Linux Kubernetes 使用statefulset控制器部署mysql主从集群
一、StatefulSets
StatefulSet 是用来管理有状态应用的工作负载 API 对象。
StatefulSet 用来管理 Deployment 和扩展一组 Pod,并且能为这些 Pod 提供序号和唯一性保证。
和 Deployment 相同的是,StatefulSet 管理了基于相同容器定义的一组 Pod。但和 Deployment 不同的是,StatefulSet 为它们的每个 Pod 维护了一个固定的 ID。这些 Pod 是基于相同的声明来创建的,但是不能相互替换:无论怎么调度,每个 Pod 都有一个永久不变的 ID。
StatefulSet 和其他控制器使用相同的工作模式。你在 StatefulSet 对象 中定义你期望的状态,然后 StatefulSet 的 控制器 就会通过各种更新来达到那种你想要的状态。
StatefulSets 对于需要满足以下一个或多个需求的应用程序很有价值:
- 稳定的、唯一的网络标识符。
- 稳定的、持久的存储。
- 有序的、优雅的部署和缩放。
- 有序的、自动的滚动更新。
在上面,稳定意味着 Pod 调度或重调度的整个过程是有持久性的。如果应用程序不需要任何稳定的标识符或有序的部署、删除或伸缩,则应该使用由一组无状态的副本控制器提供的工作负载来部署应用程序,比如 Deployment 或者 ReplicaSet 可能更适用于您的无状态应用部署需要。
给定 Pod 的存储必须由 PersistentVolume 驱动 基于所请求的 storage class 来提供,或者由管理员预先提供。
删除或者收缩 StatefulSet 并不会删除它关联的存储卷。这样做是为了保证数据安全,它通常比自动清除 StatefulSet 所有相关的资源更有价值。
StatefulSet 当前需要 headless 服务 来负责 Pod 的网络标识。您需要负责创建此服务。
当删除 StatefulSets 时,StatefulSet 不提供任何终止 Pod 的保证。为了实现 StatefulSet 中的 Pod 可以有序和优雅的终止,可以在删除之前将 StatefulSet 缩放为 0。
在默认 Pod 管理策略(OrderedReady) 时使用 滚动更新,可能进入需要 人工干预 才能修复的损坏状态。
StatefulSet将应用状态抽象成了两种情况:
- 拓扑状态:应用实例必须按照某种顺序启动。新创建的Pod必须和原来Pod的网络标识一样
- 存储状态:应用的多个实例分别绑定了不同存储数据。
StatefulSet给所有的Pod进行了编号,编号规则是:$(statefulset名称)-$(序号),从0开始。
Pod被删除后重建,重建Pod的网络标识也不会改变,Pod的拓扑状态按照Pod的“名字+编号”的方式固定下来,并且为每个Pod提供了一个固定且唯一的访问入口,即Pod对应的DNS记录,同时重建时保证每个pod挂载到原来的卷上。
二、StatefulSet通过Headless Service维持Pod的拓扑状态
首先创建Headless service:
[root@server1 pv]# mkdir statefulset
[root@server1 pv]# cd statefulset/
[root@server1 statefulset]# vim service.yaml
[root@server1 statefulset]# cat service.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
创建服务:
[root@server1 statefulset]# kubectl apply -f service.yaml
service/nginx created
[root@server1 statefulset]# kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 19d
myservice ClusterIP 10.101.31.155 <none> 80/TCP 14d
nginx ClusterIP None <none> 80/TCP 13s
- 1
- 2
- 3
- 4
- 5
- 6
- 7
可以看出创建了一个名为nginx的无头服务(Headless service)。
创建使用StatefulSet控制器的pod:
[root@server1 statefulset]# vim deployment.yaml
[root@server1 statefulset]# cat deployment.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx"
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
name: web
[root@server1 statefulset]#
[root@server1 statefulset]# kubectl apply -f deployment.yaml
statefulset.apps/web created
[root@server1 statefulset]#
[root@server1 statefulset]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nfs-client-provisioner-6b66ddf664-zjvtv 1/1 Running 0 31m
web-0 1/1 Running 0 29s
web-1 1/1 Running 0 26s
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
可以看出创建了两个名为web-0和web-1的pod,service也会由两个endpoint:
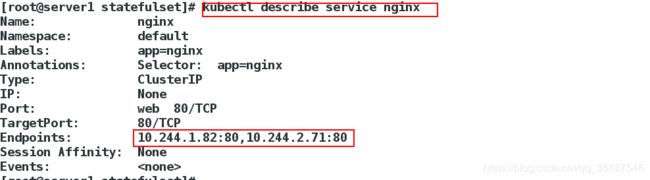
其中pod名称中的0和1是pod的唯一标识。
当我们将replicas改为1时,web-1将会被回收:
[root@server1 statefulset]# vim deployment.yaml
[root@server1 statefulset]# cat deployment.yaml
更改:
replicas: 1
[root@server1 statefulset]# kubectl apply -f deployment.yaml
statefulset.apps/web configured
