实战 | 史上最详细Hadoop大数据集群搭建,不看后悔系列
文章目录
-
- 1. 搭建环境
-
-
- 1.1 实验环境
- 1.2 架构模型
- 1.3 前期准备
-
- 2. 软件环境依赖部署
-
-
- 2.1 jdk安装及配置
- 2.2 ssh免密钥配置
-
- 3. Hadoop及Zookeeper部署
-
-
- 3.1 Hadoop安装及配置
-
- 3.1.1 解压hadoop-2.6.5.tar.gz:
- 3.1.2 修改配置文件/etc/profile:
- 3.1.3 修改 hadoop-env.sh 和 mapred-env.sh 配置文件
- 3.1.4 配置hdfs-site.xml 文件
- 3.1.5 配置 core-site.xml 和 Slaves 文件
-
- 3.1.5.1 core-site.xml 文件的配置
- 3.1.5.2 Slaves 文件的配置
- 3.1.6 Hadoop 分发以及 HA HDFS on yarn 配置
-
- 3.1.6.1 Hadoop 分发
- 3.1.6.2 HA HDFS on yarn 配置
- 3.2 ZooKeeper 安装及配置
-
- 3.2 .1 ZooKeeper 安装
- 3.2 .1 ZooKeeper 配置
- 3.3 HDFS 、ZooKeeper 和 yarn 启动
-
- 3.3.1 启动 ZooKeeper
- 3.3.2 启动 HDFS
- 3.3.3 启动 yarn
-
1. 搭建环境
1.1 实验环境
本文基于 HA 分布式文件系统(HDFS),搭建 MapReduce on yarn 大数据集群。总共需要四台虚拟机node01、node02、node03、node04,各个角色进程的分配如下表所示:
| 虚拟机 | Namenode-1 | Namenode-2 | Datanode | zookeeper | zkfc | journalnode | ResourceManager | NodeManager |
|---|---|---|---|---|---|---|---|---|
| node01 | * | * | * | |||||
| node02 | * | * | * | * | * | * | ||
| node03 | * | * | * | * | * | |||
| node04 | * | * | * | * |
1.2 架构模型
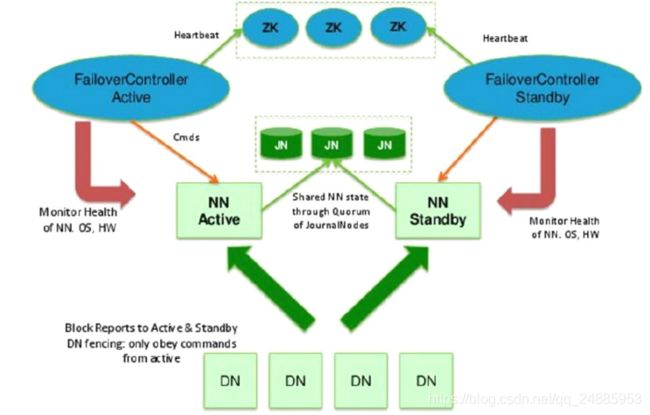
HDFS 2.x 通过Namenode主备模型解决了 HDFS 1.x 的单点故障和内存受限问题。本文采用基于 ZooKeeper 的名称节点自动切换方案。由 ZooKeeper Failover Controller 进程实时的监控 namenode 的健康状态,ZooKeeper Failover Controller 进程帮助 Namenode 向 ZooKeeper 争抢锁,获得锁的 Namenode 成为 Active ,另一台 Namenode 为 standby。 Active 对外提供服务,Standby 通过 journalnode 保持通信,同步 Active 元数据,随时以待切换。此外,Standby 完成了edits.log 文件的合并,并产生新的 image ,然后推回给 Active。如果 Active 发生故障,则自动切换到备 Standby。Datanode 同时向 Active 和 Standby 保持心跳,报告数据块的信息。HDFS 2.x 的架构模型如下图所示:
1.3 前期准备
- 修改 /etc/hosts 文件,使IP地址与主机一一映射。
//修改node01/etc/hosts文件:
[root@node01~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.179.101 node01
192.168.179.102 node02
192.168.179.103 node03
192.168.179.104 node04
- 软件包资源
jdk-7u67-linux-x64.rpm、hadoop-2.6.5.tar.gz、zookeeper-3.4.6.tar.gz:
软件包百度网盘资源链接
提取码:2nma
2. 软件环境依赖部署
众所周知,Hadoop是由热门的Java语言开发的,所以,大数据集群的运行需要依赖Java环境。首先,需要准备java环境。
2.1 jdk安装及配置
把jdk-7u67-linux-x64.rpm、hadoop-2.6.5.tar.gz两个软件包通过ftp上传到node01/home目录下:
- 解压jdk-7u67-linux-x64.rpm:
//将jdk解压至node01的/usr/local目录下
[root@node01 ~]# rpm -ivh jdk-7u67-linux-x64.rpm
- 修改配置文件/etc/profile:
[root@node01 ~]# vi /etc/profile

- 执行并验证
1 [root@node01 ~]# source /etc/profile //使配置文件生效
2 [root@node01 ~]# jps //验证Java环境
1348 jps //java环境成功安装
- 分发给node02、node03、node04
//将jdk部署到其它三台机器
[root@node01 ~]# scp -r /usr/local/java node02:/usr/local/
[root@node01 ~]# scp -r /usr/local/java node03:/usr/local/
[root@node01 ~]# scp -r /usr/local/java node04:/usr/local/
//将配置文件远程拷贝到其它三台机器
[root@node01 ~]# scp -r /etc/profile node02:/etc/
