R语言包学习之tidyr包:数据结构重构
↓↓↓欢迎关注我的公众号,在这里有数据相关技术经验的优质原创文章↓↓↓

tidyr包
tidyr包主要涉及的功能和函数有:
1)缺失值的简单补齐
2)长表变宽表与宽表变长表
gather-把宽度较大的数据转换成一个更长的形式,即宽表变长表
spread-把长的数据转换成一个更宽的形式,即长表变宽表
3)列分割与列合并
separate-将一列按分隔符分割为多列
unite-将多列按指定分隔符合并为一列
tidyr包最主要的功能就是长表和宽表之间的转化,类似于Excel中的数据透视表,因此也有人将长表和宽表之间的转化称为透视和逆透视。其转化过程如下图所示:
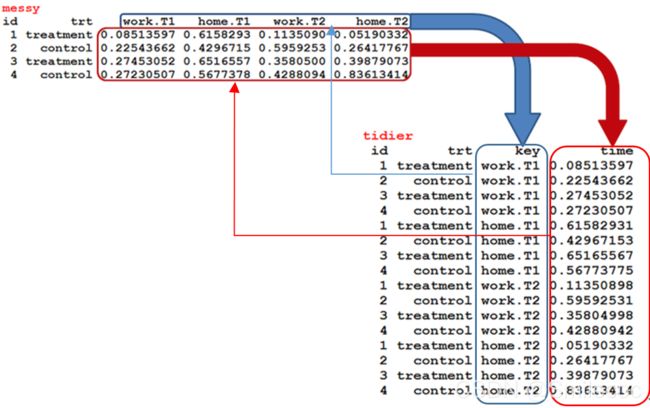
这个时候有人可能会问:好好的为什么要做长表和宽表之间的转化呢?试想一下上图中宽表的蓝色部分表头为对应时间段:
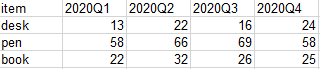
而如果我们需要一直使用这个数据集,那么随着时间的推移其表头也会随之变化,这时候我们就需要修改对应的代码,非常的麻烦。而改成对应的长表后我们只需要对长表透视一下即可得到宽表的数据,对应代码不需要变化,是不是方便很多?
安装并导入tidyr包
install.packages("tidyr")
library(tidyr)
缺失值的简单补齐
replace_na()函数
replace_na函数语法可以替换数据中的缺失值。
#创建一个带缺失值的数据集
df <- data.frame(x = c(1,2,7,NA,NA,10,22,NA,15),
y = c('a',NA,'b',NA,'b','a','a','b','a'))
#计算x的均值和y列的众数,并使用这两个值替换缺失值(当然也可以选择最大值,中位数等等填充缺失值,视情况而定)
x_mean <- mean(df$x, na.rm = TRUE)
y_mode <- as.character(df$y[which.max(table(df$y))])
#替换缺失值
df2 <- replace_na(data = df, replace = list(x = x_mean, y = y_mode))
补充部分: 缺失值的识别
处理缺失值的一般步骤为:识别缺失值–缺失数据的原因–删除缺失值或用合理的值代替缺失值。
对缺失值识别时可以使用is.na()、is.nan()、和is.infinite()函数来鉴别数据集中是否存在缺失,但是这些函数返回的是所有向量或数据框中每一个元素是否为缺失值,数据量非常大的话就不太好用。另外一种方法就是使用mice包中的md.pattern()函数来发现数据集中缺失值的模式。但该方法只能识别R中的NA和NaN为缺失值,而不能将-Inf和Inf视为缺失值,处理的办法可以用NA替代这些值。
> library(mice)
> md.pattern(df)
y x
5 1 1 0
2 1 0 1
1 0 1 1
1 0 0 2
2 3 5
函数返回了数据集中缺失值的情况,其中x和y列下的数字表示列中是否存在缺失值,0表示列中存在缺失值,1表示列中不存在缺失值。对应第一列的数字表示对应后面缺失情况的数量,最后一列表示有缺失值的变量个数。最后一行是每个变量缺失值的个数。
那我们上述的结果来说,第一行中x,y列对应的值都是1,表示这是x,y列都没有缺失值的情况,整个数据集中有5行数据都没有缺失值,对应第一列数据为5.同时由于x,y都没有缺失值,所以有缺失值的变量个数为0.之后几行也是一样的,然后到最后一行,y列的2表示对于y这一个变量总共有2个Na值,X总共有3个NA值,最后一列表示整个数据集中总共有5个缺失值。
同时我们也可通过VIM包中的aggr()函数可视化数据缺失情况:
library(VIM)
aggr(df, prop = FALSE, numbers = TRUE)

长宽表的相互转换
gather()函数
gather()函数是将宽数据转换为长数据,函数语法和参数如下:
> gather(data=,key=,value=,...,na.rm=,convert=,factor_key=)
# key:创建一个新的列名,这一列的值是转化前数据的列名
# value:再创建一个新的列名,原数据的所有旧列名的对应值成为新列名的值
# ...:按照实际需要自行指定需要转换的列
# na.rm:逻辑值,是否删除缺失值
# convert:逻辑值,在key列是否进行数据类型转换
# factor_key:逻辑值,若是F,则key自动转换为字符串,反之则是因子(原始lever水平保持不变)
使用实例:
#测试数据我们选用R内置的Iris数据集
head(iris,3)
#将iris中的所有列转化为长表(如果数据类型不一致的话可能会自动删除一些列)
gather(iris,key=var1,value = var2,na.rm = F)
#将iris中的Petal.Length和Petal.Width列转化为长表
gather(iris,key=var1,value = var2,Petal.Length,Petal.Width,na.rm = F)
#将iris中的第一列到第四列转化为长表
gather(iris,key=var1,value = var2,1:4,na.rm = F)
spread()函数
spread()函数将长数据转为宽数据,即将列展开为行,语法如下:
spread(data, key, value, fill = NA, convert = FALSE, drop = TRUE)
data:为需要转换的长形表
key:需要将变量值拓展为字段的变量
value:需要分散的值
fill:对于缺失值,可对fill赋值替换缺失值
convert:用于转化数据类型
使用实例:
创建一个测试的数据集
df = data.frame(name=c("A","A","B","B"),
group=c("g1","g2","g1","g2"),
V1=c(10,40,20,30),
V2=c(6,3,1,7))
#根据对应的V1,v2列转化为宽表
gather(df, Var1, Val2, V1:V2)
列分割与列合并
unite()函数
unite()函数是将数据框中多列合并为一列,调用公式如下:
> unite(data, col, ..., sep = "_", remove = TRUE, na.rm = FALSE)
#data:使用的数据集
# col:指定组合为新列的名字
# ...:指定数据中哪些列组合在一起,支持tidy selection选择
# sep:组合后新列中数据之间的分隔符
# remove:逻辑值,是否保留参与组合的列
#na.rm:是否删除空白
使用实例:
#将df数据集中的name和group连在一起
unite(df,add_col,name,group)
unite(df,add_col,1:2)
unite(df,add_col,c(name,group))
#将所有以V开头的列合并
unite(df,add_col,starts_with("V"))
#以_为分隔符合并前两列,并以:合并后两列
df %>%
unite(add_col,c(name,group),sep='_') %>%
unite(all_unite,c(add_col,V1,V2),sep=':')
separate()函数
separate()函数的作用正好和unite()函数相反,即将数据框中的某列按照分隔符拆分为多列,其语法如下:
> separate(data,col,into,sep,remove = TRUE,extra = "warn",fill = "warn",...)
# data:使用的数据集
# col:待拆分列
# into:定义拆分后新的列名
# sep:分隔符
# remove:逻辑值,如果为True的话删除拆分后的列
#构建一个测试的数据集
test = data.frame(name=c("Tom_MR","Carter_Tomp","Sandy_Yu","Bob_Smith"),
group=c("g1","g2","g1","g2"),
V1=c(10,40,20,30),
V2=c(6,3,1,7))
#保留原始数据中拆分前的列
separate(test,name,c("frist_name","last_name"),sep="_",remove = FALSE)
#不保留原始数据中拆分前的列
separate(test,name,c("frist_name","last_name"),sep="_")
tidyr包在R语言中也经常和dplyr包一起使用进行数据清洗,dplyr包的使用可以查看:http://smilecoc.vip/2021/08/23/R_dplyr/
参考文章:
https://rpubs.com/bradleyboehmke/data_wrangling
https://zhuanlan.zhihu.com/p/22265154
https://www.cnblogs.com/nxld/p/6060533.html