之前更完了《Kafka从入门到放弃》系列文章,本人决定开新坑——hive从入门到放弃,今天先认识一下hive。
没看过 Kafka 系列的朋友可以点此传送阅读:
《Kafka从入门到放弃》系列
hive介绍
hive是一个开源的用于大数据分析和统计的数据库工具,它的存储基于HDFS,计算基于MapReduce或Spark,可以将结构化数据映射成表,并提供类SQL查询功能。
特点
- 提供类SQL查询,容易上手,开发方便
- 封装了很多方法,尽量避免了开发MapReduce程序,减少成本
- 支持自定义函数,可以根据需求实现函数
- 适用于处理大规模数据,小数据的处理没有优势
- 执行延迟较高,适合用于数据分析,不适合对时效性要求较高的场景
hive的架构
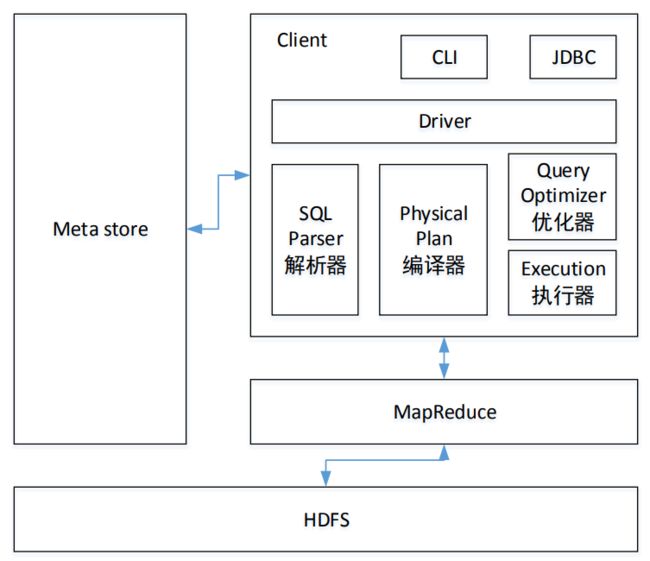
- MetaStore:元数据,数据的数据,比如某个表的元数据,包括表名、表所属的数据库、表的类型、表的数据目录等;
- CLI(命令行接口)、JDBC:用户接口,用以访问hive;
- Sql Parser 解析器:将SQL转换成抽象语法树,一般用第三方工具库完成;对抽象语法树进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误;
- Physical Plan 编译器:将抽象语法树编译生成逻辑执行计划;
- Query Optimizer 优化器:对逻辑执行计划进行优化;
- Execution 执行器:把逻辑执行计划转换成可以运行的物理计划。对Hive而言,就是 MR/Spark;
- HDFS:hive数据文件存放的地方。
不熟悉 HDFS 的朋友可以点击传送:《大数据 | 分布式文件系统 HDFS》
hive运行机制
当创建表的时候,需要指定HDFS文件路径,表和其文件路径会保存到MetaStore,从而建立表和数据的映射关系。当数据加载如表时,根据映射获取到对应的HDFS路径,将数据导入。
用户输入SQL后,hive会将其翻译成MapReduce或者Spark任务,提交到Yarn上面执行,执行成功将返回结果。
*hive默认将元数据存储在derby数据库中,但其仅支持单线程操作,若有一个用户在操作,其他用户则无法使用,造成效率不高;
而且当在切换目录后,重新进入Hive会找不到原来已经创建的数据库和表,
因此一般用MySQL存储元数据。
hive与数据库
可能有些朋友会认为,hive是数据库,因为它提供了类SQL查询功能。但其实除了这一点和数据库相似以外,其它的根本就没有多少共性。
- 数据库支持事务,可读可写;而hive不支持事务,一般用于读多写少的情况,不建议改动数据,因为数据存储在HDFS中,而HDFS的文件不支持修改;
- hive延迟比较大,因其底层是MapReduce,执行效率较慢。但当数据规模较大的情况下,hive的并行计算优势就体现出来了,数据库的效率就不如hive了;
- hive不支持索引,查询的时候是全表扫描,这也是其延迟大的原因之一;
*hive在0.14以后的版本支持事务,前提是文件格式为 orc 格式,同时必须分桶,还必须显式声明 transactional=true
hive的数据类型
数字类
| 类型 | 长度 |
|---|---|
| TINYINT | 1-byte |
| SMALLINT | 2-byte |
| INT/INTEGER | 4-byte |
| BIGINT | 8-byte |
| FLOAT | 4-byte |
| DOUBLE | 8-byte |
| DECIMAL | - |
日期类
| 类型 | 版本 |
|---|---|
| TIMESTAMP | 0.8.0以后 |
| DATE | 0.12.0以后 |
| INTERVAL | 1.2.0以后 |
字符类
| 类型 | 版本 |
|---|---|
| STRING | - |
| VARCHAR | 0.12.0以后 |
| CHAR | 0.13.0以后 |
Misc类
| 类型 | 版本 |
|---|---|
| BOOLEAN | - |
| BINARY | 0.8.0以后 |
复合类
| 类型 | 版本 | 备注 |
|---|---|---|
| ARRAYS | 0.14.以后 | ARRAY |
| MAPS | 0.14.以后 | MAP |
| STRUCTS | - | STRUCT |
| UNION | 0.7.0以后 | UNIONTYPE |
小结
本文从hive的特点、架构及运行机制开始,并将hive与数据库做对比,简单介绍了hive,同时对hive的数据类型做一个简单的介绍。
如果觉得写得还不错,麻烦点个小小的赞支持一下作者,可以持续关注【大数据的奇妙冒险】,解锁更多知识。