[root@server1 statefulset]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nfs-client-provisioner-6b66ddf664-zjvtv 1/1 Running 0 33m
web-0 1/1 Running 0 2m12s
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
而当我们将replicas改为0时,所有pod将会被回收:
[root@server1 statefulset]# vim deployment.yaml
[root@server1 statefulset]# cat deployment.yaml
更改:
replicas: 0
[root@server1 statefulset]# kubectl apply -f deployment.yaml
statefulset.apps/web configured
[root@server1 statefulset]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nfs-client-provisioner-6b66ddf664-zjvtv 1/1 Running 0 34m
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
之后再次重建pod:
[root@server1 statefulset]# vim deployment.yaml
[root@server1 statefulset]# cat deployment.yaml
更改:
replicas: 2
[root@server1 statefulset]# kubectl apply -f deployment.yaml
statefulset.apps/web configured
[root@server1 statefulset]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nfs-client-provisioner-6b66ddf664-zjvtv 1/1 Running 0 35m
web-0 0/1 ContainerCreating 0 2s
[root@server1 statefulset]# kubectl get pod
^[[3~NAME READY STATUS RESTARTS AGE
nfs-client-provisioner-6b66ddf664-zjvtv 1/1 Running 0 35m
web-0 1/1 Running 0 9s
web-1 1/1 Running 0 7s
[root@server1 statefulset]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nfs-client-provisioner-6b66ddf664-zjvtv 1/1 Running 0 35m 10.244.1.81 server2 <none> <none>
web-0 1/1 Running 0 28s 10.244.2.72 server3 <none> <none>
web-1 1/1 Running 0 26s 10.244.1.83 server2 <none> <none>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
可以看出重新创建时是先创建web-0再创建web-1,而删除的时候是先删除web-1,再删除web-0.
但是需要注意的是虽然名称标识没有变,但是pod的ip发生了变化。
现在可以直接访问服务:
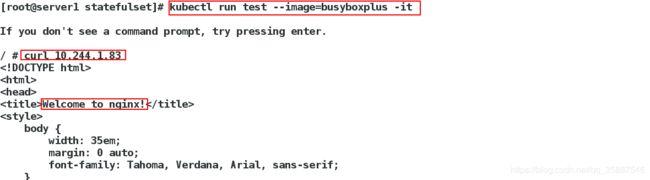
也可以解析地址:
 也可以使用
也可以使用nslookup web-1.nginx的方式解析和访问到:

PV和PVC的设计,使得StatefulSet对存储状态的管理成为了可能,现在为以上这些pod添加存储:
[root@server1 statefulset]# vim deployment.yaml
[root@server1 statefulset]# cat deployment.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx"
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
storageClassName: managed-nfs-storage #分配器名称
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Mi
[root@server1 statefulset]#
[root@server1 statefulset]# kubectl apply -f deployment.yaml
statefulset.apps/web created
[root@server1 statefulset]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nfs-client-provisioner-6b66ddf664-zjvtv 1/1 Running 0 85m 10.244.1.81 server2 <none> <none>
test 1/1 Running 2 48m 10.244.2.73 server3 <none> <none>
web-0 1/1 Running 0 25s 10.244.1.84 server2 <none> <none>
web-1 1/1 Running 0 20s 10.244.2.74 server3 <none> <none>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
StatefulSet还会为每一个Pod分配并创建一个同样编号的PVC。这样,kubernetes就可以通过Persistent Volume机制为这个PVC绑定对应的PV,从而保证每一个Pod都拥有一个独立的Volume:
[root@server1 statefulset]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
www-web-0 Bound pvc-41713073-508d-4dcf-897e-dd0575a0945a 100Mi RWO managed-nfs-storage 2m30s
www-web-1 Bound pvc-36ac2b3c-2f82-452e-ad39-bab2a51e67c6 100Mi RWO managed-nfs-storage 2m25s
