使用canal同步MySQL数据到Elasticsearch(ES)
目录
- 1、功能及使用场景
-
- 1.1、功能介绍
- 1.2、使用场景
- 2、需求引入
- 3、canal文件下载及准备
-
- 3.1 下载文件
- 3.2 准备文件
- 4、deployer安装及效果测试
-
- 4.1、deployer 配置修改
-
- 4.1.1 准备
- 4.1.2 修改连接数据库信息
- 4.2 启动deployer
- 4.3 测试deployer效果
-
- 4.3.1 在本地电脑新建普通maven工程
- 4.3.2 新建ClientSimple类
- 5、adapter安装及效果测试
-
- 5.1 修改配置
-
- 5.1.1 修改启动器配置: application.yml
- 5.1.2 修改 conf/es/mytest_user.yml文件
- 5.2 启动adapter
- 5.3 效果测试
- 6、全量数据导入
1、功能及使用场景
1.1、功能介绍
canal是阿里巴巴开源的mysql数据传输组件,基于mysql binlog,提供了准确、实时的数据传输服务。有关binlog介绍,参见binlog介绍。
以下来自官方GitHub介绍。GitHub地址

canal [kə’næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
基于日志增量订阅和消费的业务包括
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护(拆分异构索引、倒排索引等)
- 业务 cache 刷新
- 带业务逻辑的增量数据处理
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
1.2、使用场景
根据官方文档,目标系统支持MySQL、kafka、elasticsearch、hbase、rocketMQ、pulsar等。
本文主要介绍MySQL同步到Elasticsearch的使用。
2、需求引入
整个过程用一个示例来介绍canal的安装使用。
存在如下两张表(一对多关系),用户信息表和用户权限表,需要将用户信息以及权限同步到es
user_info(用户信息表):
| id | name | role_id |
|---|---|---|
| 1 | 张三 | 1 |
| 2 | 李四 | 2 |
| 3 | 王大锤 | 2 |
role(权限表):
| role_id | role_name |
|---|---|
| 1 | 管理员 |
| 2 | 测试员 |
查询sql:
SELECT a.id AS _id, a.name, a.role_id, b.role_name
FROM
user_info a
LEFT JOIN role b
ON
b.role_id = a.role_id
查询结果:
| _id | name | role_id | role_name |
|---|---|---|---|
| 3 | 王大锤 | 2 | 测试员 |
| 1 | 张三 | 1 | 管理员 |
| 2 | 李四 | 1 | 管理员 |
对应的es索引结构:
{
"user_index": {
"mappings": {
"_doc": {
"properties": {
"name": {
"type": "text"
},
"role_id": {
"type": "long"
},
"role_name": {
"type": "text"
}
}
}
}
}
}
3、canal文件下载及准备
3.1 下载文件
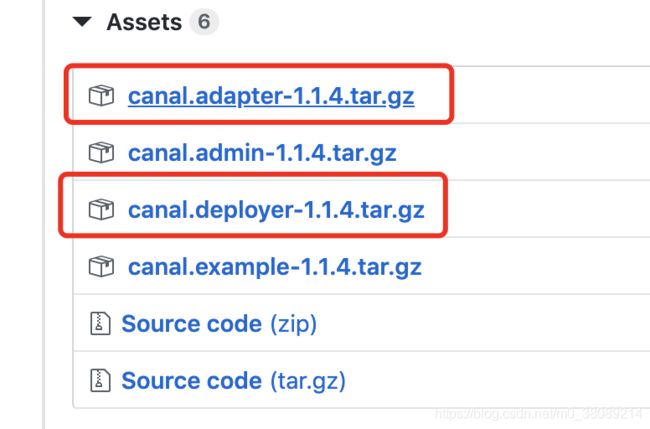
官方GitHub下载地址:https://github.com/alibaba/canal/releases
下载canal服务端(canal.deployer-1.1.4.tar.gz)和客户端(canal.adapter-1.1.4.tar.gz),如下图。
下载完成如下

