[Transformer]AutoFormerV2:Searching the Search Space of Vision Transformer
AutoFormerV2:搜索VisionTransformer的搜索空间
- Abstract
- Section I Introduction
- Section II Approach
-
- Part 1 Problem Formulation
- Part 2 Basic Search Space
- Part 3 Searching the Search Space
- Part 4 Searching in the Searched Space
- Section III Analysis and Discussion
- Section IV Experiments
-
- Part 1 实验细节
- Part 2 Ablation Study
- Part 3 Image Classification
- Part 4 Vision and Vision-Language Downstream Tasks
- Section V Related Work
- Section VI Conclusion
from 石溪大学,中山大学,中科院自动化所,微软亚研院
NIPS2021
Paper
Code待开源
Abstract
Vision Transformer在诸多视觉任务中展现了强大的表征能力,也吸引了越来越多的目光来设计更有效的Transformer结构。本文提出使用NAS来自动化设计Transformer结构,但是不仅搜索网络结构还会搜索搜索空间,核心思想是使用权重共享超网权重,然后根据计算出的E-T误差来逐步进化每个搜索维度。此外本文还根据搜索空间的搜索过程提出了通用ViT的一些设计指南并进行分析,可以促进对Vision Transformerd的理解。
本文搜索到的结果(S3)在 ImageNet上的表现优于最近被提出的模型如Swin,DeiT和ViT;本文还验证了S3在目标检测、语义分割和VQA领域方面的有效性,即证实了也适用于下游视觉和视觉语言任务。
Section I Introduction
ViT优于其强大的建模和捕获长程依赖的关系在视觉领域备受关注,提出了许多SOTA网络如ViT,DeiT在诸多任务上可以与CNN 媲美,也有诸多研究这尝试设计更有效的网络架构来进一步提升ViT的性能。
NAS作为一种强大的自动化搜索技术,已经在许多方面优于人工设计的结果。NAS的关键是搜搜空间的设计,因为它决定了搜索过程中结构的性能边界,本文已经观察到搜索空间的高进对许多SOTA模型可以进一步提升性能,许多研究人员在CNN的空间设计进行了大量努力但是对Transformer这方面的关注还没有进行有效的探索。
本文提出S3(Search the Search Space)搜索搜索空间的方法会自动定义搜索空间的一些可变尺寸。
本文试图回答一下两个问题:
(1)如何有效且高效的定义一个搜索空间?
(2)如何在不借助先验知识的情况下自动将有缺陷的搜索空间变换到一个更好的空间?
对于第一个问题,本文提出一种叫做E-T误差的指标来评估搜索空间的质量,然后通过一次one-for-all的训练对超网进行高效计算,E是关注整体质量的一种误差经验分布函数,T则会衡量搜索空间顶部结构的质量。本文与AutoFormer类似 依旧是训练一个超网然后获得大量训练良好的子网络,性能估计使用代理实现。
对于第二个问题,如何将有缺陷的搜索空间自动变为好的,可以参照Fig 1.本文将搜索空间分为深度、嵌入维度、MLP Ratio,窗口大小、头数、Q-K-V维度等,并且逐步进化每个维度来构造更好的搜索空间。本文还建立可不同维度的进化趋势来指导搜索空间的设计。
本文观察到一些实验现象,可以作为设计指导方针:
(1)第三阶段是最重要的阶段 增加block的数量可以提升性能;
(2)浅层应该使用较小的窗口,深层使用较大的窗口
;
(3)MLP Ratio最好随着网络深度的增加而逐渐增加
;
(4)Q-K-V的维度可以小于嵌入维度 并不会带来性能下降
本文希望这些观察结果可以帮助ViT结构的人工设计以及搜索空间的设计。
![[Transformer]AutoFormerV2:Searching the Search Space of Vision Transformer_第1张图片](http://img.e-com-net.com/image/info8/b7af751252d7435091573de8ccdf86a3.jpg)
本文的贡献总结如下:
(1)本文提出一种ViT搜索空间的设计方法-S3,还提出一种新的搜索pipeline可以最小化人工的参与,此外还提供了进行ViT架构设计的分析和指导方案,可以用于未来的架构搜索和设计;
(2)在ImageNet的实验验证了本文提出的搜索空间设计方法的有效性,可以提升搜索结果的性能;优于近期提出的ViT和Swin.
