【强化学习纲要】6 策略优化进阶
【强化学习纲要】6 策略优化进阶
-
- 6.1 policy gradient的变种
- 6.2 First lines of works on SOTA policy optimization
-
- 6.2.1 Policy Gradient
- 6.2.2 Natural policy gradient/TRPO
- 6.2.3 ACKTR
- 6.2.4 PPO
- 6.3 Second lines of works on SOTA policy optimization
-
- 6.3.1 DDPG
- 6.3.2 TD3
- 6.3.3 SAC
周博磊《强化学习纲要》
学习笔记
课程资料参见: https://github.com/zhoubolei/introRL.
教材:Sutton and Barton
《 Reinforcement Learning: An Introduction》
6.1 policy gradient的变种
Value-based RL versus Policy-based RL
- 在价值函数优化里面主要有deterministic policy。
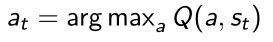
当学习了Q table后,会直接取argmax对应的动作,采取行为。 - 但是在策略优化中,有机会得到stochastic policy(随机策略) output。从这个策略函数输出,会得到一个概率,从给出的概率里面采样就可以得出需要采取的行为。
- 对于策略函数优化,优化的objective function定义如下:

通过让策略函数与环境进行交互,产生了轨迹 τ \tau τ,reward function会输出它会得到多少奖励。我们希望这条轨迹尽可能多的得到奖励。 - policy gradient(REINFORCE)算法:
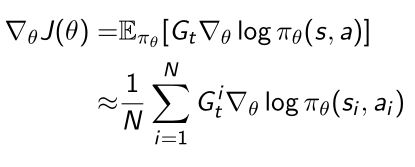
计算 J ( θ ) J(\theta) J(θ)的梯度,得到policy gradient,由return和策略函数的score function组合起来的,然后用MC近似的方法产生很多轨迹,产生很多score function的likelihood,从而近似实际的gradient,用这个gradient可以优化策略函数的参数 θ \theta θ - 然后我们希望进一步改进policy gradient的variance,使得variance尽可能小,使得策略优化的训练更稳定。
- 定义了函数advantage function:

由两部分组成,一部分是Q function,另一部分是对应的baseline,因为 V π ( s ) V^{\pi}(s) Vπ(s)是Q函数动作的平均,因此可以作为Q天然的baseline。 - 把policy gradient改进成advantage actor-critic

score function ✖ advantage function - advantage actor-critic是后面最新强化学习的基础。算advantage function的时候,是由两个方程组成的,因为如果状态很多的话,我们只能用近似的方法。所以对于Q函数,我们只能用近似函数,对于价值函数V我们也需要一个近似函数。
- 所以我们需要两组参数,对于价值函数的近似函数我们需要有一组 v v v;

- 对于Q函数我们需要有 w w w这个参数来拟合

- 所以我们同时优化这两种参数,使用TD的算法或者MC的方法。
Advantage actor-critic
- 但是我们可以进一步改写,对于Q函数我们可以用另一种形式来写——bootstrapping TD target的方法(由两部分组成,实际得到的reward,和他做bootstrapping得到下一个状态的价值)。于是我们可以写成TD error δ π θ \delta^{\pi\theta} δπθ的形式

- 对 δ π θ \delta^{\pi\theta} δπθ进行简单的变换,就又可以进行反算得到advantage function,所以这两者是近似的关系,是它的估计。

- 所以我们可以把policy gradient的TD error重写:
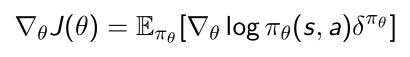
- 这样重写的好处是我们只需要取拟合它的价值函数就可以。

比如我们这里只需要拟合价值函数 V V V,它的函数的参数是 κ \kappa κ,这样就只用去估计一组critic的参数,就省了很多参数的估计,这样就可以使得价值函数的训练更稳定。
Critic at different Time-Scales
- 对于这个参数不同的优化办法也会得到不同的update, V κ ( s ) = ψ ( s ) T κ V_{\kappa}(s)={\psi(s)}^T\kappa Vκ(s)=ψ(s)Tκ。价值价值函数approximator(线性的拟合函数)当状态涉及特征 ψ ( s ) \psi(s) ψ(s),再乘以 κ \kappa κ( κ \kappa κ的意义是对状态的特征进行线性的组合),这样就可以回归它的价值函数。
- 如果选取的更新方式是基于MC的更新方式:
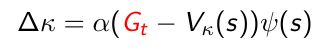
TD error就会变成实际得到的return G t G_t Gt,再去减去价值函数作为 κ \kappa κ去优化 - 如果选取更新的优化方式是TD(0)的方法:
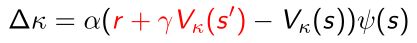
可以直接带入TD target减去价值函数。 - 我们甚至可以用多步的return:

比如走三步再bootstrapping价值函数,然后可以把公式中红色部分作为critic函数的参数估计。 - 不同的函数参数估计方法会得到不同的critic parameter。
Actors at Different Time-Scales
- 同样对于actor 策略函数,我们算策略函数的gradient J ( θ ) J(\theta) J(θ),同样对于不同的方法可以得到不同的policy gradient。

- 用蒙特卡洛的方法去算MC actor-critic对于actor policy 的gradient:

将 G t − V κ ( s t ) G_t-V_{\kappa}(s_t) Gt−Vκ(st)作为更新乘以score function。 - 如果我们优化方法选取的TD方法:

- 如果优化方法选取k-step return:

