DL | YOLO模型剪枝方法简介
文章目录
- 1. CNN模型model slimming常用方法
-
- 1.1 Low-rank Decomposition
- 1.2 Weight Quantization
- 1.3 Weight Pruning / Sparsifying
- 1.4 Structured Pruning / Sparsifying
- 1.5 Neural Architecture Learning
- 1.6 参考资料
- 2. YOLO V3 剪枝思路
-
- 2.1 主要思路
- 2.2 参考文献
- 3. YOLO V3剪枝开源项目简介
-
- 3.1 [Lam1360/YOLOv3-model-pruning](https://github.com/Lam1360/YOLOv3-model-pruning)
- 3.2 [tanluren/yolov3-channel-and-layer-pruning](https://github.com/tanluren/yolov3-channel-and-layer-pruning)
- 3.3 [coldlarry/YOLOv3-complete-pruning](https://github.com/coldlarry/YOLOv3-complete-pruning)
- 3.4 其他开源项目
- 4. 剪枝项目示例
-
- 4.1 操作流程
- 4.2 剪枝细节
-
- 4.2.1 正常剪枝
- 4.2.2 规整剪枝
- 4.2.3 极限剪枝
- 4.2.4 Tiny剪枝
1. CNN模型model slimming常用方法
1.1 Low-rank Decomposition
用像SVD这样的方法得到的低秩矩阵,去近似模型中的权重矩阵;这种方法特别适合全连接层,可以减小3倍的模型大小,不过并不能显著提高速度,因为CNN中的计算操作主要来自卷积层;
1.2 Weight Quantization
把模型的参数映射到若干组,每个组内部共享权重;只需要存储映射的分组关系和共享的权重即可。这样可以节约大量的存储空间。在AlexNet和VGGNet上可以达到35~49倍的压缩率。不过这种方法无法节约运行需要的存储和推断的时间。
有的研究尝试把实数值的权重映射为若干整数值,这大大减少了模型的大小,不过也损失了一些准确率。
1.3 Weight Pruning / Sparsifying
在一个训练好的神经网络中,把绝对值小的权重置为零,这样模型就变得很稀疏,这样可以节约存储空间。不过这种情况下,如果要提高速度,需要有支持稀疏矩阵运算的软硬件资源。
1.4 Structured Pruning / Sparsifying
去掉模型的某些小权重的通道,然后对模型进行重新微调训练。有的研究表明,这样可以做的比较小的精度损失。
在模型训练的时候,可以用group sparsity regualarization来实现神经元、卷积核、通道、层的稀疏化,从而起到剪枝的效果。
由于这些稀疏化方法并不是针对单个权重的,因此对特殊的稀疏运算的软硬件依赖也会小一些。
1.5 Neural Architecture Learning
model slimming也可以看做模型结构学习的一种,不过模型结构限制在每层的宽度。与强化学习来进行结构学习的方法相比,model slimming进行结构学习要容易一些。
1.6 参考资料
Liu Z , Li J , Shen Z , et al. Learning Efficient Convolutional Networks through Network Slimming[C]// 2017 IEEE International Conference on Computer Vision (ICCV). IEEE, 2017.
2. YOLO V3 剪枝思路
2.1 主要思路
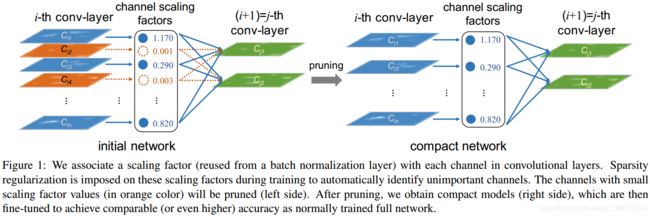
(1)利用batch normalization中的缩放因子γ 作为重要性因子,即γ越小,所对应的channel不太重要,就可以裁剪(pruning)。
(2)约束γ的大小,在目标方程中增加一个关于γ的L1正则项,使其稀疏化,这样可以做到在训练中自动剪枝,这是以往模型压缩所不具备的。
(3)方法示意图如下
原模型的损失函数修改为:

上述损失函数和常规损失函数的区别为加了第二项,其中g(s)=|s|,可以提高提高系数γ的稀疏性;
其中γ为Batch Normalization层的参数,如下式所示,其中z_in和z_out分别为BN层的输入和输出:

2.2 参考文献
Liu Z , Li J , Shen Z , et al. Learning Efficient Convolutional Networks through Network Slimming[C]// 2017 IEEE International Conference on Computer Vision (ICCV). IEEE, 2017.
