Flink 面试跳槽指南(1)——带领你疏通航道
Flink 面试跳槽指南(1)
序
作者:Hadi
时间:2022年2月7日
参考各种blog和官方文档,纯手打,如果差错请评论区见,或者提交到CSDN用户:https://blog.csdn.net/qq_36610426
如需转载,也请联系作者。
文章地址:https://blog.csdn.net/qq_36610426/article/details/122821112
Flink 基础

Flink 介绍
Flink是一个面向分布式数据流处理 和 批处理数据的开源计算引擎。用于对无界和有界的数据流进行有状态计算。可以部署在个中级群环境,对各种大小的数据规模进行快速内存计算。
Flink 和Spark Streaming的区别
Flink 和 Spark Streaming都是内存计算引擎,但Flink是标准的实时处理引擎,基于事件驱动。而Spark Streaming是微批(Micro-Batch)计算。
Flink更能对数据进行状态性的操作,设置有water mark等标识,实现的是真正的实时处理计算。
Flink的组件栈有哪些
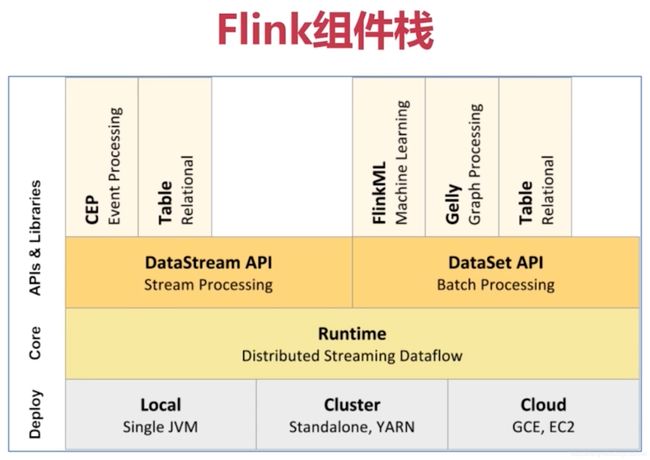
自下而上,每一层都有具体的含义。
Deploy层
基座部署层,这一层主要是涉及到Flink的部署模式,上图我们可以看出,Flink支持在单个Single JVM的Local本地部署,也能基于集群模式的Standalone和on Yarn模式,也能基于云的GCE/EC2部署模式。
Core层
核心层只包含一个内容就是RunTime,提供了Flink的计算核心算法实现,其主要内容就是实时处理和分布式计算相关内容。为上层API层提供核心处理运算,JobGraph到ExecutionGraph的映射等等。
API层
接口层主要是实现了面向流和面向批处理API,其中面向流的就是DataStream API,面向批处理的就是DataSet API。往后这两个API会慢慢统一,合并趋近一致。
Libraries层
框架层,根据API的接口,在API层之上构建满足特定应用的实时计算框架,也分为流处理和批处理两大类。对于流处理支持的 CEP复杂时间处理、基于SQL-like的Table关系操作;面向批处理支持的FlinkML,Gelly等等。
Flink 的运行必须依赖 Hadoop组件吗
不是必须依赖,但属于大数据生态圈中,现在没Hadoop就好像西方没有耶路撒冷。
根据Deploy层可以看到,我们可以基于单机JVM运行,也能基于集群的Standlone模式运行,也可以基于EC2等的云部署运行,所以我们单单运行Flink是可以的。
你们的Flink集群规模多大
提出此开放性问题主要是看看你有没有具体使用过Flink,使用过多大的范围,最好借这个问题引出你自己擅长的下一个话题。
我们的Flink程序都是通过 on Yarn进行部署运行的,通过Yarn的队列资源来运行Flink任务。由于31省都有业务,所以我们有31省的Yarn集群,总共2000+台服务器,其中Flink任务资源占10%,大概运行的实时程序实例有700+,都是我一个人独立开发运行的。这么多实时程序任务,最大的问题其实是监控怎么做,所以我们在监控中下足了功夫(引出其他话题……)。
Flink的基础编程模型了解吗
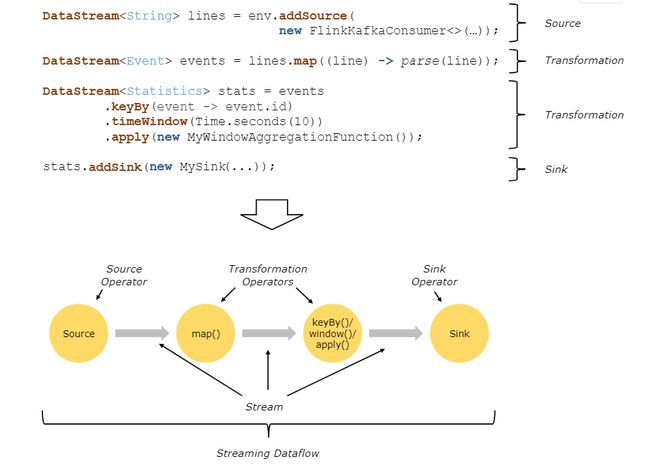
Flink程序流程基本都是 Source -> Transformation -> Sink的流程。
每个任务都是从一个或者多个Source开始,并终止于一个或者多个Sink,中间可以有各种转换、映射、合并、拆分等操作,具体代码示例:
Flink集群有哪些角色,其各自有什么作用
Flink集群中一般有客户端、Flink Master、TaskManager,其结构如下图:
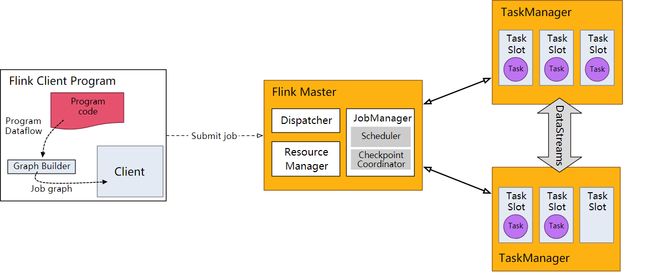
Flink Client
Flink客户端主要包括Program code,将代码进行解析,通过Graph Builder生成Job Graph,最后通过Client客户端提交给Flink集群。
Flink Master
Flink的管理中心,内部主要包含三个组件。
Dispatcher
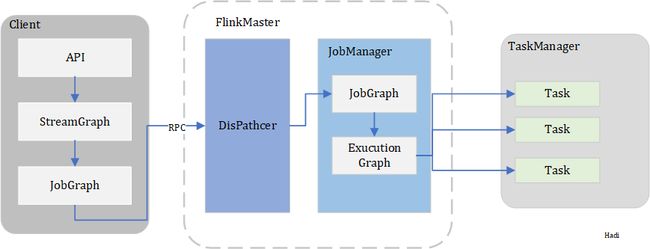
DisPatcher的作用是从Client端接收作业,并代表Client端在集群管理器上启动作业。总体上来看可以看做分发器。
其是在AppMaster启动完毕后创建的,AppMaster的主类是YarnJobClusterEntrypoint(per-job模式)或YarnSessionClusterEntrypoint(session模式),最后通过AbstractDispatherResourceManagerComponentFactory.create方法创建并启动:
// AbstractDispatcherResourceManagerComponentFactory
public DispatcherResourceManagerComponent<T> create(
Configuration configuration,
...) throws Exception {
//创建webMonitorEndpoint并启动
//创建resourceManager并启动
//创建dispatcher并启动
//Per-Job模式创建MiniDispatcher,Session模式创建StandaloneDispatcher
dispatcher = dispatcherFactory.createDispatcher(
configuration,
rpcService,
highAvailabilityServices,
resourceManagerGatewayRetriever,
blobServer,
heartbeatServices,
jobManagerMetricGroup,
metricRegistry.getMetricQueryServiceGatewayRpcAddress(),
archivedExecutionGraphStore,
fatalErrorHandler,
historyServerArchivist);
//其实就是启动了rpc endpoint
dispatcher.start();
}
Dispatcher的作用:
-
Dispatcher是可以夸作业运行,为Client端提供REST接口方便Client提交作业。
-
当一个应用被提交执行的时候,分发器就会启动并将应用提交给JobManager。
-
Dispatcher会启动一个WebUI,方便战士和监控作业执行的信息。
-
Dispatcher并不是必须的,取决于应用作业的提交方式。
JobManager
是集群任务管理中心,是整个集群任务的协调者。负责接收Flink Job,协调任务调度Scheduler,管理checkpoint,Failover故障恢复等,同时管理Flink集群中的各个TaskManager从节点。
控制一个应用程序执行的主程序,也就是说同一个Flink Session被同一个的JobManager所控制。
集群中至少要又一个Master,可以使用HA,但要保证其他的是Standby。
JobMananger中包含Actor System、Scheduler、CheckPoint三个重要组件分别作用如下:
Actor System
参与者系统,是具有各种角色、演员 Actor的容器container。提供如调度、配置、日志等服务记录。还包含一个线程池,包含所有actor。
每个Actor都将分配一个父级,类似于linux,每个actor都会有写入队列。如果多个actor是同一个地址(JVM),那么他们可以通过共享内存来传递消息,如果是远程的,则通过RPC来调用传递消息。如果Actor的状态发生错误,则其父级会收到通知,如果父级能解决,则解决,不能继续上升到父级。
Scheduler
任务调度中心,主要调度任务的启停,验证任务的成功。
Checkpoint Coordinator
checkpoint 协调器协调 operators 和 state 的分布式快照。 它通过将消息发送到相关任务来触发 checkpoint,并收集 checkpoint 确认。 它还收集并维护由确认 checkpoint 的任务报告的状态句柄。
具体的代码解析可以参考 https://www.cnblogs.com/Springmoon-venn/p/13530188.html
Resource Manager
- 主要负责管理任务管理器( Task Manager)的 插槽(slot)Taskmanger插槽是 Flink中定义的处理资源单元。
- Flink 为不同的环境和资源管理工具提供了不同资源管理器,比如YARNMesos、K8s,以及 standalone部署。
- 当 Jobmanagerl申请插槽资源时, Resourcemanager会将有空闲插槽的Taskmanager?分配给Jobmanager。如果 Resourcemanagery没有足够的插槽来满足 Jobmanagerf的请求, 它还可以向资源提供平台发起会话,以提供启动 Taskmanageri进程的容器。
Task Manager
真正执行任务的Slave节点,负责具体的任务执行和对应任务在每个节点上的资源申请和管理。其本身就是一个RPC服务器,提供了任务提交、任务取消等接口,同时包含JobLeaderService、TaskSlot管理、资源管理、心跳检测、存储服务。
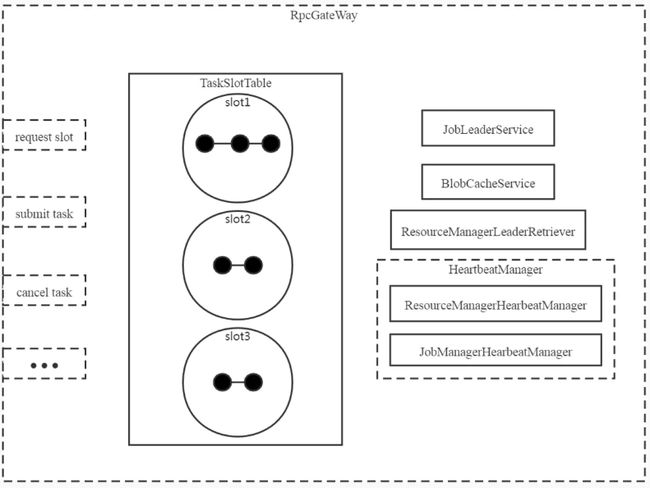
