hadoop集群搭建
第一步:安装JDK8
第二步:修改服务器名称,我搭建的是三个结点:一个主节点master两个从节点 内存2GB 磁盘20GB
| master |
192.168.116.51 |
| slave1 |
192.168.116.52 |
| slave2 |
192.168.116.53 |
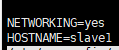
#vim /etc/sysconfig/network
一主:
![]()
两从:
![]()
第三步:设置网络IP与服务器名映射
查询IP
#ifconfig -a
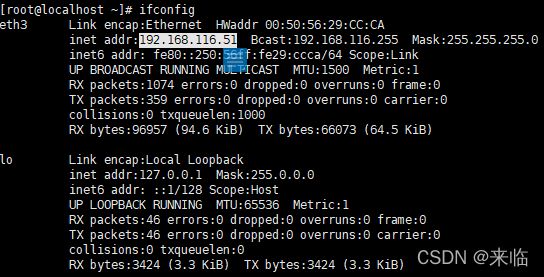
映射地址,三台服务器都要设置
#vim /etc/hosts

如果虚拟机没有关闭防火墙,需关闭防火墙,ping域名能成功

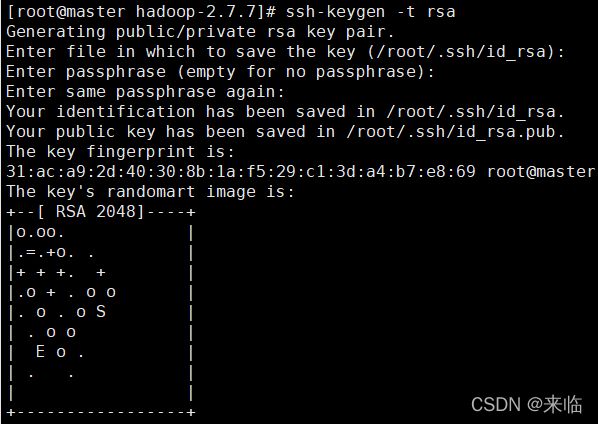
第四步:免密登录(在master节点启动hadoop集群时可以同时启动slave1、slave2节点)
#ssh-keygen -t rsa
执行后一路回车
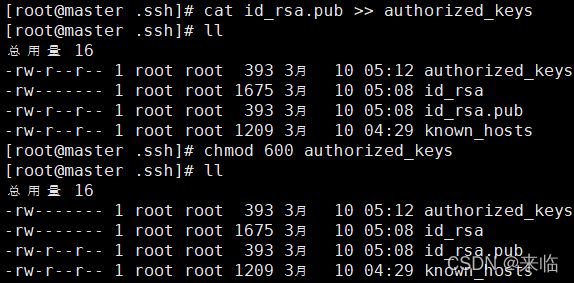
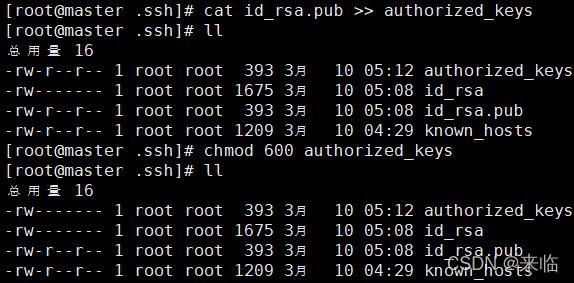
进入.ssh文件,有两个文件id_rsa(私钥)和id_rsa.pub(公钥),将公钥复制到authorized_keys并赋予authorized_keys600权限
#cd ~/.ssh/

#cat id_rsa.pub >> authorized_keys
#chmod 600 authorized_key
把公钥同步到slave1和slave2节点上
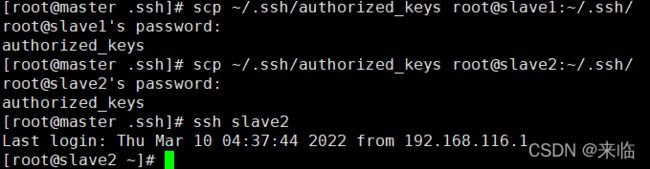
第四步 搭建Hadoop环境(master)
1、创建服务器用户及用户组(三台服务器均设置)
添加用户
#adduser hadoop
为用户设置密码
#passwd hadoop
创建hadoop用户组(前面hadoop是用户组名,后一个hadoop是用户名)
#usermod -a -G hadoop hadoop
![]()
赋予hadoop用户root权限
----经测试-这样修改不行---
#vim /etc/sudoers
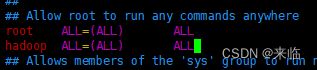
强制保存(wq!)
---------------end---------
-----使用这种方式----------
#sudo visudo

