Pandas使用操作(二)
获取列名
1、df.columns
#返回的是array格式。
df.columns[0]
2、list(df)
#返回list格式。
list(df)[0]
3、df.keys()
#pandas.core.indexes.base.Index
df.keys()[0]
将空字符串替换为nan
dataframe.iloc[:,0].str.split(',',expand=True).replace('',np.nan)
将NaN替换成None
df = df.where(df.notnull(), None)
查找输出,不改变原本内容
tps_name.DESC_out.fillna('')
几列数据合并成一列
方法1:+
使用 + 直接将多列合并为一列(合并列较少);
dataframe["newColumn"] = dataframe["age"].map(str) + dataframe["phone"] + dataframe["address”]
方法2:str.cat
使用pandas.Series.str.cat方法,将多列合并为一列(合并列较多);
dataframe["newColumn"] = dataframe["age"].map(str).str.cat([dataframe["phone"],dataframe["address”]],sep='-',na_rep='?')
#语法
Series.str.cat(others=None, sep=None, na_rep=None, join=None)
others : 准备合并的字符串列表,其数据类型可以为:Series, Index, DataFrame, np.ndarrary(N元数组) or list-like(类似列表)
备注: 由于默认join=None,所以欲合并的两个(多个)字符串列表必须具有相同的长度,否则需设置参数join= {‘left’, ‘right’, ‘outer’, ‘inner’},来控制多个字符串列表的合并方式。
(1)如果others=None(即:字符串列表df[col_1]不与其他字符串列表合并),结果将不传递其他值,而是将df[col_1]的所有值都连接成一个字符串;(详见范例1-1)
(2)如果others≠None(即:指定了与字符串列表df[col_1]合并的其他字符串列表df[col_2]),结果将用分隔符把df[col_1]与df[col_2]对应的行值连接在一起, 返回Series。(详见范例1-2)
**sep:**合并结果中不同元素/列之间的分隔符。默认情况下,使用空字符串’ ’ 。
**na_rep:**为所有缺失值插入的内容,其数据类型可以为:str或None,默认na_rep=None
备注:
(1)如果na_rep=None,则多个合并列中只要有一列的对应行元素为NaN,合并结果中该行元素将为NaN;
(2)如果na_rep=‘str’(str需自定义),则合并列中各缺失行元素将被填充为‘str’,合并结果将保留合并列的所有行元素;
join :确定连接方式,其可能的取值为:{‘left’, ‘right’, ‘outer’, ‘inner’},默认join=None
注意事项:
参与合并的列的数据类型必须为str类型,int和float等数值类型需先转化为str;
参与合并的列的长度必须相同(即:行数),否则报错,但使用pandas.Series.str.cat方法,可通过指定参数join={‘left’, ‘right’, ‘outer’, ‘inner’},实现长度不相等的列合并;
参与合并的列的各行元素均不为NaN,否则,只要有一列的对应行元素为NaN,则合并结果中该行将为NaN,但使用pandas.Series.str.cat方法,可通过指定参数na_rep=’-’,将各列中缺失行元素填充为‘-’,从而保留合并列的所有行元素;
分列split
Series.str.split(pat=None, n=-1, expand=False)
– pat 分隔符 – n 指定分割次数 -1代表全部 – expand=True 分列 返回多列
df = pd.DataFrame({'id':[1, 2],'code':['A,B,C', 'B,C']})
df.code.str.split(',')
# 按逗号分割(Series)
df.code.str.split(',')
'''
0 [A, B, C]
1 [B, C]
Name: code, dtype: object
'''
# 自动分列(DataFrame)
df.code.str.split(',', expand=True)
'''
0 1 2
0 A B C
1 B C None
'''
# 指定参数n 分割次数(DataFrame)
df.code.str.split(',', expand=True, n=1)
'''
0 1
0 A B,C
1 B C
'''
#支持正则表达式分割符
s = pd.Series(["1+1=2"])
s.str.split(r"\+|=", expand=True)
'''
0 1 2
0 1 1 2
'''
从右往左寻找分列依据,使用语法类似 split。
df['code'].str.rsplit(',', expand=True, n=1)
'''
0 1
0 A,B C
1 B C
'''
分组Grop
分组运算过程:split->apply->combine
- 拆分:进行分组的根据
- 应用:每个分组运行的计算规则
- 合并:把每个分组的计算结果合并起来
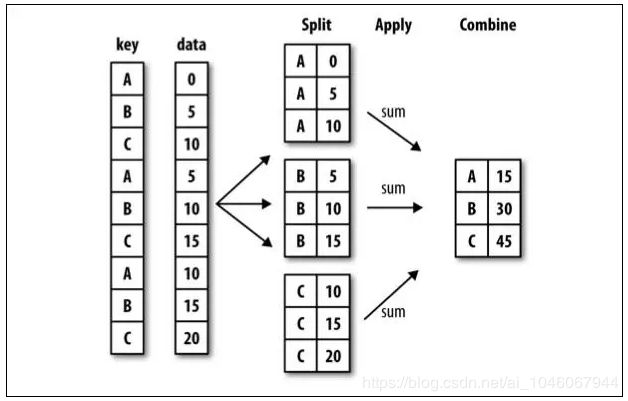
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, observed=False, **kwargs)
#by: 依据哪些列进行分组,值可以是:mapping, function, label, or list of labels
聚合函数

分组聚合
import pandas as pd