TaskSlotTable
TaskManager中最重要的就是TaskSlotTable,是指Flink任务最小的Task任务容器,他与普通线程不同的是,Slot可以分配到独立的内存和状态管理能力,不同的JobVertex可以通向Slot。
当TaskManager创建后,就会创建TaskSlotTable并添加获取Task,申请释放Slot。
JobLeaderService
JobLeaderService用于监听Master。如果Master节点改变,会通知JobLeaderService,内部是以JobId为Key来保存LeaderRetrievalService和JobManagerLeaderListener。
ResourceManager
不是Flink Master中的ResourceManager,而是TaskManager中的一个模块,用于监听ResourceManager中的主节点。如果主节点有变化,会通知ResourceManagerLeaderReriever。
HeartbeatManager
心跳检测模块包含JobManager和ResourceManager的心跳检测。
BlobCacheService
存储服务器,包含PermanentBlobService:可恢复,数据上传到BlobStore分布式文件系统;
TransientBlobService:不可恢复,数据不会上传到BlobStore分布式文件系统。
说说Flink 资源管理中 Task Slot 的概念
在TaskManager中,我们说最小任务资源单位就是TaskSlot。TaskManager会将自己管理的资源分为不同的Slot,他们享有自己独立的内存隔离,没有CPU隔离。
TaskManager其实就是一个JVM,所以Slot们还可以共享上下文信息、TCP连接、心跳消息、各种数据结构等。
在默认情况下,Flink允许子任务共享Slot,当然必须满足:它们属于同一个Job,并且不是同一个operator的子任务。所以当我们在写程序的时候,很可能一个Slot中包含一个Job的完成pipeline。这样的好处有:
Flink计算一个Job所需的Slot数量时,只需要确定pipeline上的最大并行度即可,而不用考虑每一个任务的并行度。
能够更好的利用资源,小消耗的Slot与大消耗的Slot本来任务所需的资源不一致。
Flink 资源管理中 Task Slot 的概念
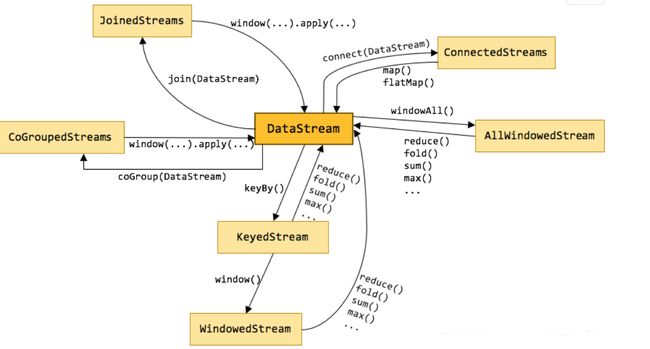
DataStream 2 DataStream
map、flatMap、filter
转换、压平、筛选
其他转换的数据流
keyBy、window、reduce、fold、sum、max、windowAll、connect、Join、apply、coGroup。
Flink分区策略
Flink的分区策略应该指的就是数据分区,一般称之为Partition。
StreamPartitioner是Flink中的数据流分区抽象接口,决定了在实际运行中的数据流分发模式,将数据切分交给Task计算,每个Task负责计算一部分数据流。所有的数据分区器都实现了ChannelSelector接口,在这个接口中定义了负载均衡的选择行为。
ChannelSelector
public interfaceChannelSelector<T extends IOReadablewritable> {
//下游可选 Channel 的数量
void setup (intnumberOfChannels);
//选路方法
int selectChannel (T record);
//是否向下游广播
boolean isBroadcast();
}
在这个接口可以看到,每一个分区器都知道下游通道的数量,在某一次任务运行的时候是固定的,除非刻意更改作业的并行度,否则不会更变。
分区策略
一共有8种分区策略,数据分区体系如下图:
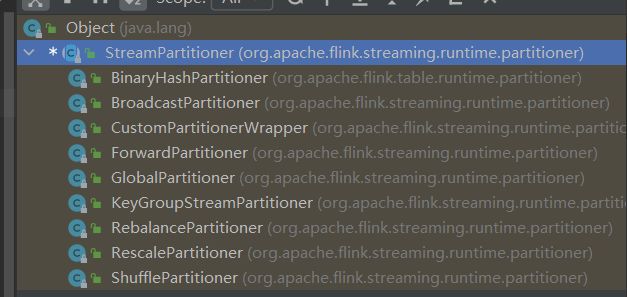
GlobalPartitioner
会将所有数据都分发到下游的第一个实例中。
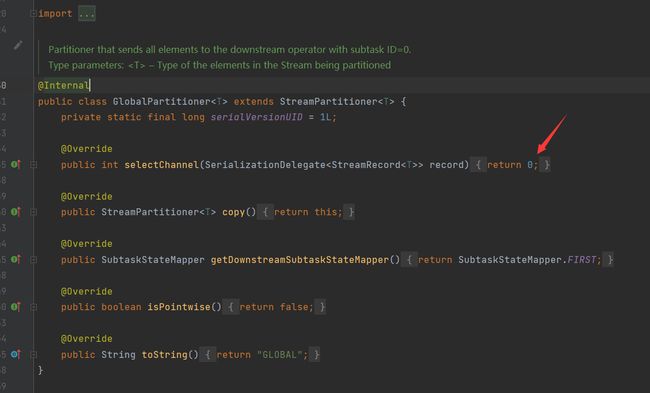
ShufflePartitioner
每次来一个都随机一个下游进行分发,这个分发的的特点是,相同数据不一定在一个下游中,使用环境很少。
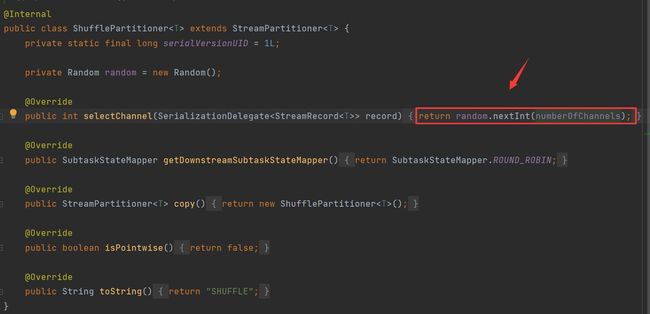
BroadcastPartitioner
发送数据到每一个下游中,一般用于dim表,小表分发,配置分发的场景。
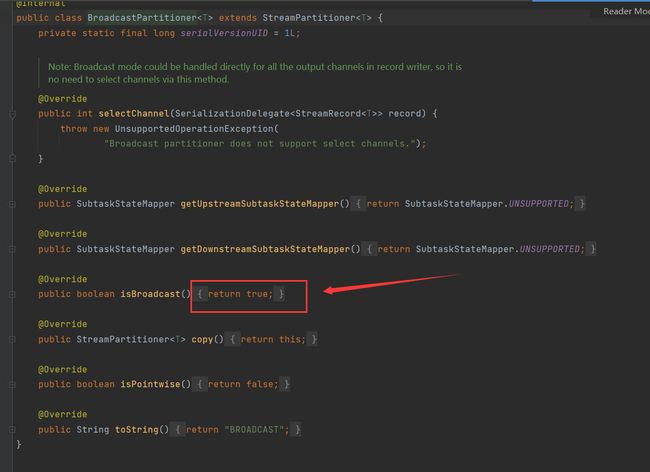
RebalancePartitioner
轮循下发数据到下游中。这个轮循是上游每个的Partitioner的轮循,并不是全局轮循。
