python爬虫实操|爬取nba中国官网球员数据
本次我们将爬取Ajax动态加载数据并进行简单数据分析,其主要方式是找到数据的json包,将其保存到本地目录,进行数据分析
文章目录
- 一、业务分析
- 二、步骤
-
- 1.找到数据
- 2.抓取数据
- 3.分析数据
- 总结
一、业务分析
目标网站:NBA中国官方网站https://china.nba.com/statistics/
爬取字段:
使用到的库:requests, json,csv,pandas numpy ,matplotlib
其中requests,json进行数据抓取
cxv保存到本地
pandas,numpy进行数据分析
matplotlib可视化
二、步骤
1.找到数据
首先,我们要找到储存数据的json包,F12进入开发者模式
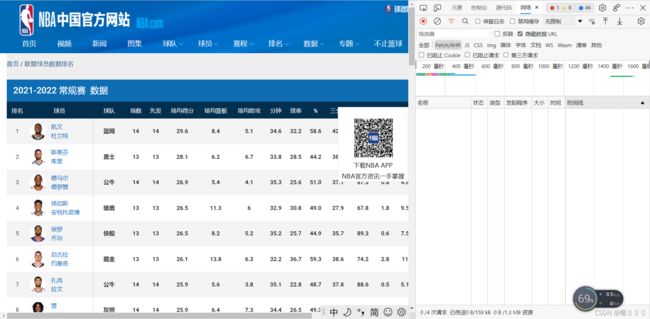
点击网络,选择XHR,进行刷新,就可以看到json包了
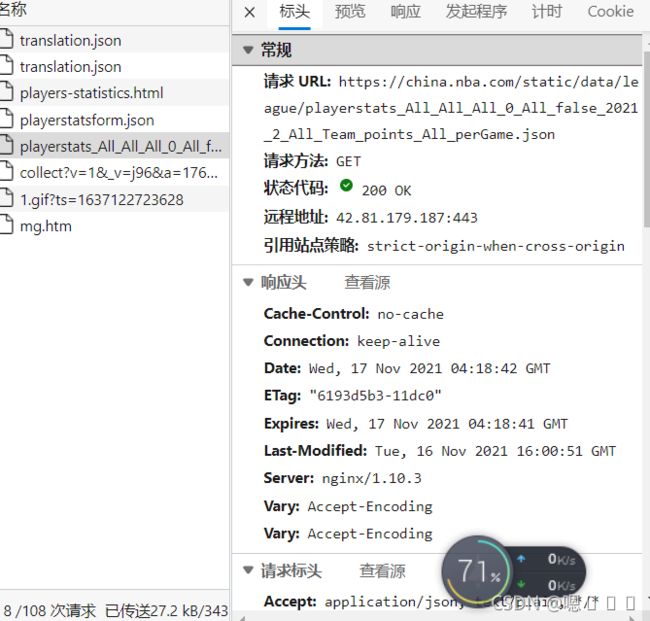
这里我们可以得到请求头信息以及json包

这就是一会儿要抓取的数据
2.抓取数据
这里我选择了抓取本赛季前50球员的数据,在json包中寻找,可以看到
![]()
这里存放的是本赛季的数据
导入库
import requests
import json
import csv
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
先定义抓取json包方法
def getJson(url):
headers={
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.53'
}
response = requests.get(url,headers=headers)
json_data = json.loads(response.text)
return json_data
定义抓取数据的方法
def getData(json_data):
playerList=[]
for item in json_data['payload']['players']:
player_dataDict={}
#球员名字
name=item['playerProfile']['code']
#出场次数
games=item['statAverage']['games']
#先发
gamesStarted=item['statAverage']['gamesStarted']
#分钟
mins=item['statAverage']['minsPg']
#三分命中
tpm=item['statAverage']['tppct']
#罚球命中
ftm=item['statAverage']['ftpct']
#进攻
offRebs=item['statAverage']['offRebsPg']
#防守
defRebs=item['statAverage']['defRebsPg']
#篮板
rebs=item['statAverage']['rebsPg']
#助攻
assists=item['statAverage']['assistsPg']
#抢断
steals=item['statAverage']['stealsPg']
#盖帽
blocks=item['statAverage']['blocksPg']
#失误
turnovers=item['statAverage']['turnoversPg']
#犯规
fouls=item['statAverage']['foulsPg']
#得分
points=item['statAverage']['pointsPg']
player_dataDict['球员']=name
player_dataDict['场次']=games
player_dataDict['先发']=gamesStarted
player_dataDict['出场时间']=mins
player_dataDict['三分命中率']=tpm
player_dataDict['罚球命中率']=ftm
player_dataDict['进攻效率']=offRebs
player_dataDict['防守效率']=defRebs
player_dataDict['篮板']=rebs
player_dataDict['助攻']= assists
player_dataDict['抢断']=steals
player_dataDict['盖帽']=blocks
player_dataDict['失误']=turnovers
player_dataDict['犯规']=fouls
player_dataDict['得分']=points
print(player_dataDict)
playerList.append(player_dataDict)
return playerList
接下来进行存储
def writeData(playerList):
#写入数据
with open('player_data.csv','w',encoding='utf-8',newline='')as f:
write=csv.DictWriter(f, fieldnames=['球员','场次','先发','出场时间','三分命中率','罚球命中率',
'进攻效率','防守效率','篮板','助攻',
'抢断','盖帽','失误','犯规','得分'])
write.writeheader()
for each in playerList:
write.writerow(each)
完整代码
import requests
import json
import csv
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
url='https://china.nba.com/static/data/league/playerstats_All_All_All_0_All_false_2021_2_All_Team_points_All_perGame.json'
def getJson(url):
headers={
