神经网络量化基础(2)——量化模型的实现
神经网络量化基础
神经网络量化基础(1)——模型的构建与基础量化函数的实现
神经网络量化基础(2)——量化模型的实现
文章目录
- 神经网络量化基础
- 前言
- 1. 网络量化模块
- 2. 不同模块的量化形式的具体实现
-
- 2.1 量化卷积层
- 2.2 其他模块的量化
- 3 量化模型的构架
前言
本文是在阅读博客时对代码的整理,旨在对量化的基础过程有更加清晰的认识
1. 网络量化模块
我们需要定义一些最基础的量化模块,以便于调用卷积,全连接,Relu和池化层等,首先定义一个量化基类,这样可以减少一些重复的代码,使代码的结构更加的清晰。
class QModule(nn.Module):
def __init__(self, qi=True, qo=True, num_bits=8):
super(QModule, self).__init__()
if qi:
self.qi = QParam(num_bits=num_bits) #
if qo:
self.qo = QParam(num_bits=num_bits)
"""
freeze 其次是 freeze 函数,这个函数主要就是计算公式 (4) 中M,q_w,q_b
"""
def freeze(self):
pass
def quantize_inference(self, x):
raise NotImplementedError('quantize_inference should be implemented.')
这个基类定义了规定了每个量化模块需要提供的方法。
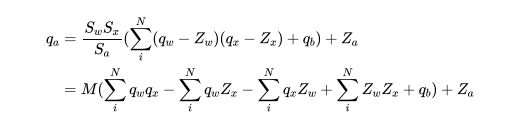
首先是__init__函数,不仅指定了需要量化的位数,还需指定是否提供量化输入(qi)和输出(qo)。同时前文已经提到,不是每一个网络都需要统计输入的min和max,大部分中间层都是运用上一层的qo,来作为自己的qi。
其次是 freeze 函数,这个函数会在统计完 min、max 后发挥作用。正如上文所说的,公式(4) 中有很多项是可以提前计算好的,freeze 就是把这些项提前固定下来,同时也将网络的权重由浮点实数转化为定点整数。
2. 不同模块的量化形式的具体实现
2.1 量化卷积层
卷积层量化主要考虑的有,输入张量,滤波器的权重参数和输出张量。具体的代码实现如下文所示:
"""
QModule 量化卷积
:conv_module: 卷积模块
:qi: 是否量化输入特征图
:qo: 是否量化输出特征图
:num_bits: 8位bit数
"""
class QConv2d(QModule):
#
def __init__(self, conv_module, qi=True, qo=True, num_bits=8):
super(QConv2d, self).__init__(qi=qi, qo=qo, num_bits=num_bits)
self.num_bits = num_bits #量化bit位
self.conv_module = conv_module #卷积模块
self.qw = QParam(num_bits=num_bits) #定义一个实例对象self.qw,主要是卷积模块的权重参数
#有很多项是可以提前计算好的,freeze 就是把这些项提前固定下来,同时也将网络的权重
#由浮点实数转化为定点整数。
def freeze(self, qi=None, qo=None):
if hasattr(self, 'qi') and qi is not None:
raise ValueError('qi has been provided in init function.')
if not hasattr(self, 'qi') and qi is None:
raise ValueError('qi is not existed, should be provided.')
if hasattr(self, 'qo') and qo is not None:
raise ValueError('qo has been provided in init function.')
if not hasattr(self, 'qo') and qo is None:
raise ValueError('qo is not existed, should be provided.')
#这里因为在池化或者激活的输入,不需要对最大值和最小是进行额外的统计,会共享相同的输出
if qi is not None:
self.qi = qi
if qo is not None:
self.qo = qo
self.M = self.qw.scale * self.qi.scale / self.qo.scale
self.conv_module.weight.data = self.qw.quantize_tensor(self.conv_module.weight.data)
self.conv_module.weight.data = self.conv_module.weight.data - self.qw.zero_point
self.conv_module.bias.data = quantize_tensor(self.conv_module.bias.data, scale=self.qi.scale * self.qw.scale, zero_point=0, num_bits=32, signed=True)
def forward(self, x): #前向传播,输入张量,x为浮点型数据
if hasattr(self, 'qi'): #判断有无qi,如果有输入qi
self.qi.update(x) # 其中self.qi是实例化对象,update主要是求出x的最大值和最小值,尺度因子和零点
x = FakeQuantize.apply(x, self.qi) #对输入张量X完成量化
self.qw.update(self.conv_module.weight.data)
# FakeQuantize.apply(self.conv_module.weight, self.qw) 完成对权重的量化
# 值得注意的是此处未对bias进行量化操作
# 卷积运算,其实将其反量化为了浮点型,得到输出张量x
x = F.conv2d(x, FakeQuantize.apply(self.conv_module.weight, self.qw), self.conv_module.bias,
stride=self.conv_module.stride,