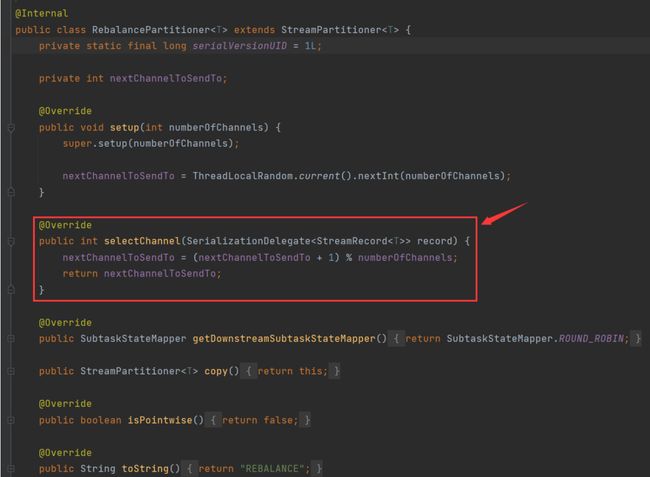
RescalePartitioner
通过计算下游Operator的并行度,将记录以循环的方式输出到下游的Operator的每个实例。通过下图可以看到他是
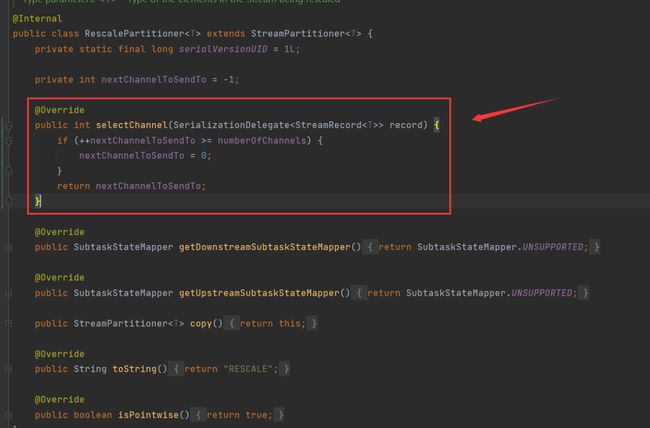
其实这个算法跟 RebalancePartitioner 是一样的算法,都是获取numberOfChannels然后取余,但是下面有个值被偷偷摸摸设置为了true ——isPointwise。
当这个值isPointwise被设置为了true以后,后续的解析行为会更变实现方法,导致后续的实现会变成特定节点只跟特定集合下游节点参与分配。详情跳转。我们知道Flink会将任务拆解为StreamGraph,提交JobGraph,最后执行ExecutionGraph。在StreamGraph转化为JobGraph中的时候,查看其代码的801行可以看到:

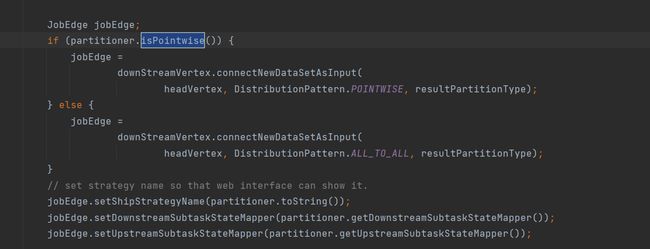
可以看到分布方式被指定成了POINTWISE,我们直接进入DistributrionParttern看看这个POINTWISE用到的哪里:
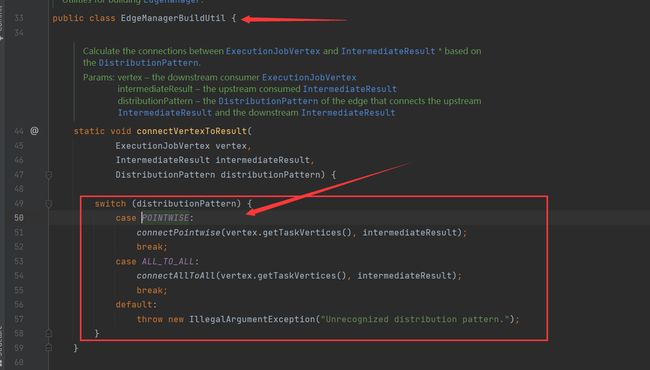
通过这个值,在JobGraph到真正执行的ExcutionGraph中时(EdgeManagerBuildButil.connectVertexToResult),使用connectPointwise去执行,那和connectAllToAll有什么区别呢:
connectAllToAll
很简单,上游分配所有下游节点,下游节点获取所有上游。
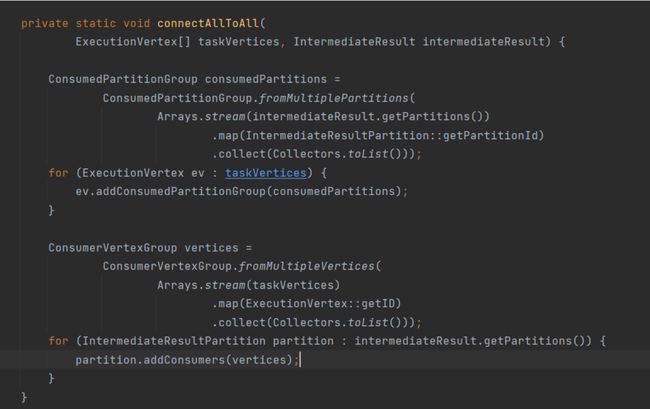
connectPointwise
主要考虑上下游的节点数进行分配计算,那么就会有三种情况:
sourceCount = targetCount
sourceCount > targetCount
sourceCount < targetCount
当上下游节点相等时直接一一对应即可:
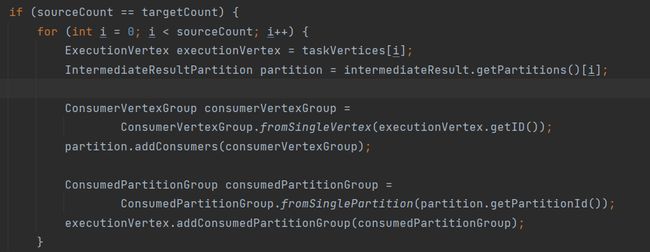
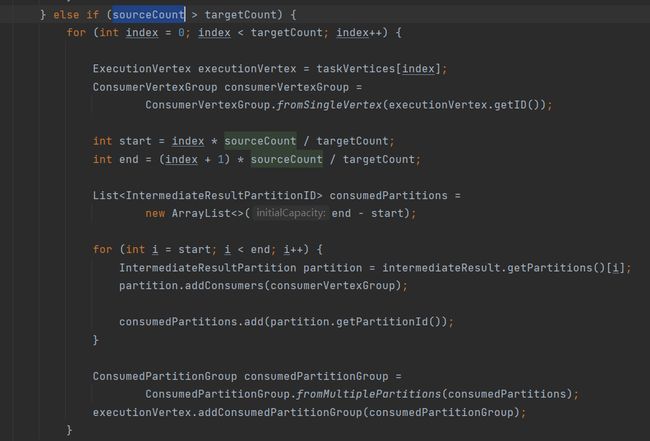
当上游节点大于下游的时候:
其实就是多个上游节点要对应同一个下游节点,那么怎么分配呢?公式为:
f ( i n d e x ) = s u b A r r a y ( i n d e x ∗ S o u r c e C o u n t / t a r g e t C o u n t , ( i n d e x + 1 ) ∗ S o u r c e C o u n t / t a r g e t C o u n t ) f(index)=subArray(index*SourceCount/targetCount,(index+1)*SourceCount/targetCount) f(index)=subArray(index∗SourceCount/targetCount,(index+1)∗SourceCount/targetCount)
注意这里的除法不保留小数。
上下游比率SourceCount/targetCount,在通过index滑动取分区。
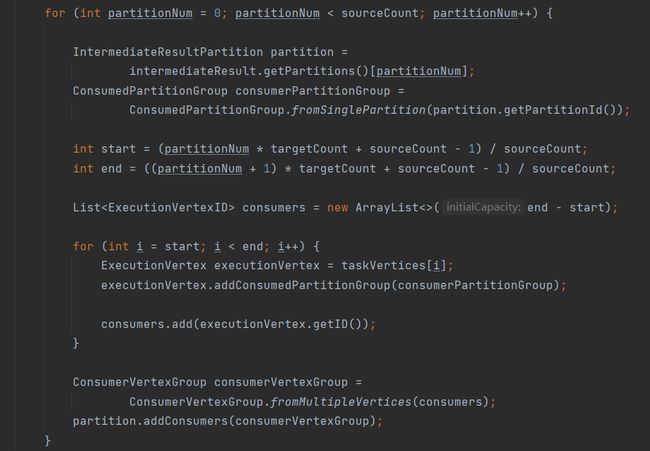
当上游节点小于下游的时候:
意味着上游节点要对应多个下游节点,使用公式:
f ( p a r t i t i o n N u m ) = ( p a r i t i o n N u m ∗ t a r g e C o u n t + s o u r c e C o u n t − 1 ) / s o u r c e C o u n t f(partitionNum)=(paritionNum*targeCount + sourceCount -1)/sourceCount f(partitionNum)=(paritionNum∗targeCount+sourceCount−1)/sourceCount
通过partitionNum进行滑动,这样上游的节点就可以向固定下游进行发送数据,且下游节点有且仅有一个上游节点。这个算法考虑的还是挺不错的,可以多看看。
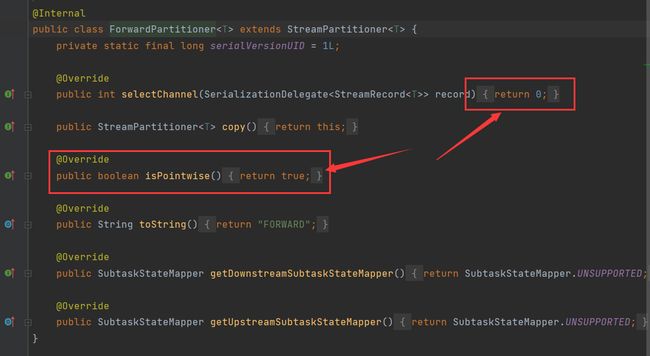
ForwardPartitioner
发送到下游对应的第一个task,与ResscalePartitioner相同,他们的isPointwise被指定为true:
KeyGroupStreamPartitioner
根据key的分区索引选择发送到相对应的下游subTask。
终于有一个使用真实数据来规定走哪一个下游了,具体代码看这段:
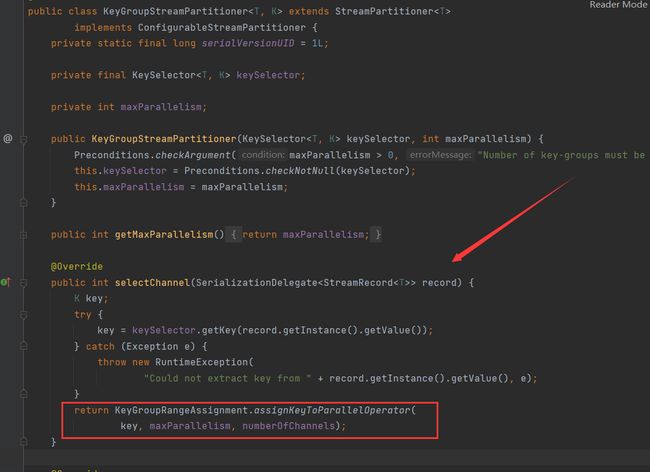
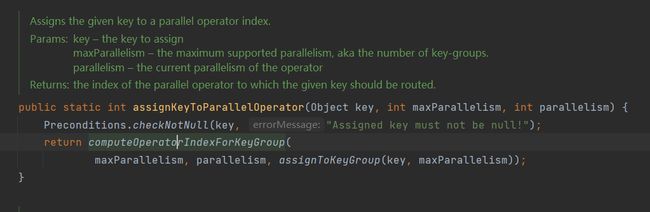
具体实现为:
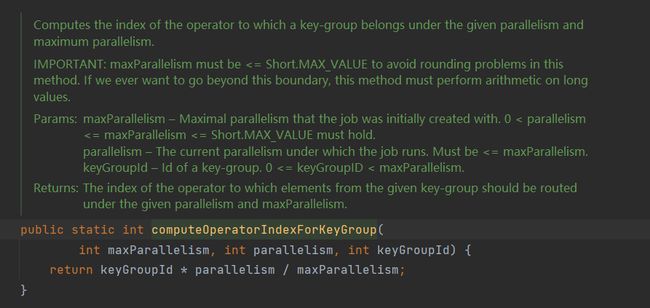
keyGroupId的计算方式:
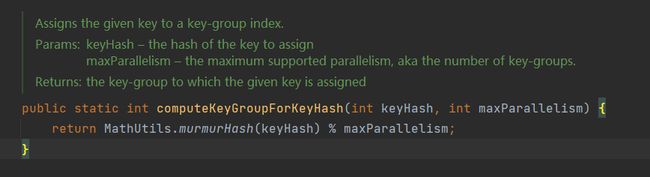
murmurHash Hash算法
一种非加密型的Hash操作,可以有较强规律的key,随机分布表现优秀。具体后续再写一篇文章介绍。
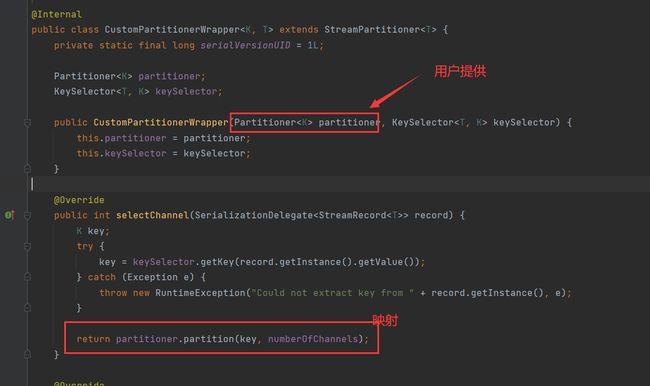
CustomPartitionerWrapper
通过自定义的方法Partition,将记录输出到下游中。
在这个中,用户必须自己提供一个Partitioner以计算正确的映射关系:
默认策略
在上下游的Operation并行度一致,且没有指定分区器的情况下,使用ForwardPartitioner;如果指定了分区器则使用RebalancePartitioner。
Flink的并行度是怎样的
并行度Parallel,是对每个subTask进行设定的。而并行度是可以用户指定的,与Java等参数一样,进行配置的时候会有层次关系:
- Operator Level 算子层次
- Execution Environment Level 执行环境层次
- Client Level 客户端层次
- System Level 系统层次
越往下,覆盖范围越大;相对的越往上,覆盖力度越大。
Operator Level
写在代码里,单独对subTask的设置:
final SingleOutputStreamOperator<CmConfig> cm = env.readFile(cmFormat, pathString
, FileProcessingMode.PROCESS_CONTINUOUSLY, 60 * 60 * 1000)
.map((MapFunction<Row, CmConfig>) CmConfig::new)
.setParallelism(10)
.returns(CmConfig.class);
上图setParallelism就是设置这单个subTask的并行度。
Execution Environment Level
当然我们程序一般会有一个env的默认并行度:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.failureRateRestart(5, Time.minutes(3), Time.minutes(1)));
env.setParallelism(parallelism);
env.disableOperatorChaining();
上面代码的env.setParallelism(parallelism);就是针对整个任务执行的默认并行度。
Client Level
当我们提交job到Flink的时候,可以通过
{{FLINK_HOME}}/bin/flink run -p 10 xxxx.jar
进行任务的提交进行设置并行度 -p 10 。
System Level
在我们部署flink的时候,{{FLINK_HOME}}/bin/flink是会加载配置文件的:flink-conf.yaml中的parallelism.default来指定全局默认并行度。一般情况下不推荐设置该值。
Flink的Slot和parallelism有什么区别
Slot是Flink中的最小计算资源,受到TaskManager的管控,在同一个TaskManager中的Slot共享一个JVM,TCP、心跳连接等都可以共享。
Parallelism本质是任务的并发数,在Flink中,一个作业会被拆分为若干个subTask,这些subTask会有自己的并发数Parallelism。
Slot唯一能和Parallelism扯上关系的就是我们一般只会指定TaskManager的数量,和每个TaskManager中的Slot数量。而计算真正计算TaskManager数量的就是通过作业的最大subTask/单TaskManager中的Slot来计算TaskManager的个数。
Flink的重启策略
Flink任务在失败的时候,会采用一定的策略来自适应这些报错。重启类在:org.apache.flink.api.common.restartstrategy.RestartStrategies中,具体的重启规则有: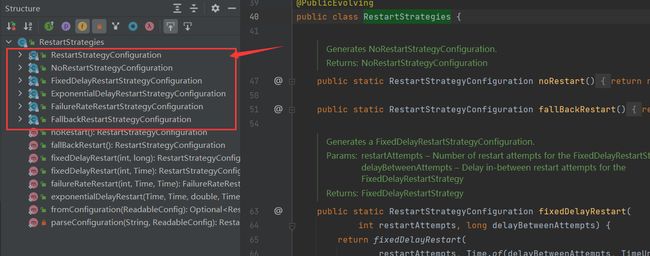
NoRestartStrategy
不进行重启,当任务失败的时候直接进行失败操作,不对任务进行重启判断。
/**
* Generates NoRestartStrategyConfiguration.