[root@node01 ~]# scp -r /etc/profile node03:/etc/
[root@node01 ~]# scp -r /etc/profile node04:/etc/
2.2 ssh免密钥配置
- 免密钥需求场景
- 管理脚本远程管理其它节点启停服务时,namenode上的管理脚本需要免密钥访问其他节点
- 在HA架构模型中,主备namenode上的ZKFC需要通过免密钥控制对方和自己
[root@node01 ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa //获取密钥,四台节点都要做
##想免密钥访问谁,就把自己的公钥放到谁的authorized_keys文件中
1 [root@node01 .ssh]# cat id_dsa.pub >> authorized_keys //和自己免密钥
2 [root@node01 .ssh]# scp id_dsa node02:`pwd`/node01.pub //把node01公钥发给node02,并命名为node01.pub
3 [root@node02 .ssh]# cat node01.pub >> authorized_keys //实现了node01对node02的免密钥登录
##对node03、node04采用上述2、3步骤
##本集群搭建需要做node01免密钥访问node02、node03、node04
##以及node02免密钥访问node01
3. Hadoop及Zookeeper部署
3.1 Hadoop安装及配置
3.1.1 解压hadoop-2.6.5.tar.gz:
为了简便,只需要在 node01 上安装和配置好 Hadoop ,然后通过远程拷贝命令分发给 node02、node03、node04。
//将hadoop-2.6.5.tar.gz解压至node01的/opt/soft目录下
[root@node01 ~]# tar -zxvf hadoop-2.6.5.tar.gz
[root@node01 ~]# mv hadoop-2.6.5 /opt/soft //把解压的目录移动至/opt/soft
3.1.2 修改配置文件/etc/profile:
[root@node01 ~]# vi /etc/profile
export JAVA_HOME=/usr/java/jdk1.7.0_67
export HADOOP_HOME=/opt/sxt/hadoop-2.6.5 #配置家目录
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin #配置bin和sbin执行目录

3.1.3 修改 hadoop-env.sh 和 mapred-env.sh 配置文件
在 Hadoop 中主要修改的配置文件有以下7个:
hadoop-env.sh、mapred-env.sh、hdfs-site.xml、core-site.xml、slaves、mapred-site.xml、yarn-site.xml。
在 MR 离线计算时,名称节点在使用脚本远程访问其它节点时,不会读取到 /etc/pofile 文件的 java 配置,所以要在这两个文件中配置 java 的绝对路径,上述配置的 JAVA_HOME。
[root@node01~]# cd $HADOOP_HOME
[root@node01 hadoop-2.6.5]# cd etc/hadoop
[root@node01 hadoop]# vi hadoop-env.sh

[root@node01 hadoop]# vi mapred-env.sh

3.1.4 配置hdfs-site.xml 文件
该文件的配置总共包含以下五点:
- 指定存放block块的数据节点(Datanode)的副本数,一般不超过所设定的数据节点数,本文设为3,提供以下配置源代码:
[root@node01 hadoop]# vi hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
- 逻辑到物理的映射,namenode服务集群node01、node02,以及他们的启动时所用的端口:8020,和浏览器访问时所用的端口:50070。提供以下配置源代码:
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node02:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node02:50070</value>
</property>
- journalnode相关信息配置,包括三台journalnode的节点及启动端口,和存放数据的目录。提供以下配置源代码:
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node01:8485;node02:8485;node03:8485/mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/var/hadoop/ha/jn</value>
</property>
- 故障的切换的实现和代理。提供以下配置源代码:
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
- 实现 HDFS 的 HA(高可用)模型自动故障转移开关,打开后,会在名称节点上创建 ZooKeeper Failover Controller 进程,监控名称节点的健康状态。提供以下配置源代码:
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
3.1.5 配置 core-site.xml 和 Slaves 文件
3.1.5.1 core-site.xml 文件的配置
- fs.defaultFS 的入口修改为上述配置的逻辑名称:hdfs://mycluster
