AlexNet论文阅读总结及代码
最近考虑整理一些经典论文的阅读笔记和重点,包括之前看过的以及近期新阅读的,方便之后复习回顾。
AlexNet论文地址:http://www.cs.toronto.edu/~fritz/absps/imagenet.pdf
AlexNet是2012年在ImageNet比赛上胜出的深度学习模型,并且以明显优势高于传统机器学习模型。虽然已经过去7年,但是其论文中的创新点现在依旧被广泛使用。
1. 网络结构和参数##
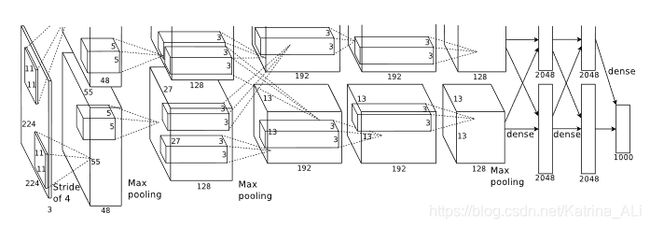
AlexNet一共包含8层,其中5层卷积层(文中说去掉任何一个卷积层效果都会变差),3层全连接层,每层具体的参数如下:
图片数据输入尺寸: 224 × {\times} × 224 × {\times} × 3
第一层卷积层: 96个 11 × 11 × 3 {11 \times 11 \times 3} 11×11×3 的卷积核
(包含一个最大池化层,跟在LRN之后)
第二层卷积层: 256个 5 × 5 × 48 {5 \times 5 \times 48} 5×5×48 的卷积核
(包含一个最大池化层,跟在LRN之后)
第三层卷积层: 384个 3 × 3 × 256 {3 \times 3 \times 256} 3×3×256 的卷积核
第四层卷积层: 384个 3 × 3 × 192 {3 \times 3 \times 192} 3×3×192 的卷积核
第五层卷积层: 256个 3 × 3 × 192 {3 \times 3 \times 192} 3×3×192 的卷积核
(包含一个最大池化层)
第一层和第二层全连接层: 4096个神经元
输出层: 100个类别输出
ImageNet的训练数据为120万张共100个类别的数据,AlexNet一共包括6千万个参数,65万个神经元,并让网络并行训练在两块GPU上(90个epoch),为了提高训练速度,使得两块GPU在进行并行计算的时候只在特定的层进行数据全交互,具体到网络结构中就是第三层卷积层与前一层的连接。
2. 主要创新技术点
(1)使用ReLU作为激活函数;
AlexNet中卷积层和全连接层的神经元均采用ReLU函数作为激活函数,主要原因是ReLU函数在进行梯度下降的计算过程中能显著加快训练过程,也就是非饱和的线性的激活函数 m a x {max} max要快于 s i g m o i d {sigmoid} sigmoid和 t a n h {tanh} tanh等饱和的非线性激活函数的收敛速度。
(在这篇论文中并没有谈及ReLU函数对于梯度消失问题的解决,只是从收敛速度上论述的)
(2)使用Dropout抑制过拟合;
神经网络因为结构复杂,很容易陷入过拟合的状态,因此过拟合措施很重要 。AlexNet分别从数据预处理和创新型手段dropout两方面来抑制过拟合:
数据预处理阶段主要是对数据做了增强扩充处理,也就是说对数据保留标签,同时对图片进行一定程度的翻转等操作,以及对RGB三通道进行强度的调整等;
传统的机器学习模型为了提高泛化能力一般会采用多模型融合,但是对于神经网络来说,训练多个模型的成本太高,因此出现了dropout的方式,dropout主要是通过在每次前后向传播过程中,以一定的概率使部分神经元失效,从而使得训练看起来像是进行了多组模型的训练,但是训练成本并不增加。该措施有效的抑制了过拟合,需要注意的是,模型训练完成后,我们前向计算的时候使用的是整个神经网络,因此需要使得结果乘以神经元失效的比例之后的结果才是我们需要的结果。
(3)使用重叠池化;
池化处理并不是一个新概念,在图像处理中就已经存在,但是那个里面的池化都是非重叠池化,也就是每相邻池化之间没有相互重叠的像素。AlexNet中首次采用了有重叠像素的池化,实验结果验证重叠池化可以提升预测准确率并能抑制过拟合。
(4)使用LRN增强泛化能力,抑制过拟合。
AlexNet中提出局部响应归一化层(LRN),是跟在激活或池化之后的一种为了提高准确度的技术方法。LRN的主要思想就是对局部神经元的神经活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈更小的神经元,从而也在一定程度上增强了泛化能力。
(但是后续的经典网络中LRN的采用并不多,通用性较差)
3. TensorFlow实现代码##
# -*- coding: utf-8 -*-
"""
AlexNet 实现代码
"""
import tensorflow as tf
import numpy as np
#定义最大池化层
def maxPoolLayer(x, kHeight, kWidth, strideX, strideY, name, padding = "SAME"):
return tf.nn.max_pool(x, ksize = [1, kHeight, kWidth, 1], # ksize代表池化的尺寸
strides = [1, strideX, strideY, 1], # 代表步长
padding = padding, name = name) # padding 为SAME代表会自动补全
# 定义dropout
def dropout(x, keepPro, name = None):
return tf.nn.dropout(x, keepPro, name)
# 定义LRN
def LRN(x, R, alpha, beta, name = None, bias = 1.0):
return tf.nn.local_response_normalization(x, depth_radius = R, alpha = alpha,
beta = beta, bias = bias, name = name)
# 定义全连接层
def fullConnectLayer(x, inputD, outputD, reluFlag, name):
with tf.variable_scope(name) as scope:
w = tf.get_variable("w", shape = [inputD, outputD], dtype = "float")
