理解“闭包”
作者:哲思
时间:2021.9.5
GitHub:zhe-si (哲思) (github.com)
前言
说起“闭包”,我的大脑里的第一反应不是在编程中常讲的“闭包”,反而是大学离散数学课本中的“闭包”。为了明确二者的区别与联系,并加强对“闭包的”本身的理解,我对“闭包”进行了一些研究,并撰写此文,希望能给大家帮助。
离散数学——“闭包”
首先,简单说明一下基本概念:
- 集合:有限、无序、互异的元素组成的整体
- 运算:n个集合映射到某一集合的映射过程
- 关系:多个集合笛卡儿积的子集,如三元关系类似
接下来,给出“闭包”比较官方的定义:
【维基百科】
数学中,若对某个集合的成员进行一种运算,生成的仍然是这个集合的成员,则该集合被称为在这个运算下闭合。
- 例如,实数在减法下闭合,但自然数不行(自然数 3 和 7 的减法 3 − 7 的结果不是自然数)。
当一个集合 S 在某个运算下不闭合的时候,我们通常可以找到包含 S 的最小的闭合集合。这个最小闭合集合被称为 S 的(关于这个运算的)闭包。
- 例如,实数是减法运算下的闭合集合,即实数是减法运算下的闭包。而自然数则不是减法下的闭包。
简单解释,就是在给定的关系中,添加最少的元素,使其具有某种性质,则称添加后的集合为该性质上关系的闭包。如:具有自反性,则为自反闭包。
再抽象一些:定义某个特定的、封闭的范围,范围内的元素满足某些性质,就是该性质下的“闭包”。
通过“闭包”,我们可以让当前研究的关系利用构造闭包得到的性质进行简化。反过来,也可以让满足某些性质的集合限定在某个确定且封闭的范围内。
函数式编程——“闭包”
概念理解
在js、python、kotlin等语言中常谈的“闭包”,其实都是指的函数式编程中的“闭包”,也称“词法闭包”或“函数闭包”。
这个概念是在λ演算中被提出,并由Peter J. Landin在1964年引入术语——“闭包”(closure)。定义中,“闭包”包括两部分:环境部分、控制部分。
函数式编程的基础就是λ演算,一种通过函数去描述世界的范式,重点是描述事物与事物间的关系。
介绍一种函数式语言:scheme(Lisp的一个方言)来描述lambda演算。
\[( define (f\ X)(Y)) \]式中,定义了一个名为\(f\)的函数,参数是X,返回值是Y
参数:X可为任意个,写作:\(x1\ x2\ ……\)
返回值:Y可为表达式(如:\((+\ x\ y)\),表示\(x + y\))或函数(如:\((lambda (x\ y)(+\ x\ y))\),表示一个接受参数\(x\)和\(y\)并返回\(x + y\)的函数)
现在,通过scheme定义一个\(x + y\)的函数(假设“+”运算已经定义):
可以通过该函数计算\(5 + 1\):
接下来,我们定义一个通用的函数,该函数可以返回一个可以给某值\(x\)加固定值\(y\)的lambda函数:
该函数的参数是\(y\),返回值是\((lambda\ (x)\ (+\ x\ y))\)。我们将目光聚焦返回值,可以看到,该函数接受一个参数\(x\),却没有\(y\)参数,\(y\)来自定义该返回值函数的上下文环境!也就是说,\(y\)由定义该函数时的上下文环境决定,相对于定义的返回值函数,\(y\)是自由的,来自环境,在不同环境下有不同表现,不被函数定义本身所限制。而\(x\)则被返回值函数的定义声明为该函数的参数,是绑定在函数内的。
我们继续上面的例子,通过该函数得到一个可以给\(x\)加1的函数:
那么,我们进一步实现给5加1的运算:
这里总共发生了两个过程:在\(f\)函数执行的局部环境下定义了一个函数、使用返回的新定义的函数在其执行的局部环境下得到最终结果。
正常情况下,函数内的局部变量会在函数执行结束后释放。但在该场景下,若\(y\)被释放,则新定义的函数中的\(y\)就无法从环境中获得了。所以,提出了一种机制,当函数在执行中,其内的某变量被其内定义的函数引用后,不会立刻释放该变量,允许新定义的函数持有该变量的引用。这就是在lambda演算中引入“闭包”的原因,这种机制产生的持有上层函数环境、新定义的函数,就叫“闭包”。
现在,我们已经基本理解了“闭包”,最后给出它的一些经典定义:
【MDN】
闭包是将函数与其引用的周边状态绑定在一起形成(封装)的组合。
【犀牛书】
将函数对象和作用域相互关联起来(一对变量的绑定),函数体内部的变量都可以保存在函数作用域内,这种特性在计算机科学文献中称为闭包。
【维基百科】