df = pd.DataFrame({'A': ['a', 'b', 'a', 'c', 'a', 'c', 'b', 'c'], 'B': [2, 8, 1, 4,
3, 2, 5, 9], 'C': [102, 98, 107, 104, 115, 87, 92, 123], 'D': [2, 98, 17, 14, 15, 7, 92,
13]})
#单列分组
df.groupby(by='A').sum()
B C D
A
a 6 324 34
b 13 190 190
c 15 314 34
#多列分组
df.groupby(by=['A','B']).sum() ###A,B成索引
C D
A B
a 1 107 17
2 102 2
3 115 15
b 5 92 92
8 98 98
c 2 87 7
4 104 14
9 123 13
#多列聚合
df.groupby(by=['A','B'])['C','D'].sum() ###2个列
C D
A B
a 1 107 17
2 102 2
3 115 15
b 5 92 92
8 98 98
c 2 87 7
4 104 14
9 123 13
#多列不同聚合方式
import numpy as np
df.groupby(by=['A']).agg({'C':[np.mean, 'sum'], 'D':['count',np.std]})
C D
mean sum count std
A
a 108.000000 324 3 8.144528
b 95.000000 190 2 4.242641
c 104.666667 314 3 3.785939
#方法1:agg
df.groupby(by=['A']).agg({'C':[np.mean]})
C
mean
A
a 108.000000
b 95.000000
c 104.666667
type(df.groupby(by=['A']).agg({'C':[np.mean]}))
<class 'pandas.core.frame.DataFrame'>
#方法2:索引
df.groupby(by=['A'])['C'].mean()
A
a 108.000000
b 95.000000
c 104.666667
Name: C, dtype: float64
type(df.groupby(by=['A'])['C'].mean())
<class 'pandas.core.series.Series'>
#总结: 两种方法结果一样,但是一个类型是DataFrame,一个为Series;有时候会用上
遍历分组
import pandas as pd
import numpy as np
ipl_data = {'Team': ['Riders', 'Riders', 'Devils', 'Devils', 'Kings',
'kings', 'Kings', 'Kings', 'Riders', 'Royals', 'Royals', 'Riders'],
'Rank': [1, 2, 2, 3, 3,4 ,1 ,1,2 , 4,1,2],
'Year': [2014,2015,2014,2015,2014,2015,2016,2017,2016,2014,2015,2017],
'Points':[876,789,863,673,741,812,756,788,694,701,804,690]}
df = pd.DataFrame(ipl_data)
grouped = df.groupby('Year')
使用groupby对象,可以遍历类似itertools.obj的对象。
for name,group in grouped:
print (name)
print (group)
#默认情况下,groupby对象具有与分组名相同的标签名称。
#选择一个分组
#使用get_group()方法,可以选择一个组。参考以下示例代码
print (grouped.get_group(2014))
#聚合函数为每个组返回单个聚合值。当创建了分组(group by)对象,就可以对分组数据执行多个聚合操作。
#一个比较常用的是通过聚合或等效的agg方法聚合 -
print (grouped['Points'].agg(np.mean))
grouped = df.groupby('Team')
agg = grouped['Points'].agg([np.sum, np.mean, np.std])
print (agg)
#转换
#分组或列上的转换返回索引大小与被分组的索引相同的对象。因此,转换应该返回与组块大小相同的结果。
grouped = df.groupby('Team')
score = lambda x: (x - x.mean()) / x.std()*10
print (grouped.transform(score))
#过滤
#过滤根据定义的标准过滤数据并返回数据的子集。filter()函数用于过滤数据。
filter = df.groupby('Team').filter(lambda x: len(x) >= 3)
print (filter)
排序sort_index
#按索引进行降序排列
df.sort_index(ascending=False)
#按值进行降序排列
df.sort_values(by="A",ascending=False) # 按某一列
df.sort_values(by=["B","A"],ascending=False) # 按2列
两个DataFrame操作
df1=pd.DataFrame([[1,2,3],[2,3,4]],columns=['a','b','c'])
df2=pd.DataFrame([[2,3,4],[3,4,5]],columns=['d','e','f'])
df3=pd.DataFrame([[1,2,3],[2,3,4]],columns=['a','b','d'])
1.合并
concat函数
pandas中concat函数的完整表达,包含多个参数,常用的有axis,join,ignore_index.