b = tf.get_variable("b", [outputD], dtype = "float")
out = tf.nn.xw_plus_b(x, w, b, name = scope.name)
if reluFlag:
return tf.nn.relu(out)
else:
return out
#定义卷积层
def convLayer(x, kHeight, kWidth, strideX, strideY,
featureNum, name, padding = "SAME", groups = 1):
channel = int(x.get_shape()[-1])
conv = lambda a, b: tf.nn.conv2d(a, b, strides = [1, strideY, strideX, 1], padding = padding)
with tf.variable_scope(name) as scope:
w = tf.get_variable("w", shape = [kHeight, kWidth, channel/groups, featureNum])
b = tf.get_variable("b", shape = [featureNum])
xNew = tf.split(value = x, num_or_size_splits = groups, axis = 3) # tf.split是将张量进行裁剪的函数:将第三维度的切分为groups大小的张量
wNew = tf.split(value = w, num_or_size_splits = groups, axis = 3)
featureMap = [conv(t1, t2) for t1, t2 in zip(xNew, wNew)]
mergeFeatureMap = tf.concat(axis = 3, values = featureMap)
out = tf.nn.bias_add(mergeFeatureMap, b)
return tf.nn.relu(tf.reshape(out, mergeFeatureMap.get_shape().as_list()), name = scope.name)
#搭建AlexNet网络
class AlexNet(object):
def __init__(self, x, keepPro, classNum, skip, modelPath = "/home/Ada/"):
self.X = x
self.KEEPPRO = keepPro
self.CLASSnum = classNum
self.SKIP = skip
self.MODELPATH = modelPath
self.buildCNN()
def buildCNN(self):
conv1 = convLayer(self.X, 11, 11, 4, 4, 96, "conv1", "VALID" )
lrn1 = LRN(conv1, 2, 2e-05, 0.75, "norm1")
pool1 = maxPoolLayer(lrn1, 3, 3, 2, 2, "pool1", "VALID")
conv2 = convLayer(pool1, 5, 5, 1, 1, 256, "conv2", groups = 2)
lrn2 = LRN(conv2, 2, 2e-05, 0.75, "lrn2")
pool2 = maxPoolLayer(lrn2, 3, 3, 2, 2, "pool2", "VALID")
conv3 = convLayer(pool2, 3, 3, 1, 1, 384, "conv3")
conv4 = convLayer(conv3, 3, 3, 1, 1, 384, "conv4", groups = 2)
conv5 = convLayer(conv4, 3, 3, 1, 1, 256, "conv5", groups = 2)
pool5 = maxPoolLayer(conv5, 3, 3, 2, 2, "pool5", "VALID")
fcIn = tf.reshape(pool5, [-1, 256 * 6 * 6])
fc1 = fullConnectLayer(fcIn, 256 * 6 * 6, 4096, True, "fc6")
dropout1 = dropout(fc1, self.KEEPPRO)
fc2 = fullConnectLayer(dropout1, 4096, 4096, True, "fc7")
dropout2 = dropout(fc2, self.KEEPPRO)
self.fc3 = fullConnectLayer(dropout2, 4096, self.CLASSNUM, True, "fc8")
#载入模型
def loadModel(self, sess):
wDict = np.load(self.MODELPATH, encoding = "bytes").item() # 字典格式
#for layers in model
for name in wDict:
if name not in self.SKIP:
with tf.variable_scope(name, reuse = True):
for p in wDict[name]:
if len(p.shape) == 1:
#bias
sess.run(tf.get_variable('b', trainable = False).assign(p))
else:
#weights
sess.run(tf.get_variable('w', trainable = False).assign(p))
4. C++实现代码##
待填
参考文献:
1.https://github.com/hjptriplebee/AlexNet_with_tensorflow
2.https://github.com/kratzert/finetune_alexnet_with_tensorflow