NeurIPS 2021 | 微软提出S3:自动搜索视觉Transformer的搜索空间
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:KAPI | 编辑:Amusi(CVer)
编者按:
搜索空间对于神经网络结构搜索方法至关重要,它决定了搜索结构的性能上下界。 到目前为止,许多研究精力已经被投入到了CNN搜索空间设计中。Vision Transformer模型作为计算机视觉的新宠儿,其搜索空间并未被很好地探索。这使得设计高效的Vision Transformer模型变得具有挑战。不同于人为地根据先验知识设计搜索空间,微软亚洲研究院的研究员提出了Search the Search Space (S3)来自动地设计Vision Transformer的搜索空间。其搜索出来的结构性能对比手工设计的ViT以及ViT变种模型有大幅度的提升。

Searching the Search Space of Vision Transformer
论文地址:http://arxiv.org/abs/2111.14725
代码地址:https://github.com/microsoft/Cream
一、 背景介绍
Vision Transformer (ViT) 近来在计算机视觉中引起了很大的关注。建立在Vision Transforme之上,最先进的模型,如ViT,DeiT,Swin-T等可以在图像分类和下游任务上与传统的CNN模型实现相当或者更优越的性能。
神经架构搜索(NAS)作为一个强大的自动化网络设计技术,其对比手工设计的优势已经被充分验证了。对于NAS方法,搜索空间至关重要,它决定了搜索期间架构的性能范围。研究人员对CNN空间的设计已经投入了许多精力。然而,现在Vision Transformer 的搜索空间并未被很好地探索。这使得设计高效的Vision Transformer模型变得具有挑战。
在本文中,作者提出先进行搜索空间的搜索 (Search the Search Space)再进行结构搜索。作者着重回答了以下两个问题:
1)如何有效、快速地衡量特定的搜索空间的好坏?
2)如何在没有人为干预的情况下将已有的搜索空间升级?
针对第一个问题,作者提出了一种新的测量标准,E-T Error,用于搜索空间质量的估计,并利用AutoFormer实现了E-T Error的快速计算。对于第二个问题,如图1所示、作者将搜索空间以多个维度进行分解,包括深度 (depth),嵌入维度 (embedding dimension),MLP比率 (MLP ratio),窗口大小 (window size),头部数量 (head number) 和Q-K-V 维度 (Q-K-V dimension),并独立进化每个维度以构成更好的空间。

图1: S3方法概括
此外,作者通过对搜索空间的搜索过程进行分析,提供了一些有趣的观察和Vision Transformer的设计指南:
1)第三阶段是最重要的,增加其网络层数可以提高性能。
2)计算Self-Attention时,浅层应使用小的窗口,对应的,深层应使用大的窗口。
3)MLP比率 应该随着网络深度一起增加。
4)Q-K-V维度可以小于嵌入维度,且不会导致性能下降。
二. 方法详情
2.1 问题描述
现有的大多数NAS方法都可以转化为一个约束优化问题:
![]()
在本文中,作者同时考虑了搜索空间设计和结构搜索。更具体地说,其问题被解耦成了以下三个单独的步骤:
第一步、 在特定约束下搜索最佳搜索空间:
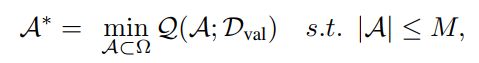
第二步、将搜索空间编码到超网 (Supernet)中并优化其权重:
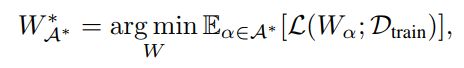
第三步、获取充分训练的超网后,利用超网的权重对候选结构进行搜索以得到最佳架构:
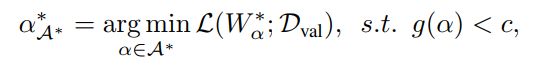
2.2 搜索空间的设计
如图2所示,作者根据ViT和Swin-T 来进行搜索空间中Vision Transformer的一般结构设置。具体而言,其包含了一个patch embedding 层,全连接形成的head,以及4个分辨率递减的stage。每个stage拥有不同个数的基本block, 每个block的结构与Swin-T类似。这其中的搜索维度包括:每个stage的block数量,以及其embedding的维度,每个stage中不同block的窗口大小,头部数量,MLP比率以及Q-K-V维度。
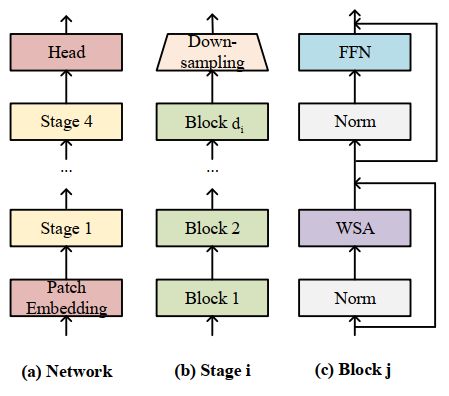
图2: 一般Vision Transformer结构
2.3 搜索空间的搜索
作者主要解答了两个问题,如何衡量一个搜索空间,以及如何根据衡量标准进行搜索空间升级。
为了衡量搜索空间,作者提出了一种新的测量标准 E-T error:
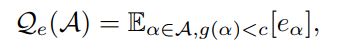
它是两部分的平均值:平均结构错误率的期望和高性能结构错误率的期望。
搜索空间的升级主要包含两个迭代的步骤:1) 超网的训练 2)空间的进化。
具体而言,对于一个给定的搜索空间,作者将它编码到一个超网,并对它进行充分的训练。随后根据超网计算不同维度的E-T error, 并用一个线性方程来模拟当前维度E-T error的趋势:
![]()
随后,根据E-T error的趋势对搜索空间进行升级:

三、分析与讨论
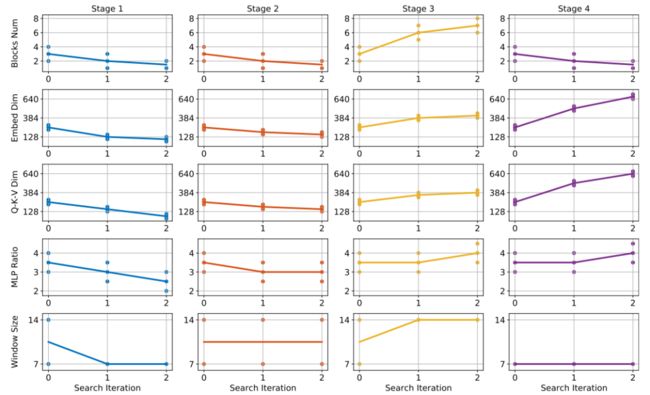
图3:空间搜索的过程
作者根据空间搜索的过程 (图3)对Vision Transformer的设计进行了分析和讨论。其结论如下:
1)第三阶段是最重要的一个,增加其网络层数可以提高性能。
2)计算Self-Attention时,浅层应使用小的窗口,对应的,深层应使用大的窗口。
3)MLP比率 应该随着网络深度一起增加。
4)Q-K-V维度可以小于嵌入维度,且不会导致性能下降。
四、实验
作者将S3搜索得到的结构和近期提出的ViT模型以及经典的CNN模型进行比较。如图4 和表1所示,搜索得到的结构在ImageNet数据集上明显优于已有的ViT模型及其变种,其拥有速度快,复杂度低,结构轻的优势。

表1:ImageNet 测试集的结果
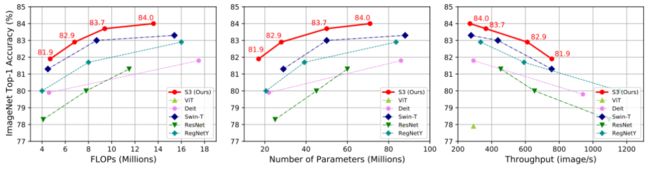
图4:不同约束下的模型比较。
同时,为了验证搜索结构的泛化能力,作者将模型迁移到了不同的下游任务当中,包括物体检测,语义分割以及视频问答。如表2,3,4所示,S3搜索得到的模型在下游任务上依然保持出色的表现,比ViT模型以及CNN模型更加优越。

表2:COCO 物体检测结果
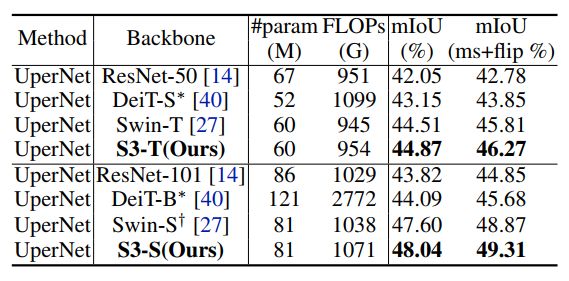
表3:ADE20K 语义分割结果

表4:VQA v2.0结果
五、结语与展望
在这项工作中,作者提出搜索Vision Transformer的搜索空间。其中心思想是利用提出的E-T error以及权重共享超网来指导、升级搜索空间的不同维度。作者还提供了针对Vision Transformer的分析和设计指南,用于理解和设计Vision Transformer模型。大量的实验表明, 搜索出的模型 —— S3在ImageNet 分类以及下游任务上展示出了超越ViT和Swin-T的卓越性能。在未来的工作中,作者希望研究将S3应用于CNN搜索空间的设计中。
上面论文代码下载
后台回复:S3,即可下载上述论文和代码
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
重磅!Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、Transformer、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看