让(k-step走到k步的return,再去bootstrapping对应的价值函数,再减去现有状态的价值函数)作为估计。
Policy gradient算法总结
- 基于不同的policy gradient方法可以得到不同的policy gradient:
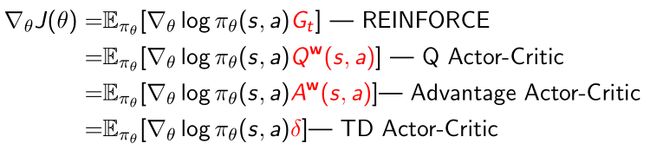
- 如果采取的纯粹MC的方法,即通过采取轨迹后,把轨迹每个点的score function(likelihood)计算下来,算每个点的return。这样就会得到 G t G_t Gt作为它的量,乘以score function,这样就会得到REINFORCE;
- 这里采取的reward是用Q函数作为reward,Q函数和 G t G_t Gt有一个对应关系, G t G_t Gt相当于是Q函数的一个采样,于是可以得到对于Q函数的actor-critic;
- 如果进一步减去baseline,用价值函数作为baseline,就可以推导出advantage actor- critic算法;
- 如果进一步采取简化的办法,用TD target作为reward function,就会变成TD actor-critic。
- 所以有如上几种actor-critic的方法,基于最后得到的奖励函数的不同,可以用不同的优化方法去优化。
- 对应的critic,对应了policy evaluation(选取MC或者TD learning的优化方法)会去不同估计它们的参数。‘
The State of the Art RL Methods
两条主线介绍策略优化的方法:
- Policy Gradient → Natural Policy Gradient/TRPO → ACKTR → PPO
- Q-learning → DDPG → TD3 → SAC
- Policy Gradient→Natural PG/TRPO→ACKTR→PPO
- TRPO: Trust region policy optimization. Schulman, L., Moritz, Jordan, Abbeel. 2015
- ACKTR: Scalable trust-region method for deep reinforcement learning using Kronecker-factored approximation. Y. Wu, E. Mansimov, S. Liao, R. Grosse, and J. Ba. 2017
- PPO: Proximal policy optimization algorithms. Schulman, Wolski, Dhariwal, Radford, Klimov. 2017
- Q-learning→DDPG→TD3→SAC
- DDPG: Deterministic Policy Gradient Algorithms, Silver et al. 2014
- TD3: Addressing Function Approximation Error in Actor-Critic Methods, Fujimoto et al. 2018
- SAC: Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor, Haarnoja et al. 2018
6.2 First lines of works on SOTA policy optimization
6.2.1 Policy Gradient
Problems with Policy Gradient
- 第一个问题:Policy Gradient的sample efficiency非常低。
- sample efficiency意思是我们需要去采取的样本,即我们需要让正在优化的策略和环境进行交互,这个交互的过程称为sample collection/data collection,这个交互的过程多少就决定了sample efficiency的多少。因为policy gradient是一种on-policy learning,即只有一种policy,优化的policy和采集数据的policy是同一个policy。
- sample efficiency意思是我们需要去采取的样本,即我们需要让正在优化的策略和环境进行交互,这个交互的过程称为sample collection/data collection,这个交互的过程多少就决定了sample efficiency的多少。因为policy gradient是一种on-policy learning,即只有一种policy,优化的policy和采集数据的policy是同一个policy。
- 第二个问题:训练过程非常不稳定。
- 只要policy update出了一些错误,或者step-size有一些问题,就会使训练的过程变得很不稳定,以至于导致训练过程崩溃。这和强监督学习,标记图片训练分类器是很不一样的。因为对于强监督学习方法,样本之间关联是非常低的,我们给的假设都是iid的假设,样本之间并没有相关度。意思是假设这批样本质量很差也没关系,下一批好就行了,这样就导致就算样本里面有些噪声,但是整个训练是没有问题的。但是在强化学习里面这就不成立了,这个iid假设就不成立了。在强化学习里面,采集到的数据(和环境交互得到的数据)之间有很高的相关度,这就导致策略本身对采集到的数据影响非常大;
- 所以说如果某一步的更新程度(policy gradient),或者step-size不是这么对,这样就产生了很错误的policy gradient;然后用这个错误的policy gradient去更新我们当前的policy,就会得到很差的policy;用这个很差的policy又去和环境交互,又采集一些数据,就会得到很糟糕的一堆数据;用很糟糕的数据计算新一轮的policy gradient,又产生很差的gradient,这样形成一个错误的循环,整个训练过程变得越来越糟;这样就很难从一个错误的policy里面恢复,就导致整个训练过程就崩溃。
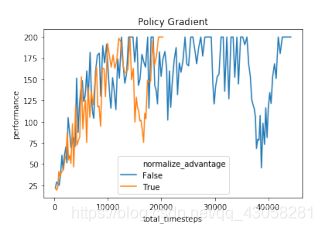
上图无论加不加normalization都会发现训练过程很不稳定;横轴是训练的时间,纵轴是当前策略的表现。这种不稳定性就是由于policy gradient的更新和data collection是耦合起来的。
所以我们在改进policy gradient的时候就希望能改进这两个policy gradient的问题。
- 改进的思路
- 对于第一点,我们希望把on-policy的进一步扩展成off-policy的。我们可以引入importance sampling(重要性采样)的方法,这也是在TRPO中使用了的。
- 对于第二点,我们希望整个训练变得更稳定。这里可以用到的方法就是在训练过程中引入Trust region(信赖域)的机制,也就是说它采取的gradient总是在一个安全的范围里面更新策略函数;另外也可以用natural policy gradient的办法,这是一个二阶的优化方式,我们直到SGD是一阶的近似,这样算出来的gradient其实并不准。
6.2.2 Natural policy gradient/TRPO
Natural Policy Gradient
- 我们之前算的policy gradient就直接对于policy function算它的优化。这里得到的gradient是在 参数空间(parameter space) 里面上升的最快的gradient,假设参数空间里面是一个欧几里得的量(Euclidean metric):

- 比如说在参数空间里面的增量 d d d, d d d是类似于欧几里得空间的一个球,现在需要找一个方向去优化这个 d d d使得整个公式极大化。这样我们找到这个 d d d是在参数空间里面steepest ascend(最陡上升)。
- 但是这里有一个问题就是:我们这样算出来的 d ∗ d^* d∗是对我们策略函数采取怎样的参数化形式比较敏感。如果policy function是用高斯的拟合函数或softmax的拟合都会对算出来的 d d d产生影响,这样就会导致当我们把 d d d加到参数上面后,这个价值函数的输出(一个概率)和参数更新并没有联系起来。
- 所以我们这里提出了另一种方法:我们想从steepest ascend in distribution space(policy output space) 考虑优化这个参数。
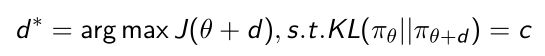
- output就是 π θ {\pi}_{\theta} πθ它实际的output,这里希望它实际的output和变化之前的output变化尽可能的小,在这个尽可能小的空间里面去优化 d d d,参数空间找到 d d d使得下一步更新出来的策略的输出(概率: π θ + d {\pi}_{\theta+d} πθ+d)尽可能的小。
- 我们这里衡量两个策略的近似距离用的KL-divergence(KL散度)。我们希望KL-divergence等于一个固定的比较小的数,我们把constraint(限制)加进去过后,整个优化过程算它的梯度的时候就可以使得 d d d让最后输出的空间能够变得尽量的连续,并且和curvature(曲率)没有关系。curvature在代数几何里面对于概率函数是如何参数化它有非常大的联系的。所以我们想使整个策略过程,和采取怎样的策略函数的参数形式没有关联。
KL-Divergence as Metric for Two Distributions
- KL散度(相对熵)是来衡量两个分布之间的相关度以及近似程度。
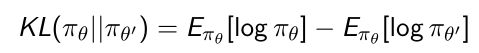
- 虽然KL散度并不是一个真实的度量,因为它不是不满足三角不等式的,并且它是非对称的。但是当 d d d足够小的时候,它也可以近似成一个对称的形式,所以当策略函数优化的neighborhood足够小的时候,KL可以当成一个度量,我们这里可以进一步进行一个简单的推导,把KL-divergence作为一个泰勒展开(Taylor expansion):
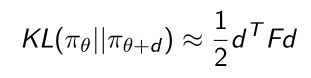
- 可以知道KL-divergence的一阶导数其实是0,这里保留的其实是它的二阶导数(泰勒展开对应的二阶数)。
- 这里的 F F F在概率里面叫做Fisher Information Matrix(费雪信息矩阵),关于KL散度的二阶导数。
- 虽然KL散度并不是一个真实的度量,因为它不是不满足三角不等式的,并且它是非对称的。但是当 d d d足够小的时候,它也可以近似成一个对称的形式,所以当策略函数优化的neighborhood足够小的时候,KL可以当成一个度量,我们这里可以进一步进行一个简单的推导,把KL-divergence作为一个泰勒展开(Taylor expansion):
- 所以现在面临一个优化问题,使得我们去优化 d d d使得满足条件: s . t . K L [ π θ ∣ ∣ π t h e t a + d ] = c s.t.KL[{\pi}_{\theta}||{\pi}_{theta+d}]=c s.t.KL[πθ∣∣πtheta+d]=c。即使得更新过后策略的输出与更新前的策略的差异度尽可能的小,小于或等于 c c c。所以我们可以把这两个优化条件整合起来:
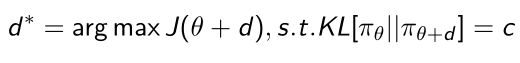
我们可以把它写成Lagrangian form(拉格朗日形式)

就可以让第一个条件再组合第二个条件,这里 λ \lambda λ是一个参数,使得在解这个优化问题的时候让两个问题都满足。
然后对优化的函数做泰勒展开,就会得到它是由四部分组成的:第一部分 a r g m a x argmax argmax和 d d d其实并没关系,第二部分是 J ( θ ) J(\theta) J(θ)函数的梯度乘以 d d d,第三部分是KL散度的拆开(一阶导数为0,只保留到二阶导数的形式),第四部分 λ c \lambda c λc。 - 然后我们再对这个展开的形式求导。因为第一部分和第四部分和 d d d没有关系,对第二、三部分做简单的部分,得到natural policy gradient:

由两部分组成:一部分是 F F F矩阵,Fisher Information Matrix(费雪信息矩阵),对它求逆;再乘以原来的policy gradient。 - 这样我们就得到了natural policy gradient的一个概念。这样我们就可以得到如下参数更新化的形式:
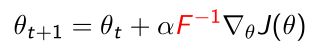
这个形式相对于最早的policy gradient就多了 F − 1 F^{-1} F−1 这一项。Fisher Information Matrix(费雪信息矩阵)是可以直接用score function算出来的,当我们采集到likelihood function后,算它的score function,再乘以它的transfer(转置)再把它加起来,这样就得到了fisheri information matrix。它就相当于second-order derivative of the KL-divergence。