此外在下游任务如目标检测、语义分割、VQA等任务的优越表现也证明了其在下游任务上的有效性。
Section II Approach
Part 1 Problem Formulation
绝大多数NAS方法搜可以看做是一种带约束的优化问题:

W指的是网络的权重,L则是损失函数,Dval和Dtrain分别代表验证损失和训练损失,g代表计算成本,c代表具体的约束
理想情况下搜索空间A会包含所有可能的结构,但是实际A通常是一个子空间,毕竟算力有限。
本文的创新在于打破了常规搜索空间是固定的这一限定,将上述带约束的优化问题分成3个步骤:
Step 1:在特定约束下搜索最优的搜索空间
![]()
Q则是评价搜索空间的指标 M代表最大的搜索空间尺寸
Step 2:遵循one-shot NAS的方法 将搜索空间编码成supernet并优化权重
![]()
Step 3:在超网训练较好的情况下来通过对子网排序选择最优的子网结构
![]()
Part 2 Basic Search Space
本文按照ViT,Swin-T的设置来搭建基础结构,研究会将输入切patch并且进行嵌入+展平,然后送入Transformer Encoder进行处理,最后经过全连接层获得分类结果。
Encoder包含4个stage会逐渐降低输入分辨率;每一个阶段中的block拥有相同的嵌入维度,因此每一个stage i就有两个搜索维度:block的数目di和嵌入维度hi。
每一个模块搜由WSA+FFN组成,但并不要求每一个block长得一样,即每一个block可以拥有不用的window-size,head numbers,MLP ratio,Q-K-V ratiod等。
Part 3 Searching the Search Space
Space Quality Evaluation
首先看如何对搜索空间的质量进行评估。对于搜索空间A,本文使用E-T误差来评价A的质量,分别代表预期的错误率和top的错误率。
此外就是常规的计算成本函数g和计算资源约束c.
其中使用N个随机抽样框架的平均错误率近似期望误差,top错误率则是前50个候选框架的平均错误率代表着搜索空间的性能上限。
One-for-all Supernet
RegNet
会训练上百个模型但只训练较少epoch,使用他们的误差作为性能评估的代理,但是本文是将搜索空间编码成超网然后采取与AutoFormer类似的训练方法,这样训练的好处就是只需要训练一个超网就能一次获得成百上千的子网络并且性能评估是十分准确的。
Searching the Search Space
搜索空间的搜索分两步进行:
(1)超网优化;
(2)空间进化
![[Transformer]AutoFormerV2:Searching the Search Space of Vision Transformer_第2张图片](http://img.e-com-net.com/image/info8/dc52ef396cfc453db8052864b4ba5498.jpg)
Step 1:对于搜索空间A的第i次迭代,会将其编码为超网。
采取sandwich training来优化超网权重,分别采样最大的和最小的和两个中等规模的结构 来计算梯度更新权重。
Step 2:首先将搜索空间A分别成各个搜索维度和4个不同的阶段,这样搜索空间就会变成所有可搜索维度和4个阶段这些子空间的笛卡尔积:
![]()
对于某一个子空间,会搜索其所有可搜索的值,然后计算当前设定下的E-T误差,然后估计E-T误差与参数选择之间的关系 用线性函数![]()
来拟合。
这样就可以获得任意一个子空间的定义:
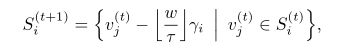
通过设定进化开始的阈值来决定什么时候进行搜索空间的进化。
Part 4 Searching in the Searched Space
当搜索空间搜索完毕,就可以在给定的搜索空间内继续进行NAS。整个搜索过程分2个步骤:
(1)超网训练 此时不施加资源约束
;
(2)进化搜索
在资源约束下进行
超网的训练与AutoFormerV1类似 会从每次迭代中随机抽取最大、最小、中等的随机架构来更新权重。
优化的目标是提升分类精度的同时最小化模型的大小和FLOPs.需要注意的是ViT中没有任何BN因此进化要比大多数CNN更快。
Section III Analysis and Discussion
本节对搜索空间的搜索过程进行讨论从而希望能为Transformer架构设计和NAS搜索空间的设计提供指引。为了最少使用先验知识,本文为不同stage设置相同的搜索空间,Fig 2,Fig3展示了详细的搜索空间和进化过程。
Fig 2每一行代表不同stage每一列代表不同的搜索维度,dot代表最终这一维度的搜索结果,FIG2可以看出每一个维度的变化趋势。