padding=self.conv_module.padding, dilation=self.conv_module.dilation,
groups=self.conv_module.groups)
if hasattr(self, 'qo'): #判断有无qo,如果有输入qo
self.qo.update(x) # 其中self.qo类的对象,update主要是求出输出特征的最大值和最小值,尺度因子和零点
x = FakeQuantize.apply(x, self.qo) #对输出特征进行量化操作, 并返回
return x
def quantize_inference(self, x):
x = x - self.qi.zero_point
x = self.conv_module(x)
x = self.M * x
x.round_()
x = x + self.qo.zero_point
x.clamp_(0., 2.**self.num_bits-1.).round_()
return x
我们会先按照正常的 forward 流程跑一些数据,在这个过程中,统计输入输出以及中间 feature map 的 min、max。等统计得差不多了,我们就可以根据 min、max 来计算 scale 和 zero point,然后根据公式 (4) 对一些数据项提前计算(freeze)。
接下来我们将着重对方法freeze(self, qi=None, qo=None)进行解释,传入参数为qi和qo,这两个参数决定了是否使用上一层qo,来作为自己的qi。之后对M,q_w,q_b等进行计算,便于在推理阶段的直接调取。
- 计算 M M M的值。
self.M = self.qw.scale * self.qi.scale / self.qo.scale
- 将卷积运算的权重参数量化为8位,即 q w q_w qw
self.conv_module.weight.data = self.qw.quantize_tensor(self.conv_module.weight.data)
- 对 q w − Z w q_w-Z_w qw−Zw进行计算
self.conv_module.weight.data = self.conv_module.weight.data - self.qw.zero_point
- 对
self.conv_module.bias进行量化
self.conv_module.bias.data = quantize_tensor(self.conv_module.bias.data, scale=self.qi.scale * self.qw.scale, zero_point=0, num_bits=32, signed=True)
接着我们对quantize_inference进行解释,其流程是上文公式。
-
x = x - self.qi.zero_point。 即为 q x − Z x q_x-Z_x qx−Zx,值得我们注意的是x是已经量化过得 q x q_x qx。 -
x = self.conv_module(x)。进行卷积运算,即 ∑ i N ( q w − Z w ) ( q x − Z x ) + q b \sum_{i}^{N}\left(q_{w}-Z_{w}\right)\left(q_{x}-Z_{x}\right)+q_{b} ∑iN(qw−Zw)(qx−Zx)+qb -
x = self.M * x \n x.round_()。进行运算 S w S x S a ( ∑ i N ( q w − Z w ) ( q x − Z x ) + q b ) \frac{S_{w} S_{x}}{S_{a}}\left(\sum_{i}^{N}\left(q_{w}-Z_{w}\right)\left(q_{x}-Z_{x}\right)+q_{b}\right) SaSwSx(∑iN(qw−Zw)(qx−Zx)+qb),并进行四舍五入。 -
x = x + self.qo.zero_point。进行最终计算 q a = S w S x S a ( ∑ i N ( q w − Z w ) ( q x − Z x ) + q b ) + Z a q_{a}=\frac{S_{w} S_{x}}{S_{a}}\left(\sum_{i}^{N}\left(q_{w}-Z_{w}\right)\left(q_{x}-Z_{x}\right)+q_{b}\right)+Z_{a} qa=SaSwSx(∑iN(qw−Zw)(qx−Zx)+qb)+Za -
x.clamp_(0., 2.**self.num_bits-1.).round_()。截断并进行返回。
2.2 其他模块的量化
理解 QConv2d 后,其他模块基本上异曲同工,这里不再赘述。
具体代码如下
"""
QLinear 全连接层的量化
:fc_module: 全连接网络模块
:qi: 是否对输入特征图
:qo: 是否对输出特征图进行量化
:num_bits: 8位bit数
"""
class QLinear(QModule):
def __init__(self, fc_module, qi=True, qo=True, num_bits=8):
super(QLinear, self).__init__(qi=qi, qo=qo, num_bits=num_bits)
self.num_bits = num_bits
self.fc_module = fc_module #全连接模块
self.qw = QParam(num_bits=num_bits) #定义一个类self.qw,主要是全连接层的权重参数
def freeze(self, qi=None, qo=None):
if hasattr(self, 'qi') and qi is not None:
raise ValueError('qi has been provided in init function.')
if not hasattr(self, 'qi') and qi is None:
raise ValueError('qi is not existed, should be provided.')
if hasattr(self, 'qo') and qo is not None:
raise ValueError('qo has been provided in init function.')
if not hasattr(self, 'qo') and qo is None:
raise ValueError('qo is not existed, should be provided.')