[root@node01 hadoop]# vi core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/hadoop/ha</value>
</property>
注意:hadoop.tmp.dir 是存放数据的目录,默认是 /tmp/ ,需要手动指定一个持久目录例:/var/hadoop/ha
- ZooKeeper Failover Controller 会用到 ZooKeeper ,需要配置 ZooKeeper 节点信息
<property>
<name>ha.zookeeper.quorum</name>
<value>node02:2181,node03:2181,node04:2181</value>
</property>
3.1.5.2 Slaves 文件的配置
配置数据节点(Datanode)的位置:
[root@node01 hadoop]# vi slaves
#打开后添加如下内容:
node02
node03
node04
3.1.6 Hadoop 分发以及 HA HDFS on yarn 配置
3.1.6.1 Hadoop 分发
鉴于以上所有的操作全部都在 node01 虚拟机上操作,所以需要把 node01 上安装配置好的 Hadoop 远程分发到 node02 、node03 、node04 上。
#分发 Hadoop
[root@node01~]# cd $HADOOP_HOME //回到 hadoop 的家目录
[root@node01 hadoop-2.6.5]# scp ./hadoop-2.6.5/ node2:`pwd`
[root@node01 hadoop-2.6.5]# scp ./hadoop-2.6.5/ node3:`pwd`
[root@node01 hadoop-2.6.5]# scp ./hadoop-2.6.5/ node4:`pwd`
#分发 Hadoop 的配置文件 /etc/profile
[root@node01 hadoop-2.6.5]# cd //回到家目录
[root@node01~]# scp /etc/profile node02:/etc/
[root@node01~]# scp /etc/profile node03:/etc/
[root@node01~]# scp /etc/profile node04:/etc/
3.1.6.2 HA HDFS on yarn 配置
- yarn 是 Hadoop 2.x 新引入的资源管理系统,yarn 的引入把资源管理和计算调度进行解耦,可使得多个计算框架运行在一个集群,如MapReduce、spark、storm 。yarn 主要有 Resourcemanager (负责整个集群的资源管理及调度)和 Nodemanager (向 RM 汇报集群节点的资源使用情况,管理container的生命周期)两个角色。
该项配置主要包括 mapre-site.xml 和 yarn-site.xml 两个文件:
[root@node01 hadoop]# cp mapre-site.xml.template mapre-site.xml //复制一份
[root@node01 hadoop]# vi mapre-site.xml
#实现了 MapReduce on yarn
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
注:以上为配置源代码
[root@node01 hadoop]# vi yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node03</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node04</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node02:2181,node03:2181,node04:2181</value>
</property>
注: 以上为配置源代码。主要配置 Resourcemanager 和 Nodemanager 的主机位置
- 将 mapre-site.xml 和 yarn-site.xml 两个文件分发给 node02。
[root@node01 hadoop]# scp mapre-site.xml yarn-site.xml node02:`pwd`
至此所有虚拟机 Hadoop 的安装及配置已经完成。
3.2 ZooKeeper 安装及配置
由 1.1 中的角色进程分配表可知,ZooKeeper 分配在node02、node03、node04 三台节点上,所以只需要在 node02 上安装配置好 ZooKeeper ,然后通过远程拷贝命令分发给 node03、node04。
3.2 .1 ZooKeeper 安装
[root@node02~]# tar -zxvf zookeeper-3.4.6.tar.gz
[root@node02~]# mv zookeeper-3.4.6.tar.gz /opt/soft //把解压的文件移至此目录
[root@node02~]# vi /etc/profile
//配置 ZooKeeper home 目录和 bin 目录
export JAVA_HOME=/usr/java/jdk1.7.0_67
export HADOOP_HOME=/opt/sxt/hadoop-2.6.5
export ZOOKEEPER_HOME=/opt/sxt/zookeeper-3.4.6
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin
3.2 .1 ZooKeeper 配置
[root@node02~]# cd $ZOOKEEPER_HOME
[root@node02 zookeeper-3.4.6]# cd conf
[root@node02 conf]# mv zoo_sample.cfg zoo.cfg //复制一份并重命名为 zoo.cfg