![[Transformer]AutoFormerV2:Searching the Search Space of Vision Transformer_第3张图片](http://img.e-com-net.com/image/info8/ed7dde394d814e059c7b438c441337a4.jpg)
The third stage is most important and increasing blocks in the third stage leads to better performance
从Fig 2可以看出第三阶段是最重要的,从step 0到steo 2有明显提升;本文也在一些CNN网络中发现第三阶段一般会有更多block。另一方面也能看到stage1,2,4的block较少,说明这些阶段应该包含更少的层。
Shallower layers should use a small window size while deep layers should use a larger one
从Fig 2最后一行可以看出,window size会在stage1减少size,stage3增大size,说明浅层倾向于window size更小,深层次使用更大size的window。
本文认为是Transformer随着深度加深增加了其聚焦区域的大小,为了验证这一点本文还可视化了注意力图,参见Fig 4.
![[Transformer]AutoFormerV2:Searching the Search Space of Vision Transformer_第4张图片](http://img.e-com-net.com/image/info8/7315eac415604a879a17a325a31cd47c.jpg)
注意力图中可以看到最大的注意力(数值最大)会随着层次的加深而扩大范围(平均距离增大),代表聚焦的区域也在扩大,这为我们之前的假设提供了坚实的证据。
Deeper layer should use larger MLP ratio
更深的层次应该使用更大的MLP ratio,传统的设计中一般所有的层其MLP Ratio都相同,但是Fig 2的第三行说明浅层应该用更小的MLP ratio,较深的层使用较大的MLP ratio.
Q-K-V dimension should be smaller than the embedding than the emnedding dimension
原始Transformer中,Q-K-V的尺寸与嵌入维度相同,但是从Fig 2第二行、第三行可以看出Q-K-V的维度组好比嵌入维度要小,两者的差距在更深层次找那个更为明显。本文的推测是深层中许多head有相似的特征,因此一个相对较小的Q-K-V维度可以具有较大的视觉表征能力。
Section IV Experiments
Part 1 实验细节
搜索的维度包括:
整个空间每个stage迭代3次
超网的训练遵循DeiT的训练策略 会在16块V100上训练300epoches
Part 2 Ablation Study
Effectiveness of once-for-all supernet training
为了验证超网训练的有效性,被窝呢随机采样了10个网络直接继承超网权重然后与微调之后或者从头训练之后的结果做对比,参见Fig 5.可以看到直接继承超网权重额可以与后两者达到差不多甚至更好的性能,说明了本文的超网采样以及性能预测代理的准确性。
![[Transformer]AutoFormerV2:Searching the Search Space of Vision Transformer_第5张图片](http://img.e-com-net.com/image/info8/1f90081d9a474c9abdd259b2d5f1d6b5.jpg)
![[Transformer]AutoFormerV2:Searching the Search Space of Vision Transformer_第6张图片](http://img.e-com-net.com/image/info8/401137105ee546588066b35f7d627d07.jpg)
Effectiveness of search space evolution
本文还测试了搜索空间进化的有效性。首先进行的实验是从搜索空间中随机抽取1000个子网继承权重然后绘制其误差分布图,参见Fig 6,可以看到进化2次后的空间质量整体明显优于原始和进化了1次的;第二个实验是使用进化算法搜索每个空间中的top结构
Table5展示了在二次演化的空间中的top结构比a,b中的top结构更好 这些结果证明了空间进化的有效性。
Part 3 Image Classification
本文将搜到的模型与其他SOTA模型在ImageNet上的表现进行了对比 参见Table 1.