*
* @return NoRestartStrategyConfiguration
*/
public static RestartStrategyConfiguration noRestart() {
return new NoRestartStrategyConfiguration();
}
具体的实现方式如下:
/** Configuration representing no restart strategy. */
public static final class NoRestartStrategyConfiguration extends RestartStrategyConfiguration {
private static final long serialVersionUID = -5894362702943349962L;
@Override
public String getDescription() {
return "Restart deactivated.";
}
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
return o instanceof NoRestartStrategyConfiguration;
}
@Override
public int hashCode() {
return Objects.hash();
}
}
看这个方法其实看不出来什么内容,其实在org.apache.flink.runtime.executiongraph.failover.flip1.RestartBackoffTimeStrategyFactoryLoader#createRestartBackoffTimeStrategyFactory方法中,依次判断了是哪种重启策略,遵循什么样的重启规则。当发现为noRestart的时候,则直接不重启。
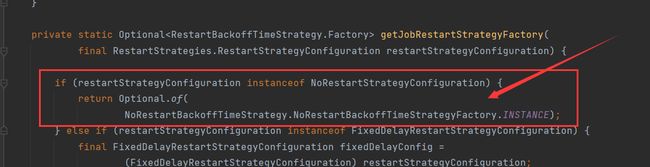
FixedDelayRestartStrategy
在一定重试次数之内进行重启操作。超过重试次数之后,不再重启。
public static final class FixedDelayRestartStrategyConfiguration
extends RestartStrategyConfiguration {
private static final long serialVersionUID = 4149870149673363190L;
private final int restartAttempts;
private final Time delayBetweenAttemptsInterval;
FixedDelayRestartStrategyConfiguration(
int restartAttempts, Time delayBetweenAttemptsInterval) {
this.restartAttempts = restartAttempts;
this.delayBetweenAttemptsInterval = delayBetweenAttemptsInterval;
}
public int getRestartAttempts() {
return restartAttempts;
}
public Time getDelayBetweenAttemptsInterval() {
return delayBetweenAttemptsInterval;
}
主要包含两个参数:重试次数&重试延迟(毫秒)。对应的实现就是org.apache.flink.runtime.executiongraph.failover.flip1.FixedDelayRestartBackoffTimeStrategy。
FailureRateRestartStrategy
一种基于失败率的重启策略。需要传入三个值:最大失败率(次数)、失败间隔、重启间隔。
/** Configuration representing a failure rate restart strategy. */
public static final class FailureRateRestartStrategyConfiguration
extends RestartStrategyConfiguration {
private static final long serialVersionUID = 1195028697539661739L;
private final int maxFailureRate;
private final Time failureInterval;
private final Time delayBetweenAttemptsInterval;
public FailureRateRestartStrategyConfiguration(
int maxFailureRate, Time failureInterval, Time delayBetweenAttemptsInterval) {
this.maxFailureRate = maxFailureRate;
this.failureInterval = failureInterval;
this.delayBetweenAttemptsInterval = delayBetweenAttemptsInterval;
}
……
}
只要在一段时间内,还没有达到最大失败次数,那么就间隔重启间隔后重启程序。
ExponentialDelayRestartStrategy
无限次指数递增重启策略。当任务失败的时候,会进行重启,重启间隔为失败次数的指数递增;没有最大重启次数限制,无限尝试重启任务。
/** Configuration representing an exponential delay restart strategy. */
public static final class ExponentialDelayRestartStrategyConfiguration
extends RestartStrategyConfiguration {
private static final long serialVersionUID = 1467941615941965194L;
private final Time initialBackoff;
private final Time maxBackoff;
private final double backoffMultiplier;
private final Time resetBackoffThreshold;
private final double jitterFactor;
public ExponentialDelayRestartStrategyConfiguration(
Time initialBackoff,
Time maxBackoff,
double backoffMultiplier,
Time resetBackoffThreshold,
double jitterFactor) {
this.initialBackoff = initialBackoff;
this.maxBackoff = maxBackoff;
this.backoffMultiplier = backoffMultiplier;
this.resetBackoffThreshold = resetBackoffThreshold;
this.jitterFactor = jitterFactor;
}
……
}
可以看到一共有五个入参,分别为:
-
initialBackoff 第一次重启时间间隔
-
maxkBackoff 最大的重启时间间隔
-
backoffMultiplier 指数系数
每次任务失败后重启间隔乘以这个系数。
-
resetBackoffThreshold 当过了多长时间后将任务重启间隔回归到initialBackoff
-
jitterFactor 重启时间的抖动系数
当任务重启的时候,会随机或加或减配置项系数的一个随机数。
FallbackRestartStrategy
使用集群的默认重启策略。其实还是以上的四种之一而已,并不在程序内进行设置,而是采用提交任务时,或者平台配置时的默认策略。
Flink中的分布式缓存
分布式缓存听起来总感觉怪怪的,其实就是类似于spark程序提交的时候 -f 一个文件上去,分发到各个节点中。
这个每个节点都能获取到这个文件数据。
与广播变量的不同是广播变量是分发到各个TaskManager节点的内存中,而分布式缓存是将文件缓存到各个TaskManager节点上。
使用代码:
env.registerCachedFile("hdfs:///path/file", "cachefilename");
File myFile = getRuntimeContext().getDistributedCache().getFile("cachefilename");
List<String> lines = FileUtils.readLines(file);
可以直接在RichFunction中,对open进行重写,将文件中的数据读取出来,存放到内存中。
Flink中的广播变量
在Flink中,同一个算子可能存在若干个不同的并行实例,计算过程可能不在同一个Slot中进行,甚至不在同一个TaskManager中,也就是不在一个Jvm中。比如这样一个情景:
我们需要设计一个算子,将所有数据根据一个文件中的kv关系进行映射。
将原始数据中的城市编码转换为城市名,需要根据一个离线文件中的数据进行关联。
离线文件广播
这样一个离线文件被读取后需要分发到每个下游中,并且每个下游都有这个离线文件汇总的全量数据。
需要注意的是,广播变量是将数据广播到内存汇总,广播的数据不能太大,不然会OOM,广播变量原则上来说不可修改。
//1.env
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//2.Source
//学生数据集(学号,姓名)
DataSource<Tuple2<Integer, String>> studentDS = env.fromCollection(
Arrays.asList(Tuple2.of(1, "张三"), Tuple2.of(2, "李四"), Tuple2.of(3, "王五"))
);
//成绩数据集(学号,学科,成绩)
DataSource<Tuple3<Integer, String, Integer>> scoreDS = env.fromCollection(
Arrays.asList(Tuple3.of(1, "语文", 50), Tuple3.of(2, "数学", 70), Tuple3.of(3, "英文", 86))
);
//3.Transformation
//将studentDS(学号,姓名)集合广播出去(广播到各个TaskManager内存中)
//然后使用scoreDS(学号,学科,成绩)和广播数据(学号,姓名)进行关联,得到这样格式的数据:(姓名,学科,成绩)
MapOperator<Tuple3<Integer, String, Integer>, Tuple3<String, String, Integer>> result = scoreDS.map(
new RichMapFunction<Tuple3<Integer, String, Integer>, Tuple3<String, String, Integer>>() {
//定义一集合用来存储(学号,姓名)
Map<Integer, String> studentMap = new HashMap<>();
//open方法一般用来初始化资源,每个subtask任务只被调用一次
@Override
public void open(Configuration parameters) throws Exception {
//-2.获取广播数据
List<Tuple2<Integer, String>> studentList = getRuntimeContext().getBroadcastVariable("studentInfo");
for (Tuple2<Integer, String> tuple : studentList) {
studentMap.put(tuple.f0, tuple.f1);
}
//studentMap = studentList.stream().collect(Collectors.toMap(t -> t.f0, t -> t.f1));
}
@Override