这里 F F F有明确的几何定义:在测量相对于模型参数的曲率(curvature of the policy(distribution))。
除以 F F F就相当于我们用某一种参数化的策略函数形式,直接去除以它的curvature,就可以把curvature去掉,这样就使得整个参数优化形式和采取怎样的策略优化独立开了。 - 所以natural policy gradient的核心就在于让这个优化过程跟它的策略函数(采取怎样的优化形式)无关,这样可以使得整个优化过程变得更稳定,这样可以使得不管你采取怎样的策略函数参数化形式,策略函数的output(这个概率)都会尽可能小的变化。
- natural gradient的进一步理解: https://wiseodd.github.io/techblog/2018/03/14/natural-gradient/
缺点:必须计算Fisher Information Matrix。
Policy Gradient with Importance Sampling
- 另外一个方面是我们想把policy gradient方法改成off-policy的方法,我们知道off-policy learning自身有很多好处,我们可以用另一种算法在环境里面去探索(explore),采集到很多激进的数据,这样来喂给优化的策略。
- 这里采取方法是Importance sampling(重要性采样):Importance sampling在采样过程里面也是用的比较广泛的,它的简单概念是:我们现在假设要去估计一个函数的期望,比如说要估算 f ( x ) f(x) f(x)这个值, x x x是从 p p p分布里面采样出来的;有时候我们不知道怎么去 p p p分布里面采样,比如说 p p p分布的形式非常奇怪,没法去直接采样,我们只能从如uniform distribution或者Gaussian distribution里面采样,那么我们怎么去根据一个不知道怎么采样的 p p p估计这个 f ( x ) f(x) f(x)参数呢?

通过简单的变换, f ( x ) f(x) f(x)针对 p p p的期望,变换成另一种期望的形式,这样 x x x就可以从另外一个分布里面采样了。采样很多的 x x x后再取平均。 - Importance sampling和策略优化有什么联系呢?对于策略优化这个函数也可以做一个简单的变换:

比如说策略优化的objective function是 J ( θ ) = E α ~ π θ [ r ( s , a ) ] J(\theta) = E_{\alpha~\pi\theta}[r(s,a)] J(θ)=Eα~πθ[r(s,a)], α \alpha α是优化的策略里面产生的,假设我们现在优化函数没法对它采样,就可以从另外一个策略函数里面对它采样,比如从 π ^ \hat{\pi} π^里面去采样action,通过importance sampling去乘以ratio来近似。这里变化就是我们可以用behavior policy π ^ \hat{\pi} π^去产生实际的轨迹。
Increasing the Robustness(鲁棒性) with Trust Regions(信赖域)
- 所以这样就可以把策略函数改写成基于之前另外一个策略的一个优化函数,另外一个策略最简单的办法是可以用之前的这个策略,在Deep Q learning中有两个策略函数,behavior policy是用的之前的策略函数,因为之前的策略函数产生的数据我们也可以放到这个replay buffer里面,所以就可以重用之前采到的数据。
- 所以现在的代价函数 J θ o l d J_{{\theta}_{old}} Jθold包含了 θ o l d {\theta}_{old} θold, θ o l d {\theta}_{old} θold表示之前一些比较老的策略函数的参数,我们就可以用 θ o l d {\theta}_{old} θold与环境进行交互采集到的data,让用data来优化现在这个policy gradient,唯一需要做的就是乘以一个ratio,让奖励函数的优化无偏。

- 但是这里存在一个问题,这里的ratio π θ / π θ o l d {\pi}_{\theta}/{\pi}_{{\theta}_{old}} πθ/πθold有可能会非常大,如果 π θ o l d {\pi}_{{\theta}_{old}} πθold这个值如果非常小的话,ratio这个权重就会非常大,就会使得整个优化过程变得非常不稳定。
- 所以这里我们希望进一步引入一个constraint(限制)使得ratio尽可能的小,即更新后新一轮的policy和老的policy的变化尽可能的小。那么这里就面临一个问题,怎么衡量两个策略的相似度呢?
- 那么就可以引用前面提到的Kullbeck-Leiler(KL) divergence,KL散度就可以用来衡量两个策略之间的相似程度。
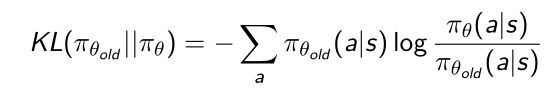
比如我们想衡量当前优化函数和之前策略函数之间的距离,就可以用KL散度的形式来度量。 - 这里就可以引入TRPO(Trust Regions Policy Optimization)的优化函数。
- 优化函数由两部分组成,第一部分是包含了importance sampling这样重写一下的代价函数:
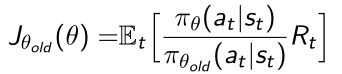
- 第二部分是加的一个优化过程中的限定,限定使得优化的 π θ {\pi}_{\theta} πθ和上一个 π θ o l d {\pi}_{{\theta}_{old}} πθold之间的距离尽可能的小。可以想象成一个球,空间内叫做trust region(信赖域)。
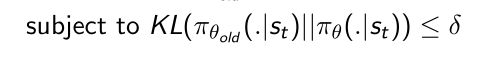

- 如上图,之前如果不加这个限制,直接用gradient ascent,使得一直往上走,但是存在的问题是有可能有一步的更新非常大或者step-size步数没有设定好,就很有可能冲出悬崖了,那整个优化过程就掉到悬崖里面去了,就再也不可以恢复出来;
- 所以我们加了这个限制的话,就类似于在每一步加了个圆圈,圆圈区域里面对应的就是trust region,每次优化过程只能在这个圆圈里面(安全的区域)选择一个方向,这样就可以使得这个训练尽可能的稳定,这样也使得它的概率输出和上一步的概率输出的步数尽可能的小,随着训练过程也可以使得trust region缩的越来越小,更新也会变得越来越小,整个过程也会变得越来越稳定。
- 优化函数由两部分组成,第一部分是包含了importance sampling这样重写一下的代价函数:
Trust Region Optimization
- 对Trust Region Optimization进行进一步的推导,对价值函数做泰勒展开,展开如下:

- 泰勒展开后,objective变为;
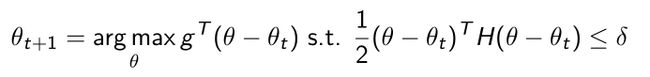
我们要优化下一步 θ t + 1 {\theta}_{t+1} θt+1,我们希望 θ t + 1 {\theta}_{t+1} θt+1满足两个条件:一是argmax(尽可能大);二是使得新出来的 θ \theta θ是满足限制式子(小于 δ \delta δ的。 - 我们解上式优化形式的时候,可以把quadratic equation(二次方程)写成Natural gradient(自然梯度)。
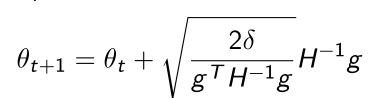
- 其中 H H H是Fisher Information Matrix(FIM)(费雪信息矩阵),前面用的 F F F表示:
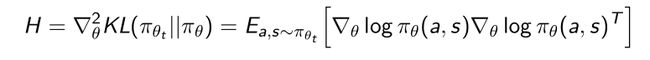
H H H是对应KL散度的二阶导数,可以通过score function的变换直接求出来。
- 其中 H H H是Fisher Information Matrix(FIM)(费雪信息矩阵),前面用的 F F F表示:
- 我们的更新形式 θ t + 1 {\theta}_{t+1} θt+1并没有 α \alpha α step size,这里用来控制step-size的是 δ \delta δ(learning rate)。