if qi is not None:
self.qi = qi
if qo is not None:
self.qo = qo
self.M = self.qw.scale * self.qi.scale / self.qo.scale
self.fc_module.weight.data = self.qw.quantize_tensor(self.fc_module.weight.data)
self.fc_module.weight.data = self.fc_module.weight.data - self.qw.zero_point
self.fc_module.bias.data = quantize_tensor(self.fc_module.bias.data, scale=self.qi.scale * self.qw.scale,
zero_point=0, num_bits=32, signed=True)
def forward(self, x):
if hasattr(self, 'qi'): #不用对输入进行在量化
self.qi.update(x)
x = FakeQuantize.apply(x, self.qi)
# 其中self.qw类的对象,update主要是求出x的最大值和最小值,尺度因子和零点
self.qw.update(self.fc_module.weight.data) #对
#全连接层
x = F.linear(x, FakeQuantize.apply(self.fc_module.weight, self.qw), self.fc_module.bias)
#将输出进行量化
if hasattr(self, 'qo'):
self.qo.update(x)
x = FakeQuantize.apply(x, self.qo)
return x
def quantize_inference(self, x): #量化推理
x = x - self.qi.zero_point
x = self.fc_module(x)
x = self.M * x
x.round_()
x = x + self.qo.zero_point
x.clamp_(0., 2.**self.num_bits-1.).round_()
return x
"""
QRelu Relu函数
:qi: 是否需要量化输入特征,默认为False
:num_bits: 8位bit数
"""
class QReLU(QModule):
def __init__(self, qi=False, num_bits=None):
super(QReLU, self).__init__(qi=qi, num_bits=num_bits)
def freeze(self, qi=None):
if hasattr(self, 'qi') and qi is not None:
raise ValueError('qi has been provided in init function.')
if not hasattr(self, 'qi') and qi is None:
raise ValueError('qi is not existed, should be provided.')
if qi is not None:
self.qi = qi
def forward(self, x):
if hasattr(self, 'qi'): #如果有qi,我们需要对其进行量化更新
self.qi.update(x)
x = FakeQuantize.apply(x, self.qi)
x = F.relu(x) #进行rule激活并进行返回
return x
def quantize_inference(self, x):
x = x.clone()
x[x < self.qi.zero_point] = self.qi.zero_point
return x
"""
QRelu Relu函数
:kernel_size: 卷积核的尺寸
:stride: 步幅
:padding: 填充
:qi: 是否量化输入的特征张量, 默认为False
:num_bits: bit数
"""
class QMaxPooling2d(QModule):
def __init__(self, kernel_size=3, stride=1, padding=0, qi=False, num_bits=None):
super(QMaxPooling2d, self).__init__(qi=qi, num_bits=num_bits)
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
def freeze(self, qi=None):
if hasattr(self, 'qi') and qi is not None:
raise ValueError('qi has been provided in init function.')
if not hasattr(self, 'qi') and qi is None:
raise ValueError('qi is not existed, should be provided.')
if qi is not None:
self.qi = qi
def forward(self, x):
if hasattr(self, 'qi'): #不对输入特征图进行重新的量化
self.qi.update(x)
x = FakeQuantize.apply(x, self.qi)
x = F.max_pool2d(x, self.kernel_size, self.stride, self.padding) #直接进行池化操作
return x
def quantize_inference(self, x):
return F.max_pool2d(x, self.kernel_size, self.stride, self.padding)
3 量化模型的构架
在卷积,池化,激活和全连接层的量化模块构造之后,便是对量化模型的具体构建,我们可以参照神经网络量化基础(1)——模型的构建与基础量化函数的实现的网络结构。
def quantize(self, num_bits=8): #构建量化神经网络
self.qconv1 = QConv2d(self.conv1, qi=True, qo=True, num_bits=num_bits) #这一过程仅仅量化了一些参数
self.qrelu1 = QReLU() #Relu
self.qmaxpool2d_1 = QMaxPooling2d(kernel_size=2, stride=2, padding=0) #Maxpooling2d
self.qconv2 = QConv2d(self.conv2, qi=False, qo=True, num_bits=num_bits) #对第二次卷积量化一些参数,与第一次基本一致
self.qrelu2 = QReLU() #Relu
self.qmaxpool2d_2 = QMaxPooling2d(kernel_size=2, stride=2, padding=0) #Maxpooling2d
self.qfc = QLinear(self.fc, qi=False, qo=True, num_bits=num_bits) #全连接层
def quantize_forward(self, x):
x = self.qconv1(x)
x = self.qrelu1(x)
x = self.qmaxpool2d_1(x)
x = self.qconv2(x)
x = self.qrelu2(x)
x = self.qmaxpool2d_2(x)
x = x.view(-1, 5*5*40)
x = self.qfc(x)
return x
def freeze(self): #下面的 freeze 函数会在统计完 min,max 后对一些变量进行固化
self.qconv1.freeze()
self.qrelu1.freeze(self.qconv1.qo)
self.qmaxpool2d_1.freeze(self.qconv1.qo)
self.qconv2.freeze(qi=self.qconv1.qo)
self.qrelu2.freeze(self.qconv2.qo)
self.qmaxpool2d_2.freeze(self.qconv2.qo)
self.qfc.freeze(qi=self.qconv2.qo)
def quantize_inference(self, x):
qx = self.qconv1.qi.quantize_tensor(x)
qx = self.qconv1.quantize_inference(qx)
qx = self.qmaxpool2d_1.quantize_inference(qx)
qx = self.qconv2.quantize_inference(qx)
qx = self.qmaxpool2d_2.quantize_inference(qx)
qx = qx.view(-1, 5*5*40)
qx = self.qfc.quantize_inference(qx)
out = self.qfc.qo.dequantize_tensor(qx)
return out