Spark 数据依赖图是啥?
0 前言
大家好,我是小林!
本篇文章是 Spark 系列的第二篇文章。
第一篇文章: 还没看的建议先去补课!本文大纲如下:
上篇文章使用一个简单的小案例,给大家说明了一个 Spark 任务,一般先生成 Job 的逻辑执行图,再转换为 Job 的物理执行图,并且它是通过 Action 类算子触发,才会执行。最后,给大家留下了下面几道思考题:
-
一个任务的逻辑执行图,也称数据依赖图,是如何生成的?
-
物理执行图又是如何生成的?
-
Spark 提供了哪些 Transformation 算子、哪些 Action 算子?
今天,针对上述问题,小林为大家拨开迷雾。
1 如何生成 Job 逻辑执行图?
在讨论如何生成 Job 逻辑执行图之前,我先给出 Spark 程序的一个通用逻辑执行图,我们先来分析下逻辑图的通用执行流程。
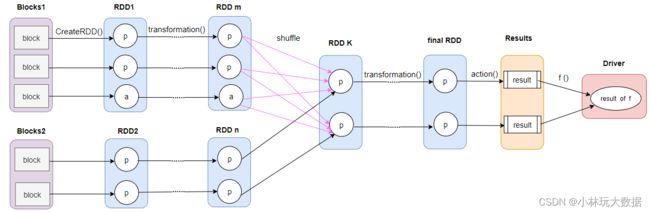
从上述逻辑执行图来看,一般可以抽象出以下几个步骤:
- 从数据源头读取数据,创建出第一个 RDD。
- 对生成的第一个 RDD 进行一系列的形态转换,也就是在 RDD 上执行一系列 transformation 算子,会产生多个不同类型的 RDD[T]。
- 最后的 final RDD 执行 action 算子,触发任务执行,每个 partition 先计算产生结果 result,各个分区再将所得得结果送到 Driver 端,执行 f( list[result] ) 计算。例如上篇文章中的
count()算子,它包含了action()和sum()2 步逻辑。
回到我们本小节讨论的问题,如何生成 Job 逻辑执行图?我们通过分析一个通用的逻辑执行图,了解到一般每个程序都会形成上述类似的数据依赖图(每个不同的 RDD 本质上代表不同的数据形态),值得注意的是,每个任务实际生成的 RDD 个数往往会比我们想象的个数要多的多(2.1会解释原因)。因此,要解决一个任务的逻辑执行图的生成,实际要解决:
- 如何产生这不同的 RDD,应该产生哪些 RDD?
- 如何建立 RDD 之间的依赖关系?
2.1 如何生成 RDD,应该产生哪些 RDD?
关于如何生成 RDD,我们分两种情况来看,第一种是在数据源头执行 createRDD() (目前使用较多的的有 textFile()、parallelize()、makeRDD()),产生整个数据依赖图中的第一个 RDD;第二种是每执行一个 transformation() 则返回一个 RDD(new 一个 RDD),但是 Spark 中很多 transformation 算子本身比较复杂,它的实现会包含多个子 transformation ,因此会生成多个 RDD。这就是实际生成的 RDD 比我们想象的要多的多的原因。
至于应该产生哪些 RDD ,这个与每个 transformation 的计算逻辑有关。官方也给每个 transformation 做了解释。在本文的第三小节,对一些典型的 transformation 作讲解。
总的来说,在 Spark 任务中,由用户所使用的不同算子生成不同的 RDD,生成的 RDD 的类型与其本身的计算逻辑相关。到此,虽然解决了 RDD 生成的问题,但还不足以形成我们所想要的数据依赖图。通过不同算子生成的 RDD 存在着上下游的依赖关系,最终才会形成数据依赖图。这上下游的依赖关系是通过什么规则建立?
如何计算每个 RDD 中有多少条数据?
数据依赖图实际上是一个计算链,每个 transformation 的计算逻辑在哪里被执行?每个 RDD 中都会有 compute() 方法,它负责接收父 RDD 或者数据源的 input records,执行完计算逻辑后输出 records。
2.2 如何建立 RDD 之间的依赖关系
关于如何建立 RDD 之间的数据依赖,解决这三个问题就行了。
- 每个 RDD 本身的依赖关系是怎样的?所产生的 RDD (在后文称为 RDD X)是依赖一个父 RDD,还是多个?