[root@server1 statefulset]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-36ac2b3c-2f82-452e-ad39-bab2a51e67c6 100Mi RWO Delete Bound default/www-web-1 managed-nfs-storage 2m28s
pvc-41713073-508d-4dcf-897e-dd0575a0945a 100Mi RWO Delete Bound default/www-web-0 managed-nfs-storage 2m33s
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
可以往这些存储里写入测试页面:
[root@server1 statefulset]# ls /nfs/
default-www-web-0-pvc-41713073-508d-4dcf-897e-dd0575a0945a
default-www-web-1-pvc-36ac2b3c-2f82-452e-ad39-bab2a51e67c6
[root@server1 statefulset]#
[root@server1 statefulset]# echo web-0 > /nfs/default-www-web-0-pvc-41713073-508d-4dcf-897e-dd0575a0945a/index.html
[root@server1 statefulset]# echo web-1 > /nfs/default-www-web-1-pvc-36ac2b3c-2f82-452e-ad39-bab2a51e67c6/index.html
- 1
- 2
- 3
- 4
- 5
- 6
测试解析和访问:
[root@server1 statefulset]# kubectl attach test -it
/ # nslookup nginx
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: nginx
Address 1: 10.244.1.84 web-0.nginx.default.svc.cluster.local
Address 2: 10.244.2.74 10-244-2-74.myservice.default.svc.cluster.local
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
可以看出解析成功。
/ # curl nginx
web-1
/ # curl nginx
web-1
/ # curl nginx
web-0
/ # curl nginx
web-0
/ # curl nginx
web-1
/ # curl nginx
web-0
/ # curl web-1.nginx #访问特定pod
web-1
/ # curl web-0.nginx
web-0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
访问可以成功负载。
接下来我们将replicas设置为3,再次进行测试:
[root@server1 statefulset]# vim deployment.yaml
[root@server1 statefulset]# cat deployment.yaml
修改:
replicas: 3
[root@server1 statefulset]# kubectl apply -f deployment.yaml
statefulset.apps/web configured
[root@server1 statefulset]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nfs-client-provisioner-6b66ddf664-zjvtv 1/1 Running 0 90m
test 1/1 Running 4 53m
web-0 1/1 Running 0 5m14s
web-1 1/1 Running 0 5m9s
web-2 1/1 Running 0 9s
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
service由三个endpoint:
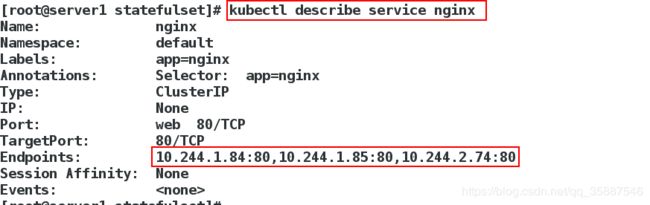 对应的pv当然也会创建:
对应的pv当然也会创建:
[root@server1 statefulset]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-36ac2b3c-2f82-452e-ad39-bab2a51e67c6 100Mi RWO Delete Bound default/www-web-1 managed-nfs-storage 5m35s
pvc-41713073-508d-4dcf-897e-dd0575a0945a 100Mi RWO Delete Bound default/www-web-0 managed-nfs-storage 5m40s
pvc-c6e2ee56-02d8-4540-9dc7-b91926d34274 100Mi RWO Delete Bound default/www-web-2 managed-nfs-storage 35s
- 1
- 2
- 3
- 4
- 5
写入测试页面并访问:
[root@server1 statefulset]# ls /nfs/
default-www-web-0-pvc-41713073-508d-4dcf-897e-dd0575a0945a
default-www-web-1-pvc-36ac2b3c-2f82-452e-ad39-bab2a51e67c6
default-www-web-2-pvc-c6e2ee56-02d8-4540-9dc7-b91926d34274
[root@server1 statefulset]# echo web-2 > /nfs/default-www-web-2-pvc-c6e2ee56-02d8-4540-9dc7-b91926d34274/index.html
[root@server1 statefulset]#
[root@server1 statefulset]# kubectl attach test -it
Defaulting container name to test.