concat函数的第一个参数为objs,一般为一个list列表,包含要合并两个或多个DataFrame,多个Series
pandas.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False,
copy=True)
-
axis表示合并方向,默认axis=0,两个DataFrame按照索引方向纵向合并,axis=1则会按照columns横向合并。
pd.concat([df1,df2],axis=1)[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-plDhbfTm-1640228340389)(C:\Users\21000123\AppData\Roaming\Typora\typora-user-images\image-20211223100947051.png)]
-
join表示合并方式,默认join=‘outer’,另外的取值为’inner’,只合并相同的部分,axis=0时合并结果为相同列名的数据,axis=1时为具有相同索引的数据
pd.concat([df2,df3],axis=0,join='inner') pd.concat([df2,df3],axis=1,join='inner')[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RmYemBvd-1640228340391)(C:\Users\21000123\AppData\Roaming\Typora\typora-user-images\image-20211223101046171.png)]
-
ignore_index表示索引的合并方式,默认为False,会保留原df的索引,如果设置ignore_index=True,合并后的df会重置索引。
pd.concat([df1,df2],ignore_index=True)[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4a4t9Wn2-1640228340392)(C:\Users\21000123\AppData\Roaming\Typora\typora-user-images\image-20211223101143385.png)]
merge函数
merge函数是pandas提供的一种数据库式的合并方法。
on可以指定合并的列、索引,how则是与数据库join函数相似,取值为left,right,outer,inner.left,right分别对应left outer join, right outer join.
pandas.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=False,
suffixes=('_x', '_y'), copy=True, indicator=False,
validate=None):
merge函数可以通过pandas.merge(df1,df2)、df1.merge(df2)两种形式来实现两个DataFrame的合并,df1.merge(df2)是默认left=self的情况
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VYOOaWlz-1640228340392)(C:\Users\21000123\AppData\Roaming\Typora\typora-user-images\image-20211223101533161.png)]
append函数
append函数是pandas针对DataFrame、Series等数据结构合并提供的函数。
df1.append(self, other, ignore_index=False, verify_integrity=False)
f1.append(df2)与pd.concat([df1,df2],ignore_index=False)具有相同的合并结果
df1.append(df2)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Teap9Xtw-1640228340393)(C:\Users\21000123\AppData\Roaming\Typora\typora-user-images\image-20211223101626042.png)]
2.并集/合集/差集
df1 = pd.DataFrame([[1,11,111],[2,22,222],[3,33,333]],columns=['id','data','comment'])
df2 = pd.DataFrame([[0,00,000],[1,11,111],[2,22,222],[4,44,444]],columns=['id','data','comment'])
# 取交集:既在df1中,也在df2中
intersection_result = pd.merge(df1, df2)
print(intersection_result)
# 取合集:df1和df2所有数据的集合
union_result = pd.merge(df1, df2, how='outer')
print(union_result)
#取差集 在df1中但不在df2中的
df1 = df1.append(df2)
df1 = df1.append(df2)
differenct_set_result = df1.drop_duplicates(['id'],keep=False)
print(differenct_set_result)