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.53'
}
response = requests.get(url,headers=headers)
json_data = json.loads(response.text)
return json_data
def getData(json_data):
playerList=[]
for item in json_data['payload']['players']:
player_dataDict={}
#球员名字
name=item['playerProfile']['code']
#出场次数
games=item['statAverage']['games']
#先发
gamesStarted=item['statAverage']['gamesStarted']
#分钟
mins=item['statAverage']['minsPg']
#三分命中
tpm=item['statAverage']['tppct']
#罚球命中
ftm=item['statAverage']['ftpct']
#进攻
offRebs=item['statAverage']['offRebsPg']
#防守
defRebs=item['statAverage']['defRebsPg']
#篮板
rebs=item['statAverage']['rebsPg']
#助攻
assists=item['statAverage']['assistsPg']
#抢断
steals=item['statAverage']['stealsPg']
#盖帽
blocks=item['statAverage']['blocksPg']
#失误
turnovers=item['statAverage']['turnoversPg']
#犯规
fouls=item['statAverage']['foulsPg']
#得分
points=item['statAverage']['pointsPg']
player_dataDict['球员']=name
player_dataDict['场次']=games
player_dataDict['先发']=gamesStarted
player_dataDict['出场时间']=mins
player_dataDict['三分命中率']=tpm
player_dataDict['罚球命中率']=ftm
player_dataDict['进攻效率']=offRebs
player_dataDict['防守效率']=defRebs
player_dataDict['篮板']=rebs
player_dataDict['助攻']= assists
player_dataDict['抢断']=steals
player_dataDict['盖帽']=blocks
player_dataDict['失误']=turnovers
player_dataDict['犯规']=fouls
player_dataDict['得分']=points
print(player_dataDict)
playerList.append(player_dataDict)
return playerList
def writeData(playerList):
#写入数据
with open('player_data.csv','w',encoding='utf-8',newline='')as f:
write=csv.DictWriter(f, fieldnames=['球员','场次','先发','出场时间','三分命中率','罚球命中率',
'进攻效率','防守效率','篮板','助攻',
'抢断','盖帽','失误','犯规','得分'])
write.writeheader()
for each in playerList:
write.writerow(each)
if __name__ == "__main__":
json_data = getJson(url)
playerList=[]
playerList += getData(json_data)
writeData(playerList)
3.分析数据
数据都存放到本地了,我们当然可以为所欲为
这里我们选取了几个字段,生成了每个球员的雷达图,方便进行比较
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df=pd.read_csv('player_data.csv')
for i in range(50):
x=df.loc[i]
name=x.loc[['球员']]
y=x.loc[['犯规','篮板','助攻','抢断','盖帽','失误']]
labels=np.array(['犯规','篮板','助攻','抢断','盖帽','失误'])
data=np.array(y)
plt.rcParams['font.sans-serif']=['SimHei']
angles=np.linspace(0, 2*np.pi,len(labels),endpoint=False)
labels=np.concatenate((labels,[labels[0]]))
data=np.concatenate((data,[data[0]]))
angles=np.concatenate((angles,[angles[0]]))
plt.polar(angles, data,'bo-',linewidth=1)
plt.thetagrids(angles*180/np.pi,labels)
plt.fill(angles, data,facecolor='b',alpha=0.25)
plt.title(str(name))
plt.show()
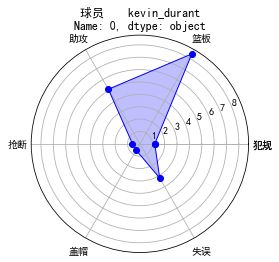
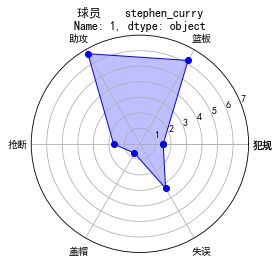
就不一个个上图了
总结
Ajax动态数据还是非常容易爬取的,同时pandas和numpy库也非常值得学习
最后一句
“湖人总冠军”