δ \delta δ是直接在限制更新之后的policy和之前的policy的近似程度 ,也就是说做了这个推导过后 δ \delta δ和learning rate直接联系起来了。这也是TRPO推导非常好的地方,不需要设定step-size,只需要指定trust region的大小,即更新后的策略和之前的策略输出距离多少,然后用距离去推出step-size。可以使得trust region设的很小,这样就使得更新非常稳定。 - δ \delta δ可以使得参数更新不会策略函数概率输出的程度,不会产生剧烈的变化。
- 所以TRPO是对natural policy gradient的更进一步的推导。

- Sham Kakade. “A Natural Policy Gradient.” NIPS 2001
- TRPO是在natural policy gradient的基础上加了importance sampling。
Trust Region Policy Optimization(TRPO)
- TRPO还提出了怎么近似计算FIM(费雪信息矩阵)。
- 我们计算Fisher Information Matrix的 H H H,就相当于natural policy gradient 要对这个矩阵求逆 x = H − 1 g x=H^{-1}g x=H−1g。当矩阵维度很大的时候,矩阵求逆的计算量(复杂度)非常大,所以TRPO就提出了不要矩阵求逆,而是转化成解线性方程的形式 H x = g Hx = g Hx=g,解 A x = b Ax=b Ax=b的形式。
- 因为

- 所以我们可以转换成quadratic equation去解:

- 因此我们现在要去优化这个quadratic equation(二次方程)

- 解这个的方法是conjugate gradient method(共轭梯度法),与gradient ascent非常像但是迭代次数更少。
- TRPO完整算法,可以当成natural policy gradient更进化的版本

算法中有用CG(conjugate gradient共轭梯度法)去解优化的过程;最终得到 θ \theta θ更新的形式,就可以用二阶的gradient去更新它的函数,这样就把trust region的限制加到了优化过程中,使得训练过程变得更稳定。
- Schulman, et al. ICML 2015: a lot of proofs
- 论文的附录中包含了两页的推导,证明guaranteed monotonic improvement(保证单调递增),在推导policy update在TRPO的每一步的优化都可以达到更好的policy。
- 证明了加入了constraint后
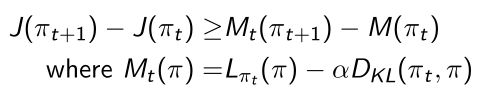
- 它每一步都可以变得更大了, J ( π t + 1 ) J({\pi}_{t+1}) J(πt+1)是大于 J ( π t ) J({\pi}_t) J(πt)的。
- 证明了加入了constraint后
- 所以当更新 M t M_t Mt的时候,优化过程就可以单调递增。
- 也可以当作一种Minorize-Maximization(MM)算法,MM算法是优化算法中的一个形式,更简单的一个形式是EM算法(Expectation-Maximization algorithm,最大期望算法)。EM算法是MM算法的一个特例。
- MM算法是在极大化surrogate function(替代函数)(蓝线),surrogate function大致意思是说对于原来的客观函数(红线)的近似。在没法直接解红线(客观函数)的优化的时候,那么直接解近似。
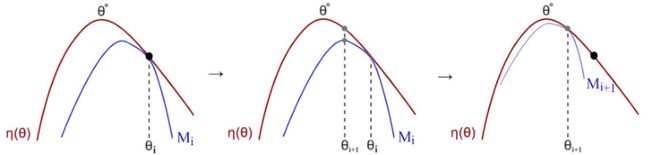
得到一个点后去更新,蓝线就会变化得到新的surrogate function(替代函数),通过不停的迭代最终找到 θ \theta θ这个点就是对应了红线(原始客观函数)极大值的点。
Result and Demo of TRPO

- Demo video is at
https://www.youtube.com/watch?v=KJ15iGGJFvQ
Limitation of TRPO
- 计算量非常大。虽然用了conjugate gradient method(共轭梯度法),但是对于每一步每个policy都要算 H H H。
- 在近似 H H H的时候, H H H本身是个期望,但是我们在近似这个期望的时候是用样本近似,需要很多样本。
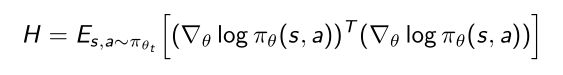
- conjugate gradient(CG)的优化本身也是一个复杂的过程。
- TRPO在有些领域没有DQN好

6.2.3 ACKTR
ACKTR: Calculating Natural Gradient with KFAC
- Y. Wu, et al. “Scalable trust-region method for deep reinforcement learning using Kronecker-factored approximation”. NIPS 2017.
- ACKTR的核心思想是想提升TRPO的计算效率。在TRPO里面有一步是算Fisher information matrix(FIM) H − 1 H^{-1} H−1,在矩阵维度很大的时候求逆计算量非常大。因此,ACKTR提出用Kronecker-factored approximation curvature(K-FAC) 方法来加速求逆。

Optimizing Neural Networks with Kronecker-factored Approximate Curvature
- 思想来自Martens et al.ICML’15:
https://arxiv.org/pdf/1503.05671.pdf - 在优化神经网络的时候,最常用的优化办法是SGD(Stochastic Gradient Descend,随机梯度下降),SGD是一阶优化方法,所以不是很准确;因此提出了用Natural Gradient Descend进一步优化它,Natural Gradient Descend涉及了二阶的优化,并且考虑了loss function本身的curvature(曲率),所以它的优化效率比一阶的更高。二阶优化Natural Policy Gradient的形式:

其中

需要算Fisher Information Matrix求逆,所以当F非常大的时候,比如模型参数很多,是神经网络,这样直接求Natural Policy Gradient的效率就很低。 - 所以这篇论文就提出用K-FAC近似Fisher Information Matrix。
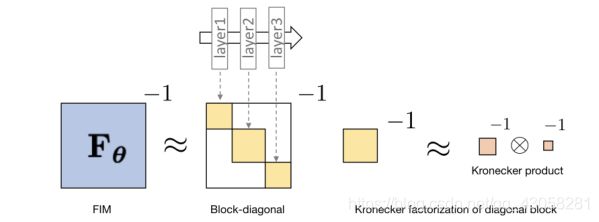
- 它的大致思想是把Fisher Information Matrix做分解。神经网络是由多层结构组成的;F这个矩阵写成diagonal block的形式,每一个block对应了某一层的参数,这某一层的参数只与层内的参数相关,所以本身这个矩阵实在diagonal(对角线)上的矩阵;对于每一个对角线上的矩阵都可以做kronecker product的分解,分解后对这个矩阵求逆就等于对分解出来的矩阵求逆。所以这篇论文就利用了这个思想来加速训练。

- 蓝色的线是对SGD优化,横轴是它的training iteration,效率是非常低的,因为它是first-order的优化;换成K-FAC natural gradient的方法后,loss降得非常快,training iteration可能是它的十倍的效率提升。
- ACKTR方法就是把natural gradient里面算Fisher Information Matrix这一步,用kronecker product做了个近似,提升了算法的效率。
- 对比实验结果

- Introductory link:
https://blog.openai.com/baselines-acktr-a2c/
6.2.4 PPO
- TRPO的简化版本,把里面的优化过程做了更简单的优化。

更新的policy和原来的policy之间的KL散度距离小于提前定的trust region的范围。 - 上式写unconstrained的形式:

用 β \beta β参数把两个条件同时组合起来,这样相当于得到了一个objective function。使得整个joint loss极大化后,第一项使得带了importance sampling的gradient极大化, β \beta β也是正数,所以相当于使得第二部分极小,这样就可以让两个条件同时满足。 - PPO的思想就是用了unconstrained form重新把两个条件结合起来,所以就可以在优化本身的客观函数的同时,也把条件考虑进去。
- PPO的算法同时还做了Adaptive kL Penalty。