Use 'kubectl describe pod/test -n default' to see all of the containers in this pod.
If you don't see a command prompt, try pressing enter.
/ # nslookup web-2.nginx
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: web-2.nginx
Address 1: 10.244.1.85 web-2.nginx.default.svc.cluster.local
/ # curl web-2.nginx
web-2
/ # curl web-1.nginx
web-1
/ # curl web-0.nginx
web-0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
可以看出成功解析且访问。
而当我们将replicas改为0后,StatefulSet会将pod从2 ,1,0有序删除。
[root@server1 statefulset]# vim deployment.yaml
[root@server1 statefulset]# cat deployment.yaml
更改:
replicas: 0
[root@server1 statefulset]# kubectl apply -f deployment.yaml
statefulset.apps/web configured
[root@server1 statefulset]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nfs-client-provisioner-6b66ddf664-zjvtv 1/1 Running 0 94m
test 1/1 Running 5 57m
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
删除后进行pod的重建:
[root@server1 statefulset]# vim deployment.yaml
[root@server1 statefulset]# cat deployment.yaml
更改:
replicas: 3
[root@server1 statefulset]# kubectl apply -f deployment.yaml
statefulset.apps/web configured
- 1
- 2
- 3
- 4
- 5
- 6
- 7
重键后测试访问:
[root@server1 statefulset]# kubectl attach test -it
/ # curl web-0.nginx
web-0
/ # curl web-1.nginx
web-1
/ # curl web-2.nginx
web-2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
依然可以成功访问,这就验证了StatefulSet 控制器的特性。
最后将replicas改为0删除所有pod。
以上的一系列操作都是通过更改部署文件实现的,当然也可以使用命令的方式:
- kubectl 弹缩
首先,想要弹缩的StatefulSet. 需先清楚是否能弹缩该应用.
$ kubectl get statefulsets <stateful-set-name>
- 1
- 改变StatefulSet副本数量:
$ kubectl scale statefulsets <stateful-set-name> --replicas=<new-replicas>
- 1
- 如果StatefulSet开始由 kubectl apply 或 kubectl create --save-config
创建,更新StatefulSet manifests中的 .spec.replicas, 然后执行命令 kubectl apply:
$ kubectl apply -f <stateful-set-file-updated>
- 1
- 也可以通过命令 kubectl edit 编辑该字段:
$ kubectl edit statefulsets <stateful-set-name>
- 1
- 使用 kubectl patch:
$ kubectl patch statefulsets <stateful-set-name> -p '{"spec":{"replicas":}}'
- 1
使用 statefulset控制器部署mysql主从集群