3.2 准备文件

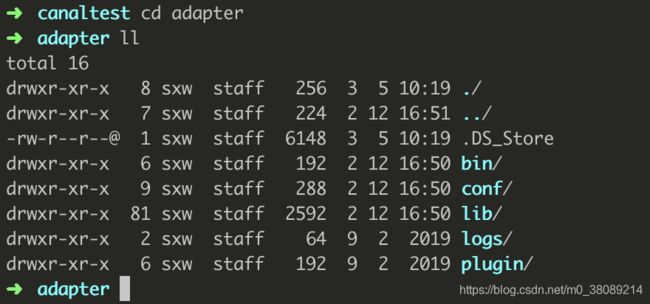
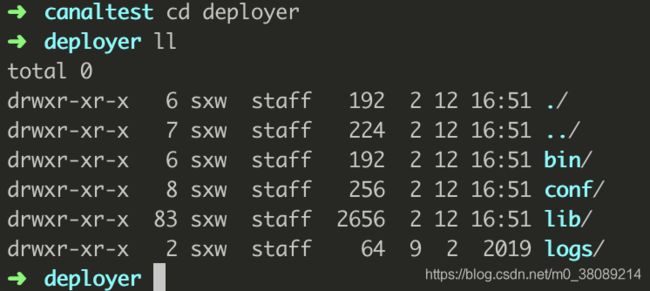
命令运行完成后,进入adapter和deployer可以看到如下结构(忽略我本机的.DS_Store)
adapter:
deployer:
4、deployer安装及效果测试
4.1、deployer 配置修改
4.1.1 准备
(针对阿里云 RDS for MySQL , 默认打开了 binlog , 并且账号默认具有 binlog dump 权限 , 不需要任何权限或者 binlog 设置,可以直接跳过这一步)
-
对于自建 MySQL , 需要先开启 Binlog 写入功能,配置 binlog-format 为 ROW 模式,my.cnf 中配置如下
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复 -
授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant,下面新建了canal账号
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
FLUSH PRIVILEGES;
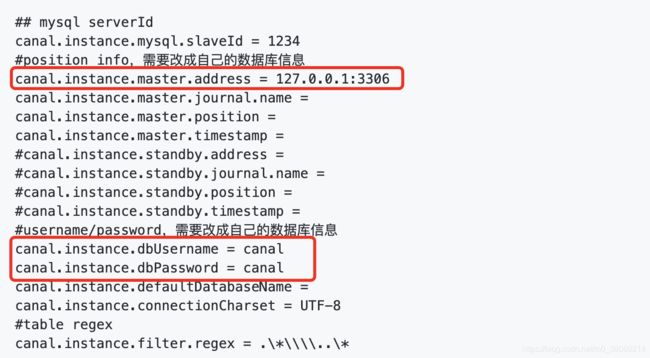
4.1.2 修改连接数据库信息
vi conf/example/instance.properties
修改如下标红信息
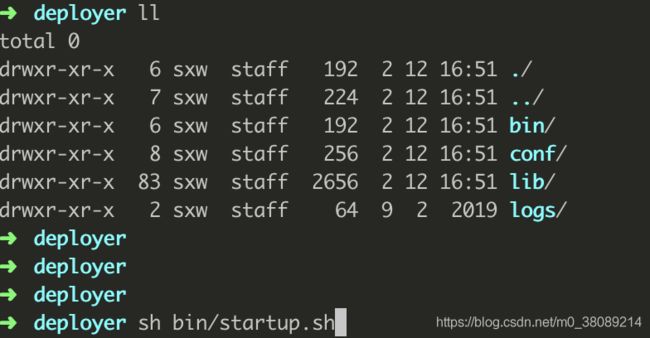
4.2 启动deployer
在deployer目录运行启动脚本
sh bin/startup.sh
- 查看 server 日志
tail -f logs/canal/canal.log

- 查看 instance 的日志
tail -f logs/example/example.log
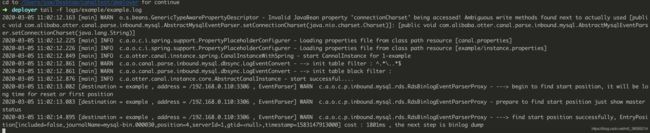
看到如上日志,标志启动成功
4.3 测试deployer效果
(4.3 步骤可跳过,主要为验证deployer端效果)
4.3.1 在本地电脑新建普通maven工程

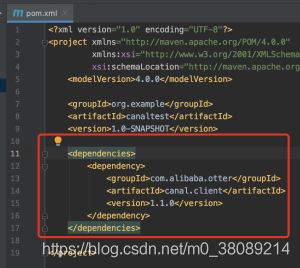
pom文件,依赖如下pom
<dependency>
<groupId>com.alibaba.ottergroupId>
<artifactId>canal.clientartifactId>
<version>1.1.0version>
dependency>
4.3.2 新建ClientSimple类
粘贴测试代码(下面链接页面上的ClientSimple代码)
https://github.com/alibaba/canal/wiki/ClientExample
将圈红ip改为部署adapter的ip,然后直接启动此main方法
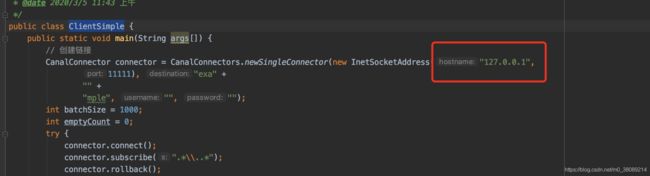
启动完成看到如下日志:
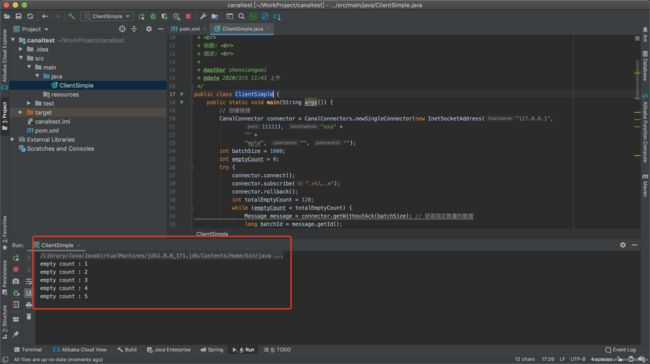
日志会循环打印count
此时触发数据库变更
user_info表变更前
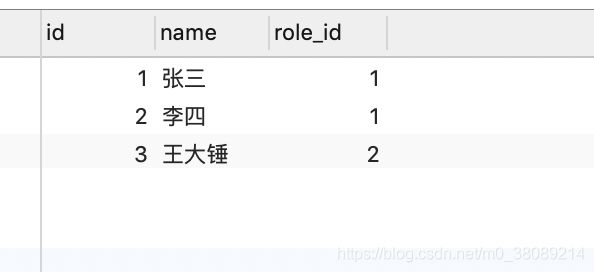
user_info表变更后,新加了一条名叫逻辑的记录