- 根据实际的情况大小, β \beta β会做一个对应的调整。当更新的policy比之前的policy较大的时候,比如大于 1.5 δ 1.5\delta 1.5δ的时候,我们就会让它的penalty变得更大, θ k + 1 {\theta}_{k+1} θk+1中第二项就会被考虑的更多;
- 当KL-divergence小于 δ / 1.5 \delta/1.5 δ/1.5的时候,就减小penalty的影响,使得算法做更大的更新。所以把 β k / 2 {{\beta}_{k}/2} βk/2。
- 也就是说算法对KL-divergence有一个自适应(adaptive)的过程来调整penalty这一项的强度。
- PPO可以取得和TRPO类似的效果,但优势是速度要快很多,因为PPO本身优化的过程是利用first-order optimization(SGD,一阶优化) 优化的,所以优化效率比二阶的TRPO快很多,因为PPO的算法过程中并没有去计算KL-divergence或者Fisher information matrix。
PPO with clipping
- 在PPO中有probability ratio(概率比) r t ( θ ) r_t(\theta) rt(θ),当前策略与之前策略输出的对比。

- 根据形式不同有各种形式的优化函数。
- PG算法(没有trust region):

直接用advantage function × reward。 - 加入KL constraint:

TPRO的情况,要满足constraint去优化它。 - KL penalty:

KL用 β \beta β写进去,PPO的创新点,KL会adaptive(自适应)这个算法。
- PPO提供了第二种方式是把objective function自身带了clipping,所以它提出了更复杂一些的形式来处理本身loss的优化情况。
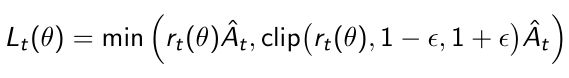
设定了clipping函数,clipping会根据你当前的probability ratio的大小。如果大于 1 + ϵ 1+\epsilon 1+ϵ或小于 1 − ϵ 1-\epsilon 1−ϵ,就会把它clip掉。使得 r t ( θ ) r_t(\theta) rt(θ)保持在 1 − ϵ 1-\epsilon 1−ϵ和 1 + ϵ 1+\epsilon 1+ϵ之间。 - 通常 ϵ \epsilon ϵ设定为0.2。这样就奠定了ratio的更新情况。
How the clipping works
- Clipping函数形式做简单的分解
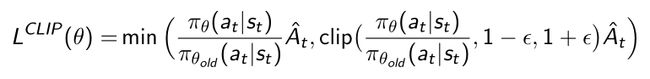
- 看成两种情况,当advantage是正数的时候,我们就需要去鼓励当前采取的行为。
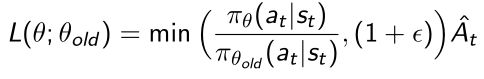
- min取ratio和 1 + ϵ 1+\epsilon 1+ϵ更小的那个数来作为weight;
- 如果ratio很大的话,如果没有这个min它就会取很大,所以加了个clip使得它最大不能超过 1 + ϵ 1+\epsilon 1+ϵ。这样就使得policy output本身不会有太激进的变化。
- 另一种条件形式,如果advantage是负数的时候,说明我们当前的行为并不会带来很大的奖励,所以我们需要discourage,让agent不要做出这样的行为,去减少它。

这里做了max的操作,当ratio特别小的时候,max operator就可以起作用,这样就使得更新不会变得特别小,也是限制了更新策略函数最小的值。 - PPO的形式:

大部分PPO算法都是用了Clipped Objective的形式,因为Clipped Objective非常容易写出来,pytorch写loss形式的时候,可以把clipped写出来就可以用简单的SGD去优化它了。 - PPO相对于TRPO和policy gradient的效率以及安全性更高,且实现非常容易。只需要加入几行代码,去限制它的loss function就可以实现,就可以把vanilla policy gradient(VPG,普通策略梯度算法)改写成PPO的形式。
Result of PPO
- 连续控制问题(MuJuCo)
https://gym.openai.com/envs/mujoco

紫线是PPO,随着training增长非常快,效率相对于其他算法更稳定。 - Demo of PPO at
https://blog.openai.com/openai-baselines-ppo/ - Emergence of Locomotion Behaviours in Rich Environments by DeepMind (Distributed PPO):
https://www.youtube.com/watch?v=hx_bgoTF7bs
Code of PPO
- Paper link of PPO:
https://arxiv.org/abs/1707.06347 - Code example:
https://github.com/cuhkrlcourse/DeepRLTutorials/blob/master/14.PPO.ipynb
def compute_loss(self,sample):
...
surr1 = ratio * adv_targ#之前的情况
surr2 = torch.clamp(ratio,1.0-self.clip_param,1.0+self.clip_param)*adv_targ#加上clipping后
action_loss = -torch.min(surr1,surr2).mean()#取min
...
通过这几行代码就可以把之前policy gradient变成PPO的形式,而其他不用做改变,这就是为什么PPO用的这么广泛,可以加入几行代码使得效率和稳定性都上一个台阶。
第一条线总结
- TRPO:通过数学证明保证了策略优化的稳定性以及单调递增的特性。
- ACKTR:对TRPO有了改进,数值上算Fisher Information Matrix用了K-FAC的方法,使得用于更广泛的用途中,效率也得到提升。
- PPO:对之前的TRPO有了更简化的改进,使得算法更加易懂且容易实现。
6.3 Second lines of works on SOTA policy optimization
另一条主线,从价值函数优化的进展,从Q-learning开始。
6.3.1 DDPG
- 全称Deep Deterministic Policy Gradient(DDPG),虽然名字是policy gradient,但是是对DQN的扩展。
- DQN算法在学到Q network后输出是离散的,action是取得argmax,只能输出唯一的离散的输出。DDPG提出动机是能够使得DQN扩展到连续的动作空间。比如之前的MuJuCo这样环境是连续控制的问题,所以需要连续控制的强化学习算法。
- DDPG本身是和DQN非常像的,可以看作DQN的连续空间的版本。
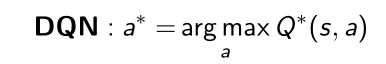
当学出Q network后,我们会取argmax,得到唯一的action。

DDPG让离散的动作空间变成连续的。- 这里取得的action是从==deterministic policy == μ θ ( s ) {\mu}_{\theta}(s) μθ(s)直接出来的, μ θ ( s ) {\mu}_{\theta}(s) μθ(s)本身我们可以当作一个policy,也就是说当我们把一个状态放进去后 μ θ ( s ) {\mu}_{\theta}(s) μθ(s)就会直接输出一个连续的值。当得到 μ θ ( s ) {\mu}_{\theta}(s) μθ(s)后,值可以直接放到Q network里面去,就可以得到Q的值。
- 因为action a a a是连续的,所以我们假设Q function对于a Q ϕ ( s , a ) Q_{\phi}(s,a) Qϕ(s,a)也是可以直接求导的,这样就可以把policy gradient的优化和value function的优化两者结合起来。
- DDPG优化函数
它也利用了target network和policy network,所以有两个network:target network以及它正在优化的organization network。- Q-target:

它的policy network也是有两个版本,有一个target network以及它正在优化的那个network,所以对于policy network和Q network都有两个网络。 - Q function:

所以它这里Q function的优化和之前value function优化是差不多的,从replay buffer里面直接采样tuples放到Q-function函数中优化。 - 当得到Q函数后,对策略函数policy进行优化的形式是:
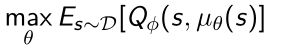
固定 Q ϕ Q_{\phi} Qϕ去优化 θ \theta θ, θ \theta θ是deterministic policy它的参数,这样就使得policy极大化。
- Q-target:
- DDPG也和DQN类似,用了replay buffer的思想,以及target network的思想。对于它的value network和policy network都有target network。
- DDPG example code (using the sampe codebase for TD3):
https://github.com/sfujim/TD3/blob/master/DDPG.py
import copy
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Implementation of Deep Deterministic Policy Gradients (DDPG)
# Paper: https://arxiv.org/abs/1509.02971
# [Not the implementation used in the TD3 paper]
#Actor的网络,action本身是连续的动作空间。
class Actor(nn.Module):
def __init__(self, state_dim, action_dim, max_action):
super(Actor, self).__init__()
self.l1 = nn.Linear(state_dim, 400)
self.l2 = nn.Linear(400, 300)
self.l3 = nn.Linear(300, action_dim)
self.max_action = max_action
def forward(self, state):
a = F.relu(self.l1(state))
a = F.relu(self.l2(a))
return self.max_action * torch.tanh(self.l3(a))#tanh可以使得fc是-1到1之间的连续值,再乘以实现定义好的max_action的值
class Critic(nn.Module):
def __init__(self, state_dim, action_dim):
super(Critic, self).__init__()
self.l1 = nn.Linear(state_dim, 400)
self.l2 = nn.Linear(400 + action_dim, 300)
self.l3 = nn.Linear(300, 1)
def forward(self, state, action):
q = F.relu(self.l1(state))
q = F.relu(self.l2(torch.cat([q, action], 1)))
return self.l3(q)
class DDPG(object):
def __init__(self, state_dim, action_dim, max_action, discount=0.99, tau=0.001):
self.actor = Actor(state_dim, action_dim, max_action).to(device)
self.actor_target = copy.deepcopy(self.actor)
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=1e-4)
self.critic = Critic(state_dim, action_dim).to(device)
self.critic_target = copy.deepcopy(self.critic)
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), weight_decay=1e-2)
self.discount = discount
self.tau = tau
def select_action(self, state):
state = torch.FloatTensor(state.reshape(1, -1)).to(device)
return self.actor(state).cpu().data.numpy().flatten()
def train(self, replay_buffer, batch_size=64):
# Sample replay buffer 采样
state, action, next_state, reward, not_done = replay_buffer.sample(batch_size)
# Compute the target Q value
target_Q = self.critic_target(next_state, self.actor_target(next_state))
target_Q = reward + (not_done * self.discount * target_Q).detach()
# Get current Q estimate
current_Q = self.critic(state, action)
# Compute critic loss
critic_loss = F.mse_loss(current_Q, target_Q)
# Optimize the critic
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
# Compute actor loss
actor_loss = -self.critic(state, self.actor(state)).mean()
# Optimize the actor
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
# Update the frozen target models
for param, target_param in zip(self.critic.parameters(), self.critic_target.parameters()):
target_param.data.copy_(self.tau * param.data + (1 - self.tau) * target_param.data)
for param, target_param in zip(self.actor.parameters(), self.actor_target.parameters()):
target_param.data.copy_(self.tau * param.data + (1 - self.tau) * target_param.data)
def save(self, filename):
torch.save(self.critic.state_dict(), filename + "_critic")
torch.save(self.critic_optimizer.state_dict(), filename + "_critic_optimizer")
torch.save(self.actor.state_dict(), filename + "_actor")
torch.save(self.actor_optimizer.state_dict(), filename + "_actor_optimizer")
def load(self, filename):
self.critic.load_state_dict(torch.load(filename + "_critic"))
self.critic_optimizer.load_state_dict(torch.load(filename + "_critic_optimizer"))
self.critic_target = copy.deepcopy(self.critic)
self.actor.load_state_dict(torch.load(filename + "_actor"))
self.actor_optimizer.load_state_dict(torch.load(filename + "_actor_optimizer"))
self.actor_target = copy.deepcopy(self.actor)
6.3.2 TD3
Twin Delayed DDPG(TD3)
- DDPG中的Q函数有时会overestimate Q-values(过估计)。实际的Q value和Q network输出的Q value进行了对比。
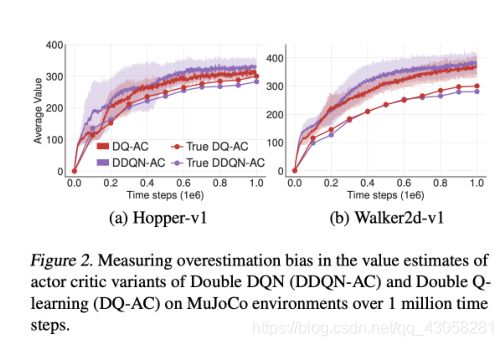
- 实际的Q value是用MC的方法去算的。举个例子,给定了policy,去产生1000条轨迹,就会得到return G t G_t Gt,取平均后就会得到Q实际对应得 G t G_t Gt的值。用Q network输出的值和实际的 G G G的平均值做对比,发现Q network输出远比实际值高,说明Q network估计的网络做了overestimate,这样就使得整个训练变得不稳定。
- TD3针对DDPG提出了三种改进:
- Clipped Double-Q Learning. 用了两个Q-network。
- “Delayed” Policy Updates. 用了"Delayed"的思想,对于策略函数的更新的速度是要慢于Q network的,这样就可以使得Q network的更新和策略函数的更新两者解耦,关联度降低,这样可以克服overestimate。
- Target Policy Smoothing. 引入smoothing的思想。
- TD3有两个Q函数, Q ϕ 1 Q_{\phi_1} Qϕ1, Q ϕ 2 Q_{\phi_2} Qϕ2。
- 所以它在算Q-target的时候用了min operator
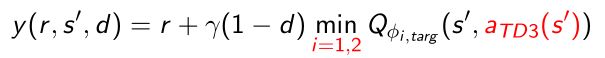
对于两个Q network取更小的那个值作为它的Q network。假设有两个人在同时estimate,现在估计算的Q-target,算法采用的是估计的更小的那个值,这样可以减弱这两个估计overconfident的可能性。 - 对于policy smoothing也引入了clipping的思想。
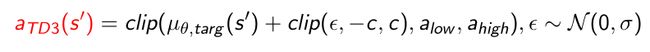
对 ϵ \epsilon ϵ本身进行clipping, e p s i l o n epsilon epsilon是从normal distribution里面采用出来的,使得引入了一些噪声clip,噪声加到输出 μ θ , t a r g ( s ′ ) {\mu}_{\theta,targ}(s') μθ,targ(s′)上面,相当于加入了一些扰动。- 加入噪声起到了regularize(规则化)的目的。
- 实验结果