可以参考官方文档:https://kubernetes.io/zh/docs/tasks/run-application/run-replicated-stateful-application/
一、部署原理
使用 statefulset控制器部署mysql主从集群的原理如下图所示:
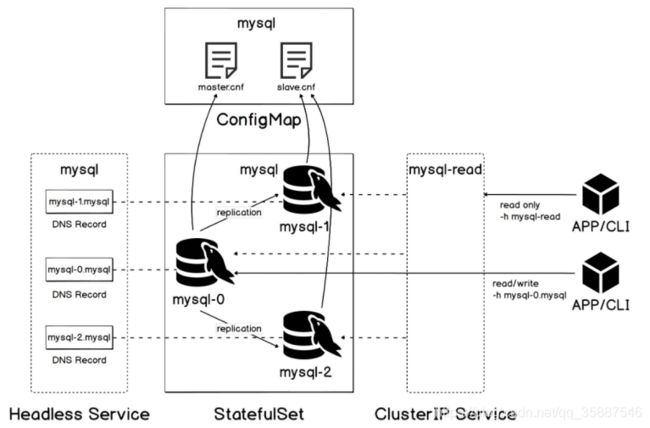
mysql主从复制的原理参考:https://blog.csdn.net/qq_35887546/article/details/104661790
具体的原理将会在下文介绍。
二、使用 statefulset控制器部署mysql主从集群
部署 MySQL
部署 MySQL 示例,包含一个 ConfigMap,两个 Services,与一个 StatefulSet。
创建ConfigMap
从以下的 YAML 配置文件创建 ConfigMap :
[root@server1 pv]# mkdir mysql
[root@server1 pv]# cd mysql/
[root@server1 mysql]# vim configmap.yaml
[root@server1 mysql]# cat configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql
labels:
app: mysql
data:
master.cnf: |
# Apply this config only on the master.
[mysqld]
log-bin
slave.cnf: |
# Apply this config only on slaves.
[mysqld]
super-read-only
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
这个 ConfigMap 提供 my.cnf 覆盖,使我们可以独立控制 MySQL 主服务器和从服务器的配置。 在这种情况下,我们希望主服务器能够将复制日志提供给从服务器,并且希望从服务器拒绝任何不是通过复制进行的写操作。
ConfigMap 本身没有什么特别之处,它可以使不同部分应用于不同的 Pod。 每个 Pod 都会决定在初始化时要看基于 StatefulSet 控制器提供的信息。
运行这个yaml文件之前删除之前实验所创建的configmap:
[root@server1 mysql]# kubectl delete cm --all
[root@server1 mysql]# kubectl get cm
No resources found in default namespace.
- 1
- 2
- 3
- 4
运行yaml文件:
[root@server1 mysql]# kubectl apply -f configmap.yaml
configmap/mysql created
[root@server1 mysql]# kubectl get cm
NAME DATA AGE
mysql 2 2s
查看这个cm的详细信息:
[root@server1 mysql]# kubectl describe cm mysql
Name: mysql
Namespace: default
Labels: app=mysql
Annotations:
Data
====
master.cnf: #主服务器的配置文件
----
# Apply this config only on the master.
[mysqld]
log-bin
slave.cnf: #从服务器的配置文件
----
# Apply this config only on slaves.
[mysqld]
super-read-only
Events: <none>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
创建Services
从以下 YAML 配置文件创建服务:
[root@server1 mysql]# vim service.yaml
[root@server1 mysql]# cat service.yaml
# Headless service for stable DNS entries of StatefulSet members.
apiVersion: v1
kind: Service
metadata:
name: mysql
labels:
app: mysql
spec:
ports:
- name: mysql
port: 3306
clusterIP: None
selector:
app: mysql
---
# Client service for connecting to any MySQL instance for reads.
# For writes, you must instead connect to the master: mysql-0.mysql.
apiVersion: v1
kind: Service
metadata:
name: mysql-read
labels:
app: mysql
spec:
ports:
- name: mysql
port: 3306
selector:
app: mysql
[root@server1 mysql]#
[root@server1 mysql]# kubectl apply -f service.yaml
service/mysql created
service/mysql-read created
[root@server1 mysql]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
mysql ClusterIP None <none> 3306/TCP 23s
mysql-read ClusterIP 10.100.94.198 <none> 3306/TCP 23s
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
Headless Service 给 StatefulSet 控制器为集合中每个 Pod 创建的 DNS 条目提供了一个宿主。因为 Headless Service 名为 mysql,所以可以通过在同一 Kubernetes 集群和 namespace 中的任何其他 Pod 内解析
客户端 Service 称为 mysql-read,是一种常规 Service,具有其自己的群集 IP,该群集 IP 在报告为就绪的所有MySQL Pod 中分配连接。可能端点的集合包括 MySQL 主节点和所有从节点。
请注意,只有读取查询才能使用负载平衡的客户端 Service。因为只有一个 MySQL 主服务器,所以客户端应直接连接到 MySQL 主服务器 Pod (通过其在 Headless Service 中的 DNS 条目)以执行写入操作。
StatefulSet控制器创建pod
最后,从以下 YAML 配置文件创建 StatefulSet:
[root@server1 mysql]# vim statefulset.yaml
[root@server1 mysql]# cat statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
spec:
selector:
matchLabels:
app: mysql
serviceName: mysql
replicas: 3
template:
metadata:
labels:
app: mysql
spec:
initContainers:
- name: init-mysql
image: mysql:5.7
command:
- bash
- "-c"
- |
set -ex
# Generate mysql server-id from pod ordinal index.
[[ `hostname` =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
echo [mysqld] > /mnt/conf.d/server-id.cnf
# Add an offset to avoid reserved server-id=0 value.
echo server-id=$((100 + $ordinal)) >> /mnt/conf.d/server-id.cnf
# Copy appropriate conf.d files from config-map to emptyDir.
if [[ $ordinal -eq 0 ]]; then
cp /mnt/config-map/master.cnf /mnt/conf.d/
else
cp /mnt/config-map/slave.cnf /mnt/conf.d/
fi
volumeMounts:
- name: conf
mountPath: /mnt/conf.d
- name: config-map
mountPath: /mnt/config-map
- name: clone-mysql
image: xtrabackup:1.0
command:
- bash
- "-c"
- |
set -ex
# Skip the clone if data already exists.
[[ -d /var/lib/mysql/mysql ]] && exit 0
# Skip the clone on master (ordinal index 0).
[[ `hostname` =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
[[ $ordinal -eq 0 ]] && exit 0
# Clone data from previous peer.
ncat --recv-only mysql-$(($ordinal-1)).mysql 3307 | xbstream -x -C /var/lib/mysql
# Prepare the backup.
xtrabackup --prepare --target-dir=/var/lib/mysql
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ALLOW_EMPTY_PASSWORD
value: "1"
ports:
- name: mysql
containerPort: 3306
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
resources:
requests:
cpu: 500m
memory: 300Mi
livenessProbe:
exec:
command: ["mysqladmin", "ping"]
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
readinessProbe:
exec:
# Check we can execute queries over TCP (skip-networking is off).
command: ["mysql", "-h", "127.0.0.1", "-e", "SELECT 1"]
initialDelaySeconds: 5
periodSeconds: 2
timeoutSeconds: 1
- name: xtrabackup
image: xtrabackup:1.0
ports:
- name: xtrabackup
containerPort: 3307
command:
- bash
- "-c"