public Tuple3<String, String, Integer> map(Tuple3<Integer, String, Integer> value) throws Exception {
//-3.使用广播数据
Integer stuID = value.f0;
String stuName = studentMap.getOrDefault(stuID, "");
//返回(姓名,学科,成绩)
return Tuple3.of(stuName, value.f1, value.f2);
}
//-1.广播数据到各个TaskManager
}).withBroadcastSet(studentDS, "studentInfo");
//4.Sink
result.print();
使用RichMapFunction重写open方法来进行初始化操作获取一份数据,然后保存在内存中,通过getBroadcastVariable来拿到广播的数据。以上写的比较难以理解了一点,下面的是实时数据的广播情况:
实时数据广播
// 需要广播的数据
final SingleOutputStreamOperator<CityConfig> city = ……
.name("getCityConfig");
// 创建 broadcastFlag
final MapStateDescriptor<String, CityConfig> cityConfigMapStateDescriptor = new MapStateDescriptor<>("city", String.class, CityConfig.class);;
// 主流数据connect 并process。
final SingleOutputStreamOperator<MyObject> myResult = myStream
.connect(city.broadcast(cityConfigMapStateDescriptor))
.process(new BroadcastProcessFunction<MyObject, CityConfig, MyObject>() {
@Override
public void processElement(MyObject value, BroadcastProcessFunction<MyObject, CityConfig, MyObject>.ReadOnlyContext ctx
, Collector<MyObject> out) throws Exception {
// 当主流数据来了怎么办
ReadOnlyBroadcastState<String, CityConfig> broadcastState = ctx.getBroadcastState(cityConfigMapStateDescriptor);
String cellKey = value.getProvinceCode() + "_" + value.getCityCode();
if (broadcastState.contains(cellKey)) {
final CityConfig cityConfig = broadcastState.get(cellKey);
out.collect(value.connect(cityConfig));
}
}
@Override
public void processBroadcastElement(CityConfig value, BroadcastProcessFunction<MyObject, CityConfig, MyObject>.Context ctx
, Collector<MyObject> out) throws Exception {
// 当广播流的数据来了怎么办
BroadcastState<String, CityConfig> broadcastState = ctx.getBroadcastState(cityConfigMapStateDescriptor);
String cellKey = value.getProvinceCode() + "_" + value.getCityId();
broadcastState.put(cellKey, value);
System.out.println(System.currentTimeMillis() + ":" + value);
}
})
.uid("connectCity")
.name("connectCity");
可以看到,其实这也是一种双流join,主要就是将主流关联测流,然后进行一系列的存放操作,可以多多查看这个类BroadcastProcessFunction。或许参考:https://blog.csdn.net/qq_36610426/article/details/121020283
Flink的窗口
在实时数据中,我们经常需要统计一段时间内的客流量、访问人数等等统计指标。
滑动/滚动窗口
一般来说,统计这些东西我们就需要进行开窗操作,而Flink中,主要是这样进行区分:
如果根据时间窗口划分,那么它就是一个TimeWindow
如果根据数据进行划分,那么它就是一个CountWindow
而窗口属性主要有很重要的两个就是size和interval。根据这两个值可以有以下三种情况:
- size == interval
tumbling-window无重叠数据,比如统计每5分钟的访问网站人数,size=interval=5min
-
size > interval
sliding-window有重叠数据,比如每1分钟统计最近15分钟比特币BTC的涨幅波动(为了让统计结果不要变化过大),size=15min,interval=1min
-
size < interval
没有名称,因为这样会损失数据,统计结果一般没啥用,但也有比如每个两个小时统计一次这个小时的优良率进行抽查。
所以根据组合time/count 和 size/interval的组合一般就有四种基本窗口:
time-tumbling-window 时间滑动窗口:无重叠数据的时间窗口,设置方式举例:timeWindow(Time.seconds(5))
time-sliding-window 时间滚动窗口:有重叠数据的时间窗口,设置方式举例:timeWindow(Time.seconds(5), Time.seconds(3))
count-tumbling-window 数量滑动窗口:无重叠数据的数量窗口,设置方式举例:countWindow(5)
count-sliding-window 数量滚动窗口:有重叠数据的数量窗口,设置方式举例:countWindow(5,3)
会话窗口
当然还有一种会话窗口:
跟前面的不一样的时,它是根据一个session gap来指定窗口间隔。如果在session gap规定的时间内没有数据进入的话,则认为窗口结束,开始下一个窗口。
import org.apache.flink.streaming.api.scala._
object SessionWindow {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val textDstream: DataStream[String] = env.socketTextStream("localhost", 9999)
val dataStream: DataStream[(String, Int)] = textDstream
.map((_, 1))
.keyBy(0)
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(5))) // 超时时长为5秒
.sum(1)
dataStream.print().setParallelism(1)
env.execute("Session Window")
}
}
Flink的状态存储
Flink的状态State一般指一个具体的task/operator的状态,Flink提供不同的State Backends状态后端,指定如何和在哪里存储状态。
Flink提供了三种存储为内存、文件、RocksDB存储。他们分别的API是:MemoryStateBackend、FSStateBackend、RocksDBStateBackend。
在生产环境中,不推荐使用内存状态存储。
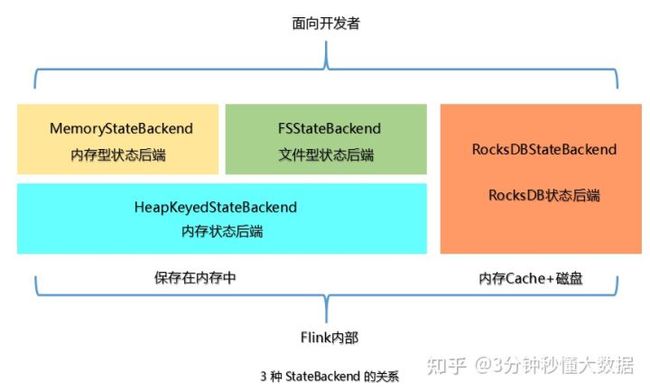
内存型 MemoryStateBackend
MemoryStateBackend,运行时所需的State数据全部保存在 TaskManager JVM堆上内存中。
执行检查点的时候,会把 State 的快照数据保存到JobManager进程的内存中。
MemoryStateBackend 可以使用异步的方式进行快照,(也可以同步),推荐异步,避免阻塞算子处理数据。
基于内存的 StateBackend 在生产环境下不建议使用,可以在本地开发调试测试 。
注意以下问题:
State 存储在 JobManager 的内存中.受限于 JobManager的内存大小。
每个 State默认5MB,可通过 MemoryStateBackend 构造函数调整
每个 State 不能超过 Akka Frame 大小。
文件型 FSStateBackend
运行时也会把所有数据保存在 TaskManager JVM堆上内存中。
执行检查点的时候,会把State的快照数据保存到配置的文件系统中。
可以使用HDFS路径或者本地路径
FSStateBackend适合用于大状态、长窗口、大键值状态的有状态处理任务。
注意以下问题:
State 数据首先被存在 TaskManager 的内存中。
State大小不能超过TM内存。
TaskManager异步将State数据写入外部存储。
MemoryStateBackend和FSStateBackend都依赖于HeapKeyedStateBackend,而它是使用State存储数据。
KV类型的State、窗口算子的State 使用HashTable 来保存数据、触发器等。
RocksDBStateBackend
RocksDBStateBackend使用嵌入式的本地数据库RocksDB,将流式数据状态存储在本地磁盘中,不会受限于TaskManager的内存大小。
在执行检查点的时候,将整个RocksDB中保存的State增量或者全量持久化到配置的文件系统中。
在JobManager内存中会存储商量的检查点元数据。RocksDB客服了State受限于内存的问题,同时又能持久化到源端文件系统中,适合生产环境使用。
但是它访问State的成本高很多,毕竟需要走数据库,那么意味着吞吐量会可能剧烈下降。
优点
- 最适合用于处理大状态、长窗口、大键值状态的有状态处理任务。
- 非常时候用于高可用方案。
- 是目前唯一支持增量检查的后端。
- 不受内存限制,收到磁盘大小。
缺点
- RocksDB的JNI API基于byte数组,单Key和Value不得超过8字节大小。
- 对于使用合并操作状态的,如ListState,随着时间可能累积超过2**31大小,会导致接下来的查询失败。
RocksDBStateBackend中还包含一些持久化策略,此部分内容不在这里详细讲解,可参考:todo。
todo 挖坑 RocksDBStateBackend的详细解析。
与CheckPoint的区别
而Checkpoint则表示了一个Flink Job,在一个特定时刻的一份全局状态快照,即包含了所有task/operator的状态。
保存机制 StateBackend(状态后端) ,默认情况下,State 会保存在 TaskManager 的内存中,CheckPoint 会存储在 JobManager 的内存中。
State 和 CheckPoint 的存储位置取决于 StateBackend 的配置。基于内存的 MemoryStateBackend、基于文件系统的 FsStateBackend、基于RockDB存储介质的 RocksDBState-Backend
State:Flink中包含两种基础的状态:Keyed State和Operator State。
状态过期
DataStream中状态过期
可以对DataStream中国的每一个状态设置 清理策略 StateTtlConfig,可以设置的内容有:
- 过期时间TTL
- 过期时间更新策略:创建和写时更新、读取和写时更新。
- State可见性:未清理可用、超时则不可用。
Flink SQL中状态过期
Flink SQL 一般在流Join、聚合类场景使用State,如果State不定时清理,则导致State过多,内存溢出。
一般可以这样进行配置:
StreamQueryConfig qConfig = ...
