ViT结构优化——Searching the Search Space (S3 NAS)
Paper地址:https://arxiv.org/abs/2111.14725
GitHub链接:https://github.com/microsoft/Cream
概述
网络结构搜索(NAS: Neural-network Architecture Search)的设计收敛,首先取决于搜索空间的设计收敛,其次取决于搜索算法的设计收敛,最终结合平台约束、生成一系列符合Trade-off的优化解(构成Pareto-front)。针对Vision-Transformer,为了获得较之AutoFormer更好的One-shot结构优化效果,AutoFormerV2 (S3 NAS)通过搜索空间的自动优化(Searching the Search Space),实现了不同搜索维度的优化更新,从而获得最佳搜索候选集合(Candidate choices)。
ViT基本模型结构

如上图所示,ViT (Vision-Transformer)的模型结构,主要分为Monolithic结构与Multi-stage结构:
- Monolithic结构:每个Transformer block输出的Patch embeddings,其序列长度与特征维度均相同,因此计算复杂度相对较高,典型如ViT、DeiT;
- Multi-stage结构:
- 将模型划分为多个Stage;在每个Stage内部,Patch embeddings的序列长度与特征维度相同;不同Stage之间,通过Patch merging模块完成特征过渡,实现序列长度降采样、特征维度增长;


Swin-Transformer是Multi-stage模型结构的典型代表,具体结构如上图所示,其中:
- Patch Partition按Patch size=4,将输入Image划分成Patch embeddings、并实现特征维度转换:
# layer definition
proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
norm = nn.LayerNorm(embed_dim)
# forward
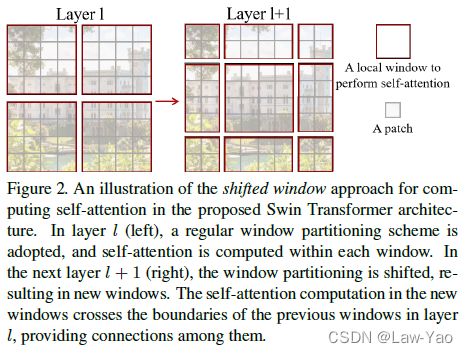
outputs = norm(proj(images).flatten(2).transpose(1, 2))- 每个Stage由若干Transformer block构成,每个Block都会执行Window-based Self-Attention (Win-SA);并且,基于第l个Block的Win-SA计算结果,第(l+1)个Block会先执行Window-shifting操作,随后执行的Win-SA、可实现Cross-window信息交互:
- 不同Stage之间,通过Patch merging实现序列长度的4倍降采样、特征维度的2倍增长:
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = x.view(B, H, W, C)
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = norm(x) # layer norm
x = reduction(x) # B H/2*W/2 2*C, linear layer- 由于Swin-Transformer采用了Win-SA、以及Patch merging,因此为了保留各个Window内部不同Patch之间的相对位置信息,需要为Attention编码引入Relative position bias:
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1
) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)Monolithic结构的ViT,涉及的搜索维度可包括Embedding dimension、Q-K-V dimension、Network depth、Number of attention heads、MLP ratio。Multi-stage结构的ViT(如Swin-Transformer),由于引入了Win-SA,且Window size大小会影响计算复杂度与Attention效果,因此也需要将Window size作为搜索维度,以更好地实现计算效率与识别精度的折中。
AutoFormerV2

如上图所示,AutoFormerV2通过不同搜索维度的自动优化搜索(Searching the Search Space),为AutoFormer形式的One-shot NAS提供了更为有效、更为收敛的搜索空间。AutoFormerV2搜索空间的搜索维度,包括Embedding dimension、Q-K-V dimension、Network depth、Number of attention heads、MLP ratio与Window size。

如上图所示,Searching the Search Space主要包括两个步骤:
- 针对第t次迭代,将搜索空间
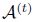 编码进入ViT超网络,然后执行Sandwich采样训练(类似于BigNAS);Sandwich采样训练,主要采集超网络中的最大模型、最小模型、以及两个随机的中间尺度模型,并融合他们的梯度、以更新超网络权重参数;在训练过程中,不采用Inplace distillation;
编码进入ViT超网络,然后执行Sandwich采样训练(类似于BigNAS);Sandwich采样训练,主要采集超网络中的最大模型、最小模型、以及两个随机的中间尺度模型,并融合他们的梯度、以更新超网络权重参数;在训练过程中,不采用Inplace distillation; - 完成超网络权重更新之后,将搜索空间分解为由不同搜索维度表示的子空间,且可表示为不同子空间的Cartesian product:
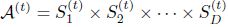 ;针对不同维度的子空间,通过E-T error的统计,以及E-T error关于搜索维度变化趋势的线性拟合(
;针对不同维度的子空间,通过E-T error的统计,以及E-T error关于搜索维度变化趋势的线性拟合( ),可实现子空间的优化更新:
),可实现子空间的优化更新:
![]()
完成Vision-Transformer搜索空间的优化搜索之后(实现了搜索空间的设计收敛),基于AutoFormer形式的One-shot NAS,并结合BigNAS的Sandwich采样训练,完成ViT超网络的充分、有效训练(实现了搜索算法的设计收敛)。完成超网络训练之后,进一步通过Evolution Search,能够获得满足平台资源约束的最佳子模型。
基于搜索空间的优化搜索,AutoFormerV2提出了ViT模型结构设计的Guideline:

有关BERT/Transformer模型压缩与优化加速的详细讨论,参考:
Bert/Transformer模型压缩与优化加速_AI Flash-CSDN博客_transformer模型加速
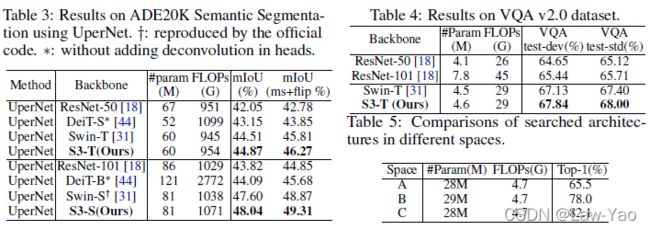
最终,AutoFormerV2的实验结果如下所示(在图像分类、目标检测、语义分割与视觉语言任务上的表现):