- RDD X 中的分区数由谁决定?
- RDD X 与其父 RDD 中的分区之间是什么依赖关系?是依赖父 RDD 中的一个分区,还是多个分区?
第一个问题很简单,有几个 RDD 参与计算,那 RDD X 就依赖几个,RDD X = rdd a.transformation(rdd b)。表示 RDD X 同时依赖 RDD a 和 RDD b。
第二个问题中的分区数量一般是由用户自己指定,如果用户没有指定,则取所有父 RDD 中最大的分区数量,即:max(numPartitions[parent RDD1],.....numPartitions[RDD n])。
第三个问题较为复杂。每个 RDD 中的分区之间的依赖关系是怎么样的,具体需要根据算子的计算逻辑,不同的算子依赖关系也不同。虽然整个数据依赖图是由多个 RDD 依赖组成,但本质上只要解决上下游两个 RDD 之间的分区是如何依赖的问题。小林只拿上下游 2 个 RDD 作为叙述。
上下游两个 RDD 之间的分区个数有可能相同,也有可能不同,但无非就这么几种情况:
- 1:1,上游 RDD a 与下游 RDD x 中的分区个数一一对应
- N:1,RDD a 中存在多个分区数据对应到 RDD x 中一个分区
- N:N,RDD a 中存在多个分区对应到 RDD x 中多个分区
- 1:N,RDD a 中的一个分区数据对应到 RDD x 中多个分区
为了便于理解,针对以上四种情况,我分别画了几张图:

从上图中可以看到,RDD x 中的每个 partition 可以依赖于父 RDD 中的一个或者多个 partition。前三个,RDD x 中的一个分区与父 RDD 中的某一个分区是完全相关的,我们叫做完全依赖,Spark 称之为 NarrowDepency(窄依赖);最后一个颜色为洋红色的,RDD x 中的一个分区只与父 RDD 中的每个分区中的部分数据相关 ,我们叫做部分依赖,Spark 称之为 ShuffleDepency(宽依赖)。
因此,总结下来 Spark 中 RDD 之间的依赖关系有两类:
- NarrowDepency,也叫作窄依赖,依赖关系有:1:1,N:1 以及 N:N。
- ShuffleDepency,也叫做宽依赖,依赖关系为:1:N。
- 对于窄依赖,具体 RDD x 中的 partition i 依赖 parent RDD 中的一个 partition 还是多个 partition ,是由 RDD x 中的
getParents(partition i)决定的。- 划分窄依赖和宽依赖,是为了生成物理执行图,具体请看本文第二小节。
好了,解决了如何生成 RDD 和如何建立 RDD 之间的依赖关系,也就形成了 Job 的逻辑执行图(也叫数据依赖图),但是最终要把逻辑执行图转换成物理执行图,才能执行。
2 如何生成 Job 物理执行图?
在上一篇的 WordCount 例子中,我画了一个 WordCount 的 DAG 型的物理执行图,里面包含了 Stage 和 task,本小节给大家说清楚,对于一个给定的 Job 逻辑执行图,如何生成 Job 的物理执行图。也就是如何划分 Stage,以及如何生成 task?