//设置过期时间为 min = 12小时 ,max = 24小时
qConfig.withIdleStateRetentionTime(Time.hours(12),Time.hours(24));
该小节参考这里。
Flink中的时间概念
实时程序运行的时候,对于数据的要求是比较高的,比如我们产生不一定是按照产生的时候送达到我们Flink中(如网络问题、数据源问题),但我们经常需要使用数据的时间来处理和标记数据,这样既可以提高效率,又能实现一些以往难以实现的功能。
在Flink中,提出了一种时间观念,使用这个可以对实时数据进行一系列操作如:延迟数据处理、双流interval join、基于时间的开窗等等。那么怎么标记一条数据的时间呢?Flink提供了三种:
-
EventTime
数据产生时间,一般这个来源于数据本身自带的数据。
-
ProcessTime
处理数据时间。
-
IngestionTime
接入Flink数据时间。
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 从调用时刻开始给env创建的每一个stream追加时间特征
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime)
env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime)
一般来说我们都会选用EventTime来进行后续数据的计算,因为这个才是数据本身的时间,其他两个都是Flink赋予的。
ProcessTime 和 IngestionTime的区别
IngestionTime是数据进入Flink的时间,ProcessTime是数据被Flink处理的时间,所以一般遵循下面的公式:
E v e n t T i m e < = I n g e s t i o n T i m e < = P r o c e s s T i m e EventTime<=IngestionTime<=ProcessTime EventTime<=IngestionTime<=ProcessTime
Flink Watermark
讲解这个东西,我们又需要了解在实际实时数据中,很多数据都是不理想的(大数据由于各种原因)。
而我们程序一般来说需要对实时数据进行开窗操作,来计算每3分钟的一些指标,那么我们怎么判定上一个窗口数据已经全部到达(或者说可以开始计算)?
比如我们一个数据到达时间如下,图中数字代表数据源端产生的顺序,队列代表我们Flink接收到的顺序:
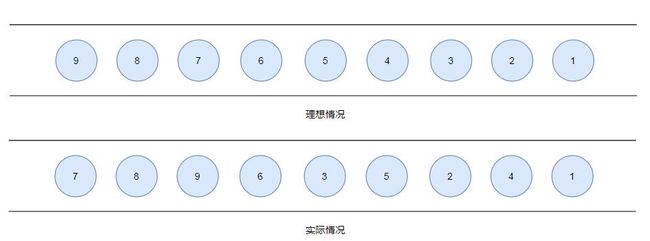
很明显,我们的数据乱序了,4号数据第二个到达Flink中,那么在这个时刻,是否意味着我03的数据已经到达?或者说我们又应该等多久才认为03的数据已经到达了。这个时候就必须引入一个机制,来保证一个特定的时间后,需要触发窗口去进行计算,这就是为什么需要Watermark。
Watermark是一种衡量Event Time数据到达进程的一种机制,主要就是用于乱序数据处理,一般要配合window开窗机制来实现。Watermark会一直不停增长,用于表示小于Watermark的Timestamp的数据已经到达,然后触发window的计算操作,所以Watermark也可以理解为一个延迟的触发机制。如果我们需要将延迟时长到T,每次系统会校验已经到达的数据中最大的maxEventTime,然后认定小于maxEventTime - T 的所有数据已经到达,并且会触发(还未触发的)小于maxEventTime - T 的窗口计算。
当我们设置T为0,window为3,上图为正序开窗,下图为乱序开窗情况:
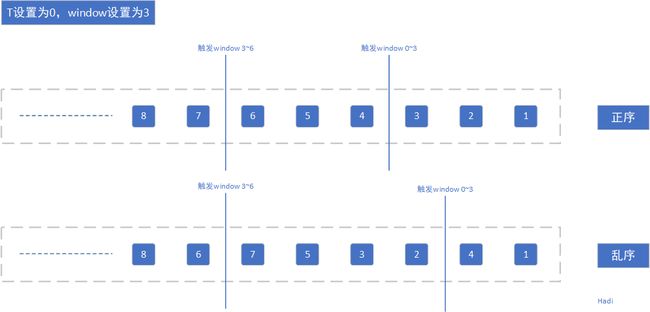
可以看到,当T=0,window=3的时候触发window03的瞬间是由于数据4的到达,这个时候,window03的桶内只有数据1,那么参与window0~3的数据就只有数据1。后面到达的3和2怎么办?一般来说就会被丢弃、走测流、重新计算等等情况。不过这也是一种很简单的watermark的计算,还有一些其他更科学的计算方式。
当我们设置T为2,window为3,上图为正序开窗,下图为乱序开窗情况:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cmyyHqdY-1644292117943)(C:\Users\huang\AppData\Roaming\Typora\typora-user-images\image-20220208111311635.png)]
可以看到,当我们配置了T=2的时候,触发window的操作都被delay了,但具体delay多久,就是看数据EventTime来决定。
Watermark的计算肯定不会这么简单,如果有需要请参考这里。todo
todo,补齐Flink watermark的实现方式等。
Flink SQL架构
在Flink 1.9的时候开始Flink SQL的着手,在1.13后热度高涨,1.14&1.15基本都是Flink的重点工作。因为大家都很明白,为了实现更多人的使用,引入sql可能是能最快吸引人们上手的一种尝试。
Flink SQL在1.9后实现了统一的Blink Planner,原来的Old Planner退出历史舞台。实现后的架构如下:
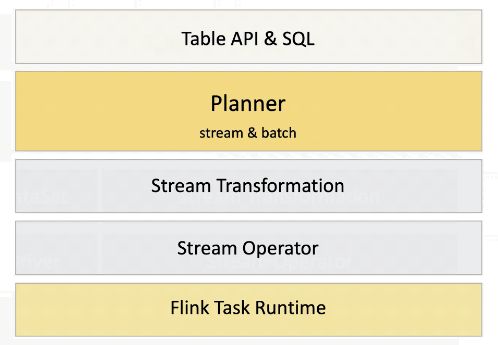
那么Flink SQL是怎么工作的呢?引用官网的图:
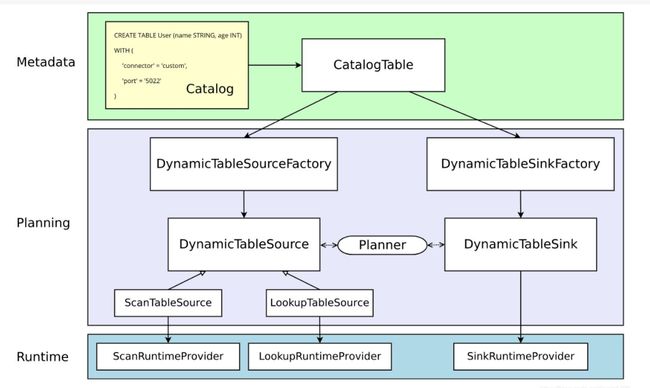
无论这么,我们的SQL最终怎么写,最后都会映射到算子上。讲的不错的可以参考这篇博客。
todo
https://cloud.tencent.com/developer/article/1864657
尾
通过这次梳理,完成了基础两个月Flink开发应该知道的最基础知识,后续还有Flink面试章节,请移步参考。
连接贴。