好书推荐——从零开始学习 Julia 编程、数学和数据科学。
好书推荐——数据科学简介:从零开始学习 Julia 编程、数学和数据科学。
书
- 好书推荐——数据科学简介:从零开始学习 Julia 编程、数学和数据科学。
-
- 书籍信息
- 前言
-
- 个人感受
- 封面:
-
- 个人感受
- 封底:
-
- 个人感受
- 1. 你需要知道的
-
- 1.1.GNU/Linux
- 1.2. 数学
- 2. 你需要什么?
- 3. 什么是数据科学?
- 4. 数据科学的阶段
-
- 4.1.收集数据
- 4.2. 数据整理
- 4.3. 统计数据
- 4.4. 可视化
- 4.5. 机器学习 (ML)
-
- 4.5.1.特征工程
- 4.5.2. 机器学习
- 4.5.3. 神经网络
- 4.6. 自动化
- 4.7. 缩放
- 总结:
-
- 附上超全目录(文字显示为机翻,不过对于帮助我们浏览观看还是挺有帮助的):
书籍信息
作者:Karthikeyan A K
在线阅读:Introduction to Datascience: Learn Julia Programming, Math & Datascience from Scratch.
关键词:数学、数据科学、Julia编程语言。
特点: 图文并茂,详略得当,概念讲解得通俗易懂,形象生动,阅读门槛较低,各章节很多看似不相关实则脉络相连
前言
在我的名为 Data Science With Julia [ 1 ]的视频系列获得了一些关注之后,我有了写这本书的勇气。在关于决策树[ 2 ]的推文也被 Julia 语言本身喜欢之后。所以我想为什么不给它更多呢?
这本书应该被视为我试图向自己解释数据科学,仅此而已。这本书能否上升到专业水平还有待观察。
个人感受
作者的勇气其实让我感到很佩服,因为有的时候——说很容易,真正去做,不容易,而且作者还将它完成了,而且作者非常谦逊,值得点赞!
封面:

封面展示了印度神话中的场景,其中善良的力量(Devar’s)和邪恶的力量(Asuran’s)搅动宇宙海洋,揭示出毒药和长生不老药等东西。以类似的方式,数据科学家可以将他掌握的大量数据用于良好目的,例如发现一种可能有效的新药,或用于跟踪和侵犯某人隐私等邪恶目的。
个人感受
看到封面之后,我感受到了一种古典色彩,仿佛跃然纸上,图中分为两方力量——善良的一方和邪恶的一方,让我想到了“科学是一把双刃剑”这句话,就拿一项技术,用于好的方面,那就是有益的,用于不好的方面,那就是有害的,有益还是有害其实是站在了相对的角度,这样我想也是辩证思维的一种体现,有些问题不能浅显地去看,要多方面,多角度去看、去考量。
封底:

我们感谢 Richard M. Stallman ( https://stallman.org ) 和自由软件基金会 ( https://fsf.org ) 使这本书成为可能。
个人感受
以微笑结尾,并表达感谢,我想这是很好的方式,就像演讲时的时候,感谢收尾一样,给此本书画上了圆满的句号。
接下来,我们通过前四小节部分,简单地走进这本书:
1. 你需要知道的
1.1.GNU/Linux
如果您没有使用过 GNU/Linux,则需要了解它,学习它的最佳地点之一是https://linuxjourney.com。
1.2. 数学
数据科学是数据处理与计算机科学相遇的地方。计算机很好,数学很快,数据科学就是数学。要了解数学,可以查看可汗学院[ 3 ]提供的课程。可以通过这些课程
- 初等微积分
- 结石
- 矩阵
- 概率和统计
有人还阅读了这本书《机器学习数学》[mml]。
2. 你需要什么?
运行本书中的程序可能需要一台性能良好的计算机。我想说最好有一台 GNU/Linux [ 4 ]机器,这样你就可以探索数据科学领域。
3. 什么是数据科学?