- |
set -ex
cd /var/lib/mysql
# Determine binlog position of cloned data, if any.
if [[ -f xtrabackup_slave_info && "x$( != "x" ]]; then
# XtraBackup already generated a partial "CHANGE MASTER TO" query
# because we're cloning from an existing slave. (Need to remove the tailing semicolon!)
cat xtrabackup_slave_info | sed -E 's/;$//g' > change_master_to.sql.in
# Ignore xtrabackup_binlog_info in this case (it's useless).
rm -f xtrabackup_slave_info xtrabackup_binlog_info
elif [[ -f xtrabackup_binlog_info ]]; then
# We're cloning directly from master. Parse binlog position.
[[ `cat xtrabackup_binlog_info` =~ ^(.*?)[[:space:]]+(.*?)$ ]] || exit 1
rm -f xtrabackup_binlog_info xtrabackup_slave_info
echo "CHANGE MASTER TO MASTER_LOG_FILE='${BASH_REMATCH[1]}',\
MASTER_LOG_POS=${BASH_REMATCH[2]}" > change_master_to.sql.in
fi
# Check if we need to complete a clone by starting replication.
if [[ -f change_master_to.sql.in ]]; then
echo "Waiting for mysqld to be ready (accepting connections)"
until mysql -h 127.0.0.1 -e "SELECT 1"; do sleep 1; done
echo "Initializing replication from clone position"
mysql -h 127.0.0.1 \
-e "$(<change_master_to.sql.in), \
MASTER_HOST='mysql-0.mysql', \
MASTER_USER='root', \
MASTER_PASSWORD='', \
MASTER_CONNECT_RETRY=10; \
START SLAVE;" || exit 1
# In case of container restart, attempt this at-most-once.
mv change_master_to.sql.in change_master_to.sql.orig
fi
# Start a server to send backups when requested by peers.
exec ncat --listen --keep-open --send-only --max-conns=1 3307 -c \
"xtrabackup --backup --slave-info --stream=xbstream --host=127.0.0.1 --user=root"
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
resources:
requests:
cpu: 100m
memory: 100Mi
volumes:
- name: conf
emptyDir: {}
- name: config-map
configMap:
name: mysql
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 1Gi
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
StatefulSet 控制器一次按顺序启动 Pod 序数索引。它一直等到每个 Pod 报告就绪为止,然后再开始下一个 Pod。
此外,控制器为每个 Pod 分配一个唯一,稳定的表单名称
上述 StatefulSet 清单中的 Pod 模板利用这些属性来执行 MySQL 复制的有序启动。
- 生成配置
在启动 Pod 规范中的任何容器之前, Pod 首先按照定义的顺序运行所有初始容器。
第一个名为 init-mysql 的初始化容器,根据序号索引生成特殊的 MySQL 配置文件。
该脚本通过从 Pod 名称的末尾提取索引来确定自己的序号索引,该名称由 hostname 命令返回。 然后将序数(带有数字偏移量以避免保留值)保存到 MySQL conf.d 目录中的文件 server-id.cnf 中。 这将转换 StatefulSet 提供的唯一,稳定的身份控制器进入需要相同属性的 MySQL 服务器 ID 的范围。
通过将内容复制到 conf.d 中,init-mysql 容器中的脚本也可以应用 ConfigMap 中的 master.cnf 或 slave.cnf。由于示例拓扑由单个 MySQL 主节点和任意数量的从节点组成,因此脚本仅将序数 0 指定为主节点,而将其他所有人指定为从节点。与 StatefulSet 控制器的部署顺序保证,这样可以确保 MySQL 主服务器在创建从服务器之前已准备就绪,以便它们可以开始复制。
- 克隆现有数据
通常,当新的 Pod 作为从节点加入集合时,必须假定 MySQL 主节点可能已经有数据。还必须假设复制日志可能不会一直追溯到时间的开始。 这些保守假设的关键是允许正在运行的 StatefulSet 随时间扩大和缩小而不是固定在其初始大小。
第二个名为 clone-mysql 的初始化容器,第一次在从属 Pod 上以空 PersistentVolume 启动时,会对从属 Pod 执行克隆操作。这意味着它将从另一个运行的 Pod 复制所有现有数据,因此其本地状态足够一致,可以开始主从服务器复制。
MySQL 本身不提供执行此操作的机制,因此该示例使用了一种流行的开源工具 Percona XtraBackup。 在克隆期间,源 MySQL 服务器可能会降低性能。 为了最大程度地减少对 MySQL 主机的影响,该脚本指示每个 Pod 从序号较低的 Pod 中克隆(即mysql-2从mysql-1中克隆)。 可以这样做的原因是 StatefulSet 控制器始终确保在启动 Pod N + 1 之前 Pod N 已准备就绪。
- 开始复制
初始化容器成功完成后,常规容器将运行。 MySQL Pods 由运行实际 mysqld 服务器的 mysql 容器和充当辅助工具的 xtrabackup 容器组成。
