bbox的位置。3D bbox可以表示为 ( x , y , z , h , w , l , θ ) (x, y, z, h, w, l, \theta) (x,y,z,h,w,l,θ),其中 ( x , y , z ) (x, y, z) (x,y,z)是中心坐标, ( h , w , l ) (h, w, l) (h,w,l)为bbox的大小, θ \theta θ为鸟瞰图的旋转角度。

为了估计一个物体的中心位置,论文提出了一个新的方法,采用bin的分割方法将前景区域分割成一个一个小块。具体来说,论文以X,Z轴作为基础,定义搜索区域为S,沿着X和Z方向分别以长度为 δ \delta δ进行分段,这样便可以得到不同的bin,因此就初步将中心点位置回归问题先转化为分类问题(即属于哪个bin)。而对于y轴坐标的确定,由于一般value值比较小,论文采用L1 loss直接对其进行回归处理。

对于旋转角 θ \theta θ,论文也将其划分成n个bin,然后转化为分类问题进行求解,求解过程与前面提及对X、Z轴的处理是相似的。而对于物体大小 ( h , w , l ) (h, w, l) (h,w,l)来说,论文鉴于每个类都要预设框了,因此只需求解偏移量而已,因此直接对其进行回归求解操作。
于是3D bbox的loss可以写为:

由于会生成多个proposals,因此采用NMS对proposals进行筛选。在训练时采用0.85的iou阈值,并且保留前300个proposals进行第二阶段的训练;而在推理时,采用0.8的iou阈值,且保留前100个作为第二阶段的网络细化。
3.3 Point cloud region pooling
接收前一阶段得到的proposal,论文稍微增大了它的尺度, ( x , y , z , h , w , l , θ ) (x, y, z, h, w, l, \theta) (x,y,z,h,w,l,θ)增加为 ( x , y , z , h + η , w + η , l + η , θ ) (x, y, z, h+\eta, w+\eta, l+\eta, \theta) (x,y,z,h+η,w+η,l+η,θ)。并且对每一个proposal中的所有点进行特征提取,包括每一个点的坐标,反射强度,预测的的前景背景类别,已经该点在第一阶段编码解码后得到的特征向量(即网络框架图中的引导线)。
3.4 Canonical 3D bounding box refinement
3.4.1 Canonical transformation
为了更好地利用前一阶段得到的精密的proposal,使得能在后面细化阶段更好学习局部空间特征,论文提出将proposal坐标标准化。如上图所示,Canonical变化在每个proposal建立一个单独的坐标系,具有一下特点:
- 坐标原点时proposal的中心;
- X和Z轴与水平地面平行,且X轴为proposal的朝向;
- Y轴与之前保持一致,水平向下。
3.4.2 Feature learning for box proposal refinement
由于Canonical变换会导致点云深度信息的损失,因此论文补充变量 d ( p ) = ( x ( p ) ) 2 + ( y ( p ) ) 2 + ( z ( p ) ) 2 d^{(p)}=\sqrt{\left(x^{(p)}\right)^2+\left(y^{(p)}\right)^2+\left(z^{(p)}\right)^2} d(p)=(x(p))2+(y(p))2+(z(p))2,记作深度特征信息。
接着将获得的全局语义特征和局部特征进行堆叠融合作为精细定位的特征。
3.4.3 Losses for box proposal refinement
假如gt与3D box的iou超过0.55,则进行3D bbox的细化学习。并在在细化学习前,将proposal( b i _ \overset\_{b_i} bi_)和gt bbox( b i g t _ \overset\_{b_i^{gt}} bigt_)转化到同一个Canonical坐标系下,即:
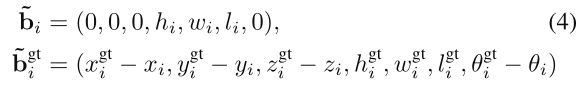
对于loss的计算,计算方式与前面bin-based的计算方式是一样的,只是将搜索范围S进行进一步缩小。
为了细化方向,论文将朝向角度固定为 [ − π / 4 , π / 4 ] \lbrack-\mathrm\pi/4,\;\mathrm\pi/4\rbrack [−π/4,π/4],并且在这 π / 2 \mathrm\pi/2 π/2中进行大小为 w w w的bin的划分,然后设计计算bin和res:

因此综上,第二阶段的损失函数为:

其中第一部分的 β \beta β是第一阶段得到的3D proposals, p r o b i prob_i probi为预测值, l a b e l i label_i labeli为对应的真实标签,即第一部分是计算框是pos还是neg的分类损失;第二部分的 β p o s \beta_{pos} βpos是用作细化的pos框,后面为bin的分类回归损失累加。