3. YOLO V3剪枝开源项目简介
3.1 Lam1360/YOLOv3-model-pruning
用 YOLOv3 模型在一个开源的人手检测数据集oxford hand上做人手检测,并在此基础上做模型剪枝。对于该数据集,对 YOLOv3 进行 channel pruning 之后,模型的参数量、模型大小减少 80% ,FLOPs 降低 70%,前向推断的速度可以达到原来的 200%,同时可以保持 mAP 基本不变。
本代码基于论文Learning Efficient Convolutional Networks Through Network Slimming (ICCV 2017) 进行改进实现的 channel pruning算法。原始论文中的算法是针对分类模型的,基于 BN 层的 gamma 系数进行剪枝的。
3.2 tanluren/yolov3-channel-and-layer-pruning
本项目以ultralytics/yolov3为基础实现,根据论文Learning Efficient Convolutional Networks Through Network Slimming (ICCV 2017)原理基于bn层Gmma系数进行通道剪枝,下面引用了几种不同的通道剪枝策略,并对原策略进行了改进,提高了剪枝率和精度;在这些工作基础上,又衍生出了层剪枝,本身通道剪枝已经大大减小了模型参数和计算量,降低了模型对资源的占用,而层剪枝可以进一步减小了计算量,并大大提高了模型推理速度;通过层剪枝和通道剪枝结合,可以压缩模型的深度和宽度,某种意义上实现了针对不同数据集的小模型搜索。
项目的基本工作流程是,使用yolov3训练自己数据集,达到理想精度后进行稀疏训练,稀疏训练是重中之重,对需要剪枝的层对应的bn gamma系数进行大幅压缩,理想的压缩情况如下图,然后就可以对不重要的通道或者层进行剪枝,剪枝后可以对模型进行微调恢复精度。
3.3 coldlarry/YOLOv3-complete-pruning
本项目以ultralytics/yolov3为YOLOv3的Pytorch实现,并在YOLOv3-model-pruning剪枝的基础上,推出了4个YOLO-v3剪枝版本。此外,最近还更新了YOLO的1bit、4bit、8bit、16bit量化。
四种方法的效果对比如下:

3.4 其他开源项目
除了以上三个之外还有 manishravula/yolov3_tiny_pruned,taheritajar/yolov3-pruning等,这些项目基本都来源于同一篇论文。
4. 剪枝项目示例
以 coldlarry/YOLOv3-complete-pruning为例详细说明,剪枝的操作流程和技术细节。
4.1 操作流程
请参考项目主页,很详细。
4.2 剪枝细节
这里主要参考一篇资料 YOLOV3剪枝方法汇总。
4.2.1 正常剪枝
使用了正常剪枝模式,不对short cut层(需要考虑add操作的维度一致问题)及上采样层(无BN)进行裁剪。
• 找到需要裁剪的BN层的对应的索引;
• 每次反向传播前,将L1正则产生的梯度添加到BN层的梯度中;
• 设置裁剪率进行裁剪;
• 将需要裁剪的层的BN层的γ参数的绝对值提取到一个列表并从小到大进行排序,若裁剪率0.8,则列表中0.8分位数的值为裁剪阈值;
• 将小于裁剪阈值的通道的γ置为0;
• 验证裁剪后的MAP(并没有将β置为0);
• 创建新的模型结构,β合并到下一个卷积层中BN中的running_mean计算;
• 生成新的模型文件。
4.2.2 规整剪枝
规整剪枝就是让网络层的通道数剪枝之后仍然是预先设定的2^n这种形式,有利于模型的推理速度提升以及内存占用降低。
• 找到需要裁剪的BN层的对应的索引;
• 每次反向传播前,将L1正则产生的梯度添加到BN层的梯度中。
• 设置裁剪率进行裁剪:
(a)将需要裁剪的层的BN层的γ参数的绝对值提取到一个列表并从小到大进行排序,若裁剪 率0.8,则列表中0.8分位数的值为裁剪阈值;