小林还是通过下面这个例子,跟你讲讲,一个逻辑执行图,是如何生成物理执行图的。下面这段代码,准备了三份数据,产生了 3 个 RDD ,后 2 个 RDD 先做 union() ,然后再与第一个 RDD 进行 join()。(这里的 union,相当于数学上的两个集合取并集,join 不用我多说了哈)。
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.HashPartitioner
object JobTest {
def main(args: Array[String]) {
val conf = new SparkConf()
conf.setMaster("local").setAppName("test")
val sc = new SparkContext(conf)
val data1 = Array[(Int, Char)](
(1, 'a'), (2, 'b'),
(3, 'c'), (4, 'd'),
(5, 'e'), (3, 'f'),
(2, 'g'), (1, 'h'))
//产生第一个 RDD,分区数为 3
val rangePairs1 = sc.parallelize(data1, 3)
//使用 hash 分区器进行重分区
val hashPairs1 = rangePairs1.partitionBy(new HashPartitioner(3))
val data2 = Array[(Int, String)]((1, "A"), (2, "B"),
(3, "C"), (4, "D"))
//产生第二个 RDD,分区数为 2
val pairs2 = sc.parallelize(data2, 2)
//通过 map 转换为 kvRDD
val rangePairs2 = pairs2.map(x => (x._1, x._2.charAt(0)))
val data3 = Array[(Int, Char)]((1, 'X'), (2, 'Y'))
//产生第三个 RDD,分区数为 2
val rangePairs3 = sc.parallelize(data3, 2)
val rangePairs = rangePairs2.union(rangePairs3)
val result = hashPairs1.join(rangePairs)
result.foreachWith(i => i)((x, i) => println("[result " + i + "] " + x))
println(result.toDebugString)
}
}
根据上述代码,我们很容易可以画出它的逻辑执行图:
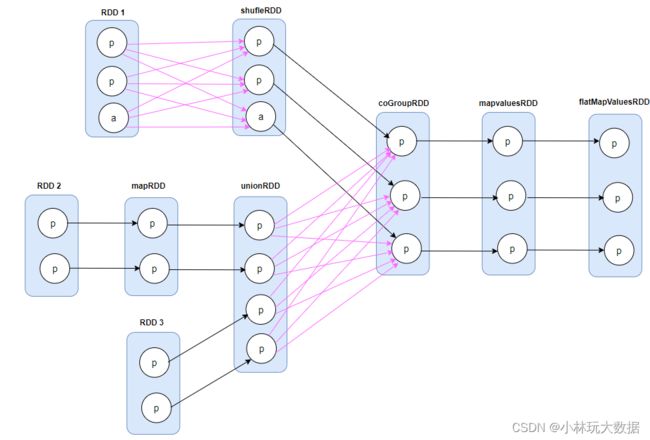
根据上面这样一个复杂的数据依赖图,怎样去划分 stage,确定 task 个数?
第一个思路:很容易让人想到的 stage 划分方法就是上下游 2 个 RDD 划作一个 Stage,每个箭头就产生一个 task;对于 RDD 聚合的情况,便把 3 个RDD 划分为一个 Stage。这样划分便会产生很多个 task(看看上面箭头),执行效率不高,对于很多 task 来说,它会很多的中间数据,占用的内存或者磁盘就会很多。
第二个思路:再仔细观察一下 Job 的物理执行图,在同一个 RDD 中,每个分区之间都是独立的,相当于分区与分区之间的依赖各自互不干扰。因此,是否可以把整个数据依赖图划分成一个 Stage,之后根据最后一个 RDD 的分区数量,每一个分区看作是一个 task,这样便可以确定 3 个 task。

根据第二个思路,划分出来为 3 个 task ,一个 Stage。图中所有的粗实线为第一个 task ,细实线为第二个 task ,虚实线为第三个 task。当第一个 task 计算完成后,第二个和第三个 task 可以复用第一个 task couGroupRDD 中已经计算得到的第二个和第三个 Partition 数据,然后只需要计算 mapvalues 和 flatMapVaules RDD 两步就可以得到结果。按照第二种思路划分,看似已经解决了第一种思路的效率问题和内存过大的问题。但其实还有 2 个难点:
- 第二种思路划分,会导致第一个 task 巨大,在碰到宽依赖(shuffleDepency)时,就必须得计算宽依赖的 RDDs (如 RDD1)的所有分区,而且都是在一个 task 中完成计算;
- 另外,还需要设计一种通用巧妙的算法,以识别一个 RDD 中的哪些分区数据需要保存下来(如 coGroupRDD 中的第二个和第三个分区),以便于其它 task 使用,这种算法比较难统一。
虽然 Spark 没有采取第二种思路去划分 Stage ,但第二中思路中的流水线计算模式(pipeline 思想)值得可取。例如:第一个 task 中,从最后的flatMapValuesRDD 中的 partition 往前推算,只需要计算当前 RDD 所依赖的 RDDs 中的分区。第二个和第三个 task,从 coGroupRDD 到最后的 RDD 计算过程,一条流水线式的计算,不需要存储中间结果。
再来思考 stage 和 task 的划分问题,反观第二种思路的问题,导致第一个 task 变大的主要原因,还是由于在碰到 shuffleDelpency 时,便无法进行 pipeline 计算,不得不计算所有的 RDD,才导致第一个 task 很臃肿。所以, Spark 在划分 stage 时,每碰到 ShuffleDepency(宽依赖) 时, 便产生一个 Stage ,然而窄依赖之间是可以进行 pipeline 计算的,这样就完美解决了上述的问题。按照这种思想,划分出来的 Job 物理执行图如下:
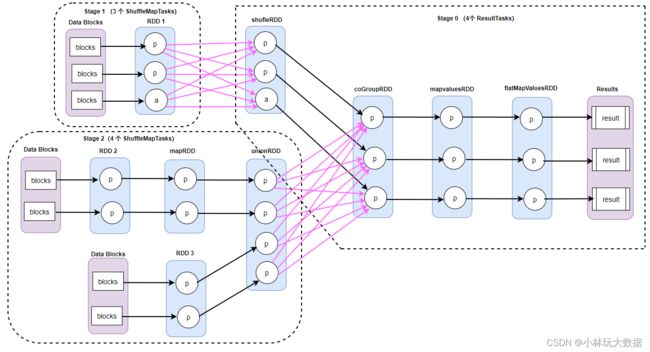
在这个案例中,一共划分了三个 Stage,Stage 0 和 Stage 1 分别都是 3 个 task,stage 2 生成了 4 个task。
所以 Stage 的划分原则:根据数据依赖图从后往前推算,每次遇到宽依赖(shuffleDepency)时就产生一个 Stage,遇到窄依赖(NarrowDependency)就将其加入当前这个 Stage,Stage 中的数量由 Stage 中的 finalRDD 的 partition 数量决定。
生成了 Job 的物理执行图之后,就是 task 执行计算得到最后的 result 了。在 Spark 中,task 的执行采取的是前面所提到的 pipeline 的计算模式。任务会根据物理执行图,从后往前推形成一条条的计算链(如上图中的粗的箭头线,也就是一个个 task 的 pipeline),对于有 parent stage(如上图中的 stage 0),它会先等着所有 parent stage 中的 final RDD 中数据计算完成,然后经过 shuffle 后,再进行计算。
3 常见的 Transformation & Action 算子
其实之前也说了,调用 transformation() 算子进行 RDD 的转换,调用 action() 算子触发任务执行。本质上 RDD 转换是数据形态的转换,所以了解各个算子的适用范围和用途,对于在业务编程中非常有用。在这里,小林给大家整理了一些常用的算子,并且做了一定的分类,供你随时查阅:
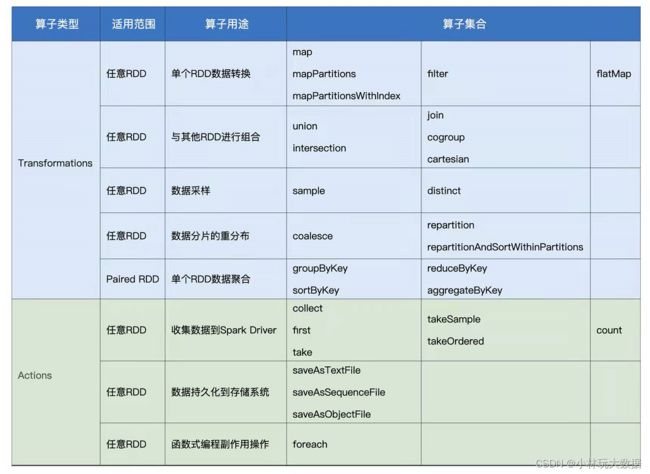
关于算子的使用及含义,本文不再赘述,更多关于算子的讲解,可参考官方文档。
4 总结
本文主要讲了一个 Job 是如何生成 Job 逻辑执行图的,以及如何根据逻辑执行图生成 Job 物理执行图,阐述了为什么 stage 和 task 的划分原则,最后整理了一些常用的转换算子和行动算子。重点回顾:
-
数据依赖关系:
- NarrowDepency,也叫作窄依赖,依赖关系有:1:1,N:1 以及 N:N。
- ShuffleDepency,也叫做宽依赖,依赖关系为:1:N。
-
Stage 划分原则,如何确定 task 数量:
根据数据依赖图从后往前推算,每次遇到宽依赖(shuffleDepency)时就产生一个 Stage,遇到窄依赖(NarrowDependency)就将其加入当前这个 Stage,Stage 中的数量由 Stage 中的 finalRDD 的 partition 数量决定。
好了今天的文章就到这里,我们下期再见,记得给小林点赞,转发、在看呀!你们的点赞就是我更文最大动力!