可以看到本文搜索到的模型S-(T/S/B)分别取得了82.1%/83.7%/84%的top-1精度;并且和其他CNN或Transformer模型比在FLOPs和网络参数接近的情况下性能更优越,特别是在小参数量时更是略优于Efficient-B7(AutoFormerV1这里没有超过EfficientNet).
![[Transformer]AutoFormerV2:Searching the Search Space of Vision Transformer_第7张图片](http://img.e-com-net.com/image/info8/4f4c48c1f6734e85ab98298b552e6855.jpg)
![[Transformer]AutoFormerV2:Searching the Search Space of Vision Transformer_第8张图片](http://img.e-com-net.com/image/info8/0cca48d9149d4bb2981bac4a32d268ef.jpg)
![[Transformer]AutoFormerV2:Searching the Search Space of Vision Transformer_第9张图片](http://img.e-com-net.com/image/info8/3c2a63207b8f43209dc41458ba211a05.jpg)
Part 4 Vision and Vision-Language Downstream Tasks
本文还将搜索到的结果迁移到其他下游视觉任务,如目标检测、语义分割和VQA任务上。
Table 2是目标检测的结果,Table 3是语义分割的结果,Table 4是VQA的结果。
在目标检测试验中,随着model size和FLOPs的增大S3-S,S3-B的性能超过了ResNeXt-101,并且也优于对应的Swin网络。
在实例分割实验中S3一直优于对应的ResNet,DeiT网络;本文还尝试着借助转置卷积搭建一个DeiT的层次结构但性能并没有得到改善。
在VQA实验中实验结果显示选择S3-T作为骨干网路可以比ResNet-101作为骨干获得2%的精度提升。
上述实验都证明了搜索到的模型具有良好的泛化性,也证明了搜索空间设计的有效性。
Section V Related Work
Vision Transformer
Transformer
最初用于NLP领域,ViT是第一个纯Transformer模型用于视觉任务;DeiT则在训练策略上进行了精巧的设计。还有一些其他工作,比如SwinTransformer使用基于窗口的SA模块来减少计算量但是效果也不错。
Search Space
人们普遍认为,一个好的搜索空间对NAS是至关重要的。对于CNN来说目前有基于cell的和基于mbconv的搜索空间,这些操作在搜索前就已经给定了;也有的工作尝试将搜索空间缩小从而寻找更加紧凑的网络模型;NSENet则是提出一种理解设计空间和设计原则的新范式,但是对Transformer这方面的探索还不多,本文是第一个从事这方面工作研究的。
Search Algorithm
最近对NAS进行自动化的网络设计越来越感兴趣,早期的方法主要基于强化学习或进化算法,这些搜索方法一般需要从头训练数以千计的候选网络;近期更多的是按照one-shot的思想,训练一个过参数化的超网,所有子网会共享超网权重。
但是对于NAS改进Transformer结构的工作很少,目前主要有:
HAT:提出硬件感知的Transformer在搜索过程汇总加入延迟约束来获得适应不同硬件平台的网络;
BossNAS则探索了基于block的自监督方法搜索CNN-Transformer混合框架。
最近的一篇工作则是本文的前身——AutoFormer,基于weight-entanglement进行有效的搜索;本文则主要关注搜索空间的搜索。
Section VI Conclusion
本文提出S3-搜索Vision Transformer的搜索空间,核心思想是在使用权重共享的超网训练过程中基于E-T误差逐步进化搜索空间的不同维度;本文还对ViT的进化过程进行了分析,这将有助于理解Transformer各部分的结构和作用。
最终搜索到的S3模型优于目前主流的Transformer和Swin;并且在下游任务中也展现出良好的鲁棒性和泛化性。
本文未来将进一步探索S3在CNN搜索空间设计中应用的可能性。