在一些语言中,在函数中可以(嵌套)定义另一个函数时,如果内部的函数引用了外部的函数的变量,则可能产生闭包。闭包可以用来在一个函数与一组“私有”变量之间创建关联关系。在给定函数被多次调用的过程中,这些私有变量能够保持其持久性。
三个定义含义基本一致。简单来说,就是\(闭包 = 函数 + 环境\),环境就是上面说到的作用域。
三个满足闭包的条件:1. 访问所在作用域;2. 函数嵌套;3. 在所在作用域外被调用。条件3是为了说明调用返回新函数的过程中在内存里实际形成了闭包;而条件2不是绝对条件,从某种意义上,全局作用域也是一种环境;所以,满足条件1即可称为闭包。
画龙点睛
到这里,偏向概念上的东西已经讲完了,但还有一些重要的细节,在这里通过论断的方式提出。
-
函数式编程,允许运行时定义函数。
在上面,我们一直没有关注一个事情——我们不是静态的在编译前定义的函数,而是在运行时动态定义的。这是函数式编程的关键之一,也是闭包形成的基础。
在上面lambda演算的例子中,我们每次在某个环境下动态定义新的函数,并将环境保存,进而形成了闭包。
-
函数的每次调用都会产生一个新的环境。
环境产生的时机是每次调用,其局部环境在调用后产生并作为运行时新动态定义的函数的环境。
这里强调一个点——“每次调用”。也就是说,如果只有一次函数调用,在其内定义多个新函数,每个新函数共享环境。
这里是一个很容易出错的地方,来个例题:利用闭包,修改下面的代码,让循环输出的结果依次为1, 2, 3, 4, 5。
该例中,我们期望每一个timer引用的i的取值作为一个独立的环境,这样timer闭包就可以输出不同的数字。
而在下面给定的源代码中,定义的多个新函数绑定的是同一个环境(最外层函数的 i 局部变量),导致每个输出都为i的最终值6。
for (var i = 1; i <= 5; i++) { setTimeout(function timer() { console.log(i); }, i * 1000); }我们为每一个 i 的取值添加了一个函数的调用,对应产生了一个独立的环境,每一个新定义的timer都使用独立环境的 ii 变量,实现了我们的目标效果。
for (var i = 1; i <= 5; i++) { (function () { var ii = i; setTimeout(function timer() { console.log(ii); }, i * 1000); })() } -
调用定义新函数的函数才会产生新的闭包。
闭包的产生对应一个新的函数被定义出来,与闭包函数本身被调用无关。
这里也有一个例子:
var fn = null; function foo() { var a = 2; function innnerFoo() { console.log(c); // 在这里,试图访问函数bar中的c变量,会抛出错误 console.log(a); } fn = innnerFoo; // 将 innnerFoo的引用,赋值给全局变量中的fn } function bar() { var c = 100; fn(); // 此处的保留的innerFoo的引用 } foo(); bar();本例中,试图在bar函数中调用某闭包函数访问bar内的局部变量,期望让闭包函数本身的调用影响闭包的产生,显然是错误的。
还是那句话,只有调用定义新函数的函数(或者像本例将新定义的函数通过保存在一个变量而不是作为返回值返回)的时候产生的环境才可以被闭包函数引用并产生新的闭包。
-
一般,闭包绑定的环境只包含用到的部分。
也就是说,一般不会不考虑用不用都把环境完整保存(这样没有引用所在外部作用域的非闭包函数岂不也要像闭包一样将环境保存?),而是用了哪个变量就保存那个变量。
举个例子:
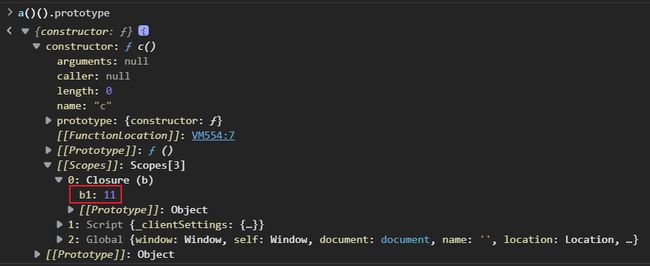
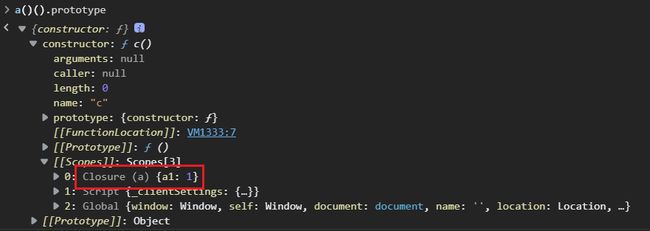
我们定义一个两层嵌套的闭包函数c,来探究部分绑定的问题。
python版本
def a(): a1 = 4 a2 = 5 def b(): b1 = 7 b2 = 8 def c(): c1 = 12 c2 = 13 return c1 + b1 # return c1 + a1 return c return bjs版本
function a() { var a1 = 1; var a2 = 2; return function b() { var b1 = 11; var b2 = 12; return function c() { var c1 = 101; var c2 = 102; return c1 + b1; // return c1 + a1; } } }我们只看最内层的闭包函数c。如果引用b1,则返回的函数只包含环境中的b1;如果引用a1,则返回的函数只包含环境中的a1。引用b2、a2同理,大家可以亲手尝试一下。
