深度学习中的网络总结
CNN的经典结构始于 1998 年的 LeNet,成于 2012 年历史性的 AlexNet,从此大盛于图像相关领域,主要包括:
- LeNet,1998年
- AlexNet,2012年
- ZF-net,2013年
- GoogleNet,2014年
- VGG,2014年
- ResNet,2015年
文章目录
- 分类网络
-
- 1.1 LeNet
- 1.2 AlexNet
- 1.3 ZF-Net(Zeiler&Fergus Net)
- 1.4 GoogLeNet
- 1.5 VGGNet
- 1.6 ResNet
分类网络
1.1 LeNet
出自论文《Gradient-Based Learning Applied to Document Recognition》 LeCun et al,IEEE 1998.
论文地址: LeNet
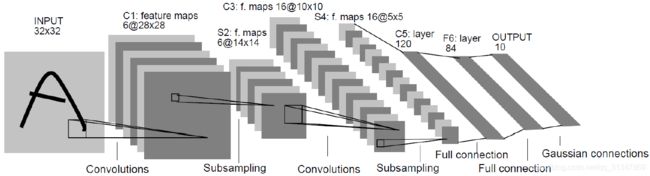
该网络是一种用于手写字体字符识别的非常高效的卷积神经网络。
输入尺寸: 32 * 32
卷积层: 2 个
池化层(下采样): 2 个
全连接层: 2 个
输出: 10 个类别(数字 0-9 的概率)
亮点: Yann LeCun 将卷积操作引入神经网络
1.2 AlexNet
出自论文《ImageNet Classification with Deep Convolutional Neural Networks》Krizhevsky A, Sutskever I et al, NIPS 2012.
论文地址: AlexNet
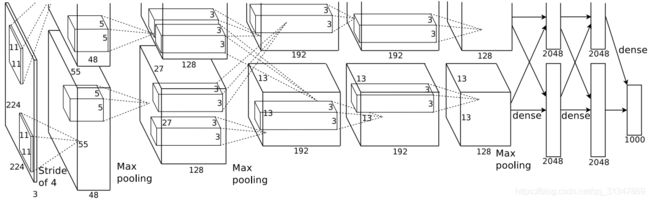
该网络由 Alex Krizhevsky 于 2012 年提出,取得 2012 年 ILSVRC 比赛冠军,top5 预测错误率为 16.4%,远超第二名。
网络层数:8 层
5 层 Conv + Pool
全连接层:3 个
1 层 softmax
有 6000 万个参数和 65 万个神经元
注意:在网络结构中输入虽然给出的是 224 * 224,但是在实际操作中,由于 224 无法被整除,所以采用了 227 * 227。
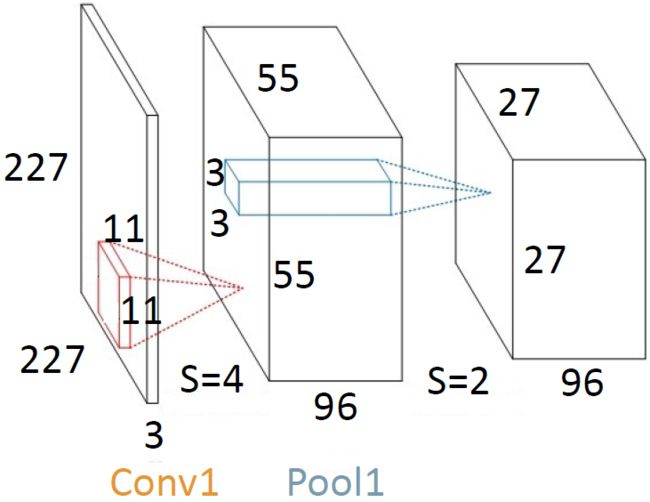
Conv1:输入大小为 227 * 227,卷积核(kernel size)大小为 11 * 11,步长(stride)为 4,卷积核个数为 96,经过计算知,输出大小为 55 * 55,第三维 = 卷积核个数 = 96。
o u t p u t = 227 − 11 + 2 ∗ 0 4 + 1 = 55 output = \frac{227-11+2*0}{4}+1=55 output=4227−11+2∗0+1=55
Pool1:下采样操作和卷积类似,只是第三维不发生变化。Pooling unit 大小为 3 * 3,步长(stride)为 2,经过计算只,输出大小为 27 * 27,第三维不变。
1.3 ZF-Net(Zeiler&Fergus Net)
出自论文《Visualizing and Understanding Convolutional Networks》Zeiler M,Fergus R,ECCV 2014.