(b)将小于裁剪阈值的通道提取出来;如果整层的通道γ均低于阈值,为了避免整层被裁剪,保留该层中γ值最大的几个(根据layer_keep参数设置,最小为1,形式为2^n)通道;
• 验证裁剪模型之后的MAP;
• 实际裁剪模型参数,β合并到下一个卷积层中BN中的running_mean计算。验证MAP,比较模型参数量及inference速度;
• 生成新的模型文件。
4.2.3 极限剪枝
正常剪枝和规整剪枝时它们都没有对shortcut层前的卷积层以及上采样层前的卷积层进行剪枝,下面的代码展示了常规/规整剪枝忽略了哪些层如下:
def parse_module_defs(module_defs):
CBL_idx = []#Conv+BN+ReLU
Conv_idx = []#Conv
for i, module_def in enumerate(module_defs):
if module_def['type'] == 'convolutional':
if module_def['batch_normalize'] == '1':
CBL_idx.append(i)
else:
Conv_idx.append(i)
ignore_idx = set()#哪些层不需要剪枝
for i, module_def in enumerate(module_defs):
# 忽略shortcut层前面邻接的卷积层
if module_def['type'] == 'shortcut':
ignore_idx.add(i-1)
identity_idx = (i + int(module_def['from']))
if module_defs[identity_idx]['type'] == 'convolutional':
ignore_idx.add(identity_idx)
elif module_defs[identity_idx]['type'] == 'shortcut':
ignore_idx.add(identity_idx - 1)
# 忽略上采样层
ignore_idx.add(84)
ignore_idx.add(96)
prune_idx = [idx for idx in CBL_idx if idx not in ignore_idx]
# 返回CBL组件的id,单独的Conv层的id,以及需要被剪枝的层的id
return CBL_idx, Conv_idx, prune_idx
因此,常规剪枝是剪得是不够"极限"的,因此在极限剪枝这个方法里面仅仅忽略上采样层前面卷积层(一共222个),shortcut相邻的卷积层全部参与剪枝,即实现了极限的YOLO-V3剪枝。
4.2.4 Tiny剪枝
所谓Tiny剪枝,是给轻量级的YOLO-V3版本(YOLO-V3 -Tiny)剪枝。
和YOLOV3剪枝只有解析模型的时候有一点差别,即生成CBL_idx,Conv_idx,
prune_idx的函数针对YOLOV3-Tiny的模型结构做了一个小变化,代码如下:
def parse_module_defs(module_defs):
CBL_idx = []
Conv_idx = []
for i, module_def in enumerate(module_defs):
if module_def['type'] == 'convolutional':
if module_def['batch_normalize'] == '1':
CBL_idx.append(i)
else:
Conv_idx.append(i)
ignore_idx = set()
# 只用忽略唯一一个上采样层前面的卷积层即可
ignore_idx.add(18)
prune_idx = [idx for idx in CBL_idx if idx not in ignore_idx]
return CBL_idx, Conv_idx, prune_idx
但建议慎重对YOLOV3-Tiny进行剪枝,对于一个类别训练出的YOLOV3模型不影响准确率的情况下基本不能剪掉任何参数,所以需要自己实测来判断自己的数据集是否剪枝后会对模型的准确率造成较大损害。