结果用js进行展示,如下图:
实现剖析
以js为例,介绍一下闭包基本的实现方式。
在js中,变量分为两种,局部和全局,并通过一个作用域链存储在堆中。
当查找变量时,会从作用域链末端(一般,末端即是当前作用域下的存储节点)向上游进行查找,直到找到目标变量。这也是函数可以引用外部作用域的变量的原因。
当函数执行结束释放时,一般会将其对应的局部存储空间释放,也就是由gc垃圾回收机制对无有效引用或不可达的对象进行释放。但由于引入了闭包,允许作用域内定义的新函数持有当前作用域的变量的引用(注意,不是拷贝),再加上新函数被返回后保存,导致变量被闭包函数持有有效引用而无法被垃圾回收机制释放。这就是闭包实现的基本原理。
给一个简单的例子,如下图。在全局调用foo函数,foo函数定义并返回一个新的innerFoo闭包函数保存在全局,返回的闭包函数持有foo函数调用中的局部变量arguments。在foo执行结束后,会释放除新定义的闭包函数innerFoo以及对应的环境arguments变量之外的其他局部变量(a变量)。
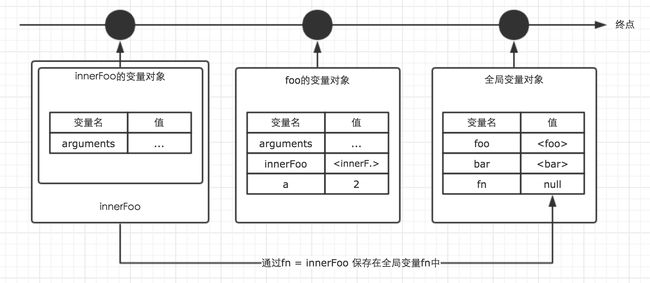
同时,由于保留下来的环境只有对应的闭包函数持有引用,所以也只能通过闭包函数进行访问,也就产生了一个访问的作用域。该特性可以避免使用全局变量,防止全局变量对命名空间等的污染。
这样的实现方式,让局部变量可以不跟随定义它的函数的结束而释放,让外部访问函数内的局部变量成为可能。但同时,更复杂的引用持有机制也容易造成内存泄漏。
类似技术对照
闭包技术是函数式编程解决定义函数依靠的数据与函数的绑定问题,同时提供变量私有化、局部化的效果。这与面向对象封装数据与对应方法的思路十分相似。(如果不熟悉面向对象,可以参考文章:从面向对象解读设计思想,包含了对面向对象从浅入深的讲解)
常见的两个相似技术是函数对象和内部类:
-
函数对象:
c++通过自定义类重载"()"运算符可以实现一种类似函数的调用方式,同时可以自由定义和配置不同对象(修改其内属性的值)来实现"()"运算符调用的不同效果,类似闭包绑定不同环境。
python也可以通过定义“_call_”魔术方法实现类似效果。
-
内部类:
java支持在函数中定义一个内部类,在内部类中可以引用外部函数的局部变量以及外部类的属性。
这个特性,也被java用来支持函数式编程的实现,如java中的lambda表达式。
思想拓展
没有证据可以证明该术语与数学中的“闭包”的关系,但我认为这里的“闭包”是数学中“闭包”概念上的一种引申。
数学中某性质的闭包指某个特定的、封闭的范围,范围内的元素都满足该性质。
在函数式编程的闭包中,闭包函数绑定的环境本身即可看成一种特定、封闭的范围,而函数就是该环境下满足的性质。
虽然没有将二者统一的必要,但确实可以从抽象形式上看出二者的一些相似性。同时,这些相似性也有益于我们去更好的理解与运用“闭包”。
【拓展】数据库——“闭包”
在关系型数据库中,定义了属性集和FD集(函数依赖,某个属性决定另一个属性时,称另一属性依赖于该属性),则某属性子集的“闭包”指该子集所有属性与基于该子集通过函数依赖可以推导出的所有属性的集合。
\[子集A的闭包 = 子集A \ ∪ \ 子集A通过FD集推导出的所有属性集合 \]
举个例子:
属性集:\(A\ B\ C\ D\)
FD集:\(\{ A \rightarrow B, B \rightarrow C, D \rightarrow B \}\)
记子集T的闭包为\(T^+\),则:
-
\(A^+ = A B C\)
解释:A可以推导出B,B推导出C,加起来为ABC
-
\((AD)^+ = ABCD\)
解释:A可以推导出B,B推导出C,D推导出B,加起来为ABCD
-
\((BD)^+ = BCD\)
解释:B可以推导出C,D可以推导出B,加起来为BCD
从上面的概念和例子中可以明显看出,在数据库中“闭包”的概念是离散数学中“闭包”概念的推广。这里的运算就是FD集,满足FD集这样的性质的最小集合就是某子集在该性质下的闭包。
后记
关于“闭包”这个单词的含义还有很多,本文只是介绍了数学和计算机领域比较重要的概念与理解。但在了解了诸多领域对于该词的描述后,发现万变不离其宗,都是在研究一个满足某些性质的封闭环境(范围)。可能,这本身就是认识论和方法论的一个重要内容——让我们在一个确定的范围内,去探究事物的本质。