论文地址:ZF-Net
亮点: ZFNet 是在 AlexNet 的基础上进行了一些细节上的变动,网络结构没有太大突破。ZF-Net 最大的贡献在于通过使用可视化技术揭示了卷积神经网络各层到底在干什么,起到了什么作用。
top5 错误率为 11.2%,取得 2013 年 ILSVRC 冠军
使用 RuLU 激活函数,交叉熵代价函数
使用较小的 filter 以保留更多原始像素信息
1.4 GoogLeNet
出自论文《Going Deeper with Convolutions》,2014
论文地址:GoogLeNet
亮点: GoogLeNet 也叫 Inception,提出构建一种稀疏性、高计算性能的网络结构
GoogLeNet 如何进一步提升性能?
之前的网络如 AlexNet、VGG 都是通过增大网络深度来获得更好的训练效果,但是深度的增加也会带来负作用,如 overfitting、梯度消失、梯度爆炸、计算复杂度过大等问题,所以 Google 提出了 Inception 网络结构。
1 * 1 卷积核的作用:减少运算量
1.5 VGGNet
卷积层:5 组
池化层:5 个
全连接层:3 个
出自论文《Very Deep Convolutional Networks for Large-Scale Image Recognition》Simonyan K et al, ICLR 2015
论文地址:VGGNet
VGG 是 Visual Geometry Group(牛津大学计算机视觉组) 的缩写,VGGNet 是 VGG 组和 Google DeepMind 公司一起研发出的深度卷积神经网络,它比较出名的是 VGG-16 和 VGG-19。
VGG 网络结构:VGGNet 可以看作是加深版本的 AlexNet,都是由卷积层、全连接层两大部分构成。
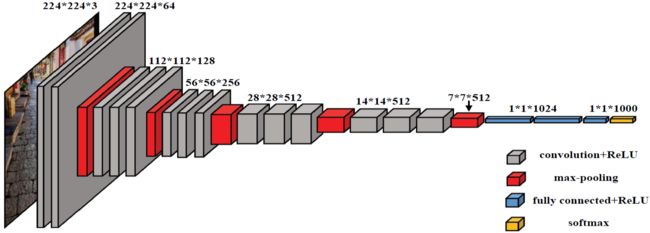
VGGNet 探索了卷积神经网络的深度与其性能之间的关系,通过反复堆叠 3 * 3 的小型卷积核和 2 * 2 的最大池化层,成功构筑了 16 ~ 19 层的卷积神经网络,证明了增加网络的深度能够在一定程度上影响网络最终的性能,可以使错误率大幅下降,同时拓展性又很强。
- VGGNet 全部使用 3 * 3 的卷积核和 2 * 2 的池化核,不断加深网络结构来提升性能。这里网络层数的增长并不会带来参数量上的爆炸,因为参数量主要集中在最后 3 个全连接层中
- 用多个小卷积的堆叠来代替单个大卷积。比如说两个 3 * 3 卷积层的串联相当于 1 个 5 * 5 的卷积层,3 个 3 * 3 的卷积层串联相当于 1 个 7 * 7 的卷积层,即 3 个 3 * 3 卷积层的感受野大小相当于 1 个 7 * 7 的卷积层,但是 3 个 3 * 3 的卷积层参数量只有 7 * 7 的一半左右,同时前者可以有 3 个非线性操作,而后者只有 1 个非线性操作,这样使得前者对于特征的学习能力更强。
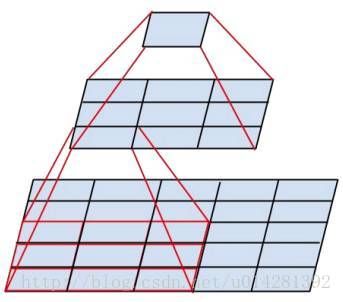
VGG 网络深度从 11 ~ 19 层不等,共有 6 种不同的网络结构,但是每种结构都将网络分成了 5 组卷积,每组卷积都将多个采用 3 * 3 卷积核的卷积层串联在一起,每组卷积后面接一个 2 * 2 的最大池化层,最后是 3 个全连接层和 1 个 softmax 层。
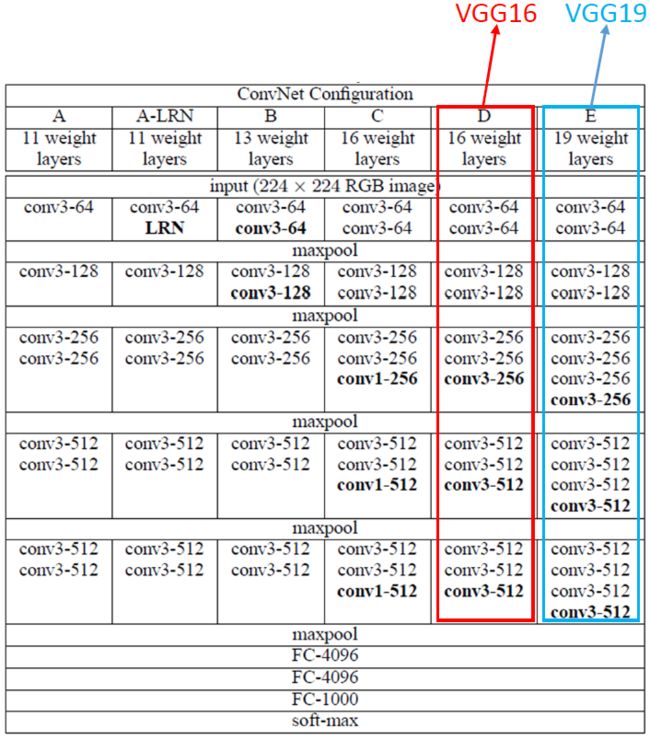
VGG 网络配置:
VGG-16 网络结构:
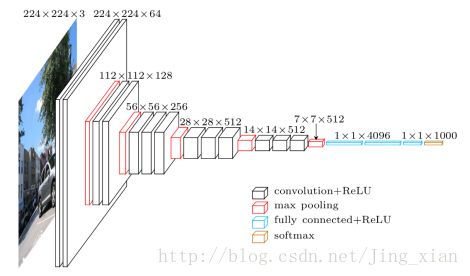