[root@node02 conf]# vi zoo.cfg
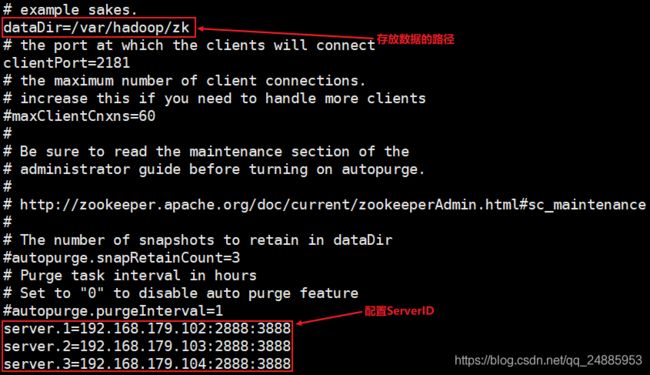
保存后退出。
创建刚刚配置的目录,并把事务 id 存入 myid 文件中。
[root@node02 conf]# mkdir -p /var/hadoop/zk //创建目录
[root@node02 conf]# echo 1 >> /var/hadoop/zk/myid //把事务 id 存入 myid 文件中
[root@node02 conf]# cd /opt/soft
[root@node02 soft]# scp -r ./zookeeper-3.4.6 node03:`pwd` //将 ZooKeeper 分发给node03
[root@node02 soft]# scp -r ./zookeeper-3.4.6 node04:`pwd` //将 ZooKeeper 分发给node04
//同时将 /etc/profile 配置文件分发给 node03 node04
[root@node02 soft]# scp -r /etc/profile node03:/etc/
[root@node02 soft]# scp -r /etc/profile node03:/etc/
值得注意的是,需要分别切换到 node03 、node04 上,重复创建目录和存事务 id两件事。
# 在 node03 上:
[root@node03 ~]# mkdir -p /var/hadoop/zk //创建目录
[root@node03 ~]# echo 2 >> /var/hadoop/zk/myid //把事务 id 存入 myid 文件中
# 在 node04 上:
[root@node04 ~]# mkdir -p /var/hadoop/zk //创建目录
[root@node04 ~]# echo 3 >> /var/hadoop/zk/myid //把事务 id 存入 myid 文件中
值得恭喜,Hadoop 和 ZooKeeper 两个软件都已经安装配置成功啦!
3.3 HDFS 、ZooKeeper 和 yarn 启动
3.3.1 启动 ZooKeeper
# 分别在 node02 node03 node04 执行以下命令,依次启动 ZooKeeper,ZooKeeper 要先启动
[root@node02 ~]# zkServer.sh start
3.3.2 启动 HDFS
启动 HDFS 前,需要格式化 Namenode,格式化 Namenode 前需要启动 journalnode ,因为主备两台 Namenode 需要通过 journalnode 传递数据。
# 第一、分别在 node01 node02 node03 执行以下命令,依次启动 journalnode
[root@node01 ~]# hadoop-daemon.sh start journalnode
# 第二、在 node01 上格式化 namenode
[root@node01 ~]# hdfs namenode -format
# 第三、启动 node01 上的 namenode
[root@node01 ~]# hadoop-daemon.sh start namenode
# 第四、在 node02 上同步
[root@node02 ~]# hdfs namenode -bootstrapStandby
# 第五、在 node01 上格式化 ZooKeeper,此步是启动 ZooKeeper Failover Controller 进程的前置依赖
[root@node01 ~]# hdfs zkfc -formatZK
注意:第二步,需要见到 successfully 字样,namenode才算格式化成功,否则重来

两次格式化做完,终于可以启动 HDFS 了。
# 在 node01 上 执行以下命令启动 HDFS
[root@node01 ~]# start-dfs.sh
# 在四台虚拟机上执行 jps 命令验证 HDFS 启动情况
# node01
[root@node01 ~]# jps
4213 NameNode
5148 Jps
4089 JournalNode
4650 DFSZKFailoverController
# node02
[root@node02 ~]# jps
3099 DFSZKFailoverController
2809 JournalNode
1813 QuorumPeerMain
2923 NameNode
4475 Jps
# node03
[root@node03 ~]# jps
2372 Jps
1610 QuorumPeerMain
2171 JournalNode
# node04
[root@node04 ~]# jps
1511 QuorumPeerMain
1982 Jps
3.3.3 启动 yarn
# 第一、在 node01 上执行以下命令,启动 三台 Nodemanager
[root@node01 ~]# start-yarn.sh
# 第二、在 node03 上执行以下命令,手工启动 Resourcemanager
[root@node03 ~]# yarn-daemon.sh start resourcemanager
# 第三、在 node04 上执行以下命令,手工启动 Resourcemanager
[root@node04 ~]# yarn-daemon.sh start resourcemanager
注意:上述命令执行完后,依次在 node02、node03 、node04 上执行 jps 验证:node02 比原来多了一个 NodeManager 进程;node03 和 node04 都多了一个 NodeManager 和 ResourceManager 进程。
结语:感谢你!耐心的看完了这篇文章!也恭喜你!我们又成长了一步!建议大家亲手实践一遍,搭建集群不是最终目的,最重要的是理解整个基于 HDFS ,MapReduce on yarn 架构模型!