- 有意思的是自己的DDPG和官方的DDPG差异很大,说明DDPG本身对于初始化或者调参是十分敏感的。TD3对参数并不是那么敏感。
- TD3和SAC是当前最好的强化学习算法之一,但是有意思的是在这篇TD3的论文中TD3比SAC好,但是在SAC的论文中显示SAC比TD3好。说明强化学习算法对参数是十分敏感的,这也是强化学习本身困难的原因。
- TD3 paper: Fujimoto, et al. Addressing Function Approximation Error in Actor-Critic Methods. ICML’18:
https://arxiv.org/pdf/1802.09477.pdf - Author’s Pytorch implementation (very clean implementation!):
https://github.com/sfujim/TD3/
这是个非常好的代码库,强烈推荐!
import copy
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Implementation of Twin Delayed Deep Deterministic Policy Gradients (TD3)
# Paper: https://arxiv.org/abs/1802.09477
#Actor定义于DDPG相同
class Actor(nn.Module):
def __init__(self, state_dim, action_dim, max_action):
super(Actor, self).__init__()
self.l1 = nn.Linear(state_dim, 256)
self.l2 = nn.Linear(256, 256)
self.l3 = nn.Linear(256, action_dim)
self.max_action = max_action
def forward(self, state):
a = F.relu(self.l1(state))
a = F.relu(self.l2(a))
return self.max_action * torch.tanh(self.l3(a))
#定义了两个Q network,保留了两组独立的参数
class Critic(nn.Module):
def __init__(self, state_dim, action_dim):
super(Critic, self).__init__()
# Q1 architecture
self.l1 = nn.Linear(state_dim + action_dim, 256)
self.l2 = nn.Linear(256, 256)
self.l3 = nn.Linear(256, 1)
# Q2 architecture
self.l4 = nn.Linear(state_dim + action_dim, 256)
self.l5 = nn.Linear(256, 256)
self.l6 = nn.Linear(256, 1)
#两个network分别forward,输出两个q值
def forward(self, state, action):
sa = torch.cat([state, action], 1)
q1 = F.relu(self.l1(sa))
q1 = F.relu(self.l2(q1))
q1 = self.l3(q1)
q2 = F.relu(self.l4(sa))
q2 = F.relu(self.l5(q2))
q2 = self.l6(q2)
return q1, q2
def Q1(self, state, action):
sa = torch.cat([state, action], 1)
q1 = F.relu(self.l1(sa))
q1 = F.relu(self.l2(q1))
q1 = self.l3(q1)
return q1
class TD3(object):
def __init__(
self,
state_dim,
action_dim,
max_action,
discount=0.99,
tau=0.005,
policy_noise=0.2,
noise_clip=0.5,
policy_freq=2
):
self.actor = Actor(state_dim, action_dim, max_action).to(device)
self.actor_target = copy.deepcopy(self.actor)
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=3e-4)
self.critic = Critic(state_dim, action_dim).to(device)
self.critic_target = copy.deepcopy(self.critic)
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=3e-4)
self.max_action = max_action
self.discount = discount
self.tau = tau
self.policy_noise = policy_noise
self.noise_clip = noise_clip
self.policy_freq = policy_freq
self.total_it = 0
def select_action(self, state):
state = torch.FloatTensor(state.reshape(1, -1)).to(device)
return self.actor(state).cpu().data.numpy().flatten()
def train(self, replay_buffer, batch_size=100):
self.total_it += 1
# Sample replay buffer
state, action, next_state, reward, not_done = replay_buffer.sample(batch_size)
with torch.no_grad():
# Select action according to policy and add clipped noise
#加入了noise,使得policy smooth,加入了normal distribution里面采样的噪声。
#noise本身做了clipping,因为从高斯采样出来很有可能采样到一个非常大的值
noise = (
torch.randn_like(action) * self.policy_noise
).clamp(-self.noise_clip, self.noise_clip)
#加了clipping的思想,把noise加到actor_target里面,引入了regularize,对输出再做了一次clip
next_action = (
self.actor_target(next_state) + noise
).clamp(-self.max_action, self.max_action)
# Compute the target Q value
#有两个target
target_Q1, target_Q2 = self.critic_target(next_state, next_action)
#取更小的值,使得克服overestimate
target_Q = torch.min(target_Q1, target_Q2)
target_Q = reward + not_done * self.discount * target_Q
# Get current Q estimates
current_Q1, current_Q2 = self.critic(state, action)
# Compute critic loss
critic_loss = F.mse_loss(current_Q1, target_Q) + F.mse_loss(current_Q2, target_Q)
# Optimize the critic
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
# Delayed policy updates
#policy update的频率是低于Q network,Q network更新两次,policy更新一次
if self.total_it % self.policy_freq == 0:
# Compute actor losse
actor_loss = -self.critic.Q1(state, self.actor(state)).mean()
# Optimize the actor
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
# Update the frozen target models
for param, target_param in zip(self.critic.parameters(), self.critic_target.parameters()):
target_param.data.copy_(self.tau * param.data + (1 - self.tau) * target_param.data)
for param, target_param in zip(self.actor.parameters(), self.actor_target.parameters()):
target_param.data.copy_(self.tau * param.data + (1 - self.tau) * target_param.data)
def save(self, filename):
torch.save(self.critic.state_dict(), filename + "_critic")
torch.save(self.critic_optimizer.state_dict(), filename + "_critic_optimizer")
torch.save(self.actor.state_dict(), filename + "_actor")
torch.save(self.actor_optimizer.state_dict(), filename + "_actor_optimizer")
def load(self, filename):
self.critic.load_state_dict(torch.load(filename + "_critic"))
self.critic_optimizer.load_state_dict(torch.load(filename + "_critic_optimizer"))
self.critic_target = copy.deepcopy(self.critic)
self.actor.load_state_dict(torch.load(filename + "_actor"))
self.actor_optimizer.load_state_dict(torch.load(filename + "_actor_optimizer"))
self.actor_target = copy.deepcopy(self.actor)
main.py将不同算法的脚本放到一个代码中去,有利于切换算法比较。run./experiments.sh可以复现它所有的结果。- 值得一提的是,作者不是Berkelely/OpenAI 或 DeepMind,而是来自McGill University。
6.3.3 SAC
Soft Actor-Critic(SAC)
- 提出了==entropy regularization(熵正则化)==的思想。
- Entropy是一个量度,度量一个随机变量对概率函数自身的无序程度
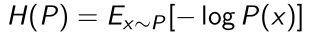
- Entropy-regularized RL:让我们策略优化的时候,让expected return和entropy两者做一个权衡,所以它的loss function 是可以写成这样一个joint loss function:

第一部分是它本身的expected return,第二部分是entropy。因为算法本身是希望对未知空间尽可能多的探索,这样就有可能获取得到更多奖励的行为。所以就做了这样一个trade-off(权衡),同时去优化,在保证得到算法policy多样性的情况下,也能得到expected return极大化。 - Value function就把这个entropy写到Value functon里面去了,增加了个entropy bonus(熵加成) α H ( π ( . ∣ s t ) ) \alpha H(\pi(.|s_t)) αH(π(.∣st)),在极大化objective function的时候,让entropy也极大化。
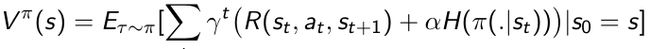
- 在推导Bellman equation的时候也写进了entropy,对entropy进行展开,Q函数就会变成如下形式:
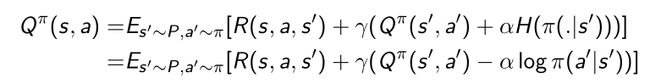
- 采用sample update,Q函数就会进一步写成如下形式:
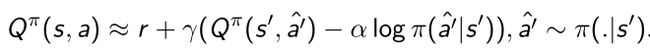
- SAC也TD3比较类似的是也用了两个Q functions, Q ϕ 1 Q_{\phi_1} Qϕ1, Q ϕ 2 Q_{\phi_2} Qϕ2。最早两个Q function的思想其实是在Duel Q network里面,可以消除Q network的overestimate。
- 与TD3一样,target取了极小的输出,再把entropy regularization(熵正则化) α l o g π θ ( a ′ ^ ∣ s ′ ) \alpha log{\pi}_{\theta}(\hat{a'}|s') αlogπθ(a′^∣s′)也写进去 。

- 优化的时候 V π ( s ) V^{\pi}(s) Vπ(s)的时候也加了entropy α l o g π ( a ∣ s ) \alpha log\pi(a|s) αlogπ(a∣s)
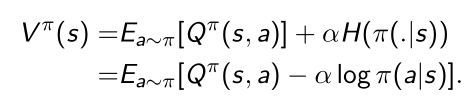
- SAC算法还用了==reparameterization(重参数)==的方法。

之前是为了更新action,action本身包含了 ϵ \epsilon ϵ, ϵ \epsilon ϵ是从normal distribution N ( 0 , 1 ) N(0,1) N(0,1)里面采样的。网络输出mean μ θ ( s ) {\mu}_{\theta}(s) μθ(s)和 σ θ ( s ) {\sigma}_{\theta}(s) σθ(s)乘以随机的 ϵ \epsilon ϵ,加和起来后随机性是从 ϵ \epsilon ϵ来的。 - 这样就可以使得expectation(期望)本来a是针对于policy function π θ {\pi}_{\theta} πθ的采样,变成跟参数 θ \theta θ没有关系的采样。

- 策略优化函数可以写成:
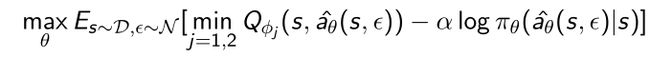
与TD3差异是有了entropy term 和reparameterization(重参数) trick。
Reparameterization Trick介绍
- 很多时候我们需要对 f ( x ) f(x) f(x)采样估计一个期望后算一个针对于 θ \theta θ的gradient,问题是期望也是和 θ \theta θ相关,所以就比较难算gradient。
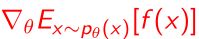
- 所以我们引入 ϵ \epsilon ϵ的思想
- ϵ \epsilon ϵ是从一个独立的分布采样出来的(uniform distribution或高斯分布)

- 采样出 ϵ \epsilon ϵ后,把 ϵ \epsilon ϵ放到某一个new network去产生 x x x

- 就可以让原来的gradient做一个简单的变化,让expectation是针对与 ϵ \epsilon ϵ的
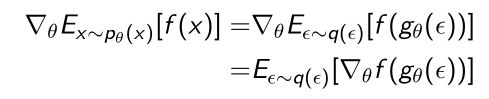
- 就相当于用 ϵ \epsilon ϵ来Reparameterize x x x,这样就可以把 g θ ( ϵ ) g_{\theta}(\epsilon) gθ(ϵ)写成:

带参的 θ \theta θ就放到 μ \mu μ和 σ \sigma σ里面去了,就和 ϵ \epsilon ϵ随机性没有关系。
- 就相当于用 ϵ \epsilon ϵ来Reparameterize x x x,这样就可以把 g θ ( ϵ ) g_{\theta}(\epsilon) gθ(ϵ)写成:
- ϵ \epsilon ϵ是从一个独立的分布采样出来的(uniform distribution或高斯分布)
- Reparameterization Trick和REINFORCE有关系,都是通过参数sampling的方法规避求导的问题。
http://stillbreeze.github.io/REINFORCE-vs-Reparameterization-trick/
SAC算法实现
https://github.com/pranz24/pytorch-soft-actor-critic/blob/master/sac.py
import os
import torch
import torch.nn.functional as F
from torch.optim import Adam
from utils import soft_update, hard_update
from model import GaussianPolicy, QNetwork, DeterministicPolicy
class SAC(object):
def __init__(self, num_inputs, action_space, args):
self.gamma = args.gamma
self.tau = args.tau
self.alpha = args.alpha
self.policy_type = args.policy
self.target_update_interval = args.target_update_interval
self.automatic_entropy_tuning = args.automatic_entropy_tuning
self.device = torch.device("cuda" if args.cuda else "cpu")
self.critic = QNetwork(num_inputs, action_space.shape[0], args.hidden_size).to(device=self.device)
self.critic_optim = Adam(self.critic.parameters(), lr=args.lr)
self.critic_target = QNetwork(num_inputs, action_space.shape[0], args.hidden_size).to(self.device)
hard_update(self.critic_target, self.critic)
if self.policy_type == "Gaussian":
# Target Entropy = −dim(A) (e.g. , -6 for HalfCheetah-v2) as given in the paper
if self.automatic_entropy_tuning is True:
self.target_entropy = -torch.prod(torch.Tensor(action_space.shape).to(self.device)).item()
self.log_alpha = torch.zeros(1, requires_grad=True, device=self.device)
self.alpha_optim = Adam([self.log_alpha], lr=args.lr)
#高斯policy的形式
self.policy = GaussianPolicy(num_inputs, action_space.shape[0], args.hidden_size, action_space).to(self.device)
self.policy_optim = Adam(self.policy.parameters(), lr=args.lr)
else:
self.alpha = 0
self.automatic_entropy_tuning = False
self.policy = DeterministicPolicy(num_inputs, action_space.shape[0], args.hidden_size, action_space).to(self.device)
self.policy_optim = Adam(self.policy.parameters(), lr=args.lr)
#selected action,把Reparameterization Trick加到采样过程
def select_action(self, state, evaluate=False):
state = torch.FloatTensor(state).to(self.device).unsqueeze(0)
if evaluate is False:
action, _, _ = self.policy.sample(state)
else:
_, _, action = self.policy.sample(state)
return action.detach().cpu().numpy()[0]
def update_parameters(self, memory, batch_size, updates):
# Sample a batch from memory
state_batch, action_batch, reward_batch, next_state_batch, mask_batch = memory.sample(batch_size=batch_size)
state_batch = torch.FloatTensor(state_batch).to(self.device)
next_state_batch = torch.FloatTensor(next_state_batch).to(self.device)
action_batch = torch.FloatTensor(action_batch).to(self.device)
reward_batch = torch.FloatTensor(reward_batch).to(self.device).unsqueeze(1)
mask_batch = torch.FloatTensor(mask_batch).to(self.device).unsqueeze(1)
with torch.no_grad():
#输出两个Q target
next_state_action, next_state_log_pi, _ = self.policy.sample(next_state_batch)
qf1_next_target, qf2_next_target = self.critic_target(next_state_batch, next_state_action)
min_qf_next_target = torch.min(qf1_next_target, qf2_next_target) - self.alpha * next_state_log_pi
next_q_value = reward_batch + mask_batch * self.gamma * (min_qf_next_target)
qf1, qf2 = self.critic(state_batch, action_batch) # Two Q-functions to mitigate positive bias in the policy improvement step
#对于两个target都会有分别的优化过程
qf1_loss = F.mse_loss(qf1, next_q_value) # JQ = (st,at)~D[0.5(Q1(st,at) - r(st,at) - γ(st+1~p[V(st+1)]))^2]
qf2_loss = F.mse_loss(qf2, next_q_value) # JQ = (st,at)~D[0.5(Q1(st,at) - r(st,at) - γ(st+1~p[V(st+1)]))^2]
qf_loss = qf1_loss + qf2_loss
self.critic_optim.zero_grad()
qf_loss.backward()
self.critic_optim.step()
#采样产生的policy
pi, log_pi, _ = self.policy.sample(state_batch)
qf1_pi, qf2_pi = self.critic(state_batch, pi)
min_qf_pi = torch.min(qf1_pi, qf2_pi)
policy_loss = ((self.alpha * log_pi) - min_qf_pi).mean() # Jπ = st∼D,εt∼N[α * logπ(f(εt;st)|st) − Q(st,f(εt;st))]
self.policy_optim.zero_grad()
policy_loss.backward()
self.policy_optim.step()
if self.automatic_entropy_tuning:
alpha_loss = -(self.log_alpha * (log_pi + self.target_entropy).detach()).mean()
self.alpha_optim.zero_grad()
alpha_loss.backward()
self.alpha_optim.step()
self.alpha = self.log_alpha.exp()
alpha_tlogs = self.alpha.clone() # For TensorboardX logs
else:
alpha_loss = torch.tensor(0.).to(self.device)
alpha_tlogs = torch.tensor(self.alpha) # For TensorboardX logs
if updates % self.target_update_interval == 0:
soft_update(self.critic_target, self.critic, self.tau)
return qf1_loss.item(), qf2_loss.item(), policy_loss.item(), alpha_loss.item(), alpha_tlogs.item()
# Save model parameters
def save_model(self, env_name, suffix="", actor_path=None, critic_path=None):
if not os.path.exists('models/'):
os.makedirs('models/')
if actor_path is None:
actor_path = "models/sac_actor_{}_{}".format(env_name, suffix)
if critic_path is None:
critic_path = "models/sac_critic_{}_{}".format(env_name, suffix)
print('Saving models to {} and {}'.format(actor_path, critic_path))
torch.save(self.policy.state_dict(), actor_path)
torch.save(self.critic.state_dict(), critic_path)
# Load model parameters
def load_model(self, actor_path, critic_path):
print('Loading models from {} and {}'.format(actor_path, critic_path))
if actor_path is not None:
self.policy.load_state_dict(torch.load(actor_path))
if critic_path is not None:
self.critic.load_state_dict(torch.load(critic_path))
- SAC is known as SOTA for robot learning:
- Learning to Walk in the Real World with Minimal Human Effort.
https://arxiv.org/pdf/2002.08550.pdf - https://www.youtube.com/watch?v=cwyiq6dCgOc
- Learning to Walk in the Real World with Minimal Human Effort.
总结
- Policy Gradient→TRPO→ACKTR→PPO
- Stochastic policy thus output probability over discrete actions
- Start with policy gradient and importance sampling for off-policy
learning
- Q-learning→DDPG→TD3→SAC
- Deterministic policy thus output continuous action spaces.
- Start with Bellman equation, which doesn’t care which transition tuples
are used, or how the actions were selected, or what happens after a
given transition - Optimal Q-function should satisfy the Bellman equation for all possible
transitions, so very esay for off-policy learning
- SpinningUp: Nice implementations and summary of the algorithms
from OpenAI: https://spinningup.openai.com/ - Stable-baseline: https://stable-baselines.readthedocs.io/
- Currently in TensorFlow
- PyTorch version is being actively developed:
https://github.com/hill-a/stable-baselines/issues/733