有很多数据,事实上我们创造了数据爆炸这个词,而且比我们意识到的更多次,这些数据表明了一些有价值的东西。有了数据,人们已经成为了不起的股票交易员[ 5 ],他们让机器赢得了原本认为只有人类才能赢得比赛的比赛[ 6 ]。
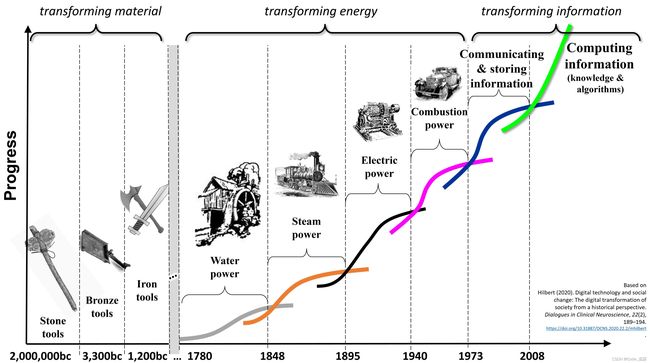
事实证明,如果我们可以通过聪明的计算机科学对大量数据进行数学运算,我们就可以做曾经被认为不可能的事情,并且那里有大量数据。
数据科学是一个我们使用计算机科学来理解我们周围的大量数据的领域。我们试图让它成为人类可以理解的,我们试图预测事情,即使我们可能不明白为什么会发生一些事情。这就是数据科学。
这可能是超级智能的风口浪尖,这肯定是数据的新时代。欢迎来到这个美妙的宇宙!
4. 数据科学的阶段
在专业环境中,数据科学可能并不简单。它需要很多阶段,当我说阶段时,不要把它想象成一个瀑布模型,每个阶段都是一个隔间,把它们想象成一个相互重叠的模糊事物。一个工作做得够多可能会导致另一个工作。本节描述了这些阶段。
4.1.收集数据
第一阶段之一是收集数据。在某些项目中可能有数据,而在某些项目中可能没有数据。您必须设计一种收集数据的方法。在某些情况下,客户会向您提供数据,但它不会是正确的。
即使您收集了正确的数据,它也可能处于非常混乱的状态,不适合任何目的。
4.2. 数据整理
数据整理是您尝试修改数据以使其适合您的目的的阶段。可能您需要收集推文并将其标记为积极或消极情绪。可能您使用的电子表格中的数据丢失了很多东西,该怎么办?
您需要了解手头的任务并与人沟通,并提出计划以使数据更适合在其上应用数学。
4.3. 统计数据
在此阶段将对数据应用统计信息。您可能会计算特定文本中出现的单词数以了解有关它的内容。您可能会将一些数值总结为均值、中位数、众数、四分位间距 (IQR) 等,并尝试理解它的意义等等。如果对经过整理和清理的数据进行统计,通常会进行统计。
4.4. 可视化
在现实世界的数据科学中,大多数问题都是通过可视化来解决的。人类是视觉动物,当某些东西以视觉形式呈现时,他们很容易得到它。我什至认为可视化是数据科学中最重要的事情。
4.5. 机器学习 (ML)
当您进行统计和可视化时,大多数问题都会产生并变得可以理解。如果不是,我们必须进行机器学习,其中机器和算法的任务是学习数据以预测有关数据,或对数据进行分类等等。
4.5.1.特征工程
机器学习的主要内容之一是特征工程。想想泰坦尼克号,当它淹死时,一些人幸存下来,另一些人死亡。你认为一个人的存活率取决于他的名字吗?他穿的衣服是什么颜色的?或者你认为这取决于他的年龄、性别、他乘坐的班级?这些是您在特征工程中需要考虑的事情。
理想情况下,如果选择正确的特征并将其提供给机器学习系统,它将快速训练并给出正确的结果。
4.5.2. 机器学习
机器学习是您将(高度修改的)数据提供给学习系统的阶段,希望它能够了解它并产生良好的结果。在确定最佳算法之前,您可能需要尝试许多 ML 算法。
4.5.3. 神经网络
当你可用的数据真的很大时,如果你无法提取特征,那么可以进入神经网络。神经网络是根据我们大脑中的神经元[ 7 ]松散地建模的,并且可以在没有太多人为干预的情况下训练自己。
4.6. 自动化
当您按照上述部分中介绍的技术找到了一个令人满意的解决方案时,您需要自动化该过程,例如构建一个好的编程库并将其托管在计算机上以自动化任务。自动化任务可以执行如下所示的操作:
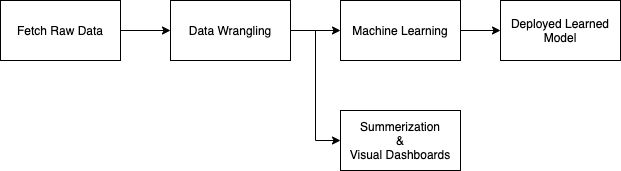
这种逐步转换数据的方法称为流水线。
4.7. 缩放
通常在需要流水线和处理大量数据量的项目中,它也需要扩展。如果有大量数据进入您的休眠服务器,您会怎么做?如果你有很多服务器运行你的算法来处理你的数据,当数据枯竭时这些服务器会发生什么?您不想为未使用的服务器支付高额费用。这些都是您在扩展阶段会担心的所有事情。
但这本书不是关于缩放的。但它可以在未来覆盖。
了解完前四节之后,相信你已经对这本书有了简单的了解,剩下具体的内容可点击这个 书籍全文 进行阅读
接下来总结一下
总结:
从零开始学习 Julia 编程、数学和数据科学。其实从书名上就告诉了我们本书重点讲解的三部分内容——①Julia编程、②数学、③数据科学。此外作者还对机器学习、人工智能和数据科学等进行了区分介绍。整本书从目录上就可以看出,分的很细,点开一个章节去看也比较容易去理解接收,从基础讲起,循序渐进地学习,这一点很不错!书中也配了很多图,让文字读起来,感觉不枯燥,这或许就是图文并茂所展示的优势所在。书的优点有很多,当然也会有其缺点和瑕疵——可能看的时候感觉联系性不强,但其实想想还是不错的。
书的话,仁者见仁智者见智,个人来讲,整体来说是瑕不掩瑜的,不错的一本书。
附上超全目录(文字显示为机翻,不过对于帮助我们浏览观看还是挺有帮助的):
- 前言
- 封面
- 封底
- 1. 你需要知道的
- 1.1。GNU/Linux
- 1.2. 数学
- 2. 你需要什么?
- 数据科学
- 3. 什么是数据科学?
- 4. 数据科学的阶段
- 4.1。收集数据
- 4.2. 数据整理
- 4.3. 统计数据
- 4.4. 可视化
- 4.5. 机器学习 (ML)
- 4.6. 自动化
- 4.7. 缩放
- 5. 预测性和描述性分析
- 5.1。描述性和预测性分析 - 伦敦霍乱
- 5.2. 描述性分析 - 拿破仑的俄罗斯战败
- 5.3. 描述后的预测
- 5.4. 可视化的力量
- 6.机器学习、人工智能和数据科学
- 6.1。机器学习
- 6.2. 人工智能
- 6.3. 数据科学
- 朱莉娅
- 7. 安装 Julia
- 8. 朱莉娅 REPL
- 8.1。球体体积
- 8.2. 清算 REPL
- 8.3. 退出语句
- 8.4. 历史
- 8.5。退出 REPL
- 9. 访问帮助
- 10. 包管理
- 10.1。安装包
- 10.2. 删除包
- 10.3. 参考
- 11. 安装 Jupyter notebook 和 Jupyter lab
- 11.1。安装 IJilia
- 11.2. 启动 Jupyter Notebook
- 11.3. 启动 Jupyter 实验室
- 11.4. 参考
- 12. 从 Julia 开始(使用 Jupyter)实验室
- 13. 文件中的 Julia 程序
- 14. 基本算术
- 15. 弦乐
- 16. 布尔运算
- 17. 比较
- 18. 条件和分支
- 19. 三元运算符
- 20. 短路评估
- 20.1。如何不使用快捷方式评估
- 21.while循环
- 21.1。寻找素数
- 22. 范围和 for 循环
- 23. 休息和继续
- 24. 数组
- 25. 元组
- 26. 理解
- 26.1. 发电机理解
- 26.2. 排列
- 26.3. 扁平化理解
- 27.Sets
- 27.1. 工会