--------end---------------
2、安装hadoop并配置环境变量(由于Hadoop集群的每一个节点上有相同配置,因此先在master上设置,后同步到其他节点上)
上传Hadoop压缩包(hadoop-2.7.7.tar.gz),我的解压路径是:/opt/hadoop/hadoop-2.7.7
配置环境变量(根据自己的解压路径设置):
#vim /etc/profile

export HADOOP_HOME=/opt/hadoop/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
3、搭建集群环境准备
切换hadoop用户
#su hadoop
在master节点上创建以下文件夹
/opt/hadoop/hadoop-2.7.7/hdfs
/opt/hadoop/hadoop-2.7.7/hdfs/name
/opt/hadoop/hadoop-2.7.7/hdfs/data
/opt/hadoop/hadoop-2.7.7/hdfs/temp
4、配置hadoop相关配置文件(/opt/hadoop/hadoop-2.7.7/etc/hadoop/)

配置hadoop-env.sh
![]()
配置yarn-env.sh
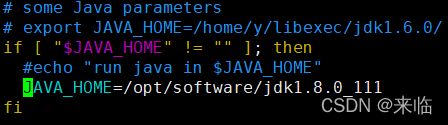
配置slaves,删除localhost,配置从服务器主机
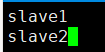
配置core-site.xml
配置hdfs-size.xml

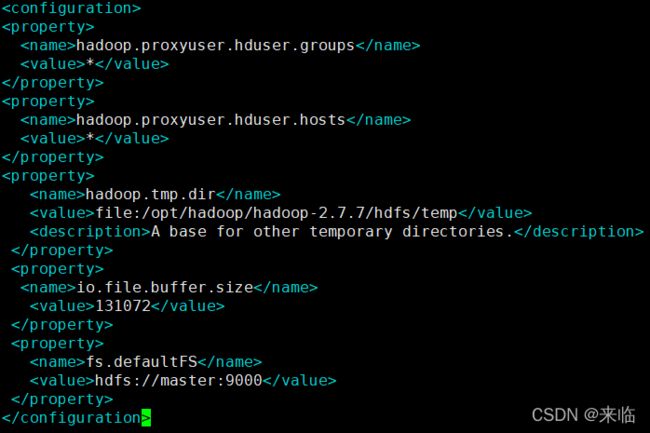
配置mapred-site.xml(如果该文件后面有.template,要删掉后缀:mv mapred-site.xml.template mapred-site.xml)
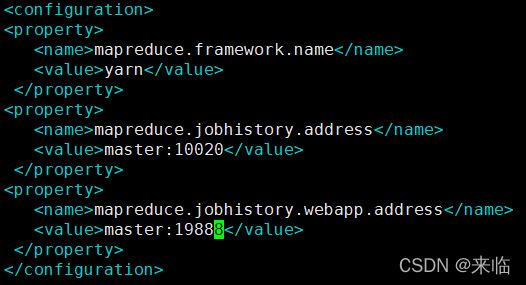
配置yarn-size.xml
5、将已配置的Hadoop分发到slave1、slave2虚拟机
#scp -r hadoop-2.7.7 hadoop@slave1:/opt/hadoop
#scp -r hadoop-2.7.7 hadoop@slave2:/opt/hadoop
如果权限不足有两种解决方案:
1、目标文件/opt 赋权 chmod /opt 777
2、使用root用户
#scp -r hadoop-2.7.7 root@slave2:/opt/hadoop
注意:slave1、slave2虚拟机Hadoop环境变量不要忘记配置
6、运行hadoop,格式化Namenode
![]()
source /etc/profile
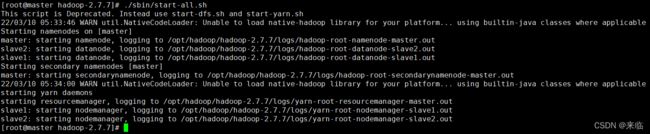
7、启动集群
#./sbin/start-all.sh
![]()
 测试运行Hadoop自带的例子
测试运行Hadoop自带的例子
#hadoop jar /opt/hadoop/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar pi 10 10
出现如下提示,恭喜你安装成功

本机访问hadoop管理页面
http://master:8088/cluster
注意:修改本机hosts(C:\Windows\System32\drivers\etc\hosts)