从上面两幅网络结构图可以看出:
- 特征图的空间分辨率单调递减;
- 特征图的 channel 数单调递增,而且是在每个 max pooling 之后 channel 数进行翻倍,直至512;
另外从论文中还可以得到一些补充网络信息:
- train input:224 * 224;kernel:3 * 3;kernel stride:1;padding:保持空间分辨率;max pooling:2 * 2 & stride = 2;
- conv 后接 3 个 FC 层,前两个 FC 有 4096 个 channel,第三个 FC 有 1000 个 channel(因为 ImageNet 有 1000 个类),最后一层为 softmax;
- 配置 C 和 配置 D 网络深度相同,区别在于 C 包含 3 个 1*1 的卷积,D 全部都是 3 * 3 的卷积,而且 D 比 C 的效果要好(原因后面补充);
- C 网络增加 1 * 1 的卷积核,主要作用是对像素进行线性变换,而不改变输出大小;
VGG网络结构如此设置的原因:
为了使输入图像在维度上流畅地转换到输出的分类向量
因为输入图像的维度是 H * W * 3(彩色图像)或 H * W * 1(灰度图像),而最后全连接层的输出是一个 1 * 1 * C 的向量,其中 C 为类别数。那么想要从输入维度转换到输出维度,就需要 VGG 的这种网络结构特点。
VGGNet优点:
-
结构简洁
VGG = 5 组卷积 + 3 层全连接 + 1 层 softmax
每组卷积之间使用 max pooling 分隔
所有隐层的激活单元都采用 ReLU -
网络表达能力强
VGG 使用多个小卷积核的卷积层代替一个较大卷积核的卷积层,一方面减少了参数,另一方面相当于进行了多次非线性映射,增强了网络的拟合表达能力
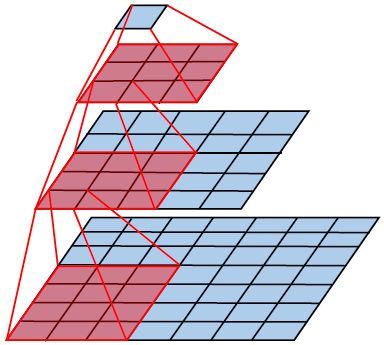
Q:既然要用小卷积核,为什么不直接采用 1 * 1 的?
A: 1 * 1 的卷积核其实也是有效的,但是没有 3 * 3 的卷积效果好,因为 3 * 3 的卷积可以学习到更大的空间特征。
Q:为什么预处理要对每个像素减去在训练集上计算出的RGB均值?
A: 深度学习中图像预处理为什么要减去均值?
Q:为什么要用小卷积的堆叠来代替单个大卷积?
A: 1)增加决策函数的判别性:每个 conv 后都有非线性修正,小卷积的堆叠可以使用多个非线性修正;2)可以减少参数量。
Q:为什么 VGGNet 网络深、参数多,却比其他网络收敛地更快?
A: 1)更大的深度和更小的卷积核所引起的隐式正则化;2)某些层的预初始化。简单说就是卷积核扩大通道数,池化缩小了宽和高,使得模型更深更宽的同时,控制了计算量的增加规模。
Q:为什么 VGG 要一直翻倍通道数?
A: 通道数越多,就能够提取更多的信息,分类效果也就越好。
训练技巧:VGGNet 在训练时先训练 A 网络,再用 A 网络的权重来初始化后面的模型,这样收敛速度更快。
1.6 ResNet
亮点:解决深度增加出现的梯度消失问题。残差网络和简单网络相比没有额外的参数,但却降低了误差。
为解决更深的网络的退化问题,提出了深度残差网络 ResNet。ResNet 有两种 mapping:identity mapping 和 residual mapping。
最后的输出是 H ( x ) = F ( x ) + x H(x) = F(x) + x H(x)=F(x)+x
- identity mapping:x
- residual mapping:H(x) - x,即残差部分 F(x)