- 27.2. 路口
- 27.3. 区别
- 27.4. 其他操作
- 27.5。您无法对 Set 进行排序
- 27.6。将集合转换为数组
- 27.7。覆盖集到元组
- 27.8. 从 Set 中弹出一个元素
- 28. 字典
- 29. 评论
- 30. 功能
- 30.1。传递参数
- 30.2。默认参数
- 30.3。默认参数
- 30.4。更多默认参数
- 30.5。返回值
- 30.6。命名参数
- 30.7。单线功能
- 30.8。作用于向量的函数
- 30.9。使用地图函数
- 30.10。匿名函数
- 30.11。变量参数
- 30.12。管道/链接功能
- 30.13。将函数作为参数传递
- 30.14。多次派遣
- 31. 正则表达式(regexp)
- 31.1。正则表达式的味道
- 31.2. 要记住的事情
- 31.3。点
- 31.4。字符类
- 31.5。锚点
- 31.6。捕获
- 31.7。计数
- 31.8。字符串到正则表达式
- 31.9。区分大小写和不区分大小写的匹配
- 31.10。扫描
- 31.11。了解有关正则表达式的更多信息
- 32.结构
- 32.1。可变结构
- 32.2. 值类型
- 32.3. 复杂数据类型
- 33. 模块
- 34. 向量和矩阵
- 35. 文件
- 35.1。纯文本
- 35.2. CSV
- 35.3. JSON
- 35.4。文本与二进制
- 36. 报废
- 37. 地块
- 37.1。安装 Julia 绘图
- 37.2. 基本绘图功能 - 绘制 Sin 和 Cos
- 37.3。散点图和直方图
- 37.4。了解有关地块的更多信息
- 38. 数据框
- 39. 调试
- 数学
- 40. 向量
- 40.1。添加
- 40.2。减少功能
- 40.3。中点
- 40.4。距离
- 40.5。震级
- 40.6。单位向量
- 40.7。向量库
- 41. 矩阵
- 42. 乙状结肠
- 43. 贝叶斯
- 44. 统计
- 44.1。全部的
- 44.2. 最低限度
- 44.3. 最大
- 44.4. 范围
- 44.5。意思是
- 44.6。中位数
- 44.7。均值与中值
- 44.8。模式
- 44.9。百分位数
- 44.10。四分位距 (IQR)
- 44.11。方差
- 44.12。标准差
- 44.13。协方差
- 44.14。相关性
- 44.15。参考
- 45. 概率
- 45.1。独立和从属事件
- 45.2. 蒙特卡罗模拟
- 45.3。贝叶斯定理
- 45.4。正态分布曲线
- 机器学习
- 46. 遗传算法
- 46.1。用遗传算法猜数字
- 46.2. 使用遗传算法进行曲线拟合
- 47. K 最近邻
- 48. 决策树
- 48.1。了解泰坦尼克号数据集
- 48.2. 熵
- 48.3. 在 Titanic 数据集上应用熵
- 48.4. 特征工程
- 48.5。特色工程数据集的熵
- 48.6。构建决策树
- 49.梯度下降
- 49.1。梯度下降猜数
- 49.2. 梯度下降的线性回归
- 49.3. 使用梯度下降推广线性回归
- 50.冷热学习
- 50.1。猜数字
- 50.2。拟合一条线
- 51. K 表示聚类
- 51.1。直觉
- 51.2。用 Julia 编写
- 52. 用于文本分类的朴素贝叶斯
- 神经网络
- 53. 反向传播
- 参考书目