MySql为什么不推荐使用UUID做主键
设计MySQL数据库表的时候,一定会考虑主键的设计。mysql官方推荐不要使用uuid或者不连续不重复的雪花id,推荐连续自增的主键id,官方的推荐是auto_increment。为什么不建议采用uuid,使用uuid究竟有什么坏处?
如果设计表不设置主键,MySQL官方有以下说明:
If you do not define a PRIMARY KEY for your table, MySQL picks the first UNIQUE index that has only NOT NULL columns as the primary key and InnoDB uses it as the clustered index. If there is no such index in the table, InnoDB internally generates a clustered index where the rows are ordered by the row ID that InnoDB assigns to the rows in such a table. The row ID is a 6-byte field that increases monotonically as new rows are inserted. Thus, the rows ordered by the row ID are physically in insertion order.
翻译:如果没有主动设置主键,就会选一个第一个不包含NULL的唯一索引列作为主键列,并把它用作一个聚集索引。如果没有这样的索引就会使用行号生成一个聚集索引,把它当做主键,这个行号6bytes,自增。可以用select _rowid from table来查询。
1. 什么是主键?主键有什么用
mysql 数据库表存放关系型结构化数据,一定会提供对数据的CRUD操作。在查询操作时,如果没有索引,MySQL必须从第一行开始,然后读取整个表以查找相关行。表越大,成本越高。通过建立索引,MySQL可以根据索引文件快速确定要在数据文件中间寻找的位置,而无需查看所有数据。
MySQL的索引主要分为主键索引(PRIMARY KEY),唯一索引(UNIQUE) ,普通索引(INDEX)和全文索引(FULLTEXT) 。主键索引是一种特殊的唯一索引,不允许有空值。
MySQL中索引是如何发挥功效的呢?先看一下MySQL的执行过程:
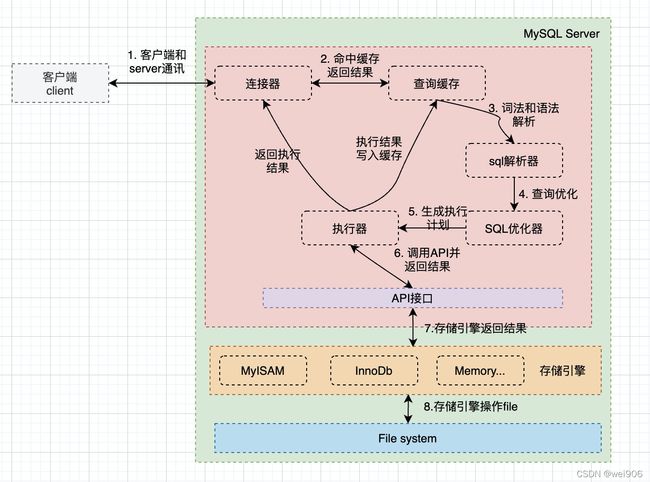
所有与数据的交互是会通过引擎服务的,MySQL中常见的引擎包括MyIsam和InnoDb。二者的差别这里不做叙述,可参见:CSDN https://mp.csdn.net/mp_blog/creation/editor/96205289
https://mp.csdn.net/mp_blog/creation/editor/96205289
InnoDB的存储文件有两个,后缀名分别是 .frm和 .idb;其中 .frm是表的定义文件, .idb是表的数据文件。InnoDB引擎采用B+Tree结构来作为索引结构,InnoDB主键的叶子节点是该行的数据,而其他索引则指向主键。

2. 为什么不推荐使用UUID
页是 InnoDB 管理的最小单位,常见的有 FSP_HDR,INODE, INDEX 等类型。页结构分为文件头(前38字节),页数据和文件尾(后8字节)。每个数据页大小为16kb,结构如下:

系统从磁盘中读取数据到内存时是以磁盘块(block)为基本单位,位于同一个磁盘块中的数据会被一次性读取出来。block大小空间往往没有16kb大,因此innodb每次io操作时都会将若干个地址连续的磁盘块的数据读入内存,从而实现整页读入内存。
MySQL写入数据时,会把数据存放到索引页中。使用UUID作为主键,新行的主键值不一定比之前的主键值大,所以innoDb无法做到总是把新行插入到索引的最后,而需要为新行寻找合适的位置来分配新的空间,这个过程会导致:
- 写入的目标页可能从缓存上移除了,或者还没有加载到缓存上,innodb写入之前需要先从磁盘找到目标页,会产生大量的随机IO;
- 因为写入是乱序的,innoDb 要做频繁的分页操作,以便为行产生新的空间,页分裂导致移动大量的数据,一次插入最少需要修改三个页以上;
- 频繁的页分裂,页会变得稀疏并被不规则的填充,最终会导致数据会有碎片;
- 随机值(uuid和雪花id)载入到聚簇索引,有时候会需要做一次OPTIMEIZE TABLE来重建表并优化页的填充,这将又需要一定的时间消耗。
使用自增主键则可以避免上述问题:
- 自增主键值是顺序的,所以Innodb把每一条记录都存储在一条记录的后面。当达到页面的最大填充因子时候(innodb默认的最大填充因子是页大小的15/16,会留出1/16的空间留作以后的 修改),下一条记录就会写入新的页中;
- 数据按照顺序方式加载,主键页就会近乎于顺序的记录填满,提升了页面的最大填充率,不会有页的浪费;
- 新插入的行一定会在原有的最大数据行下一行,mysql定位和寻址很快,不会为计算新行的位置而做出额外的消耗;
- 减少了页分裂和碎片的产生
结论:使用innodb应该尽可能的按主键的自增顺序插入,并且尽可能使用单调的增加的聚簇键的值来插入新行
3. 使用自增主键的问题
- 安全问题:如果采用自增主键,可能存在根据ID值爬取数据库记录,有安全风险;
- 系统重构:系统重构或者与其他系统集成时,可能存在新老主键冲突;
- 高并发负载,innodb在按主键进行插入的时候会造成明显的锁争用,主键的上界会成为争抢的热点,因为所有的插入都发生在这里,并发插入会导致间隙锁竞争;
- Auto_Increment锁机制会造成自增锁的抢夺,有一定的性能损失;
- 自增主键有限,要考虑主键长度问题。
Auto_increment的锁争抢问题,可以通过调优innodb_autoinc_lock_mode的配置,总共有三个有效值可供设定,即0、1、2,具体说明如下:
0:是MySQL 5.1.22版本之前自增长的实现方式,即通过表锁的AUTO-INC Locking方式,所有的insert语句在开始时都会获得一个表锁AUTO-INC Locking。该锁会一直持有到insert语句执行结束才会被释放。对于一条insert插入多个行记录的语句,保证了同一条语句插入的行记录的自增ID是连续的。
1:这是该参数的默认值,对于”simple inserts”,该值会用互斥量(mutex)去对内存中的计数器进行累加的操作。insert语句在开始时会获得一个表锁AUTO-INC Locking,但对于bulk insert,自增锁会被一直持有直到语句执行结束才会被释放。这种模式仍然保证了同一条语句插入的行记录的自增ID是连续的。
2:对于所有的插入操作”INSERT-LIKE”自增长值的产生都是通过互斥量,而不是AUTO-INC Locking的方式,不管什么情况都使用轻量级互斥的锁。因为并发插入的存在,在每次插入时,自增长的值可能不是连续的。最重要的是,基于Statement的主从复制会出现问题,任何时候都应该使用Row方式,这样才能保证最大的并发性能及主从数据的一致。