xtrabackup 辅助工具查看克隆的数据文件,并确定是否有必要在从属服务器上初始化 MySQL 复制。 如果是这样,它将等待 mysqld 准备就绪,然后执行带有从 XtraBackup 克隆文件中提取的复制参数 CHANGE MASTER TO 和 START SLAVE 命令。
一旦从服务器开始复制后,它会记住其 MySQL 主服务器。并且如果服务器重新启动或连接中断,则会自动重新连接。 另外,因为从服务器会以其稳定的 DNS 名称查找主服务器(mysql-0.mysql),即使由于重新安排而获得新的 Pod IP,他们也会自动找到主服务器。
最后,开始复制后,xtrabackup 容器监听来自其他 Pod 的连接数据克隆请求。 如果 StatefulSet 扩大规模,或者下一个 Pod 失去其 PersistentVolumeClaim 并需要重新克隆,则此服务器将无限期保持运行。
上述yaml文件中需要的镜像有:mysql:5.7 和 xtrabackup:1.0,需要提前拉取放到私有仓库里面。
运行这个文件:
[root@server1 mysql]# kubectl apply -f statefulset.yaml
statefulset.apps/mysql created
- 1
- 2
运行后等待几分钟即可查看到所有pod均以运行:
[root@server1 mysql]# kubectl get pod
NAME READY STATUS RESTARTS AGE
mysql-0 2/2 Running 0 6m34s
mysql-1 2/2 Running 0 4m2s
mysql-2 2/2 Running 0 2m
nfs-client-provisioner-6b66ddf664-zjvtv 1/1 Running 0 169m
- 1
- 2
- 3
- 4
- 5
- 6
主从测试
发送客户端流量
您可以通过运行带有 mysql:5.7 镜像的临时容器并运行 mysql 客户端二进制文件,将测试查询发送到 MySQL 主服务器(主机名 mysql-0.mysql )。
[root@server1 mysql]# kubectl run test --image=mysql:5.7 -it -- bash
root@test:/# mysql -h mysql-0.mysql
mysql> create database redhat;
Query OK, 1 row affected (0.11 sec)
mysql> show databases;
+––––––––––––+
| Database |
+––––––––––––+
| information_schema |
| mysql |
| performance_schema |
| redhat |
| sys |
| xtrabackup_backupfiles |
+––––––––––––+
6 rows in set (0.04 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
通过访问mysql-read来查看创建的数据库是否在从库创建:
[root@server1 mysql]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 19d
myservice ClusterIP 10.101.31.155 <none> 80/TCP 14d
mysql ClusterIP None <none> 3306/TCP 62m
mysql-read ClusterIP 10.100.94.198 <none> 3306/TCP 62m
[root@server1 mysql]#
[root@server1 mysql]# kubectl attach test -it
root@test:/# mysql -h 10.100.94.198
mysql> show databases;
+------------------------+
| Database |
+------------------------+
| information_schema |
| mysql |
| performance_schema |
| redhat |
| sys |
| xtrabackup_backupfiles |
+------------------------+
6 rows in set (0.05 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
可以看出从库复制了主库的操作。
也可以直接访问从库:
[root@server1 mysql]# kubectl attach test -it
root@test:/# mysql -h mysql-1.mysql
mysql> show databases;
+------------------------+
| Database |
+------------------------+
| information_schema |
| mysql |
| performance_schema |
| redhat |
| sys |
| xtrabackup_backupfiles |
+------------------------+
6 rows in set (0.02 sec)
访问第二个从库:
root@test:/# mysql -h mysql-2.mysql
mysql> show databases;
+------------------------+
| Database |
+------------------------+
| information_schema |
| mysql |
| performance_schema |
| redhat |
| sys |
| xtrabackup_backupfiles |
+------------------------+
6 rows in set (0.06 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
可以看出两个从库均复制了主库的操作。
此时mysql主从集群部署完成。
想要删除这个集群可以将replicas设置为0即可:
[root@server1 mysql]# vim statefulset.yaml
[root@server1 mysql]# cat statefulset.yaml
修改:
replicas: 0
[root@server1 mysql]# kubectl apply -f statefulset.yaml
statefulset.apps/mysql configured
[root@server1 mysql]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nfs-client-provisioner-6b66ddf664-zjvtv 1/1 Running 0 3h
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10