可在日志处观察到变更信息,标志着deployer监听mysql binlog变更成功

5、adapter安装及效果测试
canal adapter 的 Elastic Search 版本支持6.x.x以上
官方文档地址
https://github.com/alibaba/canal/wiki/Sync-ES
5.1 修改配置
5.1.1 修改启动器配置: application.yml
进adapter/conf目录
vi application.yml
修改如下配置,注意缩进格式,yml文件严格缩进格式,格式错误会引起启动失败问题。

mode使用rest模式,测试使用transport会出问题,目前没找到原因,下图mode还没更改
5.1.2 修改 conf/es/mytest_user.yml文件
adapter将会自动加载 conf/es 下的所有.yml结尾的配置文件
不需要的文件可删除,只配置需要的yml文件
修改如下配置,esMapping信息,包括 index,type,sql,其中sql尽量保证不要换行,在文本编辑器中编辑成一行,在粘贴进去,否则可能会出问题(还是由于yml格式问题)
此处的sql的字段别名即是es字段名,不写别名,默认原名即是es字段名,有关详细说明,可参见官方文档https://github.com/alibaba/canal/wiki/Sync-ES
etlCondition 可以注释掉,我们默认任何条件都同步

5.2 启动adapter
启动命令 sh bin/startup.sh
查看日志:
tail -f logs/adapter/adapter.log
观察如下日志,即表示启动成功

5.3 效果测试
canal是一个MySQL增量订阅组件,所以不支持数据的初始化
我们需要在数据库触发变更,才能将数据同步到es
变更前:
es数据->在kibana查询对应数据,可以看到右侧数据为空
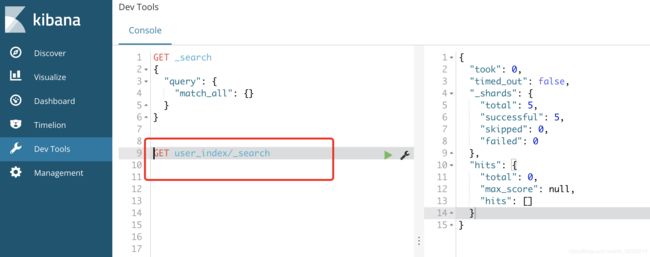
mysql数据→使用查询sql,查询到数据如下
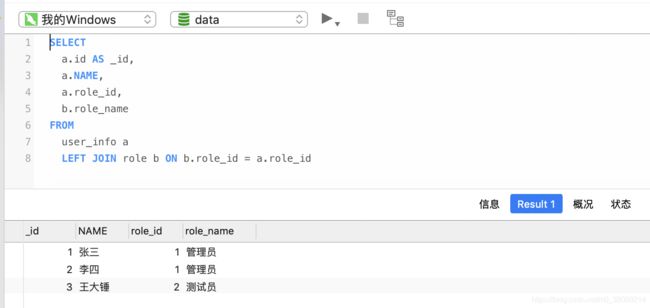
下面,我们进行数据变更:
比如将张三名字变成张六,MySQL数据如下:

此时,es数据在MySQL数据变更同时,es数据相应变更,如下,可以观察到,数据变更已经成功从MySQL同步到elasticsearch
需要注意的是,由于我们只变更了user_info表,所以此处只同步了user_info表的name和id字段,role_name字段,并没有同步,只有role_name字段变更时,才会被同步,所以实际使用时,要先做好数据初始化工作。

同时,可在logs/adapter/adapter.log观察到数据变更日志

至此,全部操作完成
6、全量数据导入
由于canal只支持增量导入,所以官方adapter提供了全量导入手动触发的功能,
canal全表同步(etl功能,手动触发)
参见源码:
/**
* ETL curl http://127.0.0.1:8081/etl/hbase/mytest_person2.yml -X POST
*
* @param type 类型 hbase, es
* @param task 任务名对应配置文件名 mytest_person2.yml
* @param params etl where条件参数, 为空全部导入
*/
@PostMapping("/etl/{type}/{task}")
public EtlResult etl(@PathVariable String type, @PathVariable String task,
@RequestParam(name = "params", required = false) String params) {
return etl(type, null, task, params);
}
只需要发送http命令即可
例:如下,ip和端口是部署canal adapter的IP和端口,然后类型选es,后面在跟上对应的yml配置文件即可
curl http://127.0.0.1:8081/etl/es/mytest_person2.yml -X POST
导入成功提示
![]()